详细讲解Hadoop源码阅读工程(以hadoop-2.6.0-src.tar.gz和hadoop-2.6.0-cdh5.4.5-src.tar.gz为代表)
不多说,直接上干货!
首先,说的是,本人到现在为止,已经玩过。




对于,这样的软件,博友,可以去看我博客的相关博文。在此,不一一赘述!
Eclipse *版本
Eclipse *下载
Jdk 1.7*安装并配置
Jdk 1.8*安装并配置
JDK的windows和Linux版本之下载
Eclipse下新建Maven项目、自动打依赖jar包
如何在Maven官网下载历史版本
setting.xml配置文件
【转】maven核心,pom.xml详解
本博文呢,Eclipse下详细讲解hadoop-2.6.0-src.tar.gz源码!作为Hadoop-2.*的代表,当然,9月初期,已经发布了Hadoop-3.*了。
本博文呢
需要具备一定的知识基础。包括懂Hadoop和源码编译、Eclipse和Jdk的版本、下载、安装、Maven创建项目和自动打依赖jar包等。
直接进入!
关于源码编译的过程
Hadoop源码的编译过程详细解读(各版本)
Spark源码的编译过程详细解读(各版本)
关于创建源码阅读工程的过程
有很多种方式,这里我暂时给博友两种。
1、使用Maven导入和后续attach source的方法
2、构建Maven工程
3、构建Java工程,使用源代码压缩包导入Eclipse工程的方法
总的来说,目前存在两种Hadoop源代码阅读环境搭建方法,分别是构建Maven工程和构建Java工程。两种方法各有利弊:前者可通过网络自动下载依赖的第三方库,但源代码会被分散到多个工程中进而带来阅读上的不便;后者可将所有源代码组织在一个工程中,但需要自己添加依赖的第三方库。
当然,上述指的是Apache Hadoop版本。
CDH版本将源代码和JAR包放到了一起,因此,如果使用CDH版本,则直接按照上述方法将源代码导入Eclipse工程即可。
这里呢,我细说三种方法。
Apache Hadoop版本
1、使用Maven导入和后续attach source的方法
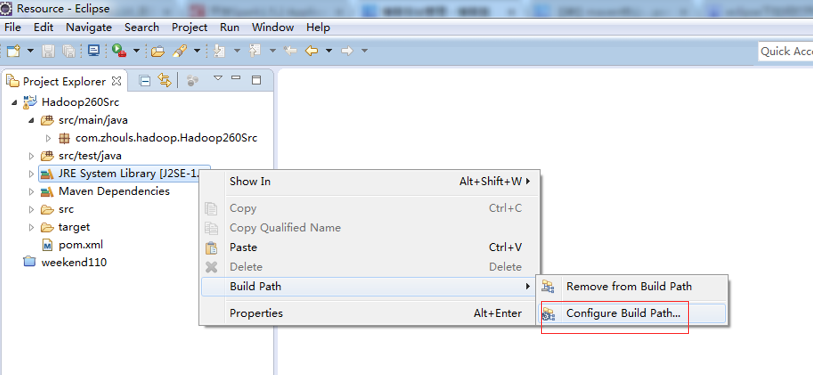
eclipse下如何打开和关闭一个项目?
打开项目:在关闭的项目上右击,选择“open project”,即可打开项目。
关闭项目:在打开的项目上右击,选择“close project”,即可关闭项目。


