运用sklearn进行线性判别分析(LDA)代码实现
基于sklearn的线性判别分析(LDA)代码实现
一、前言及回顾
本文记录使用sklearn库实现有监督的数据降维技术——线性判别分析(LDA)。在上一篇LDA线性判别分析原理及python应用(葡萄酒案例分析),我们通过详细的步骤理解LDA内部逻辑实现原理,能够更好地掌握线性判别分析的内部机制。当然,在以后项目数据处理,我们有更高效的实现方法,这篇将记录学习基于sklearn进行LDA数据降维,提高编码速度,而且会感觉更加简单。
LDA详细介绍与各步骤实现请看上回:LDA线性判别分析原理及python应用(葡萄酒案例分析)。
学习之后可以对数据降维处理两种实现方法进行对比:
- 无监督的PCA技术:主成分分析PCA数据降维原理及python应用(葡萄酒案例分析)
- 有监督的LDA技术:LDA线性判别分析原理及python应用(葡萄酒案例分析)
二、定义分类结果可视化函数
这个函数与上一篇文章 运用sklearn进行主成分分析(PCA)代码实现 里是一样的,plot_decision_region函数在分类结果区别决策区域中可以复用。
def plot_decision_regions(x, y, classifier, resolution=0.02):
markers = ['s', 'x', 'o', '^', 'v']
colors = ['r', 'g', 'b', 'gray', 'cyan']
cmap = ListedColormap(colors[:len(np.unique(y))]) x1_min, x1_max = x[:, 0].min() - 1, x[:, 0].max() + 1
x2_min, x2_max = x[:, 1].min() - 1, x[:, 1].max() + 1
xx1, xx2 = np.meshgrid(np.arange(x1_min, x1_max, resolution), np.arange(x2_min, x2_max, resolution))
z = classifier.predict(np.array([xx1.ravel(), xx2.ravel()]).T)
z = z.reshape(xx1.shape)
plt.contourf(xx1, xx2, z, alpha=0.4, cmap=cmap) for idx, cc in enumerate(np.unique(y)):
plt.scatter(x=x[y == cc, 0],
y=x[y == cc, 1],
alpha=0.6,
c=cmap(idx),
edgecolor='black',
marker=markers[idx],
label=cc)
三、10行代码实现葡萄酒数据集分类
sklearn依然实现了LDA类方法,我们只需要直接调用而无需自己实现内部逻辑,这样显得更加方便。所以,10行代码实现也不为过,重点需要先理解内部逻辑原理。
关键代码如下:
lda = LDA(n_components=2)
lr = LogisticRegression()
x_train_lda = lda.fit_transform(x_train_std, y_train) # LDA是有监督方法,需要用到标签
x_test_lda = lda.fit_transform(x_test_std, y_test) # 预测时候特征向量正负问题,乘-1反转镜像
lr.fit(x_train_lda, y_train)
plot_decision_regions(x_train_pca, y_train, classifier=lr)
plt.xlabel('LD1')
plt.ylabel('LD2')
plt.legend(loc='lower left')
plt.show()
使用训练集拟合模型之后,分类效果如何呢?
