YARN-MapReduce的作业提交流程
YARN分布式资源管理系统
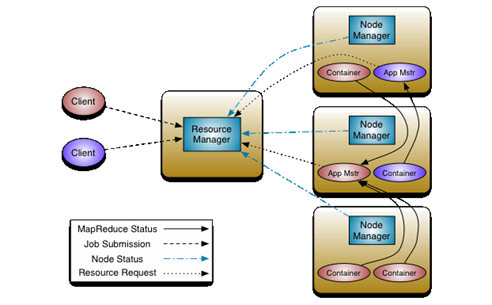
组成:
ResourceManager:YARN的资源管理器,主节点,通过NodeManager管理集群中所有的资源
NodeManager:YARN的节点管理器,从节点,通过container管理资源,一个dataNode对应一个NodeManager
Container:包装资源,CPU/内存/IO
容器:最小的资源单位,1GB内存,一个虚拟核心
Master:协调MapReduce作业中任务的运行
Application Master和MapReduce任务运行于容器中,这些容器由ResourceManager调度,由nodemanager管理
yarn工作流程
1.client端向ResourceManager提交应用程序, 也就是client端会将 jar包,配置文件,切片等数据上传到hdfs上的某路径下;
2. resourceManager将此应用程序添加到任务队列中;
3. 等待资源充沛时, resourceManager为该应用程序分配第一个container,在这个container中启动应用程序的ApplicationMaster;
4. ApplicationMaster首先向ResourceManager注册,用户可以直接通过ResourceManager查看应用程序的运行状态, 还会进行分片等工作, 之后向ResourceManager申请运行任务所需的资源;
5. ApplicationMaster采用轮询的方式通过RPC协议向ResourceManager申请和领取资源, 发送命令让NodeManager创建container, 之后执行task;
6. ApplicationMaster监控job执行作业, 必要时候进行容错处理, 直到ApplicationMaster检测到job完成后, 向ResourceManager通知, 注销自己
作业提交流程

1.取号,向resourcemanager申请一个新的application ID,用于MapReduce作业的ID
2.检查作业的输出,如果没有指定输出或者路径已经存在(路径存在时会覆盖),则不提交作业,并且抛出异常
3.检查作业的输入并计算输入切片,如果不能计算切片(如:输入路径不存在等),不提交作业,抛出异常
4.拷贝jar包,配置文件,计算好的切片到共享文件系统的以作业ID命名的目录中,作业的jar包默认副本数量为10,nademanager如果运行作业中的任务时,会有很多副本可以访问
5.调用resourcemanager的submitApplication方法提交作业
6.resourcemanager挑选一台NodeManager,该NodeManager分配容器(Container)并在此容器上启动application master进程,读取客户端上传的资源,并计算需要多少map任务和reduce任务,向resourceManager为map任务申请资源
reduce任务可以运行于集群中的任意位置,而map任务会有本地读取数据的限制。
7.当map任务的完成度达到百分之五的时候,再向resourceManager为reduce任务申请资源
8.所有的reduce任务运行完成之后,MRAppMaster会通知客户端作业完成。

YARN-MapReduce的作业提交流程的更多相关文章
- YARN作业提交流程剖析
YARN(MapReduce2) Yet Another Resource Negotiator / YARN Application Resource Negotiator对于节点数超出4000的大 ...
- Spark运行架构及作业提交流程
1.yarn-cluster模式: (1)client客户端提交spark Application应用程序到yarn集群. (2)ResourceManager收到了请求后,在集群中选择一个NodeM ...
- Hadoop2.x Yarn作业提交(客户端)
转自:http://blog.csdn.net/lihm0_1/article/details/22186833 YARN作业提交的客户端仍然使用RunJar类,和MR1一样,可参考 http://b ...
- YARN(MapReduce 2)运行MapReduce的过程-源码分析
这是我的分析,当然查阅书籍和网络.如有什么不对的,请各位批评指正.以下的类有的并不完全,只列出重要的方法. 如要转载,请注上作者以及出处. 一.源码阅读环境 需要安装jdk1.7.0版本及其以上版本, ...
- hadoop2.7之作业提交详解(上)
根据wordcount进行分析: import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; impo ...
- MapReduce简述、工作流程及新旧API对照
什么是MapReduce? 你想数出一摞牌中有多少张黑桃.直观方式是一张一张检查而且数出有多少张是黑桃. MapReduce方法则是: 1. 给在座的全部玩家中分配这摞牌. 2. 让每一个玩家数自己手 ...
- Spark:三种任务提交流程standalone、yarn-cluster、yarn-client
spark的runtime参考:Spark:Yarn-cluster和Yarn-client区别与联系浪尖分享资料 standalone Spark可以通过部署与Yarn的架构类似的框架来提供自己的集 ...
- MapReduce源码分析之新API作业提交(二):连接集群
MapReduce作业提交时连接集群是通过Job的connect()方法实现的,它实际上是构造集群Cluster实例cluster,代码如下: private synchronized void co ...
- 4 weekend110的YARN的通用性意义 + yarn的job提交流程
Mr程序写完之后,提交给yarn,yarn会产生一个MRAppMaster,想说的是,yarn变得很 通用,yarn集群上,不光可以跑mr程序,还可以跑各种运算模型. 海量批处理,mapreduce ...
随机推荐
- 第六章 类(Class) 和对象(Object)
一.笔记导图 二.实例代码: public class PrintCarStatus{ public static void main(String[] args){ int speed; Strin ...
- cao 啥时候能系统地复习一下数据结构 我光学数学去了
最近有功夫的话再敲敲数据结构复习复习
- 脑桥Brain-Pons
date: 2014-02-01 15:30:11 updated: 2014-02-01 15:30:11 [一] "2025.7.3.Brain-Pons?Expeiment?Under ...
- Zotero使用教程
之前一直想有一个管理文献的好工具,但囿于麻烦都没有去做.最近需要阅读大量的文献,便重新拾起了这个念头,在几经搜索后,选定了Zotero作为文献管理工具. 至于为什么选择这个软件,我也许并说不清,网上有 ...
- Filebeat 根据不同的日志设置不同的索引
平时在物理机上使用 Filebeat 收集日志时,会编写多个 filebeat 配置文件然后启动多个 filebeat 进程来收集不同路径下的日志并设置相对应的索引.那么如果将所有的日志路径都写到一个 ...
- SpringBoot整合JPA遇到的问题
在学习SpringBoot中使用Repository时出现这种错误 或者使用findOne也会报错,只需要改为 应该是SpringBoot版本的原因,fingOne()方法好像已经不用了.
- Python常用组件、命令大总结(持续更新)
Python开发常用组件.命令(干货) 持续更新中-关注公众号"轻松学编程"了解更多. 1.生成6位数字随机验证码 import random import string def ...
- Python列表lists索引关于字符串小纪
看的出'字符串列表'中的空格也是计算在内的
- sdsdsd
create PROCEDURE b2(in c_year int,in co int)begin declare num int; if exists(select * from class whe ...
- bert做阅读理解的一个细节
如上图所示,展示了如何用BERT来做信息抽取任务的结构图.注意一下几点即可: 1.将Question和Paragraph分别作为BERT的text1和text2输入. 2.start/end span ...