已经关闭
用Maven创建Hadoop260Src

或者




Group Id:com.zhouls.hadoop
Artifact Id:Hadoop260Src






默认生成的pom.xml配置文件的,内容是
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.</modelVersion> <groupId>com.zhouls.hadoop</groupId>
<artifactId>Hadoop260Src</artifactId>
<version>0.0.-SNAPSHOT</version>
<packaging>jar</packaging> <name>Hadoop260Src</name>
<url>http://maven.apache.org</url> <properties>
<project.build.sourceEncoding>UTF-</project.build.sourceEncoding>
</properties> <dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>3.8.</version>
<scope>test</scope>
</dependency>
</dependencies>
</project>
这一步,最为关键,具体怎么修改pom.xml,是要看自己的需求。
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.</modelVersion> <groupId>com.zhouls.hadoop</groupId>
<artifactId>Hadoop260Src</artifactId>
<version>0.0.-SNAPSHOT</version>
<packaging>jar</packaging> <name>Hadoop260Src</name>
<url>http://maven.apache.org</url> <properties>
<project.build.sourceEncoding>UTF-</project.build.sourceEncoding>
<junit.version>4.10</junit.version>
<hadoop.version>2.6.</hadoop.version>
</properties> <dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>${junit.version}</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.6.</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.6.</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>2.6.</version>
<exclusions>
<exclusion>
<groupId>jdk.tools</groupId>
<artifactId>jdk.tools</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>jdk.tools</groupId>
<artifactId>jdk.tools</artifactId>
<version>1.6</version>
<scope>system</scope>
<systemPath>${JAVA_HOME}/lib/tools.jar</systemPath>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
</dependency>
</dependencies> <build>
<sourceDirectory>src/main/java</sourceDirectory>
<testSourceDirectory>src/main/test</testSourceDirectory> <plugins>
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
<archive>
<manifest>
<mainClass></mainClass>
</manifest>
</archive>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin> <plugin>
<groupId>org.codehaus.mojo</groupId>
<artifactId>exec-maven-plugin</artifactId>
<version>1.2.</version>
<executions>
<execution>
<goals>
<goal>exec</goal>
</goals>
</execution>
</executions>
<configuration>
<executable>java</executable>
<includeProjectDependencies>true</includeProjectDependencies>
<includePluginDependencies>false</includePluginDependencies>
<classpathScope>compile</classpathScope>
<mainClass>com.zhouls.hadoop.Hadoop260Src</mainClass>
</configuration>
</plugin>
</plugins>
</build> </project>

成功!
目前,在pom.xml里只加入了部分,如mapreduce和hdfs,随着以后,逐渐,可以将yarn,hive,hbase,pig,zookeeper...等加入。
至此,成功!
具体,后续,请见我的博客。地址。。。。
2、构建Maven工程
(1)构建Maven工程
通过Maven工程搭建Hadoop源代码阅读环境的步骤如下:
步骤1 解压缩Hadoop源代码。
将下载到的Hadoop源代码压缩包解压到工作目录下,比如hadoop-2.6.0-src.tar.gz


解压到当前目录下,得到

步骤2 导入Maven工程。

在Eclipse中,依次选择“File”→“Import”→“Maven”→“Existing Maven Project”,在弹出的对话框中的“Root Directory”后面,选择Java源代码所在的目录。
单击“Next”按钮,在弹出的对话框中选择“Resolve All Later”,并单击“Finish”按钮完成Maven项目导入。之后,Eclipse会自动通过网络从Maven库中下载依赖的第三方库(JAR包等)。注意,你所使用的电脑必须能够联网。
将Hadoop 2.0源代码导入Maven项目后,会生成50个左右的工程,这些都是通过Maven构建出来的,每个工程是一个代码模块,且彼此相对独立,可以单独编译。你可以在某个工程下的“src/main/java”目录下查看对应的源代码。



