并查集算法Union-Find的思想、实现以及应用
并查集算法,也叫Union-Find算法,主要用于解决图论中的动态连通性问题。
Union-Find算法类
这里直接给出并查集算法类UnionFind.class,如下:
/*** Union-Find 并查集算法* @author Chiaki*/public class UnionFind {// 连通分量个数private int count;// 存储若干棵树private int[] parent;// 记录树的"重量"private int[] size;// 构造函数public UnionFind(int count) {this.count = count;parent = new int[count];size = new int[count];for (int i = 0; i < count; i++) {parent[i] = i;size[i] = 1;}}// 连通函数public void union(int p, int q) {// 如果节点p和q已经连接,直接返回if (connected(p,q)) return;// 找到节点p和节点q的根节点int rootP = find(p);int rootQ = find(q);if (size[rootP] > size[rootQ]) {parent[rootQ] = rootP;size[rootP] += size[rootQ];} else {parent[rootP] = rootQ;size[rootQ] += size[rootP];}count--;}// 判断是否连通public boolean connected(int p, int q) {int rootP = find(p);int rootQ = find(q);return rootP == rootQ;}// 寻找根节点public int find(int x) {while (parent[x] != x) {parent[x] = parent[parent[x]];x = parent[x];}return x;}// 返回连通分量个数public int count() {return count;}}
下面逐步解释Union-Find算法类中的变量定义以及相关函数。
成员变量
可以看到该类中定义了三个成员变量,分别是int count、int[] parent以及int[] size。
int count:可以理解为连通分量的个数。
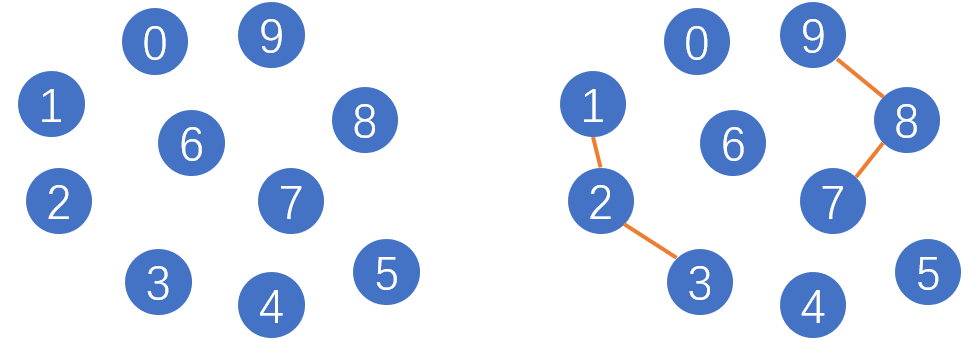
如上左图所示,共有10个节点(分量),此时连通分量的个数为10。如上右图所示,在进行连通操作(union)后,分量之间存在了连接关系(connected),因此此时的连通分量个数为6。
int[] parent:定义父节点数组。说到父节点数组,这里使用多棵树来表示连通性。规定树中的每个节点都有一个指针指向其父节点。一开始没有连通,此时每个节点指向父节点的指针都是指向自己,也就是根节点;当两个节点被连通,就让其中的任意一个节点的根节点接到另一个节点的根节点上,如下图所示。
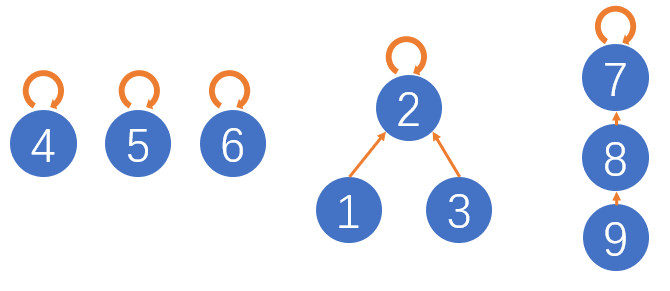
此时,可以得到:若节点p和节点q连通,那么它们一定有相同的根节点。
int[] size:记录每一棵树中节点的数量,称之为树的重量,以此方便对树的平衡性进行优化。如上张图所示,如果要把节点3和节点7连接(union),此时树的情况如下图所示:
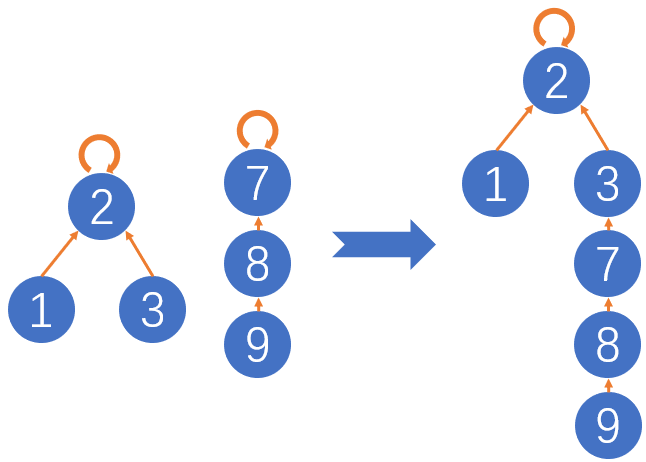
此时,可以看出,树的平衡性出现了问题,因此我们需要借助树的重量,即int[] size数组对节点的连接操作(union)进行平衡性优化。
构造函数
UnionFind类构造函数的参数为int n,即初始的节点数目,亦即初始连通分量的个数。在进行初始化操作时,主要是初始化父节点数组int[] parent以及每棵树中节点的数目数组int[] size。在初始情况下,每个节点的父节点都是自身,而每棵树中节点的个数都是1,因此构造函数如下:
