Lucene分页-----SearcherAfter
/**
* 分页,SearcherAfter
* @param query
* @param pageIndex
* @param pageSize
*/
public void searchPageByAfter(String query,int pageIndex,int pageSize){
try {
IndexSearcher indexSearcher = getSearcher();
QueryParser parser = new QueryParser("content", new StandardAnalyzer());
Query q = parser.parse(query);
//获取上一页的最后一个元素
ScoreDoc lastScoreDoc = getLastScoreDoc(pageIndex, pageSize, q, indexSearcher);
//通过最后一个元素搜索下页的pageSize个元素
TopDocs topDocs = indexSearcher.searchAfter(lastScoreDoc,q,pageSize);
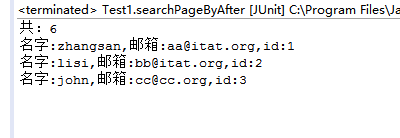
System.out.println("共:"+topDocs.totalHits);
for (ScoreDoc item : topDocs.scoreDocs) {
Document doc = indexSearcher.doc(item.doc);
System.out.println("名字:" + doc.get("name") + ",邮箱:" + doc.get("email") + ",id:" + doc.get("id"));
}
} catch (Exception e) {
// TODO: handle exception
e.printStackTrace();
}finally{
try {
directory.close();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
测试:
@Test
public void searchPageByAfter(){
SearchUtil util = new SearchUtil();
util.searchPageByAfter("like",1,3);
}

Lucene分页-----SearcherAfter的更多相关文章
- Lucene 分页搜索实现
Lucene中有两种分页查询方式 1.一次查询出大量数据,然后根据页码定位是哪个文档,其实就是暴力获取了 2.通过调用searchAfter来实现 我们都知道collect是lucene中对搜索到的文 ...
- 关于Lucene分页标准
public IEnumerable<SearchResult> Search(string keyword, string[] fieldNames, int pageSize, int ...
- Lucene查询索引(分页)
分页查询只需传入每页显示记录数和当前页就可以实现分页查询功能 Lucene分页查询是对搜索返回的结果进行分页,而不是对搜索结果的总数量进行分页,因此我们搜索的时候都是返回前n条记录 package c ...
- lucene 查询+分页+排序
lucene 查询+分页+排序 1.定义一个工厂类 LuceneFactory 1 import java.io.IOException; 2 3 import org.apache.lucene.a ...
- 谈谈个人网站的建立(二)—— lucene的使用
首先,帮忙点击一下我的网站http://www.wenzhihuai.com/ .谢谢啊,如果可以,GitHub上麻烦给个star,以后面试能讲讲这个项目,GitHub地址https://github ...
- lucene4.7学习总结
花了一段时间学习lucene今天有时间把所学的写下来,网上有很多文章但大部分都是2.X和3.X版本的(当前最新版本4.9),希望这篇文章对自己和初学者有所帮助. 学习目录 (1)什么是lucene ( ...
- lucene4.7学习总结 (zhuan)
http://blog.csdn.NET/mdcmy/article/details/38167955?utm_source=tuicool&utm_medium=referral ***** ...
- lucene两个分页操作
基于lucene两个分页: lucene3.5查询方式(每次查询所有记录,然后取当中部分记录.这样的方式用的最多),lucene官方的解释:因为我们的速度足够快. 处理海量数据时.内存easy内存溢出 ...
- lucene的两种分页操作
基于lucene的分页有两种: lucene3.5之前分页提供的方式为再查询方式(每次查询全部记录,然后取其中部分记录,这种方式用的最多),lucene官方的解释:由于我们的速度足够快.处理海量数据时 ...
随机推荐
- RIDE常用快捷键
重命名: F2 搜索关键字: F5 执行用例: F8 创建新工程: Ctrl+N 创建新测试套: Ctrl+Shift+F 创建新用例: Ctrl+Shift+T 创建新关键字: Ctrl+Shift ...
- 现代Web的资源/类型/元素--发展趋势
5月6日,谷歌开发者中心推出了一个 Web 开发最佳实践手册.伯乐在线资源频道摘编该资源后,已邀请一些关注 Web 开发的朋友参与翻译手册. 由于译者朋友几乎都是已在职,都是在工作之余参与,每位的翻译 ...
- Qualcomm Android display架构分析
Android display架构分析(一) http://blog.csdn.net/BonderWu/archive/2010/08/12/5805961.aspx http://hi.baidu ...
- How to effectively work with multiple files in Vim?
Why not use tabs (introduced in Vim 7)? You can switch between tabs with :tabn and :tabp, With :tabe ...
- 如何在 Linux 终端下创建新的文件系统/分区
在 Linux 中创建分区或新的文件系统通常意味着一件事:安装 Gnome Parted 分区编辑器(GParted).对于大多数 Linux 用户而言,这是唯一的办法.不过,你是否考虑过在终端创建这 ...
- 3 weekend110的hadoop中的RPC框架实现机制 + hadoop中的RPC应用实例demo
hadoop中的RPC框架实现机制 RPC是Remotr Process Call, 进程间的远程过程调用,不是在一个jvm里. 即,Controller拿不到Service的实例对象. hadoop ...
- Ubuntu 14.04 配置 Java SE
首先下载Java SE,下载地址:http://www.oracle.com/technetwork/java/javase/downloads/index.html: 下载后把压缩包拷贝到自定义的目 ...
- Java多线程异步调度程序分析(二)
源自:http://blog.sina.com.cn/s/blog_4cc16fc50100c0uh.html public abstract class Result { //抽象的结果类 pu ...
- 驱动lx4f120h,头文件配置,没有完全吃透,望指点
来了块开发板,没接触过,希望能驱动起来,就首先试一下驱动LED,没想到刚开始建好工程问题就来了 使用GPIO驱动,首先想到的是关于GPIO的头文件gpio.h,事实上这个还不够,还需要设置一下系统的配 ...
- linux之access函数解析
[lingyun@localhost access_1]$ ls access.c 实例一: [lingyun@localhost access_1]$ cat access.c /******** ...