SpringCloud Sleuth
1.定义
Sleuth(分布式请求链路跟踪):提供了一套完整的服务跟踪解决方案,也兼容zipkin。
参考网址:https://github.com/spring-cloud/spring-cloud-sleuth
2.项目开发
源代码:https://github.com/zhongyushi-git/cloud-sleuth.git
2.1环境搭建
这里需要下载zipkin的jar才能使用。
1)zipkin下载地址:https://dl.bintray.com/openzipkin/maven/io/zipkin/java/zipkin-server/2.12.9/zipkin-server-2.12.9-exec.jar
2)在下载的jar目录下执行命令
java -jar zipkin-server-2.12.9-exec.jar
看到下图说明配置成功
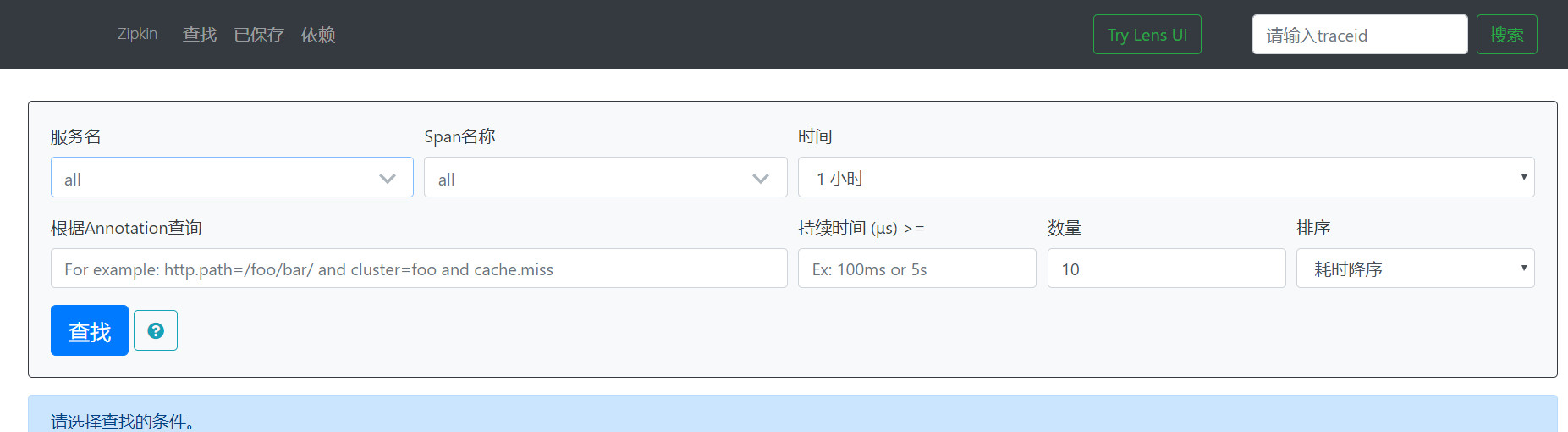
3)访问http://localhost:9411/zipkin/可看到相关的页面,主要用来查看请求的调用记录的。
2.2父工程搭建
创建一个maven的父工程cloud-sleuth,导入依赖
<!--统一管理jar包版本-->
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<junit.version>4.12</junit.version>
<log4j.version>1.2.17</log4j.version>
</properties>
<!-- 依赖管理,父工程锁定版本-->
<dependencyManagement>
<dependencies>
<!--spring boot 2.2.2-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-dependencies</artifactId>
<version>2.2.2.RELEASE</version>
<type>pom</type>
<scope>import</scope>
</dependency>
<!--spring cloud Hoxton.SR1-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>Hoxton.SR1</version>
<type>pom</type>
<scope>import</scope>
</dependency>
<!--junit-->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>${junit.version}</version>
</dependency>
<!--log4j-->
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>${log4j.version}</version>
</dependency>
</dependencies>
</dependencyManagement> <build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<configuration>
<fork>true</fork>
<addResources>true</addResources>
</configuration>
</plugin>
</plugins>
</build>
2.3注册服务eureka
1)创建一个子工程cloud-eureka-server7001,导入依赖
2)yml配置
server:
port: 7001 eureka:
instance:
#eureka服务端的实例名称
#单机版
hostname: localhost