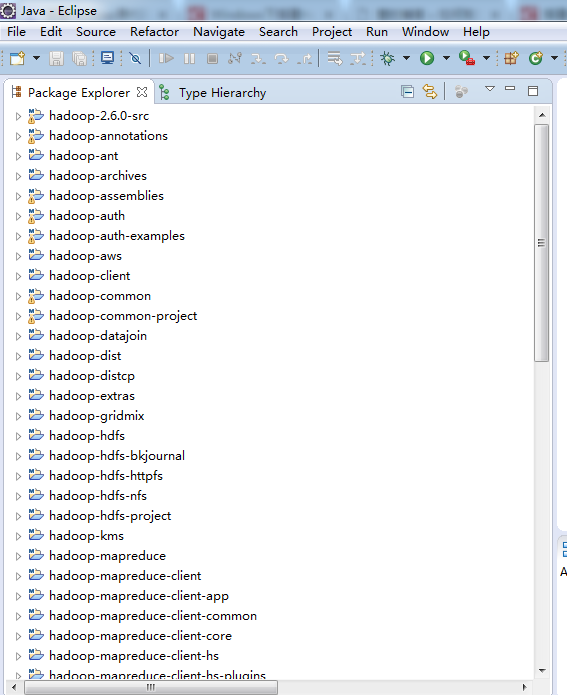

成功!大功告成!
每个工程是一个代码模块,且彼此相对独立,可以单独编译。你可以在某个工程下的“src/main/java”目录下查看对应的源代码。


注意: 中间,也许需要一段时间,因为是Maven嘛,联网下载相关,正常!
3、构建Java工程,使用源代码压缩包导入Eclipse工程的方法

下载,太简单了,不多赘述!
解压,


新建Java工程,打开Eclipse

File -> New -> Java Project
并在弹出的对话框中取消选中“Use default location”前的勾号,然后选择刚的hadoop-2.6.0-src的安装目录

