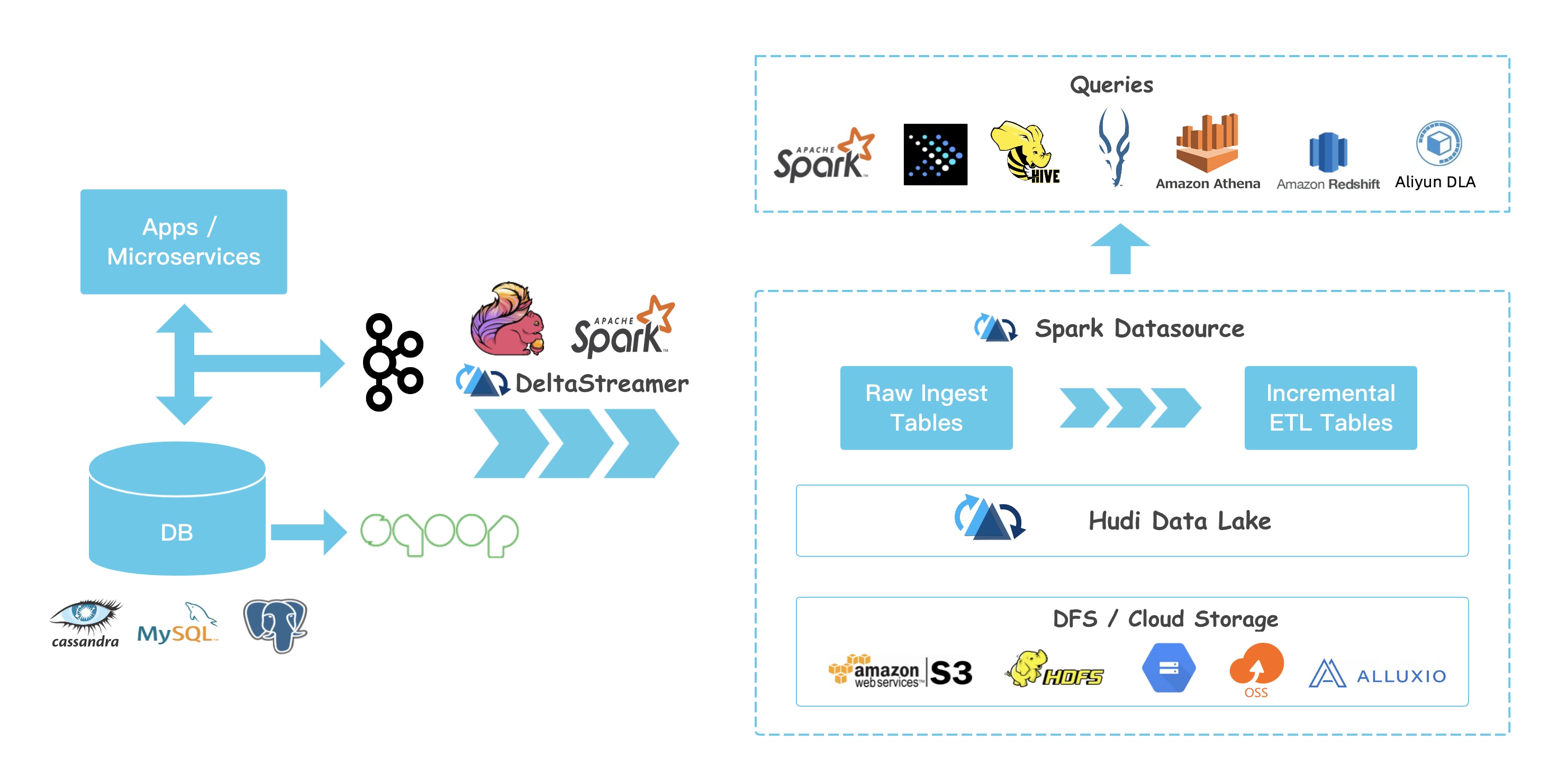
数据湖-Apache Hudi
Hudi特性
数据湖处理非结构化数据、日志数据、结构化数据
支持较快upsert/delete, 可插入索引
Table Schema
小文件管理Compaction
ACID语义保证,多版本保证 并具有回滚功能
savepoint 用户数据恢复的保存点
支持多种分析引擎 spark、hive、presto
编译Hudi
git clone https://github.com/apache/hudi.git && cd hudi
mvn clean package -DskipTests
hudi 高度耦合spark
执行spark-shell测试Hudi
bin/spark-shell --packages org.apache.spark:spark-avro_2.11:2.4.5 --conf 'spark.serializer=org.apache.spark.serializer.KryoSerializer' --jars /Users/macwei/IdeaProjects/hudi-master/packaging/hudi-spark-bundle/target/hudi-spark-bundle_2.11-0.6.1-SNAPSHOT.jar
hudi 写入数据
// spark-shell
import org.apache.hudi.QuickstartUtils._
import scala.collection.JavaConversions._
import org.apache.spark.sql.SaveMode._
import org.apache.hudi.DataSourceReadOptions._
import org.apache.hudi.DataSourceWriteOptions._
import org.apache.hudi.config.HoodieWriteConfig._
val tableName = "hudi_trips_cow"
val basePath = "file:///tmp/hudi_trips_cow"
val dataGen = new DataGenerator
// spark-shell
val inserts = convertToStringList(dataGen.generateInserts(10))
val df = spark.read.json(spark.sparkContext.parallelize(inserts, 2))
df.write.format("hudi").
