KubeEdge云边协同设计原理
云端组件CloudCore与k8s Master的关系
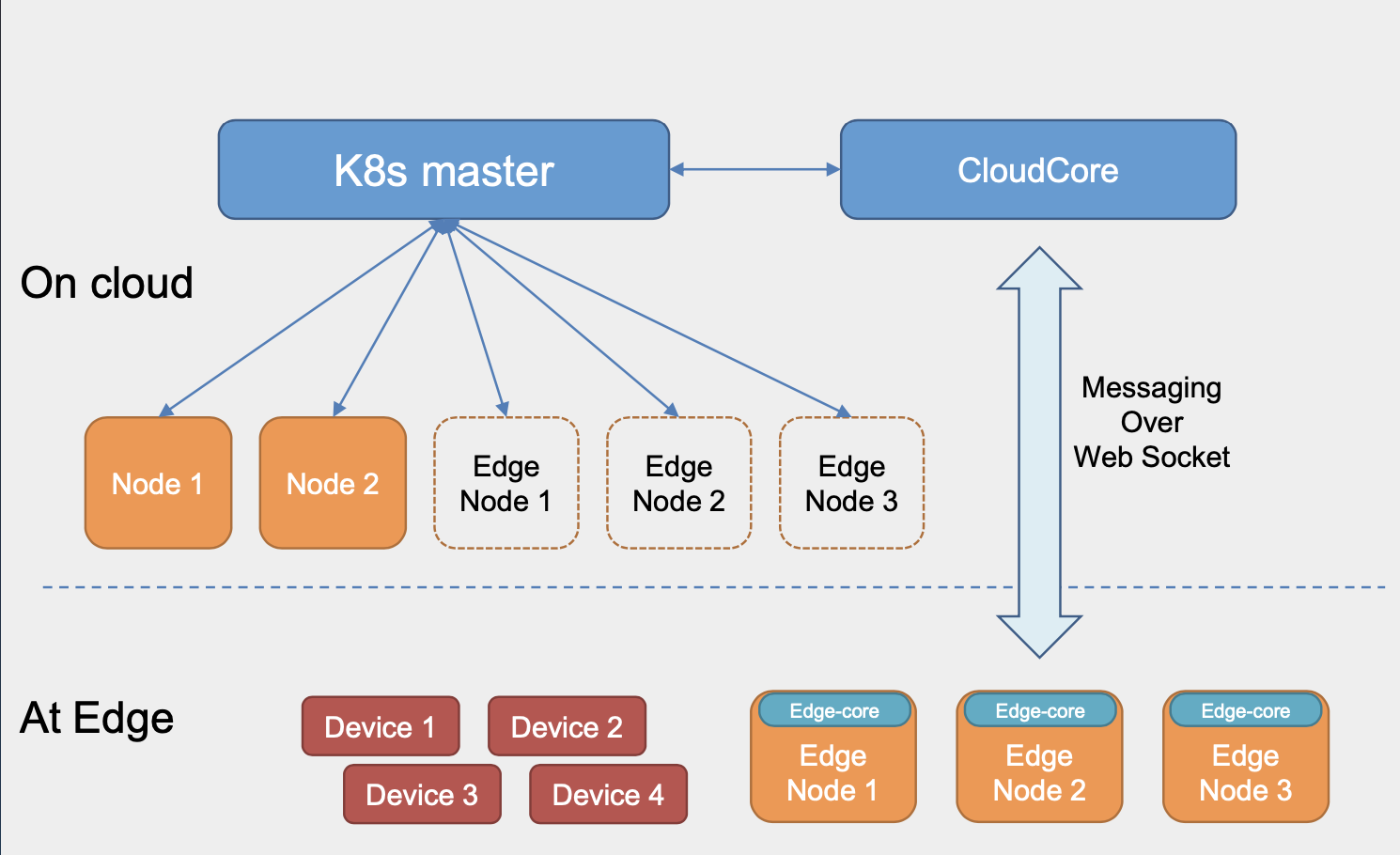
从黑盒角度看,CloudCore就是k8s的一个插件,它是非侵入的来扩展k8s的一部分功能,将原来云上的节点映射到边缘端进行管理,一个CloudCore可以管理多个边缘节点。
CloudCore里面有EdgeController、DeviceController、CSI Driver、Admission Webhook以及CloudHub这些组件。
EdgeController详解
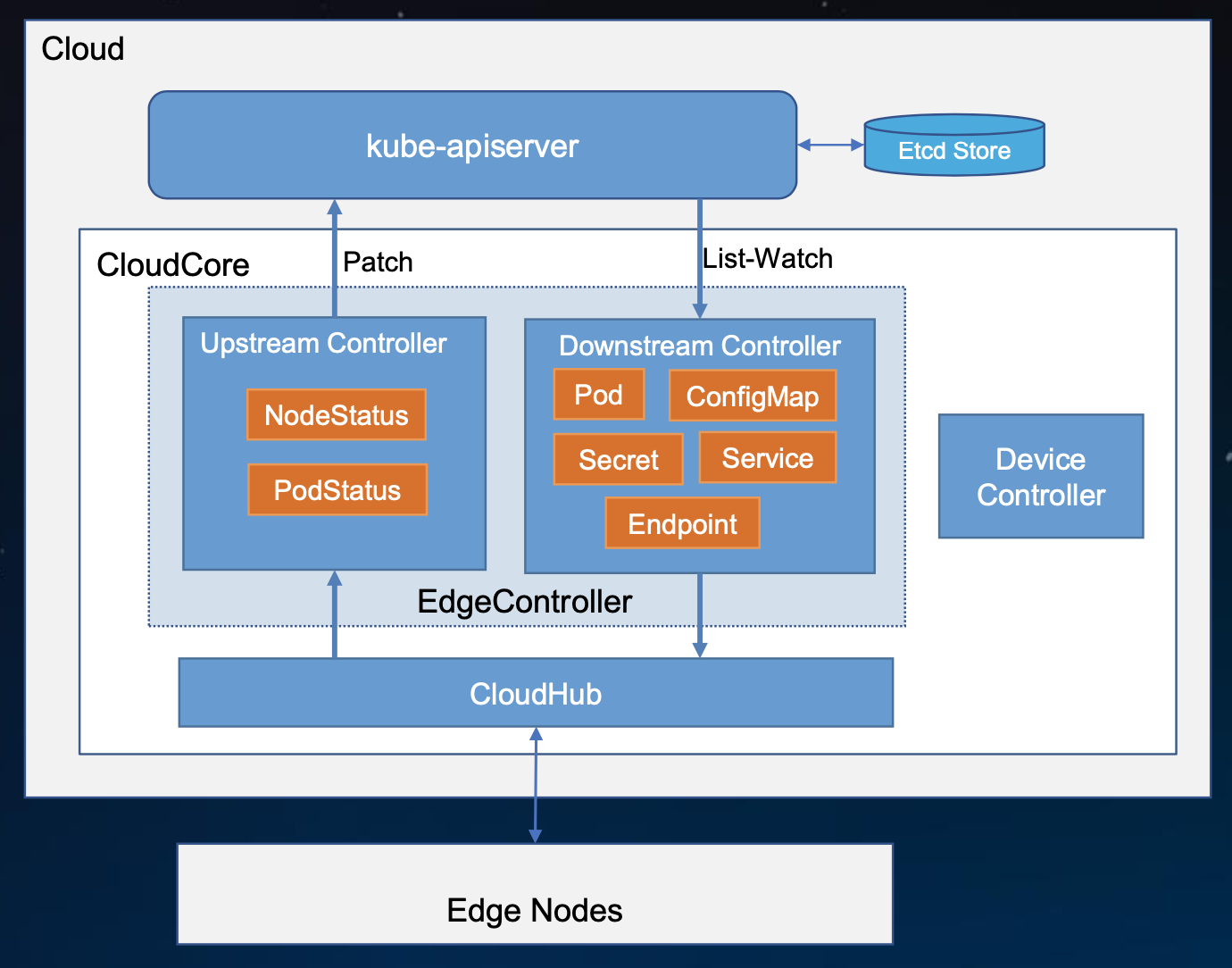
upstream处理上行数据(与原生k8s中kubelet上报自身信息一致,这里主要上报边缘节点node状态和pod状态);downstream处理下行数据。云边协同采用的是在websocket之上封装了一层消息,而且不会全量的同步数据,只会同步和本节点最相关最需要的数据,边缘节点故障重启后也不会re-list,因为边缘采用了持久化存储,直接从本地恢复。