synchronized的jvm源码分析聊锁的意义
上篇写完了ReentrantLock源码实现,从我们的角度分析设计锁,在对比大神的实现,顺道拍了一波道哥的马屁,虽然他看不到,哈哈。这一篇我们来聊一聊synchronized的源码实现,并对比reentrantLock的实现,相信认真看完一定会对锁的理解更加深入。
废话不多说先来一段代码:
static String s = new String();
static int a = 1; public static void main(String[] args) {
synchronized (s) {
a++;
}
}
我们一般写加锁也就这么写,为啥一个synchronized关键字就能做到加锁的效果呢,我们来看下这段代码main方法里的字节码:
0: getstatic #2 // Field s:Ljava/lang/String;
3: dup
4: astore_1
5: monitorenter
6: getstatic #3 // Field a:I
9: iconst_1
10: iadd
11: putstatic #3 // Field a:I
14: aload_1
15: monitorexit
16: goto 24
19: astore_2
20: aload_1
21: monitorexit
22: aload_2
23: athrow
24: return
我们主要看一下标红的几行,5,15,21,其中monitorenter是进入临界区的操作,monitorexit是退出临界区时的操作,而为啥又俩monitorexit,其中15行是正常退出的,而21行是异常退出的,毕竟我们之前写lock是放在finally中的,而这里当然也要通过手段保证退出临界区必须要释放锁。知道了synchronized其实就是monitorenter和monitorexit,我们还需要了解的就是对象头,这里我特意补了一篇对象头的介绍:https://www.cnblogs.com/gmt-hao/p/14151951.html,接下来的synchronized源码还是比较依赖对象头的理解的。
在翻看synchronized的源码时,找入口就花了我很长的时间,有的文章说是InterpreterRuntime::monitorenter方法,有的文章写的是bytecodeInterpreter.cpp里的CASE(_monitorenter)方法后来我发现后者里面其实是调用了前者的,所以倾向于后者看了下去,但是我下载的jdk8里面的代码是这样的:
CASE(_monitorenter): {
oop lockee = STACK_OBJECT(-1); //取到锁对象
// derefing's lockee ought to provoke implicit null check
CHECK_NULL(lockee); //判空
// find a free monitor or one already allocated for this object
// if we find a matching object then we need a new monitor
// since this is recursive enter
BasicObjectLock* limit = istate->monitor_base();
BasicObjectLock* most_recent = (BasicObjectLock*) istate->stack_base();
BasicObjectLock* entry = NULL;
while (most_recent != limit ) {
if (most_recent->obj() == NULL) entry = most_recent;
else if (most_recent->obj() == lockee) break;
most_recent++;
}
if (entry != NULL) {
entry->set_obj(lockee);
markOop displaced = lockee->mark()->set_unlocked(); //复制一份锁对象并将其设置为无锁状态
entry->lock()->set_displaced_header(displaced);
if (Atomic::cmpxchg_ptr(entry, lockee->mark_addr(), displaced) != displaced) {
// Is it simple recursive case?
if (THREAD->is_lock_owned((address) displaced->clear_lock_bits())) {
entry->lock()->set_displaced_header(NULL);
} else {
CALL_VM(InterpreterRuntime::monitorenter(THREAD, entry), handle_exception);
}
}
UPDATE_PC_AND_TOS_AND_CONTINUE(1, -1);
} else {
istate->set_msg(more_monitors);
UPDATE_PC_AND_RETURN(0); // Re-execute
}
}
对,就这么点就没了,网上也有很多文章是按照这个写的,这让我看的时候很困惑,而且这些文章关于偏向锁的解释我都感觉和代码对不上,有种硬生生强塞进去的感觉,我当时就很好奇,这种文章的作者自己真的理解了吗,写这些文章不怕误导读者吗。这里我要推荐一篇我觉得写的非常好的,我也从中借鉴了很多,看了这篇博客之后,很多之前没理通的逻辑都弄明白了,非常感谢,这里贴上链接:https://www.jianshu.com/p/4758852cbff4(找资料的过程中发现很多博客都是抄的这篇文章的),关于文章中写到的为什么jdk8的某版本及之前的版本里面代码无法解释偏向锁的问题,也是看了文章中推荐的R大的文章才算是有所理解,在此非常感谢这些真正传道授业解惑的人,也贴一下链接:https://book.douban.com/annotation/31407691/,我就不再赘述(主要是理解的比较浅显),希望想了解synchronized源码的小伙伴还是看一下上面提供的链接文章。
下面才是源码解析正式开始,由于bytecodeInterpreter.cpp中的CASE(_monitorenter)代码和真正模板解释器的汇编代码逻辑基本一致(主要是我太菜了看不懂),这里就用这里的实现来解释synchronized源码,贴上代码:
1.偏向锁的获取
CASE(_monitorenter): {
//获取锁对象
oop lockee = STACK_OBJECT(-1);//栈帧当中生成一个lock record 记录
BasicObjectLock* limit = istate->monitor_base();
BasicObjectLock* most_recent = (BasicObjectLock*) istate->stack_base();
BasicObjectLock* entry = NULL;
while (most_recent != limit ) {
if (most_recent->obj() == NULL) entry = most_recent;
else if (most_recent->obj() == lockee) break;
most_recent++;
}
if (entry != NULL) {
//将lock record中的obj指向锁对象
entry->set_obj(lockee);
int success = false;
uintptr_t epoch_mask_in_place = (uintptr_t)markOopDesc::epoch_mask_in_place;
//获取锁对象头信息
markOop mark = lockee->mark();
intptr_t hash = (intptr_t) markOopDesc::no_hash;
// implies UseBiasedLocking
//判断是否禁用偏向锁
if (mark->has_bias_pattern()) {
uintptr_t thread_ident;
uintptr_t anticipated_bias_locking_value;
//获取线程id
thread_ident = (uintptr_t)istate->thread();
//计算是否偏向自己
anticipated_bias_locking_value =
(((uintptr_t)lockee->klass()->prototype_header() | thread_ident) ^ (uintptr_t)mark) &
~((uintptr_t) markOopDesc::age_mask_in_place);
//1.判断是否偏向自己
if (anticipated_bias_locking_value == 0) {
// already biased towards this thread, nothing to do
if (PrintBiasedLockingStatistics) {
(* BiasedLocking::biased_lock_entry_count_addr())++;
}
success = true;
}
//2.判断是否可偏向,不可偏向则尝试撤销
else if ((anticipated_bias_locking_value & markOopDesc::biased_lock_mask_in_place) != 0) {
// 拿到锁对象的原型对象头
markOop header = lockee->klass()->prototype_header();
if (hash != markOopDesc::no_hash) {
header = header->copy_set_hash(hash);
}
//其实这里是将锁对象的mark word替换为没有偏向的,即撤销偏向
if (lockee->cas_set_mark(header, mark) == mark) {
if (PrintBiasedLockingStatistics)
(*BiasedLocking::revoked_lock_entry_count_addr())++;
}
}
//3.判断是否过期,即判断对象头中epoch是否不一致,若不一致则尝试重偏向
else if ((anticipated_bias_locking_value & epoch_mask_in_place) !=0) {
// try rebias
//基于lockee对象构造一个偏向当前线程的mark word
markOop new_header = (markOop) ( (intptr_t) lockee->klass()->prototype_header() | thread_ident);
if (hash != markOopDesc::no_hash) {
new_header = new_header->copy_set_hash(hash);
}
//cas替换mark word为上面偏向当前线程的
if (lockee->cas_set_mark(new_header, mark) == mark) {
if (PrintBiasedLockingStatistics)
(* BiasedLocking::rebiased_lock_entry_count_addr())++;
}
else { //替换失败则说明有多个线程同时竞争,锁升级
CALL_VM(InterpreterRuntime::monitorenter(THREAD, entry), handle_exception);
}
success = true;
}
else {//4.走到这里要么是偏向其他线程且没有过期的,要么就是匿名偏向(即没有保存线程信息)
// try to bias towards thread in case object is anonymously biased
//这里构造一个当前mark word的匿名偏向对象头
markOop header = (markOop) ((uintptr_t) mark & ((uintptr_t)markOopDesc::biased_lock_mask_in_place |
(uintptr_t)markOopDesc::age_mask_in_place |
epoch_mask_in_place));
if (hash != markOopDesc::no_hash) {
header = header->copy_set_hash(hash);
}
//这是将mark word偏向当前线程
markOop new_header = (markOop) ((uintptr_t) header | thread_ident);
// debugging hint
DEBUG_ONLY(entry->lock()->set_displaced_header((markOop) (uintptr_t) 0xdeaddead);)
//这里会尝试将偏向当前线程的mark word替换到锁对象中,
//若是匿名偏向则可以cas成功,若已经偏向其他线程,
//或有可能刚好被其他线程先修改了,都说明有多个线程竞争,
//则会cas失败
if (lockee->cas_set_mark(new_header, header) == header) {
if (PrintBiasedLockingStatistics)
(* BiasedLocking::anonymously_biased_lock_entry_count_addr())++;
}
else {//替换失败则说明有多个线程同时竞争,锁升级
CALL_VM(InterpreterRuntime::monitorenter(THREAD, entry), handle_exception);
}
success = true;
}
}
// traditional lightweight locking
if (!success) { //轻量锁,当偏向锁未开启或失败
//构造无锁mark word
markOop displaced = lockee->mark()->set_unlocked();
// 将上面构造的lock record指向该无锁mark word
entry->lock()->set_displaced_header(displaced);
bool call_vm = UseHeavyMonitors;
// 使用重量级锁或者轻量级锁加锁失败,结果都会导致使用重量级锁
//这里if条件不满足的话则说明轻量级锁加锁成功直接结束
if (call_vm || lockee->cas_set_mark((markOop)entry, displaced) != displaced) {
// Is it simple recursive case?