options(getQuickstartWriteConfigs).
option(PRECOMBINE_FIELD_OPT_KEY, "ts").
option(RECORDKEY_FIELD_OPT_KEY, "uuid").
option(PARTITIONPATH_FIELD_OPT_KEY, "partitionpath").
option(TABLE_NAME, tableName).
mode(Overwrite).
save(basePath)
读取hudi数据:
val tripsSnapshotDF = spark.
read.
format("hudi").
load(basePath + "/*/*/*/*")
tripsSnapshotDF.createOrReplaceTempView("hudi_trips_snapshot")
spark.sql("select fare, begin_lon, begin_lat, ts from hudi_trips_snapshot where fare > 20.0").show()
+------------------+-------------------+-------------------+-------------+
| fare| begin_lon| begin_lat| ts|
+------------------+-------------------+-------------------+-------------+
| 64.27696295884016| 0.4923479652912024| 0.5731835407930634|1609771934700|
| 93.56018115236618|0.14285051259466197|0.21624150367601136|1610087553306|
| 33.92216483948643| 0.9694586417848392| 0.1856488085068272|1609982888463|
| 27.79478688582596| 0.6273212202489661|0.11488393157088261|1610187369637|
|34.158284716382845|0.46157858450465483| 0.4726905879569653|1610017361855|
| 43.4923811219014| 0.8779402295427752| 0.6100070562136587|1609795685223|
| 66.62084366450246|0.03844104444445928| 0.0750588760043035|1609923236735|
| 41.06290929046368| 0.8192868687714224| 0.651058505660742|1609838517703|
+------------------+-------------------+-------------------+-------------+
spark.sql("select _hoodie_commit_time, _hoodie_record_key, _hoodie_partition_path, rider, driver, fare from hudi_trips_snapshot").show()
+-------------------+--------------------+----------------------+---------+----------+------------------+
|_hoodie_commit_time| _hoodie_record_key|_hoodie_partition_path| rider| driver| fare|
+-------------------+--------------------+----------------------+---------+----------+------------------+
| 20210110225218|3c7ef0e7-86fb-444...| americas/united_s...|rider-213|driver-213| 64.27696295884016|
| 20210110225218|222db9ca-018b-46e...| americas/united_s...|rider-213|driver-213| 93.56018115236618|
| 20210110225218|3fc72d76-f903-4ca...| americas/united_s...|rider-213|driver-213|19.179139106643607|
| 20210110225218|512b0741-e54d-426...| americas/united_s...|rider-213|driver-213| 33.92216483948643|
| 20210110225218|ace81918-0e79-41a...| americas/united_s...|rider-213|driver-213| 27.79478688582596|
| 20210110225218|c76f82a1-d964-4db...| americas/brazil/s...|rider-213|driver-213|34.158284716382845|
| 20210110225218|73145bfc-bcb2-424...| americas/brazil/s...|rider-213|driver-213| 43.4923811219014|
| 20210110225218|9e0b1d58-a1c4-47f...| americas/brazil/s...|rider-213|driver-213| 66.62084366450246|
| 20210110225218|b8fccca1-9c28-444...| asia/india/chennai|rider-213|driver-213|17.851135255091155|
| 20210110225218|6144be56-cef9-43c...| asia/india/chennai|rider-213|driver-213| 41.06290929046368|
+-------------------+--------------------+----------------------+---------+----------+------------------+
对比
数据导入至hadoop方案: maxwell、canal、flume、sqoop
hudi是通用方案
hudi 支持presto、spark sql下游查询
hudi存储依赖hdfs
hudi可以当作数据源或数据库,支持PB级别
概念
Timeline: 时间戳
state:即时状态
原子写入操作
compaction: 后台协调hudi中差异数据
rollback: 回滚
savepoint: 数据还原
任何操作都有以下状态:
- Requested 已安排操作行为,但是没有开始
- Inflight 正在执行当前操作
- Completed 已完成操作
hudi提供两种表类型:
- CopyOnWrite 适用全量数据,列式存储,写入过程执行同步合并重写文件
- MergeOnRead 增量数据,基于列式(parquet)和行式(avro)存储,更新记录到增量文件(日志文件),压缩同步和异步生成新版本文件,延迟更低
hudi查询类型:
- 快照查询 查询最新快照表数据,如果是MergeOnRead表,动态合并最新版本基本数据和增量数据用于显示查询;如果是CopyOnWrite,直接查询Parquet表,同时提供upsert、delete操作
- 增量查询 只能看到写入表的新数据
- 优化读查询 给定时间段的一个查询
资料参考
- Docker Demo: https://hudi.apache.org/docs/docker_demo.html Hudi 官方建议代码测试可在Docker进行, 如果在Docker运行有问题也可以进行Remote Debugger
- Hudi 目前代码写的很多实现其实有点不太好, 如果有想贡献提交PR的可参考: 如何进行开源贡献
数据湖-Apache Hudi的更多相关文章
- 使用Apache Hudi构建大规模、事务性数据湖
一个近期由Hudi PMC & Uber Senior Engineering Manager Nishith Agarwal分享的Talk 关于Nishith Agarwal更详细的介绍,主 ...