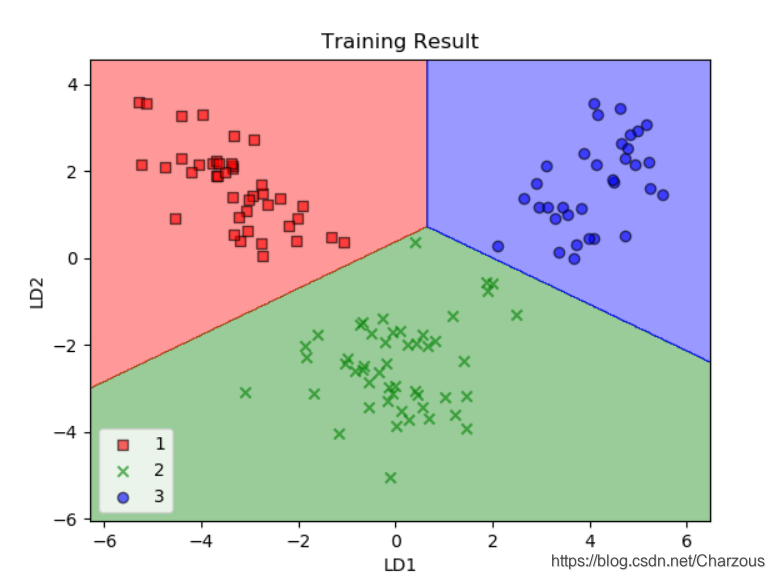
可以看到模型对训练数据集精确地分类,比PCA效果好,因为LDA使用了数据集的标签,是有监督的学习。
更准确来说,我们要看模型在测试集上的效果,对比如下:
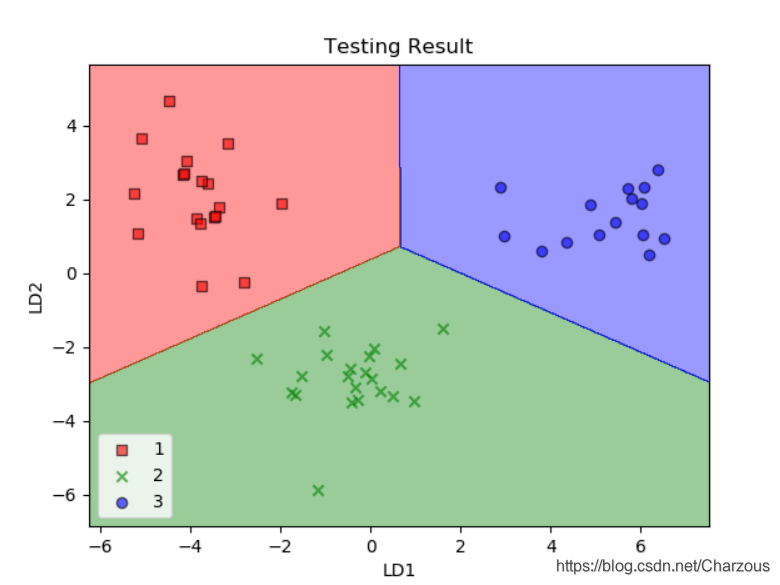
可见,经过逻辑回归分类器,提取了两个最具线性判别性的特征,将包含13个特征的葡萄酒数据集投影到二维子空间,实现了精确地分类。
四、完整代码
from sklearn.linear_model import LogisticRegression
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis as LDA
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from matplotlib.colors import ListedColormap
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np def plot_decision_regions(x, y, classifier, resolution=0.02):
markers = ['s', 'x', 'o', '^', 'v']
colors = ['r', 'g', 'b', 'gray', 'cyan']
cmap = ListedColormap(colors[:len(np.unique(y))])
x1_min, x1_max = x[:, 0].min() - 1, x[:, 0].max() + 1
x2_min, x2_max = x[:, 1].min() - 1, x[:, 1].max() + 1
xx1, xx2 = np.meshgrid(np.arange(x1_min, x1_max, resolution), np.arange(x2_min, x2_max, resolution))
z = classifier.predict(np.array([xx1.ravel(), xx2.ravel()]).T)
z = z.reshape(xx1.shape)
plt.contourf(xx1, xx2, z, alpha=0.4, cmap=cmap) for idx, cc in enumerate(np.unique(y)):
plt.scatter(x=x[y == cc, 0],
y=x[y == cc, 1],
alpha=0.6,
c=cmap(idx),
edgecolor='black',
marker=markers[idx],
label=cc) def main():
# load data
df_wine = pd.read_csv('D:\\PyCharm_Project\\maching_learning\\wine_data\\wine.data', header=None) # 本地加载
# df_wine = pd.read_csv('https://archive.ics.uci.edu/ml/machine-learning-databases/wine/wine.data',
# header=None) # 服务器加载 # split the data,train:test=7:3
x, y = df_wine.iloc[:, 1:].values, df_wine.iloc[:, 0].values
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.3, stratify=y, random_state=0) # standardize the feature 标准化单位方差
sc = StandardScaler()
x_train_std = sc.fit_transform(x_train)