public UnionFind(int count) {this.count = count;parent = new int[count];size = new int[count];for (int i = 0; i < count; i++) {parent[i] = i;size[i] = 1;}}
其他函数
在上面的介绍中,我们知道,在UnionFind类中最重要的操作就是连接(union)操作。然而,在将节点p和节点q连接时,需要把一个节点(假定为节点p)的指针指向另一个节点(假定为节点q)的父节点,因此,我们需要先实现一个int find(int x)函数来找到一个节点的父节点,如下所示:
public int find(int x) {while (parent[x] != x) {parent[x] = parent[parent[x]];x = parent[x];}return x;}
另外,实现boolean connected(int p, int q)函数判断节点p和节点q是否处于连接状态,如下:
public boolean connected(int p, int q) {int rootP = find(p);int rootQ = find(q);return rootP == rootQ;}
在实现int find(int x)函数和boolean connected(int p, int q)函数后,接下来要实现最关键的连接操作,即void union(int p, int q)函数,如下所示:
public void union(int p, int q) {// 如果节点p和q已经连接,直接返回if (connected(p,q)) return;// 找到节点p和节点q的根节点int rootP = find(p);int rootQ = find(q);// 根据size数组进行平衡化操作:小树接到大树下if (size[rootP] > size[rootQ]) {parent[rootQ] = rootP;size[rootP] += size[rootQ];} else {parent[rootP] = rootQ;size[rootQ] += size[rootP];}// 连接完成后,连通分量减一count--;}
最后,完成连通分量计数函数int count(),如下:
public int count() {return count;}
Union-Find算法应用
在介绍完并查集算法类UnionFind.class后,下面来看看该算法的应用。
朋友圈/好友关系问题
这个问题是并查集的一个典型应用,印象中猿辅导的算法手撕中这个题出现的频率比较高。问题描述如下:
班上有 N 名学生。其中有些人是朋友,有些则不是。他们的友谊具有是传递性。如果已知 A 是 B 的朋友,B 是 C 的朋友,那么我们可以认为 A 也是 C 的朋友。所谓的朋友圈,是指所有朋友的集合。
给定一个
N * N的矩阵 M,表示班级中学生之间的朋友关系。如果M[i][j]= 1,表示已知第 i 个和 j 个学生互为朋友关系,否则为不知道。你必须输出所有学生中的已知的朋友圈总数。输入输出示例如下:输入:
[[1,1,0],
[1,1,0],
[0,0,1]]输出:2
利用并查集来解决该问题(假设UnionFind.class已定义,下同),如下:
class Solution {public int findCircleNum(int[][] M) {int n = M.length;UnionFind uf = new UnionFind(n);for (int i = 0; i < n; i++) {for (int j = 0; j < n; j++) {if (M[i][j] == 1) uf.union(i, j);}}return uf.count();}}
岛屿数量
岛屿数量问题其实也是互联网大厂常问的题目之一,除了采用DFS来实现,并查集也可以用于解决这类问题。问题描述如下:
给你一个由 '1'(陆地)和 '0'(水)组成的的二维网格,请你计算网格中岛屿的数量。岛屿总是被水包围,并且每座岛屿只能由水平方向和/或竖直方向上相邻的陆地连接形成。此外,你可以假设该网格的四条边均被水包围。输入输出示例如下:
输入:grid = [
["1","1","1","1","0"],
["1","1","0","1","0"],