//锁重入
if (!call_vm && THREAD->is_lock_owned((address) displaced->clear_lock_bits())) {
entry->lock()->set_displaced_header(NULL);
} else { //锁升级
CALL_VM(InterpreterRuntime::monitorenter(THREAD, entry), handle_exception);
}
}
}
UPDATE_PC_AND_TOS_AND_CONTINUE(1, -1);
} else {
istate->set_msg(more_monitors);
UPDATE_PC_AND_RETURN(0); // Re-execute
}
}
上面的代码我都加了注释,基本逻辑应该是可以看的懂得,主要解释一下几个难以理解的点,这里我分别用红黄蓝三色标记了,下面一一解释:
红:这里的BasicObjectLock的定义在basicLock.hpp中:
class BasicObjectLock {
friend class VMStructs;
private:
BasicLock _lock; // the lock, must be double word aligned
oop _obj;
里面分别包含了一个BasicLock和一个oop对象,BasicLock的定义也在当前文件中:
class BasicLock {
friend class VMStructs;
friend class JVMCIVMStructs;
private:
volatile markOop _displaced_header;
public:
其实就是一个markOop对象头,也就是说BasicObjectLock其实就是一个对象本身和对象头的组合,也叫做lock record。
了解完这些我们再看代码,其实就是从当前调用方法栈的most_recent(栈底)搜索到limit(栈顶)遍历查找,直到找到一个空闲的或者之前就指向当前锁对象的lock record。
黄:黄色部分代码还是挺复杂的,首先看 (uintptr_t)lockee->klass()->prototype_header() | thread_ident) ,这个其实是那当前锁对象的class原型对象头和当前线程进行或运算(其实相当于对象头记录下当前线程信息),。
再看后面 ^ (uintptr_t)mark,其实就是那生成的偏向当前线程的mark word和当前锁对象的进行异或运算看两者的区别。
再看后面& ~((uintptr_t) markOopDesc::age_mask_in_place) ,~((uintptr_t) markOopDesc::age_mask_in_place) 这个是将拿到mark word为...00001111000取反后变为...11110000111,再和前面进行与运算,可以排除掉gc年龄的干扰,就可以将不同点集中到偏向线程、偏向状态以及锁状态上,如果上面代码中步骤1等于0成立则说明和锁对象一样,可以得出偏向自己,步骤2和偏向锁状态与运算不等于0说明偏向状态标志位为0,没有开启偏向模式,步骤3也一样,只是计算epoch值是否相等,可判断是否需要重偏向。
蓝:上面也提到了这块通过判断epoch值是否相同,但是原因我找过很多资料,最终发现有一篇问题下的一个回答说的比较好,附上链接:https://www.zhihu.com/question/56582060/answer/155398235 防止回答失效,原文摘抄了过来:
上面主要介绍了偏向锁的加锁和轻量锁的部分加锁流程,流程可参考下图:
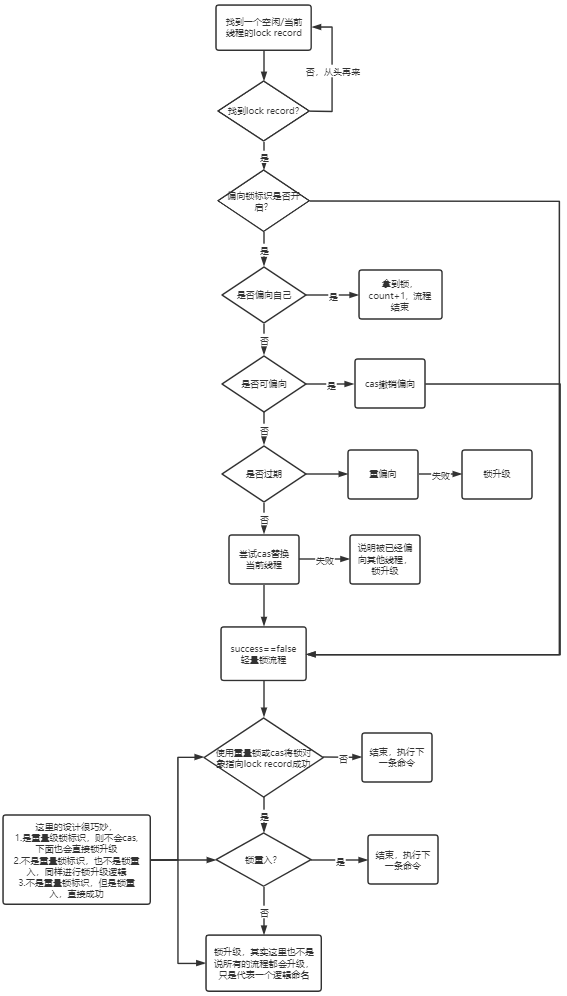
2.偏向锁批量撤销和重偏向
接下来主要是偏向锁撤销和重偏向流程,先看InterpreterRuntime::monitorenter代码:
IRT_ENTRY_NO_ASYNC(void, InterpreterRuntime::monitorenter(JavaThread* thread, BasicObjectLock* elem))if (PrintBiasedLockingStatistics) {
Atomic::inc(BiasedLocking::slow_path_entry_count_addr());
}
Handle h_obj(thread, elem->obj());
assert(Universe::heap()->is_in_reserved_or_null(h_obj()),
"must be NULL or an object");
if (UseBiasedLocking) { //开启偏向锁
// Retry fast entry if bias is revoked to avoid unnecessary inflation
ObjectSynchronizer::fast_enter(h_obj, elem->lock(), true, CHECK);
} else {
ObjectSynchronizer::slow_enter(h_obj, elem->lock(), CHECK);
}
这里主要就两个方法开启偏向锁时执行的fast_enter和未开启偏向锁执行的slow_enter,我们先看fast_enter方法:
void ObjectSynchronizer::fast_enter(Handle obj, BasicLock* lock,
bool attempBiasedLocking::revoke_and_rebiast_rebias, TRAPS) {
if (UseBiasedLocking) { //使用偏向锁
if (!SafepointSynchronize::is_at_safepoint()) { //不在安全点(安全点指所有java线程都停在安全点,只有vm线程运行)
BiasedLocking::Condition cond = BiasedLocking::revoke_and_rebias(obj, attempt_rebias, THREAD);
if (cond == BiasedLocking::BIAS_REVOKED_AND_REBIASED) {
return;
}
} else {
BiasedLocking::revoke_at_safepoint(obj);
}
assert(!obj->mark()->has_bias_pattern(), "biases should be revoked by now");
} slow_enter(obj, lock, THREAD);
}
这里再次判断了UseBiasedLocking,由于fast_enter方法里面也会执行slow_enter方法,个人感觉上一层的if-else是多余的,不过也有可能是为了可读性更强吧。
这里的is_at_safepoint我找了下源码里的解释,在safepoint.cpp文件里可以看到:
inline static bool is_at_safepoint() { return _state == _synchronized; }
enum SynchronizeState {
_not_synchronized = 0, // Threads not synchronized at a safepoint
// Keep this value 0. See the comment in do_call_back()
_synchronizing = 1, // Synchronizing in progress
_synchronized = 2 // All Java threads are stopped at a safepoint. Only VM thread is running
};
是否在安全点其实就是判断状态是不是_synchronized,而作者的解释就是:所有java线程在安全点暂停,只有vm线程处于运行态,而我在读revoke_and_rebias方法和revoke_at_safepoint方法源码发现区别主要是前者多了一些校验和cas操作,因此此处只写revoke_and_rebias的逻辑实现:
BiasedLocking::Condition BiasedLocking::revoke_and_rebias(Handle obj, bool attempt_rebias, TRAPS) {
assert(!SafepointSynchronize::is_at_safepoint(), "must not be called while at safepoint");
markOop mark = obj->mark(); //对象头
//是匿名偏向 && 重偏向标识为false 根据原文解释可以知道这里做的是当前锁对象hashcode计算会撤销偏向
if (mark->is_biased_anonymously() && !attempt_rebias) {
markOop biased_value = mark;
markOop unbiased_prototype = markOopDesc::prototype()->set_age(mark->age());
markOop res_mark = obj->cas_set_mark(unbiased_prototype, mark);
if (res_mark == biased_value) {
return BIAS_REVOKED;
}
} else if (mark->has_bias_pattern()) { //开启偏向模式
Klass* k = obj->klass();
markOop prototype_header = k->prototype_header();
//锁对象对应的class对象头关闭偏向,出现这种情况--看注释这种情况是由于批量撤销延迟,需要cas替换修复
if (!prototype_header->has_bias_pattern()) {
markOop biased_value = mark;
markOop res_mark = obj->cas_set_mark(prototype_header, mark);return BIAS_REVOKED;
} else if (prototype_header->bias_epoch() != mark->bias_epoch()) { //epoch过期
markOop biased_value = mark;