x_test_std = sc.fit_transform(x_test) lda = LDA(n_components=2)
lr = LogisticRegression()
x_train_lda = lda.fit_transform(x_train_std, y_train) # LDA是有监督方法,需要用到标签
x_test_lda = lda.fit_transform(x_test_std, y_test) # 预测时候特征向量正负问题,乘-1反转镜像
lr.fit(x_train_lda, y_train)
plt.figure(figsize=(6, 7), dpi=100) # 画图高宽,像素
plt.subplot(2, 1, 1)
plot_decision_regions(x_train_lda, y_train, classifier=lr)
plt.title('Training Result')
plt.xlabel('LD1')
plt.ylabel('LD2')
plt.legend(loc='lower left') plt.subplot(2, 1, 2)
plot_decision_regions(x_test_lda, y_test, classifier=lr)
plt.title('Testing Result')
plt.xlabel('LD1')
plt.ylabel('LD2')
plt.legend(loc='lower left')
plt.tight_layout() # 子图间距
plt.show() if __name__ == '__main__':
main()
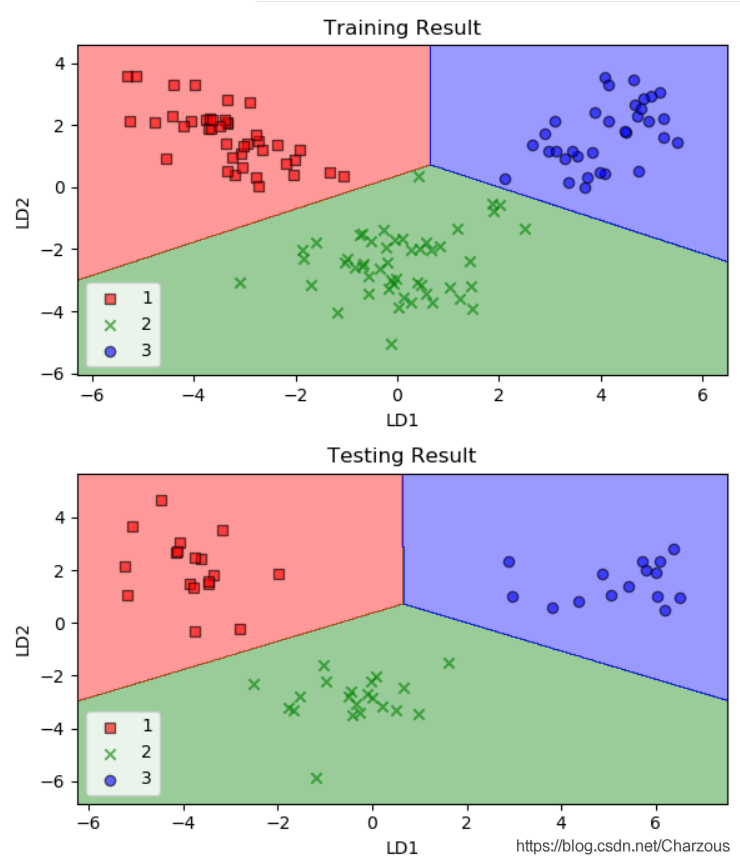
五、降维压缩数据技术总结
至此,数据降维压缩的技术学习告一段落,经过这次学习,我感觉到一次比较系统的学习会收获更多,此次学习了主成分分析(PCA)和线性判别分析(LDA),这两种经典的数据降维技术各有特点。
前者是无监督技术,忽略分类标签,寻找最大化方差方向提取主成分;后者是有监督技术,训练时候考虑分类标签,在线性特征空间最大化类的可分性。应用场景也各有优势,PCA在图像识别应用好,LDA在特征提取方面更有优势。
这里列出这次学习过程的博文记录,方便查找:
- 主成分分析PCA数据降维原理及python应用(葡萄酒案例分析)
- 运用sklearn进行主成分分析(PCA)代码实现
- LDA线性判别分析原理及python应用(葡萄酒案例分析)
- 运用sklearn进行线性判别分析(LDA)代码实现
我的博客园:运用sklearn进行线性判别分析(LDA)代码实现
我的CSDN:https://blog.csdn.net/Charzous/article/details/108064317
版权声明:本文为博主原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。
本文链接:https://blog.csdn.net/Charzous/article/details/108064317
运用sklearn进行线性判别分析(LDA)代码实现的更多相关文章
- 机器学习 —— 基础整理(四)特征提取之线性方法:主成分分析PCA、独立成分分析ICA、线性判别分析LDA
本文简单整理了以下内容: (一)维数灾难 (二)特征提取--线性方法 1. 主成分分析PCA 2. 独立成分分析ICA 3. 线性判别分析LDA (一)维数灾难(Curse of dimensiona ...
- 机器学习理论基础学习3.2--- Linear classification 线性分类之线性判别分析(LDA)
在学习LDA之前,有必要将其自然语言处理领域的LDA区别开来,在自然语言处理领域, LDA是隐含狄利克雷分布(Latent Dirichlet Allocation,简称LDA),是一种处理文档的主题 ...