client:
#false表示不向注册中心注册自己
register-with-eureka: false
#false表示自己端就是注册中心,我的职责就是维护服务实例,并不需要去检索服务
fetch-registry: false
service-url:
#设置与Eureka Server交互的地址查询服务和注册服务都需要依赖这个地址
#单机版
defaultZone: http://${eureka.instance.hostname}:${server.port}/eureka/
3)创建包com.zys.cloud,包下创建启动类
package com.zys.cloud; import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.netflix.eureka.server.EnableEurekaServer; @SpringBootApplication
@EnableEurekaServer
public class EurekaMain7001 {
public static void main(String[] args) {
SpringApplication.run(EurekaMain7001.class, args);
}
}
2.4服务提供者模块
1)创建一个子工程cloud-provider8001作为服务消费者,导入依赖
<dependencies>
<!--web-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
<!--eureka-client-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
</dependency>
<!--包含了sleuth+zipkin-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
</dependency>
</dependencies>
2)yml配置
server:
port: 8001 spring:
application:
name: cloud-provider
zipkin:
#监控地查看址
base-url: http://localhost:9411
sleuth:
sampler:
#采样率
probability: 1 #把客户端注册到服务列表中
eureka:
client:
#表示是否将自己注册进EurekaServer默认为true
register-with-eureka: true
#是否从EurekaServer抓取已有的注册信息,默认为true。单节点无所谓,集群必须设置为true才能配合ribbon使用负载均衡
fetch-registry: true
service-url:
#单机版
defaultZone: http://localhost:7001/eureka
#设置入驻的服务的名称,是唯一的
instance:
instance-id: cloud-provider
#访问路径显示ip
prefer-ip-address: true
里面主要是配置了ziplin的相关信息。
3)创建包com.zys.cloud,包下创建启动类
package com.zys.cloud; import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.client.discovery.EnableDiscoveryClient;
import org.springframework.cloud.netflix.eureka.EnableEurekaClient; @SpringBootApplication
@EnableEurekaClient
public class ProviderMain8001 {