markOop rebiased_prototype = markOopDesc::encode((JavaThread*) THREAD, mark->age(), prototype_header->bias_epoch());
markOop res_mark = obj->cas_set_mark(rebiased_prototype, mark);
if (res_mark == biased_value) {
return BIAS_REVOKED_AND_REBIASED;
}
} else { //false,cas偏向撤销
markOop biased_value = mark;
markOop unbiased_prototype = markOopDesc::prototype()->set_age(mark->age());
markOop res_mark = obj->cas_set_mark(unbiased_prototype, mark);
if (res_mark == biased_value) {
return BIAS_REVOKED;
}
}
}
}
//这里是根据配置的允许撤销和重偏向次数与真实次数对比返回对应的标识,并在下面执行对应操作
//enum HeuristicsResult {
// HR_NOT_BIASED = 1, 不需要偏向
// HR_SINGLE_REVOKE = 2, 单个撤销
// HR_BULK_REBIAS = 3, 批量重偏向
// HR_BULK_REVOKE = 4 批量撤销
// };
HeuristicsResult heuristics = update_heuristics(obj(), attempt_rebias);
if (heuristics == HR_NOT_BIASED) {//未偏向直接返回
return NOT_BIASED;
} else if (heuristics == HR_SINGLE_REVOKE) { //执行单个撤销
Klass *k = obj->klass();
markOop prototype_header = k->prototype_header();
if (mark->biased_locker() == THREAD &&
prototype_header->bias_epoch() == mark->bias_epoch()) { //判断是线程自己并且epoch值没有过期,撤销及重偏向,直接执行撤销偏向
ResourceMark rm;
log_info(biasedlocking)("Revoking bias by walking my own stack:");
EventBiasedLockSelfRevocation event;
BiasedLocking::Condition cond = revoke_bias(obj(), false, false, (JavaThread*) THREAD, NULL);
((JavaThread*) THREAD)->set_cached_monitor_info(NULL);
assert(cond == BIAS_REVOKED, "why not?");
if (event.should_commit()) {
post_self_revocation_event(&event, k);
}
return cond;
} else { //走到这里说明是其他线程,则必须等到安全点时由vm线程执行
EventBiasedLockRevocation event;
VM_RevokeBias revoke(&obj, (JavaThread*) THREAD);
VMThread::execute(&revoke);
if (event.should_commit() && revoke.status_code() != NOT_BIASED) {
post_revocation_event(&event, k, &revoke);
}
return revoke.status_code();
}
}
EventBiasedLockClassRevocation event;
//批量撤销
VM_BulkRevokeBias bulk_revoke(&obj, (JavaThread*) THREAD,
(heuristics == HR_BULK_REBIAS),
attempt_rebias);
VMThread::execute(&bulk_revoke);return bulk_revoke.status_code();
}
这里我已经删了一部分注释和断言,但逻辑依旧感觉很复杂,流程上面代码写了注释,下面也会贴出流程图,这里主要解释几个重点:
1.撤销偏向先生成一个未偏向mark word,然后cas替换, 重偏向则是生成一个保存要替换的对象头的mark word,然后cas替换。
2.HeuristicsResult heuristics = update_heuristics(obj(), attempt_rebias); 详细分析:
static HeuristicsResult update_heuristics(oop o, bool allow_rebias) {
markOop mark = o->mark();
if (!mark->has_bias_pattern()) { //不可偏向直接返回
return HR_NOT_BIASED;
}
Klass* k = o->klass();
jlong cur_time = os::javaTimeMillis(); //当前时间
jlong last_bulk_revocation_time = k->last_biased_lock_bulk_revocation_time(); //上次批量撤销的时间
int revocation_count = k->biased_lock_revocation_count(); //撤销的次数(之前看到撤销的时候就会count++这里用上了)
//定义在globs.hpp,BiasedLockingBulkRebiasThreshold取值为20;BiasedLockingBulkRevokeThreshold取值为40,BiasedLockingDecayTime为25000毫秒
//这个if的逻辑还是比较简单的,其实就是在指定时间阈值到达后,重偏向次数达到但撤销未达到阈值,则执行默认的批量重偏向,并重置撤销count值
if ((revocation_count >= BiasedLockingBulkRebiasThreshold) && //1.重偏向次数达到阈值
(revocation_count < BiasedLockingBulkRevokeThreshold) && //2.撤销未到达阈值
(last_bulk_revocation_time != 0) && //这里主要是为了防止多个线程同时触发
(cur_time - last_bulk_revocation_time >= BiasedLockingDecayTime)) { //3.距上次批量撤销时间是否达到阈值
k->set_biased_lock_revocation_count(0);
revocation_count = 0;
}
// Make revocation count saturate just beyond BiasedLockingBulkRevokeThreshold
if (revocation_count <= BiasedLockingBulkRevokeThreshold) { //此次的count值也要加上
revocation_count = k->atomic_incr_biased_lock_revocation_count();
}
if (revocation_count == BiasedLockingBulkRevokeThreshold) { //达到批量撤销阈值,返回对应标识,后续会执行批量撤销
return HR_BULK_REVOKE;
}
if (revocation_count == BiasedLockingBulkRebiasThreshold) { //达到批量重偏向阈值,返回重偏向标识,后续会执行批量重偏向
return HR_BULK_REBIAS;
}
return HR_SINGLE_REVOKE;
}
其实就是根据配置的阈值和实际重偏向或撤销的次数比较,返回对应的标识枚举,并在后面的逻辑中做对应的处理(单个撤销、批量撤销、直接返回)。
3.无论是单个撤销执行的revoke_bias或者批量撤销执行的bulk_revoke其实最终执行的都是revoke_bias,后者也就是for循环处理了一下,所以这里只分析revoke_bias逻辑:
static BiasedLocking::Condition revoke_bias(oop obj, bool allow_rebias, bool is_bulk, JavaThread* requesting_thread, JavaThread** biased_locker) {
markOop mark = obj->mark();
if (!mark->has_bias_pattern()) { //没有开启偏向模式,直接返回NOT_BIASEDreturn BiasedLocking::NOT_BIASED;
}
uint age = mark->age();
markOop biased_prototype = markOopDesc::biased_locking_prototype()->set_age(age); //构造一个匿名偏向mark word
markOop unbiased_prototype = markOopDesc::prototype()->set_age(age); //构建一个关闭偏向的(无锁)mark word
JavaThread* biased_thread = mark->biased_locker();
if (biased_thread == NULL) { //看注释的意思是:匿名偏向对象,我们可能会因为在计算hashcode进入这一步
// Object is anonymously biased. We can get here if, for
// example, we revoke the bias due to an identity hash code
// being computed for an object.
