SQL Server中的高可用性(2)----文件与文件组
在谈到SQL Server的高可用性之前,我们首先要谈一谈单实例的高可用性。在单实例的高可用性中,不可忽略的就是文件和文件组的高可用性。SQL Server允许在某些文件损坏或离线的情况下,允许数据库依然保持部分在线,从而保证了高可用性。
文件和文件组
有关文件和文件组的基本概念,有很多文章已经阐述过了。这里我只是提一下,文件组作为SQL Server访问文件的一个抽象层而存在。因此SQL Server上所做的操作不是直接针对文件,而是针对文件组。
使用多个文件组和文件不仅仅是为了分散IO和提高性能,还有高可用性方面的原因。有关一个数据库应该包含几个文件或文件组,Paul Randal已经做过非常棒的阐述,请参阅:http://www.sqlskills.com/blogs/paul/files-and-filegroups-survey-results/。
数据库中使用多个文件或文件组在高可用性方面的好处包括:
- 某文件的IO损坏,数据库还可以保证部分在线。
- 将索引和表分开存放,假如索引文件不在线,数据依然可以被访问。
- 历史数据和热数据分开,历史归档数据损坏,不影响热数据。
- 分开数据文件使得在灾难恢复时仅仅恢复部分数据从而缩短了宕机时间
- 数据库分为多个文件使得可以通过增加文件或移动文件的方式解决空间不足的问题
文件
在SQL Server中,文件分为三类,分别为:
- 主数据文件
- 辅助数据文件
- 日志文件
其中,主数据文件默认以扩展名mdf结尾,辅助数据库文件默认以ndf结尾,日志文件以ldf结尾。虽然扩展名是可以修改的,但强烈建议不要去改扩展名。
上面提到文件名值得是物理文件名,但是实际上在SQL Server中进行操作,操作的是逻辑文件名。
任何时间,文件都会处于某一种状态,这些状态包括:
- 在线
- 离线
- 恢复中
- 还原挂起
- 质疑
可以通过sys.database_files这个DMV来查看数据库文件中包含状态在内的相关信息,如图1所示。
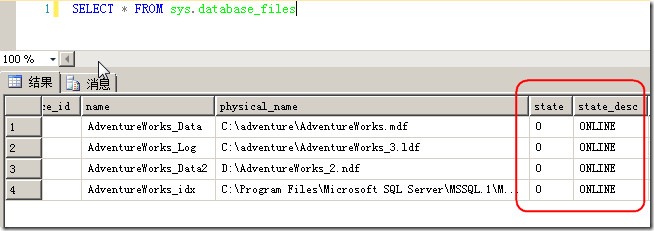
图1.查看数据库中文件的状态等相关信息
你甚至可以在数据库缺少NDF文件时附加数据库,具体细节,请参阅MCM黄大师的一篇文章:http://www.sqlnotes.info/2013/05/07/attach-database-with-missing-ndf-file/。
文件组
在SQL Server中,文件组中某个文件的状态决定了整个文件组的状态。但文件的状态独立于数据库的状态,比如说文件的状态是离线,但数据库依然能保证在线,这也就是所谓的数据库部分在线,举个例子,某个文件包含了名为selldata的表,如果该文件离线,但数据库在线,所有针对该selldata的表上的操作都会失败。
如果需要数据库中的某个文件组在线,该文件组中的所有文件都应该处于在线状态。
表分区
表分区是自SQL Server 2005之后出现的一个概念,我之前已经写过一篇关于表分区的文章。表分区的概念虽然很老了,但是很多地方对于表分区的使用依然处于非常初级的阶段。
我见过大部分想到使用表分区的例子是出现性能问题,从而考虑分散大表的IO。但实际上,表分区还会提高可用性。使用表分区的好处还包括:
- 轻松管理大表或分区
- 提高并发性(产生分区锁,而不是表锁)
- 以文件组级别就行备份和还原,从而仅仅只备份和还原表的一部分(比如说只备份表中的热数据),从而减少了还原时间
- 可以仅仅在线重建某个分区
值得注意的是,对表分区后,也要对表上的非聚集索引进行索引分区。否则有可能造成性能方面的例子。
DEMO
DEMO1 :仅重建某个分区
下面例子是一个简单的分区表,并对索引进行分区后,仅仅重建某个分区,而不是整个索引。比如说表中按照数据冷热进行分区,可以仅仅对热数据进行重建,从而大大减少了重建索引所需的时间,如代码清单1所示。
--创建分区函数
CREATE PARTITION FUNCTION [t](int) AS RANGE LEFT FOR VALUES (100, 500)
--分区架构
CREATE PARTITION SCHEME [x] AS PARTITION [t] TO ([PRIMARY], [FileGroup1], [FileGroup1]) --创建表