public static void main(String[] args) {
SpringApplication.run(ProviderMain8001.class, args);
}
}
4)在包下新建controller接口
package com.zys.cloud.controller; import org.springframework.beans.factory.annotation.Value;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RestController; @RestController
public class UserController {
@Value("${server.port}")
private String port; @GetMapping("/user/get")
public String get() {
return "provider port is :" + port;
} }
2.5服务消费者模块
1)创建一个子工程cloud-provider8001作为服务消费者,导入依赖
<dependencies>
<!--web-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
<!--eureka-client-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
</dependency>
<!--包含了sleuth+zipkin-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
</dependency>
</dependencies>
2)yml配置
server:
port: 80 spring:
application:
name: cloud-consumer
zipkin:
#监控地查看址
base-url: http://localhost:9411
sleuth:
sampler:
#采样率
probability: 1 #把客户端注册到服务列表中
eureka:
client:
#表示是否将自己注册进EurekaServer默认为true
register-with-eureka: true
#是否从EurekaServer抓取已有的注册信息,默认为true。单节点无所谓,集群必须设置为true才能配合ribbon使用负载均衡
fetch-registry: true
service-url:
#单机版
defaultZone: http://localhost:7001/eureka
#设置入驻的服务的名称,是唯一的
instance:
instance-id: cloud-provider
#访问路径显示ip
prefer-ip-address: true
3)创建包com.zys.cloud,包下创建启动类
package com.zys.cloud; import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.netflix.eureka.EnableEurekaClient; @SpringBootApplication
@EnableEurekaClient
public class ConsumerMain80 {
public static void main(String[] args) {
SpringApplication.run(ConsumerMain80.class, args);
}
}
4)在包下新建config的配置类