if (!allow_rebias) { //不允许偏向,设为无锁mark word
obj->set_mark(unbiased_prototype);
}// Handle case where the thread toward which the object was biased has exited
bool thread_is_alive = false;
if (requesting_thread == biased_thread) { //当前线程和偏向线程一致
thread_is_alive = true;
} else { //不一致,jvm会保存一份存活线程list,这里找偏向线程,找不到false,找到为true
ThreadsListHandle tlh;
thread_is_alive = tlh.includes(biased_thread);
}
if (!thread_is_alive) { //偏向线程不存活,允许重偏向则设为匿名偏向,否则设为无锁
if (allow_rebias) {
obj->set_mark(biased_prototype);
} else {
obj->set_mark(unbiased_prototype);
}return BiasedLocking::BIAS_REVOKED;
}//走到这里线程还存活
GrowableArray<MonitorInfo*>* cached_monitor_info = get_or_compute_monitor_info(biased_thread);//根据偏向线程找到所有对象
BasicLock* highest_lock = NULL; //这个应该很熟悉了,上面介绍过,lock record中的对象头部分
//遍历找到的所有对象,找到当前对象(这块不知道理解的对不对)
for (int i = 0; i < cached_monitor_info->length(); i++) {
MonitorInfo* mon_info = cached_monitor_info->at(i);
if (oopDesc::equals(mon_info->owner(), obj)) {// Assume recursive case and fix up highest lock later
markOop mark = markOopDesc::encode((BasicLock*) NULL);
highest_lock = mon_info->lock();
highest_lock->set_displaced_header(mark);
} else {
}
}
if (highest_lock != NULL) { //这块偏向锁的理解还是有点问题,希望有大神可以指点指点
highest_lock->set_displaced_header(unbiased_prototype); //设置匿名偏向mark word
obj->release_set_mark(markOopDesc::encode(highest_lock));
} else { //说明已经不在临界区内if (allow_rebias) {
obj->set_mark(biased_prototype);
} else {
obj->set_mark(unbiased_prototype);
}
}
// If requested, return information on which thread held the bias
if (biased_locker != NULL) {
*biased_locker = biased_thread;
}
return BiasedLocking::BIAS_REVOKED;
}
这里主要做的就是判断是否需要撤销偏向,再根据是否在临界区内以及是否允许偏向分别指向匿名偏向或无锁mark word,这里可以看的出来,如果是轻量锁的话,撤销之后还要指向一个lock record来保存之前的mark word信息,具体流程图如下:
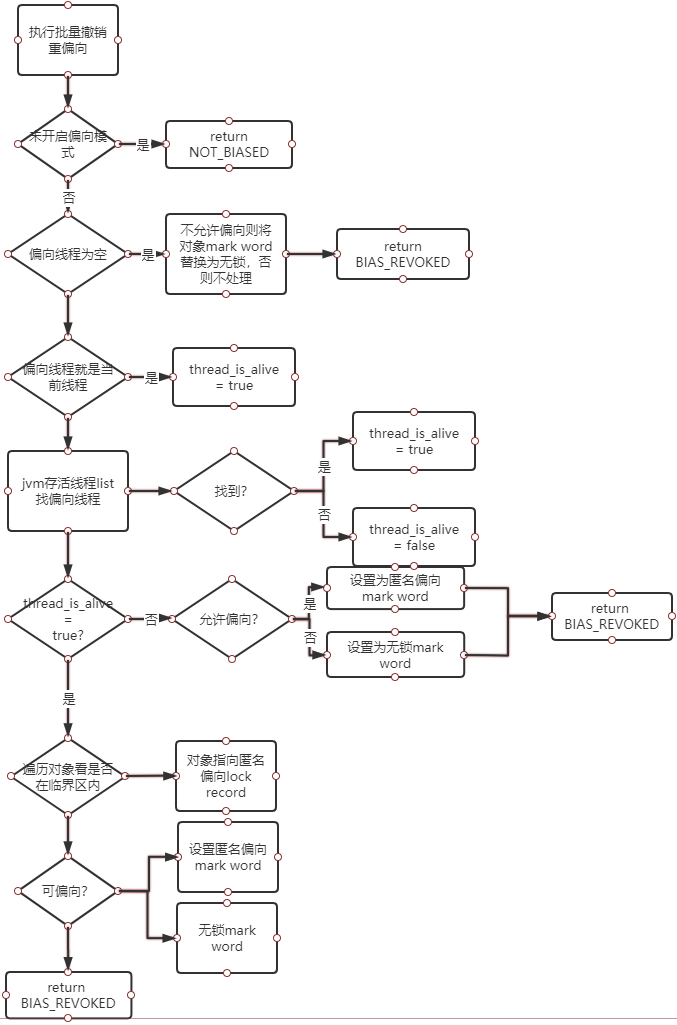
上面总的流程图如下:
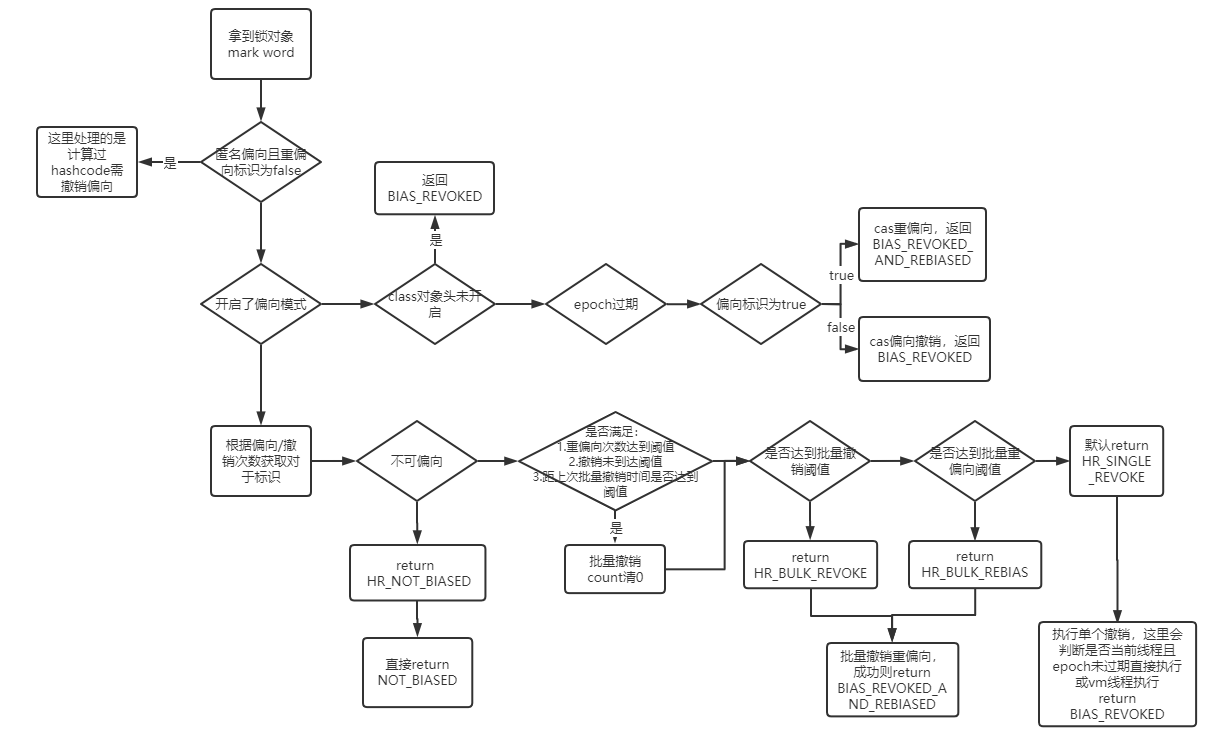
这张图不知道为什么试过很多方法,都是模糊的,这里给个链接吧:https://www.processon.com/view/link/6010043c079129045d3a376a
3.轻量级锁
其实上面讲完就快到重量级锁了,是不是突然发现轻量级锁没啥存在感,我也是写重量级锁写着写着发现轻量级锁没写,这里简单补一下吧,其实轻量级锁加锁主要存在三个地方:
1.上面第一部分最后 !success的流程
2.第二部分就是遍历对象monitor,然后设置lock record,但是具体的我理解的不太好,希望有大牛看到的话可以帮忙在评论区解释一下
3.slow_enter里面当mark->is_neutral()为true的时候,尝试加偏向锁,其实这里就可以看的出来,偏向锁其实就是将lock record(这个其实就是偏向锁进来的时候创建的entry,可以回头找一下)指向锁对象,然后cas将锁对象的mark word指向lock record,线程每次进来都会生成一个新的lock record,我相信看到这里应该已经有了一个关系图在脑子里了:

大致是这样的,虽有点粗糙,但大致能表达意思了,哈哈,偷个懒,等我重量级锁和锁释放写完,看有没有精力再来优化一波吧。
写重量锁的时候,发现有的状态看单词不太看得懂,如上面的mark->is_neutral()翻译是中立,这里解释一下,其实这里可以看markOop.hpp文件中有这么几个枚举:
enum { locked_value = 0, //00
unlocked_value = 1, //01
monitor_value = 2, //10
marked_value = 3, //11
biased_lock_pattern = 5 //101
};
光看0,1,2,3,5可能不太理解,但看后面的二进制数,000轻量锁,01无锁,10重量锁,11gc,101偏向锁,而像is_neutral方法其实就是判断是否是unlocked_value即无锁,其他以此类推。
4.重量级锁
qq重量级锁主要分为锁膨胀过程和加锁过程,首先看slow_enter方法:
void ObjectSynchronizer::slow_enter(Handle obj, BasicLock* lock, TRAPS) {
markOop mark = obj->mark();if (mark->is_neutral()) { //001 无锁状态,尝试cas指向lock record 轻量锁加锁,成功直接返回
lock->set_displaced_header(mark);
if (mark == obj()->cas_set_mark((markOop) lock, mark)) {
return;
}
// Fall through to inflate() ...