["1","1","0","0","0"],
["0","0","0","0","0"]
]输出:1
采用并查集方法解决:
class Solution {public int numIslands(char[][] grid) {int r = grid.length;if (r == 0) return 0;int c = grid[0].length;int size = r * c;// 方向数组(向下和向右的坐标偏移)int[][] directions = {{1, 0}, {0, 1}};// +1表示虚拟水域,认为网格四条边被水包围UnionFind uf = new UnionFind(size + 1);for (int i = 0; i < r; i++) {for (int j = 0; j < c; j++) {if (grid[i][j] == '1') {for (int[] direction : directions) {int newX = i + direction[0];int newY = j + direction[1];if (newX < r && newY < c && grid[newX][newY] == '1') {uf.union(c * i + j, c * newX + newY);}}} else {// 如果不是陆地,则所有水域与虚拟水域连接uf.union(c * i + j, size);}}}// 减去虚拟水域return uf.count() - 1;}}
等式方程的可满足性
题目描述如下:
给定一个由表示变量之间关系的字符串方程组成的数组,每个字符串方程
equations[i]的长度为 4,并采用两种不同形式之一:a==b或a!=b。在这里,a 和 b 是小写字母(不一定不同),表示单字母变量名。只有当可以将整数分配给变量名,以便满足所有给定的方程时才返回
true,否则返回false。 输入输出示例如下:输入:[ab, bc, a==c]
输出:true输入:[ab, b!=c, ca]
输出:false
采用并查集算法解决该问题,如下:
class Solution {public boolean equationsPossible(String[] equations) {// 可能出现的26个字母UnionFind uf = new UnionFind(26);// 将相等的字母进行连接for (String e : equations) {if (e.charAt(1) == '=') {char x = e.charAt(0);char y = e.charAt(3);uf.union(x - 'a', y - 'a');}}// 若已经成立的相等关系被打破就返回falsefor (String e : equations) {if (e.charAt(1) == '!') {char x = e.charAt(0);char y = e.charAt(3);if (uf.connected(x - 'a', y - 'a')) return false;}}return true;}}
Union-Find算法的简单总结
并查集算法主要是解决图中的动态连通性问题。对于类似岛屿数量的问题,注意在初始化并查集时做到+1来表示一个虚拟节点,同时对于其中的二维数组可以采用方向数组int[] directions = {{1, 0}, {0, 1}}来规范和简化代码。对于等式方程的可满足性,主要是利用了并查集算法的等价特点。
参考
labuladong在leetcode547的题解
并查集算法Union-Find的思想、实现以及应用的更多相关文章
- Union-Find 并查集算法
一.动态连通性(Dynamic Connectivity) Union-Find 算法(中文称并查集算法)是解决动态连通性(Dynamic Conectivity)问题的一种算法.动态连通性是计算机图 ...
- 第三十一篇 玩转数据结构——并查集(Union Find)
1.. 并查集的应用场景 查看"网络"中节点的连接状态,这里的网络是广义上的网络 数学中的集合类的实现 2.. 并查集所支持的操作 对于一组数据,并查集主要支持两种操作:合并两 ...