CREATE TABLE [Sales].[SalesOrderDetailPartition](
[SalesOrderID] [int] NOT NULL,
[SalesOrderDetailID] [int] IDENTITY(1,1) NOT NULL,
[CarrierTrackingNumber] [nvarchar](25) NULL,
[OrderQty] [smallint] NOT NULL,
[ProductID] [int] NOT NULL,
[SpecialOfferID] [int] NOT NULL,
[UnitPrice] [money] NOT NULL,
[UnitPriceDiscount] [money] NOT NULL,
[LineTotal] AS (isnull(([UnitPrice]*((1.0)-[UnitPriceDiscount]))*[OrderQty],(0.0))),
[rowguid] [uniqueidentifier] ROWGUIDCOL NOT NULL,
[ModifiedDate] [datetime] NOT NULL,
) ON x(SalesOrderID) INSERT INTO [Sales].[SalesOrderDetailPartition]([SalesOrderID],
[CarrierTrackingNumber],
[OrderQty] ,
[ProductID] ,
[SpecialOfferID],
[UnitPrice],
[UnitPriceDiscount],ModifiedDate,rowguid)
SELECT [SalesOrderID],
[CarrierTrackingNumber],
[OrderQty] ,
[ProductID] ,
[SpecialOfferID],
[UnitPrice],
[UnitPriceDiscount],ModifiedDate,rowguid FROM [Sales].[SalesOrderDetail] go
--创建索引分区
CREATE NONCLUSTERED INDEX test_partition_idx ON [Sales].[SalesOrderDetailPartition](ProductID) on x(SalesOrderID) --仅仅重建某个分区
ALTER INDEX test_partition_idx
ON [Sales].[SalesOrderDetailPartition]
REBUILD Partition = 1
代码清单1.仅仅重建某个分区,而不是整个索引
关于这里,更深入的文章可以参阅:http://www.mssqltips.com/sqlservertip/1621/sql-server-partitioned-tables-with-multiple-filegroups-for-high-availability/
DEMO2:数据库部分在线和文件还原
--创建测试数据库
CREATE DATABASE test
GO
--改成完整恢复模式
ALTER DATABASE test SET RECOVERY FULL
--添加一个文件组
ALTER DATABASE test
ADD FILEGROUP WW_GROUP
GO
--向文件组中添加文件
ALTER DATABASE test
ADD FILE
( NAME = ww,
FILENAME = 'D:\wwdat1.ndf',
SIZE = 5MB,
MAXSIZE = 100MB,
FILEGROWTH = 5MB)
TO FILEGROUP ww_Group --在不同文件组上分别创建两个表
CREATE TABLE test..test ( id INT IDENTITY )
ON [primary]
CREATE TABLE test..test_GR ( id INT IDENTITY )
ON ww_Group --做完整备份
BACKUP DATABASE test
TO DISK='D:\Test_backup.bak'WITH INIT --做文件备份