} else if (mark->has_locker() &&
THREAD->is_lock_owned((address)mark->locker())) { //轻量锁重入
assert(lock != mark->locker(), "must not re-lock the same lock");
assert(lock != (BasicLock*)obj->mark(), "don't relock with same BasicLock");
lock->set_displaced_header(NULL);
return;
}//这里设置一个不为0即不能看起来像重入标识,也不能看起来向持有锁的值
lock->set_displaced_header(markOopDesc::unused_mark());
//重量锁,inflate膨胀,enter真正加锁
ObjectSynchronizer::inflate(THREAD,
obj(),
inflate_cause_monitor_enter)->enter(THREAD);
}
这里做轻量级锁最后的挣扎,毕竟重量级锁就得进入内核态了,那消耗就大得多了。
接下来看膨胀流程:
ObjectMonitor* ObjectSynchronizer::inflate(Thread * Self,
oop object,
const InflateCause cause) { // Inflate mutates the heap ...
// Relaxing assertion for bug 6320749.
assert(Universe::verify_in_progress() ||
!SafepointSynchronize::is_at_safepoint(), "invariant"); EventJavaMonitorInflate event; for (;;) { //自旋
const markOop mark = object->mark();
assert(!mark->has_bias_pattern(), "invariant"); // The mark can be in one of the following states: //这里分为以下几种情况
// * Inflated - just return //膨胀完成,直接返回
// * Stack-locked - coerce it to inflated //轻量级加锁状态
// * INFLATING - busy wait for conversion to complete //膨胀中
// * Neutral - aggressively inflate the object. //无锁状态
// * BIASED - Illegal. We should never see this //偏向状态,不过在这里是非法的,不会出现 // CASE: inflated 直接返回
if (mark->has_monitor()) {
ObjectMonitor * inf = mark->monitor();
assert(inf->header()->is_neutral(), "invariant");
assert(oopDesc::equals((oop) inf->object(), object), "invariant");
assert(ObjectSynchronizer::verify_objmon_isinpool(inf), "monitor is invalid");
return inf;
} // CASE: inflation in progress - inflating over a stack-lock.//膨胀过程中,这里只会有一个线程完成膨胀,其他线程调用spin/yield/park函数等待
if (mark == markOopDesc::INFLATING()) {
ReadStableMark(object);
continue;
} // CASE: stack-locked
if (mark->has_locker()) { //轻量级锁加锁状态
ObjectMonitor * m = omAlloc(Self); //分配一个ObjectMonitor对象实例
m->Recycle();
m->_Responsible = NULL;
m->_recursions = 0;
m->_SpinDuration = ObjectMonitor::Knob_SpinLimit; // Consider: maintain by type/class markOop cmp = object->cas_set_mark(markOopDesc::INFLATING(), mark); //尝试设置为INFLATING状态,失败则继续下一轮自旋
if (cmp != mark) {
omRelease(Self, m, true);
continue; // Interference -- just retry
} markOop dmw = mark->displaced_mark_helper();
assert(dmw->is_neutral(), "invariant"); // Setup monitor fields to proper values -- prepare the monitor
m->set_header(dmw);
m->set_owner(mark->locker());
m->set_object(object);
guarantee(object->mark() == markOopDesc::INFLATING(), "invariant");
object->release_set_mark(markOopDesc::encode(m)); OM_PERFDATA_OP(Inflations, inc());
if (log_is_enabled(Debug, monitorinflation)) {
if (object->is_instance()) {
ResourceMark rm;
log_debug(monitorinflation)("Inflating object " INTPTR_FORMAT " , mark " INTPTR_FORMAT " , type %s",
p2i(object), p2i(object->mark()),
object->klass()->external_name());
}
}
if (event.should_commit()) {
post_monitor_inflate_event(&event, object, cause);
}
return m;
}
膨胀可能会出现的这几种状态:
// * Inflated - just return //膨胀完成,直接返回
// * Stack-locked - coerce it to inflated //轻量级加锁状态,
// * INFLATING - busy wait for conversion to complete //膨胀中
// * Neutral - aggressively inflate the object. //无锁状态
1.如果已经膨胀完成,则直接返回ObjectMonitor对象
2.如果当前状态为膨胀过程中,这里只会有一个线程去膨胀,其他线程调用spin/yield/park函数等待
3.如果当前处于轻量级锁加锁状态,
(1)首先分配一块给ObjectMonitor对象实例,然后cas设置mark word为INFLATING状态,值为0,只有这一种情况会将mark word设置为0(看解释是为了保证在膨胀过程中,防止其他线程来修改,同时也为了防止膨胀过程中解锁,无论哪种情况,都会等待膨胀完成)
(2)设置ObjectMonitor对象指向lock record
(3)设置锁对象指向mark word指向ObjectMonitor对象
4.如果当前处于无锁状态,和3差不多,但是不用设置INFLATING状态,我个人觉得是因为无锁状态能走到这里肯定是因为关闭了偏向锁和轻量锁,走到这的是第一个线程,能cas成功的也只有一个,如果失败了重试就可以,不会有影响。
最终成功都会设置为重量锁状态。
膨胀完就该到真正的重量锁加锁了:
重量级锁加锁真的是绕到我了,光顺着流程看代码压根理不清楚,废话不多说,先看为敬,看不懂的可以先去看看我前面的ReentrantLock源码分析:https://www.cnblogs.com/gmt-hao/p/14125742.html
void ObjectMonitor::enter(TRAPS) {
Thread * const Self = THREAD;
//null代表无锁状态,如果可以cas成功,则说明直接拿到锁了(加锁前先尝试拿锁,是不是和ReentrantLock似曾相识的感觉)
//这种情况一般是关闭偏向锁,轻量锁
void * cur = Atomic::cmpxchg(Self, &_owner, (void*)NULL);
if (cur == NULL) { //拿到锁直接返回
return;
}
if (cur == Self) { //是否线程重入
_recursions++;
return;
}
//这里是判断当前线程地址在不在当前栈内存区域,在的话则说明线程是之前持有过轻量级锁的,并且是第一次进入重量级锁,
//这里设计的很巧妙,第一次进入直接返回,不加锁(这里主要指的是不排队),和ReentrantLock很相似,ReentrantLock也是第一次不排队
if (Self->is_lock_owned ((address)cur)) {
_recursions = 1;
_owner = Self; //_owner指向当前获取到锁资源的线程
return;
}
Self->_Stalled = intptr_t(this);
if (TrySpin(Self) > 0) { //尝试一定次数的自旋,拿到锁直接返回
Self->_Stalled = 0;
return;
}
Atomic::inc(&_count);
JFR_ONLY(JfrConditionalFlushWithStacktrace<EventJavaMonitorEnter> flush(jt);)
EventJavaMonitorEnter event;
if (event.should_commit()) {
event.set_monitorClass(((oop)this->object())->klass());
event.set_address((uintptr_t)(this->object_addr()));
}
。。。
{
JavaThreadBlockedOnMonitorEnterState jtbmes(jt, this);
Self->set_current_pending_monitor(this);
。。。
for (;;) {
jt->set_suspend_equivalent();
。。。
EnterI(THREAD);
if (!ExitSuspendEquivalent(jt)) break;
_recursions = 0;
_succ = NULL;
exit(false, Self);
jt->java_suspend_self();
}
Self->set_current_pending_monitor(NULL);
。。。
}
去除掉七七八八不重要的代码如上,前面都是尽全力不进入等待队列,直接看下面EnterI(THREAD)方法:
void ObjectMonitor::EnterI(TRAPS) {
Thread * const Self = THREAD;
// Try the lock - TATAS
if (TryLock (Self) > 0) { //不死心再试一次
return;
}
if (TrySpin(Self) > 0) { //不死心再自旋一次
return;
}
//正式开始重量锁
ObjectWaiter node(Self);
Self->_ParkEvent->reset();
node._prev = (ObjectWaiter *) 0xBAD;
node.TState = ObjectWaiter::TS_CXQ;
ObjectWaiter * nxt;
for (;;) {
//自旋尝试将node节点插入cxq头部
node._next = nxt = _cxq;
if (Atomic::cmpxchg(&node, &_cxq, nxt) == nxt) break;
// Interference - the CAS failed because _cxq changed. Just retry.
