网络安全传输系统-sprint2线程池技术优化
part1:线程池工作原理
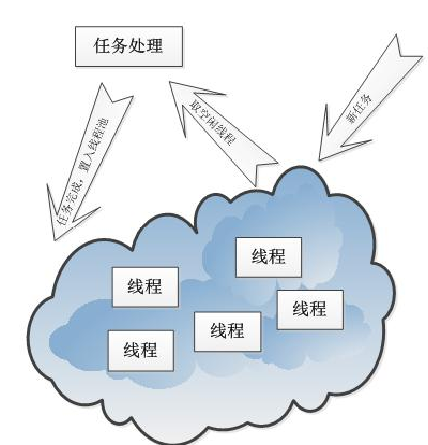
为满足多客户端可同时登陆的要求,服务器端必须实现并发工作方式。当服务器主进程持续等待客户端连接时,每连接上一个客户端都需一个单独的进程或线程处理客户端的任务。但考虑到多进程对系统资源消耗大,单一线程存在重复创建、销毁等动作产生过多的调度开销,故采用线性池的方法。
线程池是移植多线程并发的处理方式,由一堆已创建好的线程组成。有新任务 -> 取出空闲线程处理任务 -> 任务处理完成放入线程池等待。
优点:避免了处理短时间任务时大量的线程重复创建、销毁的代价,非常适用于连续产生大量并发任务的场合。
part2:线程池实现原理过程
(1)、初始设置任务队列(链表)作为缓冲机制,并初始化创建n个线程,加锁去任务队列取任务运行(多线程互斥);
(2)、在处理任务过程中,当任务队列为空时,所有线程阻塞(阻塞IO)处于空闲(wait)状态;
(3)、当任务队列加入新的任务时,队列加锁,然后使用条件变量唤醒(work)处于阻塞中的某一线程来执行任务;
(4)、执行完后再次返回线程池中成为空闲(wait)状态,依序或等待执行下一个任务;
最后完成所有任务将线程池中的线程统一销毁。
main主函数下:
//1、初始化线程池
pool_init();
// 等待连接
while ()
{
new_fd = accept(sockfd, (struct sockaddr*)(&client_addr), &sin_size);
//2.执行process,将process任务交给线程池
pool_add_task(process, new_fd);
} void pool_init(int max_thread_num)
{
pool = (Cthread_pool*)malloc(sizeof(Cthread_pool));//空间申请
pthread_mutex_init(&(pool->queue_lock), NULL);
/*初始化条件变量*/
pthread_cond_init(&(pool->queue_ready), NULL);
pool->queue_head = NULL;
pool->max_thread_num = max_thread_num;
pool->cur_task_size = ;
pool->shutdown = ;
//申请堆空间
pool->threadid = (pthread_t*)malloc(max_thread_num * sizeof(pthread_t));
for (i = ; i < max_thread_num; i++) //
{ //创建n个线程 保存线程id
pthread_create(&(pool->threadid[i]), NULL, thread_routine, NULL);
}
}
void* thread_routine(void* arg)
{
while ()
{
pthread_mutex_lock(&(pool->queue_lock)); //锁互斥锁
while (pool->cur_task_size == && !pool->shutdown)
{ //1.当前没有任务,且线程池处于非关闭
printf ("thread 0x%x is waiting\n", pthread_self ());
//等待条件成熟函数->线程等待
pthread_cond_wait (&(pool->queue_ready), &(pool->queue_lock));
}
if (pool->shutdown) /*2.线程池要销毁了*/
{ /*遇到break,continue,return等跳转语句,千万不要忘记先解锁*/
pthread_mutex_unlock(&(pool->queue_lock)); //解互斥锁
printf ("thread 0x%x will exit\n", pthread_self ());
pthread_exit (NULL); //线程退出函数
}
/*待处理任务减1,并取出链表中的头元素*/
//3.处理任务
pool->cur_task_size--; //等待任务-1
Cthread_task *task = pool->queue_head; //取第一个任务处理
pool->queue_head = task->next; //链表头指向下一个任务
pthread_mutex_unlock (&(pool->queue_lock)); //解互斥锁 /*调用回调函数,执行任务*/
(*(task->process)) (task->arg);
free(task);
task = NULL;
} pthread_exit(NULL);
}
int pool_add_task(void* (*process) (int arg), int arg)
{
/*构造一个新任务 初始化*/
Cthread_task* task = (Cthread_task*)malloc(sizeof(Cthread_task));
task->process = process;
task->arg = arg;
task->next = NULL;
pthread_mutex_lock(&(pool->queue_lock));
~~~~~~
pthread_mutex_unlock(&(pool->queue_lock));
pthread_cond_signal(&(pool->queue_ready)); //条件成熟函数->唤醒线程
return ;
} void* process(int arg) //读取操作符,读取对应的命令响应
{
if (cmd == 'Q')
{ /*关闭SSL*/
SSL_shutdown(ssl);
SSL_free(ssl);
close(tmp_fd);
break;
}
else
handle(cmd, ssl);
}
网络安全传输系统-sprint2线程池技术优化的更多相关文章
- 阶段3-团队合作\项目-网络安全传输系统\sprint2-线程池技术优化
之前问题的存在,之前只是用一个客户端在与服务器进行连接,当多个客户端进行连接的时候会连接不上处于等待状态,说明以前我们的服务器只能同时处理一个请求,故需要修改 服务器: 单发:初始化--等待客户端连接 ...