package com.zys.cloud.config; import org.springframework.cloud.client.loadbalancer.LoadBalanced;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.web.client.RestTemplate; //相当于spring中的applicationContext.xml
@Configuration
public class ConfigBean { @Bean
@LoadBalanced
public RestTemplate getRestTemplate(){
return new RestTemplate();
}
}
5)在包下新建controller接口
package com.zys.cloud.controller; import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.*;
import org.springframework.web.client.RestTemplate; import java.util.Map; @RestController
@RequestMapping("/consumer")
public class UserController {
private final String BASE_URL="http://cloud-provider"; @Autowired
private RestTemplate restTemplate; @GetMapping("/get")
public String get(){
return restTemplate.getForObject(BASE_URL+"/user/get",String.class);
} }
2.6测试
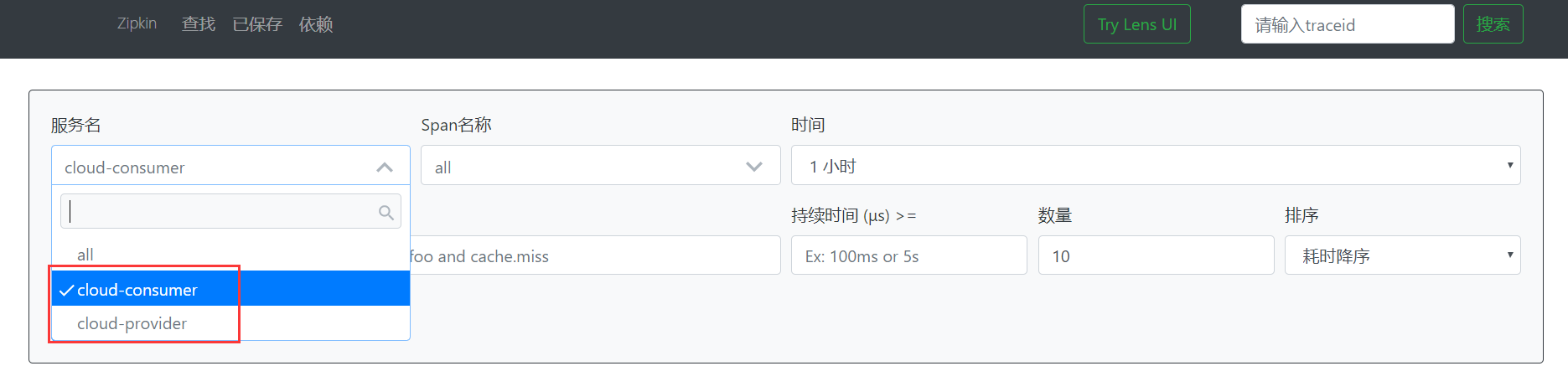
先启动7001,然后启动8001,最后启动80。访问http://localhost/consumer/get,然后再回到zipkin的页面,发现服务名多了两个,分别是设置的消费者和生产者。
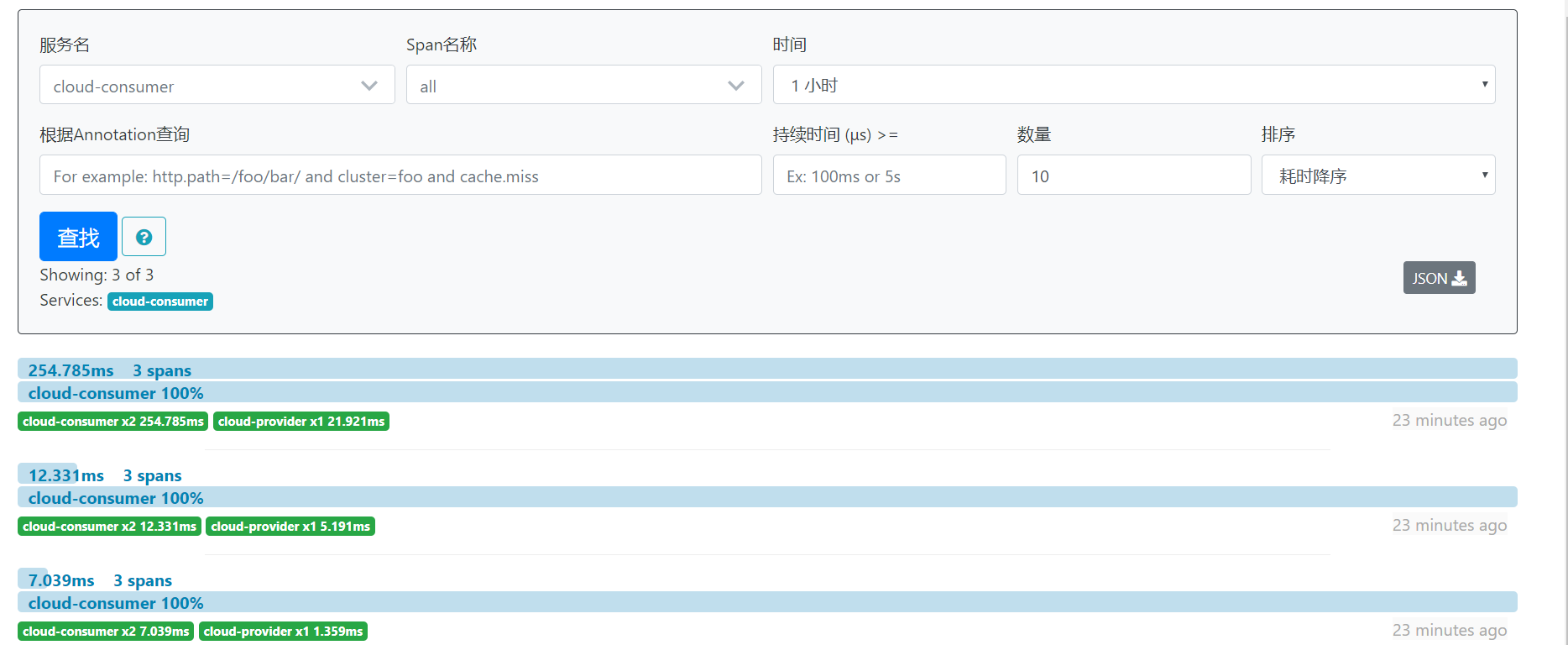
选择一个服务后点击查找,就会显示出链路信息
SpringCloud Sleuth的更多相关文章
- 新版本SpringCloud sleuth整合zipkin
SpringCloud Sleuth 简介 Spring Cloud Sleuth为Spring Cloud实现了分布式跟踪解决方案. Spring Cloud Sleuth借鉴了Dapper的术语. ...
- SpringCloud Sleuth + Zipkin 实现链路追踪
一.Sleuth介绍 为什么要使用微服务跟踪? 它解决了什么问题? 1.微服务的现状? 随着业务的发展,单体架构变为微服务架构,并且系统规模也变得越来越大,各微服务间的调用关系也变得越来越复杂 ...
- SpringCloud学习笔记(十、SpringCloud Sleuth)
目录: 什么是SpringCloud Sleuth 为什么使用SpringCloud Sleuth 如何使用SpringCloud Sleuth 什么是SpringCloud Sleuth: Spri ...
- springcloud -- sleuth+zipkin整合rabbitMQ详解
为什么使用RabbitMQ? 我们已经知道,zipkin的原理是服务之间的调用关系会通过HTTP方式上报到zipkin-server端,然后我们再通过zipkin-ui去调用查看追踪服务之间的调用链路 ...
- SpringCloud Sleuth 使用
1. 介绍 Spring-Cloud-Sleuth是Spring Cloud的组成部分之一,为SpringCloud应用实现了一种分布式追踪解决方案,其兼容了Zipkin, HTrace和log- ...