// As an optional optimization we retry the lock.
//每次失败都会去尝试获取一下锁,看到这里再结合上面也知道,synchronized是非公平锁了
if (TryLock (Self) > 0) {return;
}
}
//这里可以结合ReentrantLock理解,就是当等待队列为空时,尝试设置为自己
if (nxt == NULL && _EntEnryList == NULL) {
Atomic::replace_if_null(Self, &_Responsible);
}
int nWakeups = 0;
int recheckInterval = 1;
for (;;) {
//一有机会就去尝试
if (TryLock(Self) > 0) break;
// park self
if (_Responsible == Self) { //如果等待队列为空,则只park自己一小段时间,过一会再次尝试
Self->_ParkEvent->park((jlong) recheckInterval);
// Increase the recheckInterval, but clamp the value.
recheckInterval *= 8;
if (recheckInterval > MAX_RECHECK_INTERVAL) {
recheckInterval = MAX_RECHECK_INTERVAL;
}
} else { //否则park住自己,等待唤醒
Self->_ParkEvent->park();
}
if (TryLock(Self) > 0) break;
if (_succ == Self) _succ = NULL;
// Invariant: after clearing _succ a thread *must* retry _owner before parking.
OrderAccess::fence();
}
这里的cxq队列其实相当于是ReentrantLock的阻塞队列,只不过reentrantLock会头节点唤醒下一个节点,这里是新线程塞入头部,唤醒尾部,可以看到,基本是一致的,其实只要理解了ReentrantLock,可以发现,synchronized的加锁和它基本是一样的,这里有一个 _EntEnryList干扰了我很久,后来慢慢找资料,发现其实和cxq是一样的,只不过为了防止并发过高(据网上很多资料统计是这么说的),会讲一些候选node放入_EntEnryList,其实道理是一样的,至于如何塞进去的,我们接着看wait,notify:
void ObjectMonitor::wait(jlong millis, bool interruptible, TRAPS) {
Thread * const Self = THREAD ;
JavaThread *jt = (JavaThread *)THREAD;
TEVENT (Wait) ;
。。。。
ObjectWaiter node(Self);
node.TState = ObjectWaiter::TS_WAIT ; //设置状态为TS_WAIT
Self->_ParkEvent->reset() ;
OrderAccess::fence(); // ST into Event; membar ; LD interrupted-flag
Thread::SpinAcquire (&_WaitSetLock, "WaitSet - add") ;
AddWaiter (&node) ; //主要看这里,将node放入等待队列
Thread::SpinRelease (&_WaitSetLock) ;
。。。。
int ret = OS_OK ;
int WasNotified = 0 ;
{ // State transition wrappers
OSThread* osthread = Self->osthread();
OSThreadWaitState osts(osthread, true);
{
ThreadBlockInVM tbivm(jt);
// Thread is in thread_blocked state and oop access is unsafe.
jt->set_suspend_equivalent();
if (interruptible && (Thread::is_interrupted(THREAD, false) || HAS_PENDING_EXCEPTION)) {
// Intentionally empty
} else
if (node._notified == 0) { //这里直接park住
if (millis <= 0) {
Self->_ParkEvent->park () ;
} else {
ret = Self->_ParkEvent->park (millis) ;
}
}
} // Exit thread safepoint: transition _thread_blocked -> _thread_in_vm
if (node.TState == ObjectWaiter::TS_WAIT) {
Thread::SpinAcquire (&_WaitSetLock, "WaitSet - unlink") ;
if (node.TState == ObjectWaiter::TS_WAIT) {
DequeueSpecificWaiter (&node) ; // unlink from WaitSet
assert(node._notified == 0, "invariant");
node.TState = ObjectWaiter::TS_RUN ;
}
Thread::SpinRelease (&_WaitSetLock) ;
}
guarantee (node.TState != ObjectWaiter::TS_WAIT, "invariant") ;
OrderAccess::loadload() ;
if (_succ == Self) _succ = NULL ;
WasNotified = node._notified ;
ObjectWaiter::TStates v = node.TState ;
if (v == ObjectWaiter::TS_RUN) {
//这里等到唤醒之后会重新进入抢锁
enter (Self) ;
} else {
guarantee (v == ObjectWaiter::TS_ENTER || v == ObjectWaiter::TS_CXQ, "invariant") ;
ReenterI (Self, &node) ;
node.wait_reenter_end(this);
}
} // OSThreadWaitState()
jt->set_current_waiting_monitor(NULL);
guarantee (_recursions == 0, "invariant") ;
_recursions = save; // restore the old recursion count
_waiters--; // decrement the number of waiters
if (SyncFlags & 32) {
OrderAccess::fence() ;
}
// check if the notification happened
if (!WasNotified) {
if (interruptible && Thread::is_interrupted(Self, true) && !HAS_PENDING_EXCEPTION) {
TEVENT (Wait - throw IEX from epilog) ;
THROW(vmSymbols::java_lang_InterruptedException());
}
}
}
其实这里一共就几步:1.加入waitSet队列 2.park住 3.等待notify之后,加入EntryList或者cxq队列,等待机会唤醒竞争锁(enter方法上面讲过)
这里加入waitSet队列其实跟ReentrantLock的Condition差不多,代码如下:
inline void ObjectMonitor::AddWaiter(ObjectWaiter* node) {
if (_WaitSet == NULL) {
_WaitSet = node;
node->_prev = node;
node->_next = node;
} else {
ObjectWaiter* head = _WaitSet;
ObjectWaiter* tail = head->_prev;
tail->_next = node;
head->_prev = node;
node->_next = head;
node->_prev = tail;
}
}
就是一个双端队列的头节点添加过程,我们接下来再看一下notify方法:
首先看jdk1.8的:
void ObjectMonitor::notify(TRAPS) {
CHECK_OWNER();
if (_WaitSet == NULL) {
TEVENT (Empty-Notify) ;
return ;
}
DTRACE_MONITOR_PROBE(notify, this, object(), THREAD);
int Policy = Knob_MoveNotifyee ;
Thread::SpinAcquire (&_WaitSetLock, "WaitSet - notify") ;
ObjectWaiter * iterator = DequeueWaiter() ;
if (iterator != NULL) {
if (Policy != 4) {
iterator->TState = ObjectWaiter::TS_ENTER ;
}
iterator->_notified = 1 ;
Thread * Self = THREAD;
iterator->_notifier_tid = Self->osthread()->thread_id();
ObjectWaiter * List = _EntryList ;
if (Policy == 0) { // prepend to EntryList
//看了很多网上的文章,对这块都没有解释,其实无论是否为空,都是放到EntryList的头部,这块判断只是jvm源码对于性能的追求而已
if (List == NULL) {
iterator->_next = iterator->_prev = NULL ;
_EntryList = iterator ;
} else {
List->_prev = iterator ;
iterator->_next = List ;
iterator->_prev = NULL ;
_EntryList = iterator ;
}
} else
if (Policy == 1) { // append to EntryList
//这里都是放到EntryList队尾
if (List == NULL) {
iterator->_next = iterator->_prev = NULL ;
_EntryList = iterator ;
} else {
// CONSIDER: finding the tail currently requires a linear-time walk of
// the EntryList. We can make tail access constant-time by converting to
// a CDLL instead of using our current DLL.