点击Next,最好是点击Finish。
可以一一看看
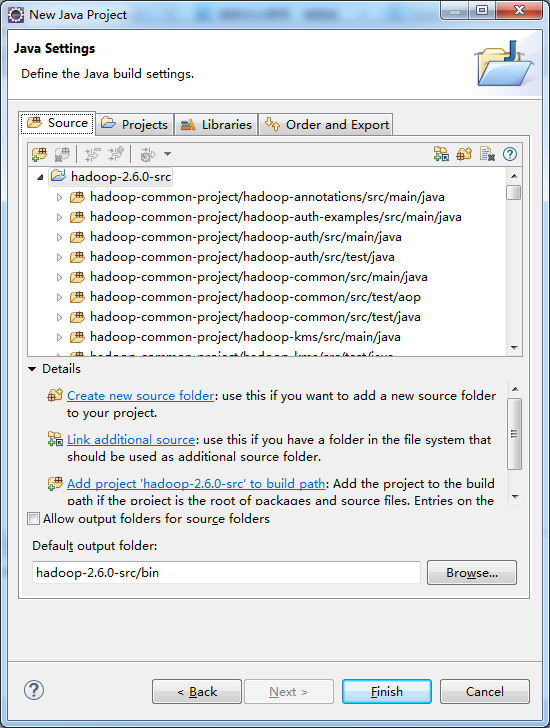

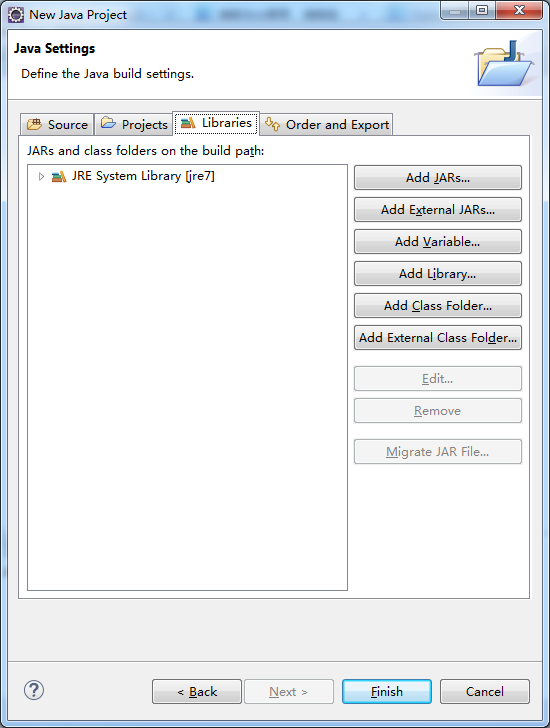

点击Finish


至此,大功告成!
拿出里面的例子,来看看

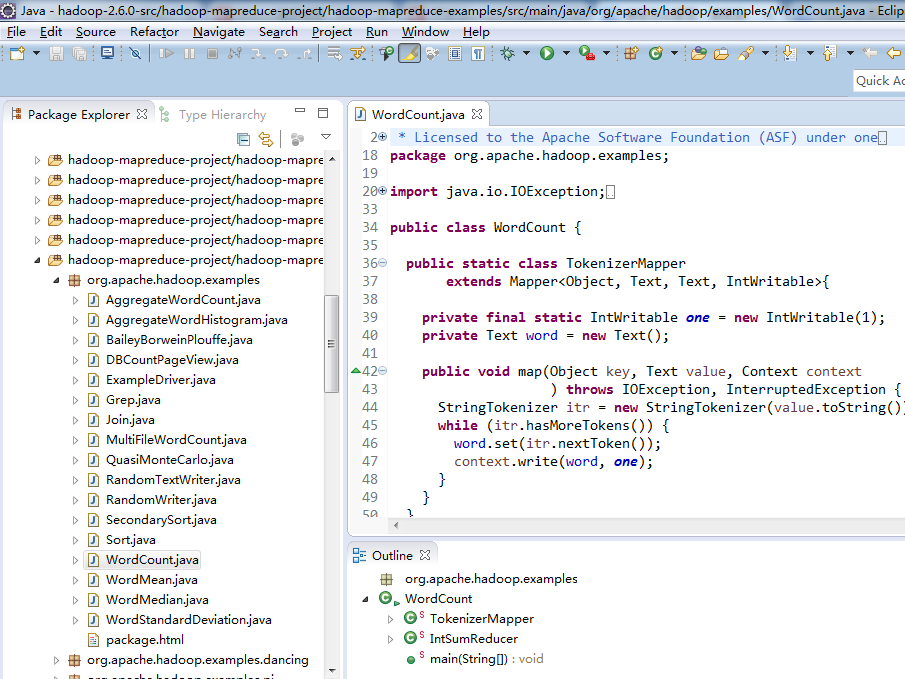

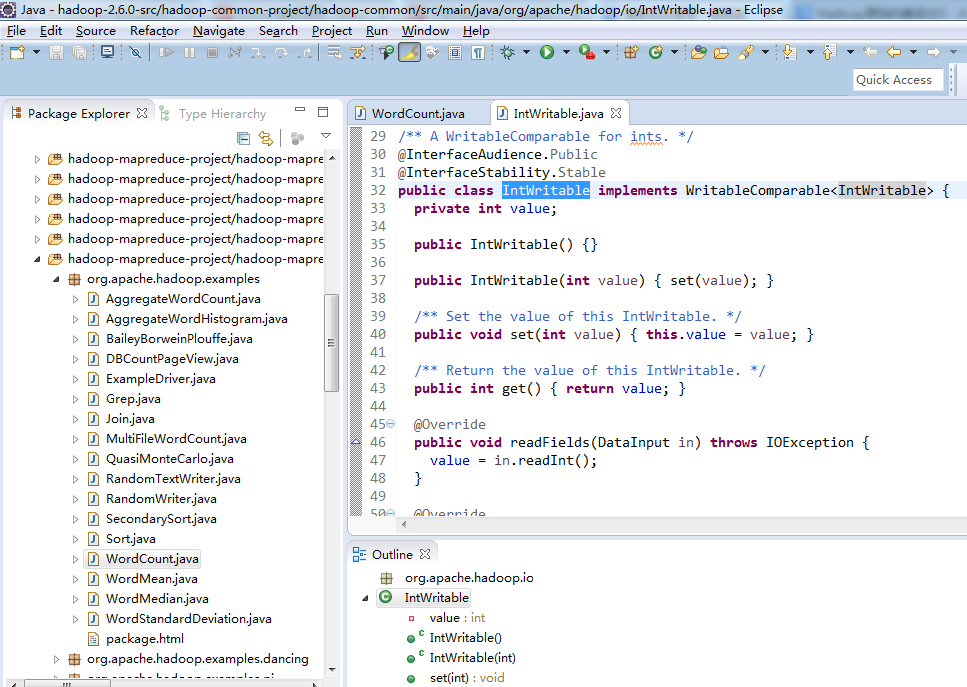
ok!
但是呢?
需要注意的是,通过以上方法导入Hadoop 2.*源代码后,很多类或者方法找不到对应的JAR包,为了解决这个问题,你需要将第三方JAR包导入工程中,如下所示,
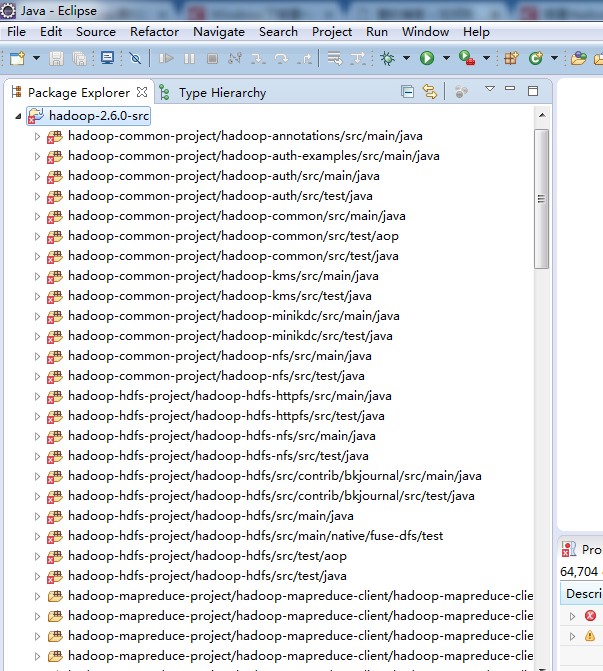
方法如下:解压存放JAR包的压缩包,然后右击Project名称,在弹出的快捷菜单中选择“Properties”命令,将会弹出一个界面,然后在该界面中依次选择“Java Build Path”→ “Libraries”→“Add External JARs...”,将解压目录中share/hadoop目录下各个子目录中lib文件夹下的JAR包导入工程。