- 线性判别分析LDA原理总结
在主成分分析(PCA)原理总结中,我们对降维算法PCA做了总结.这里我们就对另外一种经典的降维方法线性判别分析(Linear Discriminant Analysis, 以下简称LDA)做一个总结. ...
- 线性判别分析LDA详解
1 Linear Discriminant Analysis 相较于FLD(Fisher Linear Decriminant),LDA假设:1.样本数据服从正态分布,2.各类得协方差相等.虽然 ...
- 线性判别分析 LDA
点到判决面的距离 点\(x_0\)到决策面\(g(x)= w^Tx+w_0\)的距离:\(r={g(x)\over \|w\|}\) 广义线性判别函数 因任何非线性函数都可以通过级数展开转化为多项式函 ...
- 机器学习中的数学-线性判别分析(LDA)
前言在之前的一篇博客机器学习中的数学(7)——PCA的数学原理中深入讲解了,PCA的数学原理.谈到PCA就不得不谈LDA,他们就像是一对孪生兄弟,总是被人们放在一起学习,比较.这这篇博客中我们就来谈谈 ...
- 主成分分析(PCA)与线性判别分析(LDA)
主成分分析 线性.非监督.全局的降维算法 PCA最大方差理论 出发点:在信号处理领域,信号具有较大方差,噪声具有较小方差 目标:最大化投影方差,让数据在主投影方向上方差最大 PCA的求解方法: 对样本 ...
- LDA线性判别分析原理及python应用(葡萄酒案例分析)
目录 线性判别分析(LDA)数据降维及案例实战 一.LDA是什么 二.计算散布矩阵 三.线性判别式及特征选择 四.样本数据降维投影 五.完整代码 结语 一.LDA是什么 LDA概念及与PCA区别 LD ...
- 线性判别分析(LDA)准则:FIsher准则、感知机准则、最小二乘(最小均方误差)准则
准则 采用一种分类形式后,就要采用准则来衡量分类的效果,最好的结果一般出现在准则函数的极值点上,因此将分类器的设计问题转化为求准则函数极值问题,即求准则函数的参数,如线性分类器中的权值向量. 分类器设 ...
随机推荐
- SQL数据多条转单条(CONCAT_WS)
一.concat()函数可以连接一个或者多个字符串 concat(str1,str2,…) 返回结果为连接参数产生的字符串.如有任何一个参数为NULL ,则返回值为 NULL. select conc ...
- Python 编程语言的核心是什么?
01 Python 编程语言的核心是什么? 为什么要问这个问题? 我想要用Python实现WebAssembly,这并不是什么秘密.这不仅可以让Python进入浏览器,而且由于iOS和Andr ...
- python numpy库np.percentile用法说明
在python中计算一个多维数组的任意百分比分位数,此处的百分位是从小到大排列,只需用np.percentile即可…… a = range(1,101) #求取a数列第90%分位的数值 np.per ...
- js获得url地址携带参数
function GetQueryString(name) { var reg = new RegExp("(^|&)" + name + "=([^&] ...
- 云原生时代高性能Java框架—Quarkus(二)
--- *构建Quarkus本地镜像.容器化部署Quarkus项目* Quarkus系列博文 Quarkus&GraalVM介绍.创建并启动第一个项目 构建Quarkus本地镜像.容器化部署Q ...
- 服务器入侵应急响应排查(Linux篇)
总体思路 确认问题与系统现象 → 取证清除与影响评估 → 系统加固 → 复盘整改 常见入侵 ① 挖矿: 表象:CPU增高.可疑定时任务.外联矿池IP. 告警:威胁情报(主要).Hids.蜜罐(挖矿扩散 ...
- fgdsafhak
- 搭建NFS Server
搭建NFS Server Kubetrain K8S在线直播培训,内推机会 不满意可无条件退款 现在就去广告 #背景 Kubernetes 对 Pod 进行调度时,以当时集群中各节点的可用资源作为主要 ...
- NanoHTTPD服务
需要导入nanohttpd2.3,jar包 继承NanoHTTPD public class HttpServer extends NanoHTTPD { public HttpServer(int ...
- 深入理解Spring AOP 1.0
本文相关代码(来自官方源码spring-test模块)请参见spring-demysify org.springframework.mylearntest包下. 统称能够实现AOP的语言为AOL,即( ...