ObjectWaiter * Tail ;
for (Tail = List ; Tail->_next != NULL ; Tail = Tail->_next) ;
assert (Tail != NULL && Tail->_next == NULL, "invariant") ;
Tail->_next = iterator ;
iterator->_prev = Tail ;
iterator->_next = NULL ;
}
} else
if (Policy == 2) { // 放入cxq队首
// prepend to cxq
if (List == NULL) {
iterator->_next = iterator->_prev = NULL ;
_EntryList = iterator ;
} else {
iterator->TState = ObjectWaiter::TS_CXQ ;
for (;;) {
ObjectWaiter * Front = _cxq ;
iterator->_next = Front ;
if (Atomic::cmpxchg_ptr (iterator, &_cxq, Front) == Front) {
break ;
}
}
}
} else
if (Policy == 3) { // 放入cxq队尾
iterator->TState = ObjectWaiter::TS_CXQ ;
for (;;) {
ObjectWaiter * Tail ;
Tail = _cxq ;
if (Tail == NULL) {
iterator->_next = NULL ;
if (Atomic::cmpxchg_ptr (iterator, &_cxq, NULL) == NULL) {
break ;
}
} else {
while (Tail->_next != NULL) Tail = Tail->_next ;
Tail->_next = iterator ;
iterator->_prev = Tail ;
iterator->_next = NULL ;
break ;
}
}
} else {
ParkEvent * ev = iterator->_event ;
iterator->TState = ObjectWaiter::TS_RUN ;
OrderAccess::fence() ;
ev->unpark() ;
}
if (Policy < 4) {
iterator->wait_reenter_begin(this);
}
}
Thread::SpinRelease (&_WaitSetLock) ;
if (iterator != NULL && ObjectMonitor::_sync_Notifications != NULL) {
ObjectMonitor::_sync_Notifications->inc() ;
}
}
jdk1.8的比较复杂,具体情况主要根据Policy的值进行区分,0:放入EntryList头部,1.放到EntryList队尾 2.放到cxq队首, 3.放入cxq队尾,我猜这块估计就是为了处理高并发下的竞争,不同的状态代表有没有线程在竞争。
再看jdk12的:
void ObjectMonitor::INotify(Thread * Self) {
Thread::SpinAcquire(&_WaitSetLock, "WaitSet - notify");
ObjectWaiter * iterator = DequeueWaiter();
if (iterator != NULL) {
iterator->TState = ObjectWaiter::TS_ENTER;
iterator->_notified = 1;
iterator->_notifier_tid = JFR_THREAD_ID(Self);
ObjectWaiter * list = _EntryList;
if (list == NULL) {
iterator->_next = iterator->_prev = NULL;
_EntryList = iterator;
} else {
iterator->TState = ObjectWaiter::TS_CXQ;
for (;;) {
ObjectWaiter * front = _cxq;
iterator->_next = front;
if (Atomic::cmpxchg(iterator, &_cxq, front) == front) {
break;
}
}
}
iterator->wait_reenter_begin(this);
}
Thread::SpinRelease(&_WaitSetLock);
}
这代码量,完全不是一个数量级的,jdk12的只判断_EntryList是否为空来选择放入_cxq还是_EntryList,其实我个人觉得,要理解synchronized的话,这个就足够了。
总结:
总算是写完了加锁流程,先来总结一下吧,我们默认在开启偏向锁和轻量锁的情况下,当线程1进来时,首先会加上偏向锁,其实这里只是用一个状态来控制(就和aqs的思想比较类似),会记录枷锁的线程,如果重入,则不会进行锁升级,而当有多个线程交替进入(没有产生锁竞争),则会进行锁升级,撤销偏向锁,而当多次撤销同一个线程达到批量重偏向的阈值但没有达到批量撤销的阈值,则会进行批量重偏向,将轻量锁重新设置为偏向锁,并将撤销及重偏向计数清0。当有多个锁竞争时则会升级为重量级锁,重量级锁正常会进入一个cxq的队列,在调用wait方法之后,则会进入一个waitSet的队列park等待,而当调用notify方法唤醒之后,则有可能进入EntryList,其实这块只是synchronized对于并发竞争资源的处理,可以不用过多的关注。
看完这些是不是感觉和ReentrantLock差不多,其实两者的实现基本上是一致的,在重量级锁上最后都会park进入内核态,而对于并发竞争资源的处理,导致synchronized的效率可能会比ReentrantLock更高,但是我感觉这种提升微乎其微,但是这也支持了说synchronized效率更高的证据吧。
.tb_button { padding: 1px; cursor: pointer; border-right: 1px solid rgba(139, 139, 139, 1); border-left: 1px solid rgba(255, 255, 255, 1); border-bottom: 1px solid rgba(255, 255, 255, 1) }
.tb_button.hover { borer: 2px outset #def; background-color: rgba(248, 248, 248, 1) !important }
.ws_toolbar { z-index: 100000 }
.ws_toolbar .ws_tb_btn { cursor: pointer; border: 1px solid rgba(85, 85, 85, 1); padding: 3px }
.tb_highlight { background-color: rgba(255, 255, 0, 1) }
.tb_hide { visibility: hidden }
.ws_toolbar img { padding: 2px; margin: 0 }
.tb_button { padding: 1px; cursor: pointer; border-right: 1px solid rgba(139, 139, 139, 1); border-left: 1px solid rgba(255, 255, 255, 1); border-bottom: 1px solid rgba(255, 255, 255, 1) }
.tb_button.hover { borer: 2px outset #def; background-color: rgba(248, 248, 248, 1) !important }
.ws_toolbar { z-index: 100000 }
.ws_toolbar .ws_tb_btn { cursor: pointer; border: 1px solid rgba(85, 85, 85, 1); padding: 3px }
.tb_highlight { background-color: rgba(255, 255, 0, 1) }
.tb_hide { visibility: hidden }
.ws_toolbar img { padding: 2px; margin: 0 }
.tb_button { padding: 1px; cursor: pointer; border-right: 1px solid rgba(139, 139, 139, 1); border-left: 1px solid rgba(255, 255, 255, 1); border-bottom: 1px solid rgba(255, 255, 255, 1) }
.tb_button.hover { borer: 2px outset #def; background-color: rgba(248, 248, 248, 1) !important }
.ws_toolbar { z-index: 100000 }
.ws_toolbar .ws_tb_btn { cursor: pointer; border: 1px solid rgba(85, 85, 85, 1); padding: 3px }
.tb_highlight { background-color: rgba(255, 255, 0, 1) }
.tb_hide { visibility: hidden }
.ws_toolbar img { padding: 2px; margin: 0 }
.tb_button { padding: 1px; cursor: pointer; border-right: 1px solid rgba(139, 139, 139, 1); border-left: 1px solid rgba(255, 255, 255, 1); border-bottom: 1px solid rgba(255, 255, 255, 1) }
.tb_button.hover { borer: 2px outset #def; background-color: rgba(248, 248, 248, 1) !important }
.ws_toolbar { z-index: 100000 }
.ws_toolbar .ws_tb_btn { cursor: pointer; border: 1px solid rgba(85, 85, 85, 1); padding: 3px }
.tb_highlight { background-color: rgba(255, 255, 0, 1) }
.tb_hide { visibility: hidden }
.ws_toolbar img { padding: 2px; margin: 0 }
.tb_button { padding: 1px; cursor: pointer; border-right: 1px solid rgba(139, 139, 139, 1); border-left: 1px solid rgba(255, 255, 255, 1); border-bottom: 1px solid rgba(255, 255, 255, 1) }