share/hadoop目录下各个子目录中lib文件夹,分别如下


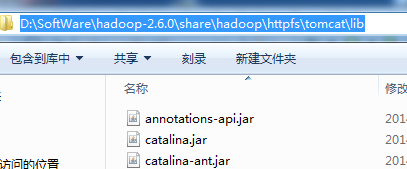


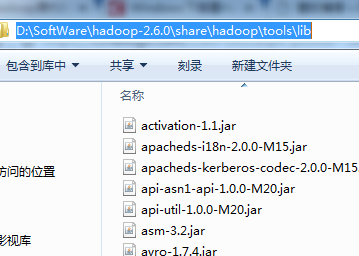
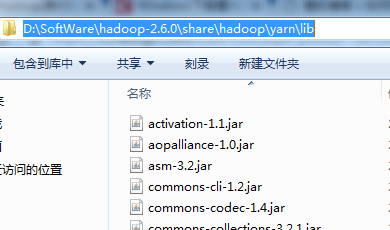
一一导入!!!(细心)
具体做法,如下:
右击Project名称,即,hadoop-2.6.0-src,在弹出的快捷菜单中选择“Properties”命令

将会弹出一个界面,然后在该界面中依次选择“Java Build Path”→ “Libraries”→“Add External JARs...”

1、D:\SoftWare\hadoop-2.6.0\share\hadoop\common\lib

2、D:\SoftWare\hadoop-2.6.0\share\hadoop\hdfs\lib

3、D:\SoftWare\hadoop-2.6.0\share\hadoop\httpfs\tomcat\lib

4、D:\SoftWare\hadoop-2.6.0\share\hadoop\kms\tomcat\lib
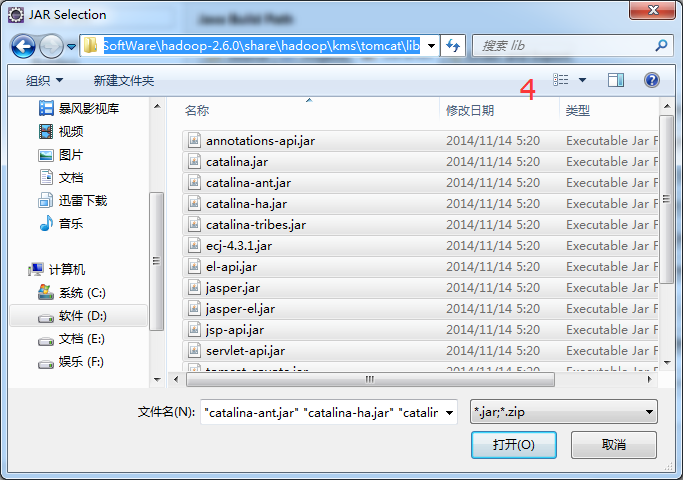
5、D:\SoftWare\hadoop-2.6.0\share\hadoop\mapreduce\lib