BACKUP DATABASE test
FILE = 'ww',
FILEGROUP = 'ww_Group'
TO DISK='D:\CROUPFILES.bak'WITH INIT
--备份日志
BACKUP LOG test
TO DISK='D:\Test__log.ldf'WITH INIT --删除文件组中的表内的数据
TRUNCATE TABLE test..test_GR --还原备份,日志仅仅被应用于那个还原状态的文件
RESTORE DATABASE test
FILE = 'ww',
FILEGROUP = 'ww_Group'
FROM DISK ='D:\CROUPFILES.bak'
WITH FILE = 1,NORECOVERY
RESTORE LOG test
FROM DISK='D:\Test__log.ldf'
WITH FILE = 1, NORECOVERY --备份尾端日志
BACKUP LOG test
TO DISK='D:\Test__log.ldf' WITH NOINIT,NO_TRUNCATE
--还原尾端日志
RESTORE LOG test
FROM DISK='D:\Test__log.ldf'
WITH FILE = 2, RECOVERY
GO --查看数据,删除数据的操作被成功恢复
SELECT *
FROM test..test_GR --清除数据库
DROP DATABASE test
代码清单2.备份还原单个文件
代码清单2很好的阐述了整个文件备份还原的过程,其中,在文件还原的过程中我们可以看到数据库本身是在线的,但数据库中有一个文件处于还原状态,如图2所示。
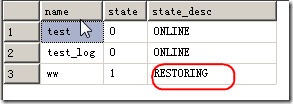
图2.ww文件处于还原中状态
此时对于表test_GR做操作的话,会提示因文件组没有联机而失败,如图3所示。
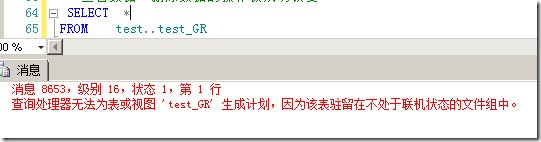
图3.因为文件组没有联机而导致操作失败
再对尾端日志进行备份还原之后,该文件组成功上线。
小结
本篇文章阐述了文件和文件组在高可用性中的作用。了解这些特性对于降低还原时间非常有必要。在数据库开始上线之前,尽量合理的把一个数据库分为多个文件组和文件,不仅仅提升性能和并发性,还可以使得DR更加容易。
SQL Server中的高可用性(2)----文件与文件组的更多相关文章
- SQL Server中的高可用性1
SQL Server中的高可用性(1)----高可用性概览 自从SQL Server 2005以来,微软已经提供了多种高可用性技术来减少宕机时间和增加对业务数据的保护,而随着SQL Server ...
- SQL Server中的高可用性(1)----高可用性概览
自从SQL Server 2005以来,微软已经提供了多种高可用性技术来减少宕机时间和增加对业务数据的保护,而随着SQL Server 2008,SQL Server 2008 R2,SQL ...
- SQL Server中的高可用性(3)----复制
在本系列文章的前两篇对高可用性的意义和单实例下的高可用性做了阐述.但是当随着数据量的增长,以及对RTO和RPO要求的严格,单实例已经无法满足HA/DR方面的要求,因此需要做多实例的高可用性.本 ...
- SQL Server中的高可用性(3)----复制 (转载)
在本系列文章的前两篇对高可用性的意义和单实例下的高可用性做了阐述.但是当随着数据量的增长,以及对RTO和RPO要求的严格,单实例已经无法满足HA/DR方面的要求,因此需要做多实例的高可用性.本文着重对 ...
- SQL Server中的高可用性----复制
在本系列文章的前两篇对高可用性的意义和单实例下的高可用性做了阐述.但是当随着数据量的增长,以及对RTO和RPO要求的严格,单实例已经无法满足HA/DR方面的要求,因此需要做多实例的高可用性.本文着重对 ...
- SQL Server 中执行Shell脚本计算本地文件的内容大小
SQL Server 数据库中除了能执行基本的SQL语句外,也可以执行Shell脚本.默认安装后,SQL中的Shell脚本的功能是关闭的,需要手动打开, 执行以下脚本即可打开该功能. -- 允许配置高 ...