- 并查集(Union Find)的基本实现
概念 并查集是一种树形的数据结构,用来处理一些不交集的合并及查询问题.主要有两个操作: find:确定元素属于哪一个子集. union:将两个子集合并成同一个集合. 所以并查集能够解决网络中节点的连通 ...
- hdu 1232 畅通工程(并查集算法)
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=1232 畅通工程 Time Limit: 4000/2000 MS (Java/Others) M ...
- 并查集 (Union Find ) P - The Suspects
Severe acute respiratory syndrome (SARS), an atypical pneumonia of unknown aetiology, was recognized ...
- Union-Find(并查集): Quick union算法
Quick union算法 Quick union: Java implementation Quick union 性能分析 在最坏的情况下,quick-union的find root操作cost( ...
- Union-Find(并查集): Quick union improvements
Quick union improvements1: weighting 为了防止生成高的树,将smaller tree放在larger tree的下面(smaller 和larger是指number ...
- hdu 1213 How Many Tables(并查集算法)
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=1213 How Many Tables Time Limit: 2000/1000 MS (Java/O ...
- 【lazy标记得思想】HDU3635 详细学习并查集
部分内容摘自以下大佬的博客,感谢他们! http://blog.csdn.net/dm_vincent/article/details/7769159 http://blog.csdn.net/dm_ ...
随机推荐
- 不懂 ZooKeeper?没关系,这一篇给你讲的明明白白
本来想系统回顾下 ZooKeeper的,可是网上没找到一篇合自己胃口的文章,写的差不多的,感觉大部分都是基于<从Paxos到ZooKeeper 分布式一致性原理与实践>写的,所以自己读了一 ...
- Linux实战(11):配置PPPOE拨号
前言: 由于需要做网站数据的抓取,普通的固定代理会容易被封禁,所以我们就用PPPOE通过动态拨号换不同的IP地址来解决该问题,下面PPPOE设置的整个方法过程: 移除NetworkManager安装r ...
- php Zookeeper使用踩坑
用的是Zookeeper扩展,Php版本为7.2.17,下载地址: https://pecl.php.net/package/zookeeper 用的是0.6.4版本 创建节点官方给的示例如下: &l ...
- hystrix(8) 插件
上一节讲到HystrixCommand的执行流程. Hystrix内部将一些模块实现成了插件,并且提供了用户提供自己的实现,通过配置来替换插件.Hystrix提供了5个插件,分别为并发相关插件(Hys ...
- Powershell编程基础-004-for语句的使用
For循环在PowerShell中也称为For语句. 同其他编程语言类似 当指定条件的值为True时,此循环以代码块的形式执行语句,另,For后面接(;;)代表恒为真! 实例1:用于执行指定次数的语句 ...
- 【JAVA】HashMap源码阅读
目录 1.关键的几个static参数 2.内部类定义Node节点 3.成员变量 4.静态方法 5.HashMap的四个构造方法 6.put方法 7.扩容resize方法 8.get方法 9.remov ...
- 命令执行漏洞攻击&修复建议
应用程序有时需要调用一些执行系统命令的函数,如在PHP中,使用system.exec.shell_exec.passthru.popen.proc_popen等函数可以执行系统命令.当黑客能控制这些函 ...
- Ribbon源码分析(一)-- RestTemplate 以及自定义负载均衡算法
如果只是想看ribbon的自定义负载均衡配置,请查看: https://www.cnblogs.com/yangxiaohui227/p/13186004.html 注意: 1.RestTemplat ...
- Spring Boot 第三弹,一文带你了解日志如何配置?
前言 日志通常不会在需求阶段作为一个功能单独提出来,也不会在产品方案中看到它的细节.但是,这丝毫不影响它在任何一个系统中的重要的地位. 今天就来介绍一下Spring Boot中的日志如何配置. Spr ...
- 数论(8):min_25 筛(扩展埃氏筛)
min_25 筛介绍 我们考虑这样一个问题. \[ans=\sum_{i = 1}^nf(i)\\ \] 其中 \(1 \le n \le 10^{10}\) 其中 \(f(i)\) 是一个奇怪的函数 ...