6、D:\SoftWare\hadoop-2.6.0\share\hadoop\tools\lib

7、D:\SoftWare\hadoop-2.6.0\share\hadoop\yarn\lib

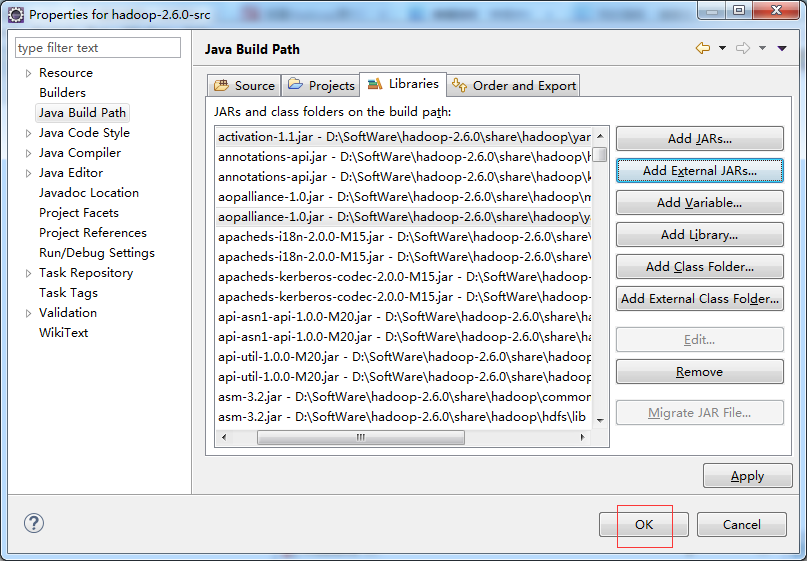

得到,之后,可以看出,错误大大减半。


然后,手动再去修改,即可!
其实这个错误,也不是错误。

最后成功!
CDH版本
这里,我就只已构建Java工程赘述下,其他的几种方法,同理,很简单的!
关于下载:
http://archive-primary.cloudera.com/cdh5/cdh/5/