- SQL Server中如何用mdf,ldf文件还原数据库
不论是手动还原还是写个脚本还原,首先都要修改文件的属性为可读写,另外这个用户能够修改 1.手动Attach 2.写个脚本还原 我个人比较喜欢写个脚本去还原 Exec sp_attach_db @dbn ...
- 是否应该将SAN上的SQL Server中的user database的data文件, log文件和TempDB文件放在不同的LUN上?
请看下面的两个精彩解答: 解答1: If your SAN has performance and availability algorithms built into the management ...
- c#Winform程序调用app.config文件配置数据库连接字符串 SQL Server文章目录 浅谈SQL Server中统计对于查询的影响 有关索引的DMV SQL Server中的执行引擎入门 【译】表变量和临时表的比较 对于表列数据类型选择的一点思考 SQL Server复制入门(一)----复制简介 操作系统中的进程与线程
c#Winform程序调用app.config文件配置数据库连接字符串 你新建winform项目的时候,会有一个app.config的配置文件,写在里面的<connectionStrings n ...
随机推荐
- Kotlin的Lambda表达式以及它们怎样简化Android开发(KAD 07)
作者:Antonio Leiva 时间:Jan 5, 2017 原文链接:https://antonioleiva.com/lambdas-kotlin/ 由于Lambda表达式允许更简单的方式建模式 ...
- Ubuntu 14.04中Elasticsearch集群配置
Ubuntu 14.04中Elasticsearch集群配置 前言:本文可用于elasticsearch集群搭建参考.细分为elasticsearch.yml配置和系统配置 达到的目的:各台机器配置成 ...
- X86和X86_64和X64有什么区别?
x86是指intel的开发的一种32位指令集,从386开始时代开始的,一直沿用至今,是一种cisc指令集,所有intel早期的cpu,amd早期的cpu都支持这种指令集,ntel官方文档里面称为&qu ...
- 一篇文章看懂TPCx-BB(大数据基准测试工具)源码
TPCx-BB是大数据基准测试工具,它通过模拟零售商的30个应用场景,执行30个查询来衡量基于Hadoop的大数据系统的包括硬件和软件的性能.其中一些场景还用到了机器学习算法(聚类.线性回归等).为了 ...
- Node.js:path、url、querystring模块
Path模块 该模块提供了对文件或目录路径处理的方法,使用require('path')引用. 1.获取文件路径最后部分basename 使用basename(path[,ext])方法来获取路径的最 ...
- 【原创经验分享】WCF之消息队列
最近都在鼓捣这个WCF,因为看到说WCF比WebService功能要强大许多,另外也看了一些公司的招聘信息,貌似一些中.高级的程序员招聘,都有提及到WCF这一块,所以,自己也关心关心一下,虽然目前工作 ...
- javaScript生成二维码(支持中文,生成logo)
资料搜索 选择star最多的两个 第一个就是用的比较多的jquery.qrcode.js(但不支持中文,不能带logo)啦,第二个支持ie6+,支持中文,根据第二个源代码,使得,jquery.qrco ...
- Win10连接远程桌面时提示“您的凭据不工作”
我遇到这个问题的时候查找网上都给出一堆高大上的解决办法, 然而我的错误实际上是用户名的问题, 很多人以为远程用户名就一定是锁屏状态下的登录名, 其实不是,跟自己设置有关,所以首先应该检查远程用户名是否 ...
- Linux网络驱动--snull
snull是<Linux Device Drivers>中的一个网络驱动的例子.这里引用这个例子学习Linux网络驱动. 因为snull的源码,网上已经更新到适合最新内核,而我自己用的还是 ...
- hive
Hive Documentation https://cwiki.apache.org/confluence/display/Hive/Home 2016-12-22 14:52:41 ANTLR ...