- SpringCloud Sleuth入门介绍
案例代码:https://github.com/q279583842q/springcloud-e-book 一.Sleuth介绍 为什么要使用微服务跟踪?它解决了什么问题? 1.微服务的现状? ...
- SpringCloud入门(十一):Sleuth 与 Zipkin分布式链路跟踪
现今业界分布式服务跟踪的理论基础主要来自于 Google 的一篇论文<Dapper, a Large-Scale Distributed Systems Tracing Infrastructu ...
- 学习一下 SpringCloud (五)-- 配置中心 Config、消息总线 Bus、链路追踪 Sleuth、配置中心 Nacos
(1) 相关博文地址: 学习一下 SpringCloud (一)-- 从单体架构到微服务架构.代码拆分(maven 聚合): https://www.cnblogs.com/l-y-h/p/14105 ...
- SpringCloud(八)Sleuth 分布式请求链路跟踪
SpringCloud Sleuth 分布式请求链路跟踪 概述 为什么会出现这个技术?需要解决哪些问题? 在微服务框架中,一个由客户端发起的请求在后端系统中会经过多个不同的的服务节点调用来协同产生最后 ...
随机推荐
- 武装你的WEBAPI-OData常见问题
本文属于OData系列 目录 武装你的WEBAPI-OData入门 武装你的WEBAPI-OData便捷查询 武装你的WEBAPI-OData分页查询 武装你的WEBAPI-OData资源更新Delt ...
- Redis集群搭建很easy
前言 哨兵模式虽然让读写分离更加高可用,但单台服务器由于本身的内存和CPU瓶颈,对于高并发和大数据业务的应用场景还是远远不能满足:对于这种情况,有点经验的小伙伴会毫不犹豫的想到集群,搞他好几个节点,负 ...
- 2019 Multi-University Training Contest 1 Path(最短路+最小割)
题意:给你n个点 m条边 现在你能够堵住一些路 问怎样能让花费最少且让1~n走的路比最短路的长度要长 思路:先跑一边最短路 建一个最短路图 然后我们跑一边最大流求一下最小割即可 #include &l ...
- Codeforces Round #633 (Div. 2)
Codeforces Round #633(Div.2) \(A.Filling\ Diamonds\) 答案就是构成的六边形数量+1 //#pragma GCC optimize("O3& ...
- VJ train1 O-统计问题 题解
原谅我缺少设备,只能手写图解 题目: 在一无限大的二维平面中,我们做如下假设: 1. 每次只能移动一格: 2. 不能向后走(假设 ...
- L2-013 红色警报 (25分) 并查集复杂度
代码: 1 /* 2 这道题也是简单并查集,并查集复杂度: 3 空间复杂度为O(N),建立一个集合的时间复杂度为O(1),N次合并M查找的时间复杂度为O(M Alpha(N)), 4 这里Alpha是 ...
- LianLianKan HDU - 4272 状压dp
题意:长度为n(n<=1000)的栈,栈顶元素可以与下面1~5个数中相同的元素消去,问最后能都完全消去. 题解: 比如这个序列12345678910112这个位置的最远可匹配位置能到11为什么呢 ...
- 功能按钮发post请求 参数放入body中
1.功能按钮事件参数 queryBody_ids:{data.ids} 前端会生成下划线后面的编码ids,并替换{data.ids} 2.后端建参数model后端参数可以只包含前端返回的部分参数 [D ...
- UWP(二)调用Win32程序
目录 一.如何构建Win32程序 二.如何构建UWP工程? 三.Samples 一.如何构建Win32程序 打开csproj文件,使用如下代码添加引用(Reference).注意,如果指定位置不存在, ...
- Django服务器布置(Ubuntu+uwsgi+nginx+Django)
一.安装Python apt install python3 二.安装pip apt install python3-pip 三.创建目录 创建虚拟服务目录 mkdir -p /data/env 创建 ...