解压

这里,我为了方便,自命名。




在Eclipse里直接关联源码
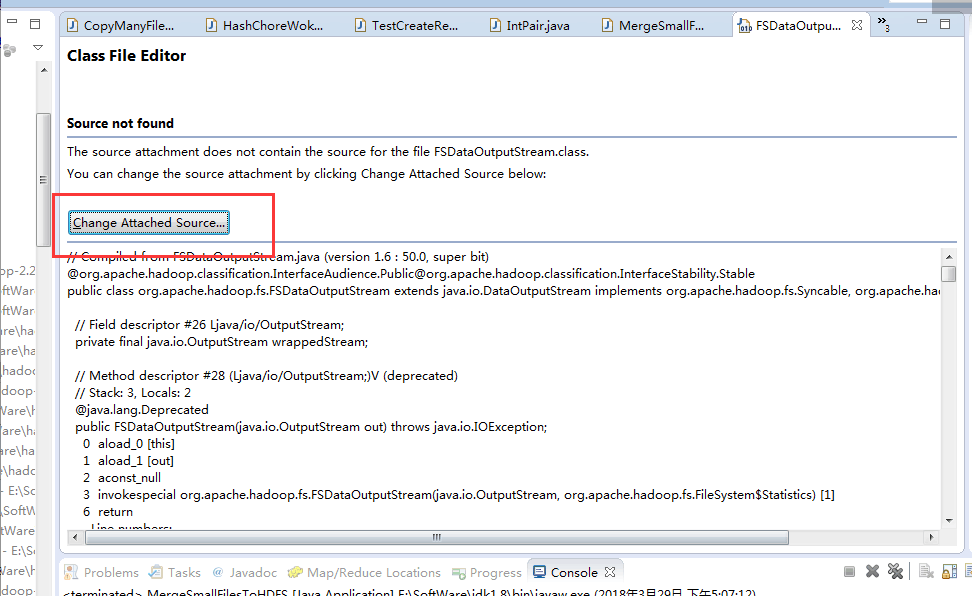
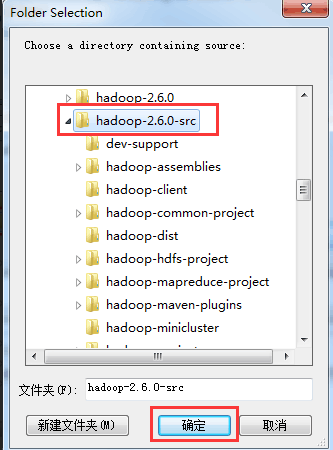
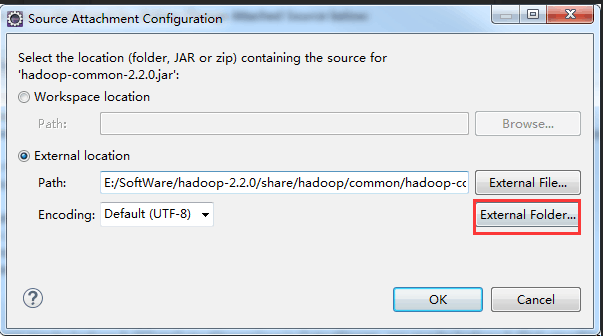
ok,至此结束!
欢迎,喜欢专研hadoop/spark源码的博友们,跟我一起交流,互相学习!
感谢如下的博主:
http://blog.csdn.net/cnhk1225/article/details/50482431
http://blog.csdn.net/yhao2014/article/details/43017191
同时,大家可以关注我的个人博客:
http://www.cnblogs.com/zlslch/ 和 http://www.cnblogs.com/lchzls/ http://www.cnblogs.com/sunnyDream/
详情请见:http://www.cnblogs.com/zlslch/p/7473861.html
人生苦短,我愿分享。本公众号将秉持活到老学到老学习无休止的交流分享开源精神,汇聚于互联网和个人学习工作的精华干货知识,一切来于互联网,反馈回互联网。
目前研究领域:大数据、机器学习、深度学习、人工智能、数据挖掘、数据分析。 语言涉及:Java、Scala、Python、Shell、Linux等 。同时还涉及平常所使用的手机、电脑和互联网上的使用技巧、问题和实用软件。 只要你一直关注和呆在群里,每天必须有收获
对应本平台的讨论和答疑QQ群:大数据和人工智能躺过的坑(总群)(161156071)![]()
![]()
![]()
![]()
![]()