.tb_button.hover { borer: 2px outset #def; background-color: rgba(248, 248, 248, 1) !important }
.ws_toolbar { z-index: 100000 }
.ws_toolbar .ws_tb_btn { cursor: pointer; border: 1px solid rgba(85, 85, 85, 1); padding: 3px }
.tb_highlight { background-color: rgba(255, 255, 0, 1) }
.tb_hide { visibility: hidden }
.ws_toolbar img { padding: 2px; margin: 0 }
.tb_button { padding: 1px; cursor: pointer; border-right: 1px solid rgba(139, 139, 139, 1); border-left: 1px solid rgba(255, 255, 255, 1); border-bottom: 1px solid rgba(255, 255, 255, 1) }
.tb_button.hover { borer: 2px outset #def; background-color: rgba(248, 248, 248, 1) !important }
.ws_toolbar { z-index: 100000 }
.ws_toolbar .ws_tb_btn { cursor: pointer; border: 1px solid rgba(85, 85, 85, 1); padding: 3px }
.tb_highlight { background-color: rgba(255, 255, 0, 1) }
.tb_hide { visibility: hidden }
.ws_toolbar img { padding: 2px; margin: 0 }
.tb_button { padding: 1px; cursor: pointer; border-right: 1px solid rgba(139, 139, 139, 1); border-left: 1px solid rgba(255, 255, 255, 1); border-bottom: 1px solid rgba(255, 255, 255, 1) }
.tb_button.hover { borer: 2px outset #def; background-color: rgba(248, 248, 248, 1) !important }
.ws_toolbar { z-index: 100000 }
.ws_toolbar .ws_tb_btn { cursor: pointer; border: 1px solid rgba(85, 85, 85, 1); padding: 3px }
.tb_highlight { background-color: rgba(255, 255, 0, 1) }
.tb_hide { visibility: hidden }
.ws_toolbar img { padding: 2px; margin: 0 }
.tb_button { padding: 1px; cursor: pointer; border-right: 1px solid rgba(139, 139, 139, 1); border-left: 1px solid rgba(255, 255, 255, 1); border-bottom: 1px solid rgba(255, 255, 255, 1) }
.tb_button.hover { borer: 2px outset #def; background-color: rgba(248, 248, 248, 1) !important }
.ws_toolbar { z-index: 100000 }
.ws_toolbar .ws_tb_btn { cursor: pointer; border: 1px solid rgba(85, 85, 85, 1); padding: 3px }
.tb_highlight { background-color: rgba(255, 255, 0, 1) }
.tb_hide { visibility: hidden }
.ws_toolbar img { padding: 2px; margin: 0 }
.tb_button { padding: 1px; cursor: pointer; border-right: 1px solid rgba(139, 139, 139, 1); border-left: 1px solid rgba(255, 255, 255, 1); border-bottom: 1px solid rgba(255, 255, 255, 1) }
.tb_button.hover { borer: 2px outset #def; background-color: rgba(248, 248, 248, 1) !important }
.ws_toolbar { z-index: 100000 }
.ws_toolbar .ws_tb_btn { cursor: pointer; border: 1px solid rgba(85, 85, 85, 1); padding: 3px }
.tb_highlight { background-color: rgba(255, 255, 0, 1) }
.tb_hide { visibility: hidden }
.ws_toolbar img { padding: 2px; margin: 0 }
synchronized的jvm源码分析聊锁的意义的更多相关文章
- JVM源码分析之synchronized实现
“365篇原创计划”第十二篇. 今天呢!灯塔君跟大家讲: JVM源码分析之synchronized实现 java内部锁synchronized的出现,为多线程的并发执行提供了一个稳定的 ...
- JVM源码分析之Java对象头实现
原创申明:本文由公众号[猿灯塔]原创,转载请说明出处标注 “365篇原创计划”第十一篇. 今天呢!灯塔君跟大家讲: JVM源码分析之Java对象头实现 HotSpot虚拟机中,对象在内存中的布局分为三 ...
- JVM源码分析之Object.wait/notify实现
“365篇原创计划”第十一篇. 今天呢!灯塔君跟大家讲: JVM源码分析之Object.wait/notify实现 最简单的东西,往往包含了最复杂的实现,因为需要为上层的存在提 ...
- JVM源码分析之堆外内存完全解读
JVM源码分析之堆外内存完全解读 寒泉子 2016-01-15 17:26:16 浏览6837 评论0 阿里技术协会 摘要: 概述 广义的堆外内存 说到堆外内存,那大家肯定想到堆内内存,这也是我们 ...
- JVM源码分析之SystemGC完全解读
JVM源码分析之SystemGC完全解读 概述 JVM的GC一般情况下是JVM本身根据一定的条件触发的,不过我们还是可以做一些人为的触发,比如通过jvmti做强制GC,通过System.gc触发,还可 ...
- JVM源码分析之一个Java进程究竟能创建多少线程
JVM源码分析之一个Java进程究竟能创建多少线程 原创: 寒泉子 你假笨 2016-12-06 概述 虽然这篇文章的标题打着JVM源码分析的旗号,不过本文不仅仅从JVM源码角度来分析,更多的来自于L ...
- JVM源码分析之Metaspace解密
概述 metaspace,顾名思义,元数据空间,专门用来存元数据的,它是jdk8里特有的数据结构用来替代perm,这块空间很有自己的特点,前段时间公司这块的问题太多了,主要是因为升级了中间件所 ...
- JVM源码分析-JVM源码编译与调试
要分析JVM的源码,结合资料直接阅读是一种方式,但是遇到一些想不通的场景,必须要结合调试,查看执行路径以及参数具体的值,才能搞得明白.所以我们先来把JVM的源码进行编译,并能够使用GDB进行调试. 编 ...
- JVM源码分析之警惕存在内存泄漏风险的FinalReference(增强版)
概述 JAVA对象引用体系除了强引用之外,出于对性能.可扩展性等方面考虑还特地实现了四种其他引用:SoftReference.WeakReference.PhantomReference.FinalR ...
随机推荐
- linux目录和Windows目录对比
linux目录和Windows目录对比 我们应该知道 Windows 有一个默认的安装目录专门用来安装软件.Linux 的软件安装目录也应该是有讲究的,遵循这一点,对后期的管理和维护也是有帮助的. / ...
- php + redis 实现关注功能
产品价值 1: 关注功能 2: 功能分析之"关注"功能 3: 平平无奇的「关注」功能,背后有4点重大价值 应用场景 在做PC或者APP端时,掺杂点社交概念就有关注和粉丝功能; 数据 ...
- three.js WebGLRenderTarget
今天郭先生说一说WebGLRenderTarget,它是一个缓冲,就是在这个缓冲中,视频卡为正在后台渲染的场景绘制像素. 它用于不同的效果,例如把它做为贴图使用或者图像后期处理.线案例请点击博客原文. ...
- IntelliJ IDEA无法新建类解决办法
IntelliJ IDEA无法新建类解决办法 灿夏 2018-07-14 08:50:05 4891 收藏 1 展开 原文地址 IntelliJ IDEA使用教程 (总目录篇) [原文地址](ht ...
- java代理(静态代理和jdk动态代理以及cglib代理)
版权声明:本文为Fighter168原创文章,未经允许不得转载. 目录(?)[+] 说到代理,脑袋中浮现一大堆代理相关的名词,代理模式,静态代理,jdk代理,cglib代理等等. 记忆特别深刻 ...
- IDEA和eclips工具对比
描述 eclipse idea 在当前类查找方法 ctrl+o ctrl+F12 查找文件 ctrl+shift+N 大小写转换 ctrl+shift+X ctrl+shift+Y ctrl ...
- Java Hash表 数据结构
思考: 数组由于内存地址连续,是一种查询快增删慢的数据结构: 链表由于内存地址不连续,是一种查询慢增删快的数据结构: 那么怎么实现查询又快,增删也快的数据结构呢? 要是把数组和链表结合起来会怎么样? ...
- 任意文件上传——tcp
package chaoba; import java.io.BufferedReader; import java.io.File; import java.io.FileInputStream; ...
- 源码编译搭建LNMP环境
LNMP源码编译 1.LNMP介绍 LNMP=Linux Nginx Mysql PHP Nginx ("engine x") 是一个高性能的 HTTP 和 反向代理 服务器.Ng ...
- ABP框架中短信发送处理,包括阿里云短信和普通短信商的短信发送集成
在一般的系统中,往往也有短信模块的需求,如动态密码的登录,系统密码的找回,以及为了获取用户手机号码的短信确认等等,在ABP框架中,本身提供了对邮件.短信的基础支持,那么只需要根据自己的情况实现对应的接 ...