- 基于Apache Hudi构建分析型数据湖
为了有机地发展业务,每个组织都在迅速采用分析. 在分析过程的帮助下,产品团队正在接收来自用户的反馈,并能够以更快的速度交付新功能. 通过分析提供的对用户的更深入了解,营销团队能够调整他们的活动以针对特 ...
- Apache Hudi助力nClouds加速数据交付
1. 概述 在nClouds上,当客户的业务决策取决于对近实时数据的访问时,客户通常会向我们寻求有关数据和分析平台的解决方案.但随着每天创建和收集的数据量都在增加,这使得使用传统技术进行数据分析成为一 ...
- 官宣!ASF官方正式宣布Apache Hudi成为顶级项目
马萨诸塞州韦克菲尔德(Wakefield,MA)- 2020年6月 - Apache软件基金会(ASF).350多个开源项目和全职开发人员.管理人员和孵化器宣布:Apache Hudi正式成为Apac ...
- Apache Hudi和Presto的前世今生
一篇由Apache Hudi PMC Bhavani Sudha Saktheeswaran和AWS Presto团队工程师Brandon Scheller分享Apache Hudi和Presto集成 ...
- 划重点!AWS的湖仓一体使用哪种数据湖格式进行衔接?
此前Apache Hudi社区一直有小伙伴询问能否使用Amazon Redshift查询Hudi表,现在它终于来了. 现在您可以使用Amazon Redshift查询Amazon S3 数据湖中Apa ...
- Halodoc使用 Apache Hudi 构建 Lakehouse的关键经验
Halodoc 数据工程已经从传统的数据平台 1.0 发展到使用 LakeHouse 架构的现代数据平台 2.0 的改造.在我们之前的博客中,我们提到了我们如何在 Halodoc 实施 Lakehou ...
- 使用 Apache Hudi 实现 SCD-2(渐变维度)
数据是当今分析世界的宝贵资产. 在向最终用户提供数据时,跟踪数据在一段时间内的变化非常重要. 渐变维度 (SCD) 是随时间推移存储和管理当前和历史数据的维度. 在 SCD 的类型中,我们将特别关注类 ...
- 华为云 MRS 基于 Apache Hudi 极致查询优化的探索实践
背景 湖仓一体(LakeHouse)是一种新的开放式架构,它结合了数据湖和数据仓库的最佳元素,是当下大数据领域的重要发展方向. 华为云早在2020年就开始着手相关技术的预研,并落地在华为云 Fusio ...
随机推荐
- Docker - 配置加速器
https://www.daocloud.io/mirror#accelerator-doc curl -sSL https://get.daocloud.io/daotools/set_mirror ...
- [leetcode]BestTimetoBuyandSellStock买卖股票系列问题
问题1: If you were only permitted to complete at most one transaction (ie, buy one and sell one share ...
- Centos7 编译安装PHP7.2
yum install wget 在 /usr/local/src 目录下载php源码包 wget http://cn2.php.net/distributions/php-7.2.4.tar.gz ...
- Interface注意事项
Interface 成员声明 声明属性,默认static & final 声明方法,默认public interface Instrument { int VALUE = 5; // stat ...
- java使用正则的例子
package com.accord.util; import java.util.ArrayList; import java.util.List; import java.util.regex.M ...
- llinux文件相关指令
一---导读 首先我们来看这样一个小案例,假设张三要出差,按照 这样的路线进行 北京->上海,之后回到北京.再按照北京->天津->石家庄这样的路线进行出差(北京是根据地).假设现在张 ...
- 小米11和iphone12参数对比哪个好
小米11:搭载最新一代三星的AMOLED屏幕,120Hz屏幕刷新,iPhone12使用全新一代的视网膜屏,6.1英寸屏幕,支持60Hz屏幕刷新,支持HDR显示,P3广色域小米手机爆降800 优惠力度空 ...
- 【SpringBoot1.x】SpringBoot1.x 开发热部署和监控管理
SpringBoot1.x 开发热部署和监控管理 热部署 在开发中我们修改一个 Java 文件后想看到效果不得不重启应用,这导致大量时间花费,我们希望不重启应用的情况下,程序可以自动部署(热部署). ...
- .net core 和 WPF 开发升讯威在线客服与营销系统:使用 WebSocket 实现访客端通信
本系列文章详细介绍使用 .net core 和 WPF 开发 升讯威在线客服与营销系统 的过程.本产品已经成熟稳定并投入商用. 在线演示环境:https://kf.shengxunwei.com 注意 ...
- 初识JWT
1.JWT是什么 官方网站 JWT是JSON Web Token的简称.是一种开放标准(RFC 7519),定义了一种紧凑且自包含的方式,以JSON对象的形式在各方之间安全地传输信息,因为他被数字签名 ...