详细讲解Hadoop源码阅读工程(以hadoop-2.6.0-src.tar.gz和hadoop-2.6.0-cdh5.4.5-src.tar.gz为代表)的更多相关文章
- Hadoop源码阅读环境搭建(IDEA)
拿到一份Hadoop源码之后,经常关注的两件事情就是 1.怎么阅读?涉及IDEA和Eclipse工程搭建.IDEA搭建,选择源码,逐步导入即可:Eclipse可以选择后台生成工程,也可以选择IDE导入 ...
- Mac搭建Hadoop源码阅读环境
1.本次Hadoop源码阅读环境使用的阅读工具是idea,Hadoop版本是2.7.3.需要安装的工具包括idea.jdk.maven.protobuf等 2.jdk,使用的版本是1.8版,在jdk官 ...
- 【深入浅出 Yarn 架构与实现】1-2 搭建 Hadoop 源码阅读环境
本文将介绍如何使用 idea 搭建 Hadoop 源码阅读环境.(默认已安装好 Java.Maven 环境) 一.搭建源码阅读环境 一)idea 导入 hadoop 工程 从 github 上拉取代码 ...
- 琐碎-将hadoop源码作为工程导入eclipse
之前写过如何用eclipse看hadoop源码,虽然非官方版的,但是可以达到目的,最重要是简单方便快速 官方版(hadoop2.2.0)的也有: 源码目录为: 和之前的源码目录有很大的不同 编译的时候 ...
- IntelliJ IDEA 配置 Hadoop 源码阅读环境
1.下载安装IDEA https://www.jetbrains.com/idea/download/#section=windows 2.下载hadoop源码 https://archive.apa ...
- Apache Hadoop 源码阅读
总之一句话,这些都是hadoop-2.2.0的源代码里有的.也就是不光只是懂理论,编程最重要,还是基本功要扎实啊.... 在hadoop-2.2.0的源码里,按Ctrl + Shift + T . 跳 ...
- Apache Hadoop 源码阅读(陆续更新)
不多说,直接上干货! 总之一句话,这些都是hadoop-2.2.0的源代码里有的.也就是不光只是懂理论,编程最重要,还是基本功要扎实啊.... 在hadoop-2.2.0的源码里,按Ctrl + Sh ...
- Hadoop 源码阅读技巧
http://www.cnblogs.com/xuxm2007/category/388607.html 个人谈谈阅读hadoop源代码的经验.首先,不得不说,hadoop发展到现在这个阶段, ...
- hadoop源码阅读
1.Hadoop的包的功能分析 2.由于Hadoop的MapReduce和HDFS都有通信的需求,需要对通信的对象进行序列化.Hadoop并没有采用java的序列化,而是引入它自己的系统.org.ap ...
随机推荐
- CODEVS 2055 集合划分
[题目描述] 对于从1到N(1<=N<=39)的连续整数集合,划分成两个子集合,使得每个集合的数字之和相等. 举个例子,如果N=3,对于{1,2,3}能划分成两个子集合,他们每个的所有数字 ...
- pywinauto二次封装(pywinnat.py)
将pywinauto常用方法进行封装,使得pywinauto用起来更简单 #头文件的引入 from pywinauto import application from pywinauto import ...
- DOS系统里,分屏显示目录的命令是什么??
dir /sdir /pdir /w 我记得这三个都是我当年常用的命令,有分瓶的,有滚动时候每页停顿的,还有去掉详细信息的吧,, 可以放在一起使用.如dir /p/w /p是滚动时候中间停顿的,/w是 ...
- ECSHOP安装或使用中提示Strict Standards: Non-static method cls_image:
随着ECSHOP的不断发展,越来越多的人成为了ECSHOP的忠实粉丝.由于每个人的服务器环境和配置都不完全相同,所以ECSHOP也接二连三的爆出了各种各样的错误信息.相信不少新手朋友在ECSHOP安装 ...
- MemSQL Start[c]UP 2.0 - Round 2
反正晚上睡不着,熬到1点开始做比赛,6个题目只做了2个题目,而且手速还比较慢,待提升空间还很大呢. A题:给定两个0,1串(len<=100000), 但是不是普通的二进制串,而是q进制串,q ...
- Android开发UI之个性化控件之Menu
MenuDrawer 滑出式菜单,通过拖动屏幕边缘滑出菜单,支持屏幕上下左右划出,支持当前View处于上下层,支持Windows边缘.ListView边缘.ViewPager变化划出菜单等. 项目地址 ...
- poj1691(dfs)
链接 dfs了 写得有点乱 #include <iostream> #include<cstdio> #include<cstring> #include<a ...
- bzoj2208
首先有向图的题目不难想到先tarjan缩点 一个强连通分量中的点的连通数显然是相等: 据说这样直接dfs就可以过了,但显然不够精益求精 万一给定的是一个完全的DAG图怎么办,dfs铁定超时: 首先想, ...
- POJ_3061_Subsequence_(尺取法)
描述 http://poj.org/problem?id=3061 给定长度为n的数列整数以及整数S.求出总和不小于S的连续子序列的长度的最小值,如果解不存在输出0. Subsequence Time ...
- Memcached 拒绝服务漏洞
漏洞名称: Memcached 拒绝服务漏洞 CNNVD编号: CNNVD-201401-176 发布时间: 2014-01-15 更新时间: 2014-01-15 危害等级: 漏洞类型: ...