- 用 ThreadPoolExecutor/ThreadPoolTaskExecutor 线程池技术提高系统吞吐量(附带线程池参数详解和使用注意事项)
1.概述 在Java中,我们一般通过集成Thread类和实现Runnnable接口,调用线程的start()方法实现线程的启动.但如果并发的数量很多,而且每个线程都是执行很短的时间便结束了,那样频繁的 ...
- 基于线程池技术的web服务器
前言:首先简单模拟一个场景,前端有一个输入框,有一个按钮,点击这个按钮可以实现搜索输入框中的相关的文本和图片(类似于百度.谷歌搜索).看似一个简单的功能,后端处理也不难,前端发起一个请求,后端接受到这 ...
- java线程池技术(二): 核心ThreadPoolExecutor介绍
版权声明:本文出自汪磊的博客,转载请务必注明出处. Java线程池技术属于比较"古老"而又比较基础的技术了,本篇博客主要作用是个人技术梳理,没什么新玩意. 一.Java线程池技术的 ...
- Java基础-Java中的并法库之线程池技术
Java基础-Java中的并法库之线程池技术 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.什么是线程池技术 二.
- 基于SmartThreadPool线程池技术实现多任务批量处理
一.多线程技术应用场景介绍 本期同样带给大家分享的是阿笨在实际工作中遇到的真实业务场景,请跟随阿笨的视角去如何采用基于开源组件SmartThreadPool线程池技术实现多任务批量处理.在工作中您是否 ...
- java线程池技术
1.线程池的实现原理?简介: 多线程技术主要解决处理器单元内多个线程执行的问题,它可以显著减少处理器单元的闲置时间,增加处理器单元的吞吐能力.假设一个服务器完成一项任务所需时间为:T1 创建线程时间, ...
- 你真的懂ThreadPoolExecutor线程池技术吗?看了源码你会有全新的认识
Java是一门多线程的语言,基本上生产环境的Java项目都离不开多线程.而线程则是其中最重要的系统资源之一,如果这个资源利用得不好,很容易导致程序低效率,甚至是出问题. 有以下场景,有个电话拨打系统, ...
- Java线程池技术以及实现
对于服务端而言,经常面对的是客户端传入的短小任务,需要服务端快速处理并返回结果.如果服务端每次接受一个客户端请求都创建一个线程然后处理请求返回数据,这在请求客户端数量少的阶段看起来是一个不错的选择,但 ...
随机推荐
- 解决IOS端微信浏览器input,textarea有内上边框阴影
box-shadow:0px 0px 0px rgba(0,0,0,0); -webkit-appearance:none;
- pip install scrapy报错:error: Unable to find vcvarsall.bat解决方法
今天在使用pip install scrapy 命令安装Scrapy爬虫框架时,出现了很让人头疼的错误,错误截图如下: 在网上查找解决方法时,大致知道了问题的原因.是因为缺少C语言的编译环境,其中一种 ...
- python 装饰器(五):装饰器实例(二)类装饰器(类装饰器装饰函数)
回到装饰器上的概念上来,装饰器要求接受一个callable对象,并返回一个callable对象(不太严谨,详见后文). 那么用类来实现也是也可以的.我们可以让类的构造函数__init__()接受一个函 ...
- python利用difflib判断两个字符串的相似度
我们再工作中可能会遇到需要判断两个字符串有多少相似度的情况(比如抓取页面内容存入数据库,如果相似度大于70%则判定为同一片文章,则不录入数据库) 那这个时候,我们应该怎么判断呢? 不要着急,pytho ...
- Crystal Reports --报表设计
完整的报表解决方案 数据访问—>报表设计—>报表管理—>与应用系统集成 一.规划报表 设计报表的准备工作 谁看报表? 报表的数据是什么?(页眉页脚的内容?是否需要分组?是否需要汇总? ...
- Ethical Hacking - NETWORK PENETRATION TESTING(8)
WEP Cracking Basic case Run airdump-ng to log all traffic from the target network. airodump-ng --cha ...
- 【Python学习笔记三】一个简单的python爬虫
这里写爬虫用的requests插件 1.一般那3.x版本的python安装后都带有相应的安装文件,目录在python安装目录的Scripts中,如下: 2.将scripts的目录配置到环境变量pa ...
- 013.Nginx动静分离
一 动静分离概述 1.1 动静分离介绍 为了提高网站的响应速度,减轻程序服务器(Tomcat,Jboss等)的负载,对于静态资源,如图片.js.css等文件,可以在反向代理服务器中进行缓存,这样浏览器 ...
- selenium自动爬取网易易盾的验证码
我们在爬虫过程中难免会遇到一些拦路虎,比如各种各样的验证码,时不时蹦出来,这时候我们需要去识别它来继续我们的工作,接下来我将爬取网一些滑动验证码,然后通过百度的EasyDL平台进行数据标注,创建模型, ...
- 一起学Blazor WebAssembly 开发(1)
最近blazor的WebAssembly 正式版出来了,正好手头有一个项目采用的前后端分离模式做的,后端用的abp vnext(.net core 的一个很著名的框架)框架开发的,其实前端之前考虑的使 ...