本地数据怎么实时保持最新?就是通过downstream不断从云上发生变更的相关数据往边缘去同步。
kubernetes中拉起应用的过程
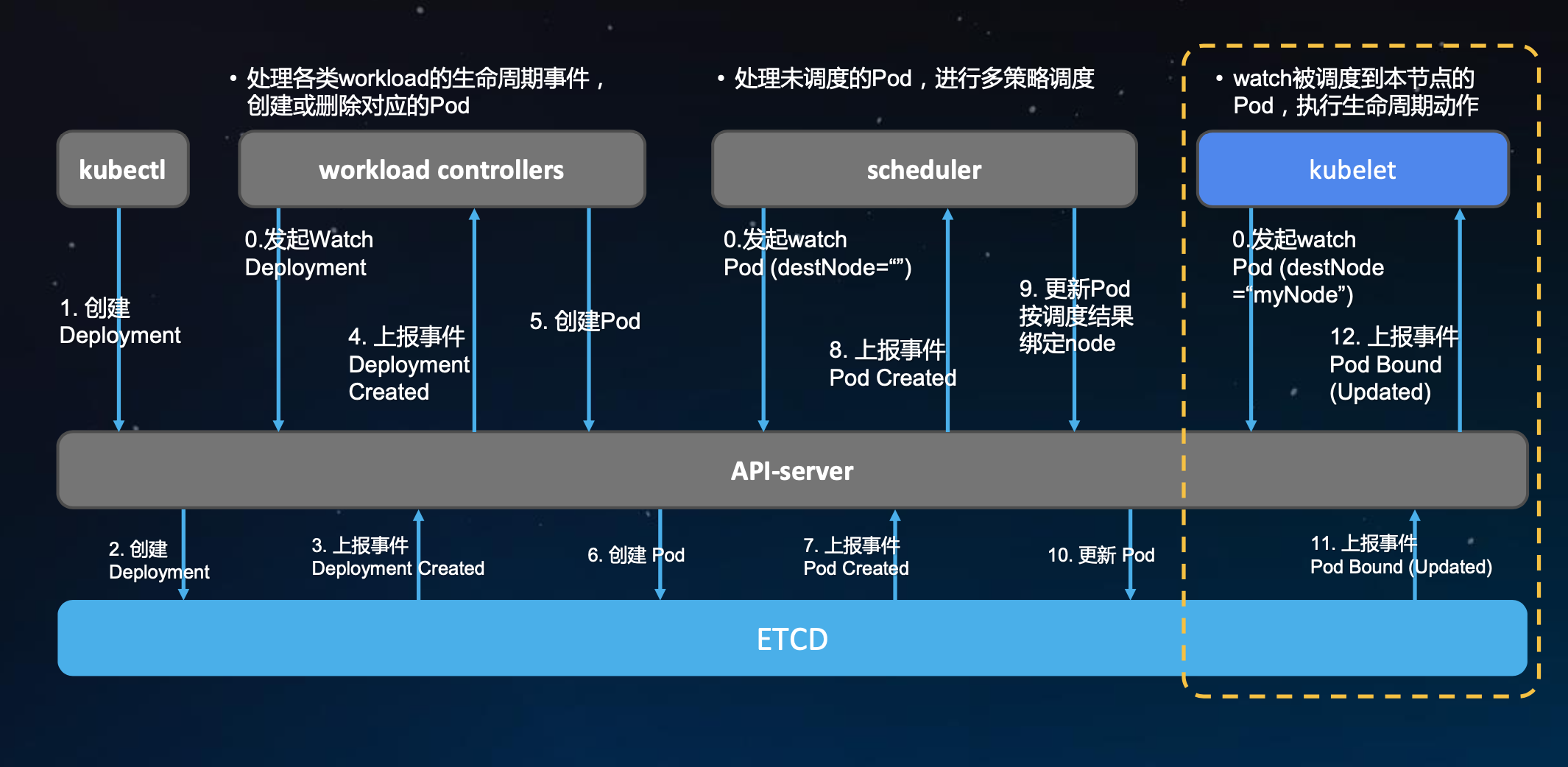
workload controller是k8s中管理各种应用类型的控制器,管理各种应用的生命周期,以goroutine方式运行在controller manager中,是k8s原生的组件。
0. workload controllers(这里用deployment controller举例) 会watch所有deployment对象,scheduler主要watch未分配节点的pod对象,kubelet watch的过滤条件是调度到本节点的pod
- 通过命令行创建一个Deployment
- api server就会做对应的存储(所有集群状态的查询都是通过api server与etcd的交互进行的)
- etcd会有一个反馈给api server
- api server会把这个事件反馈给订阅了这个事件的组件,比如deployment相关事件会反馈给deployment controller组件
- deployment controller watch到变化后,根据定义文件去发出创建相应pod事件
- api server修改etcd中pod的信息
- etcd接着反馈给api server资源变更事件
- api server把pod create事件反馈给scheduler
- scheduler会根据它加载的调度策略在集群中找到一个合适节点 ,更新pod字段信息
- api server修改etcd中pod信息
- etcd返回给api server pod Bound(update)事件
- 订阅相关node name pod的kubelet就会收到事件通知,然后执行拉起动作
图中黄色框就是kubeedge中通过CloudCore加边缘节点组件做等价替换的范围。
KubeEdge拉起边缘应用
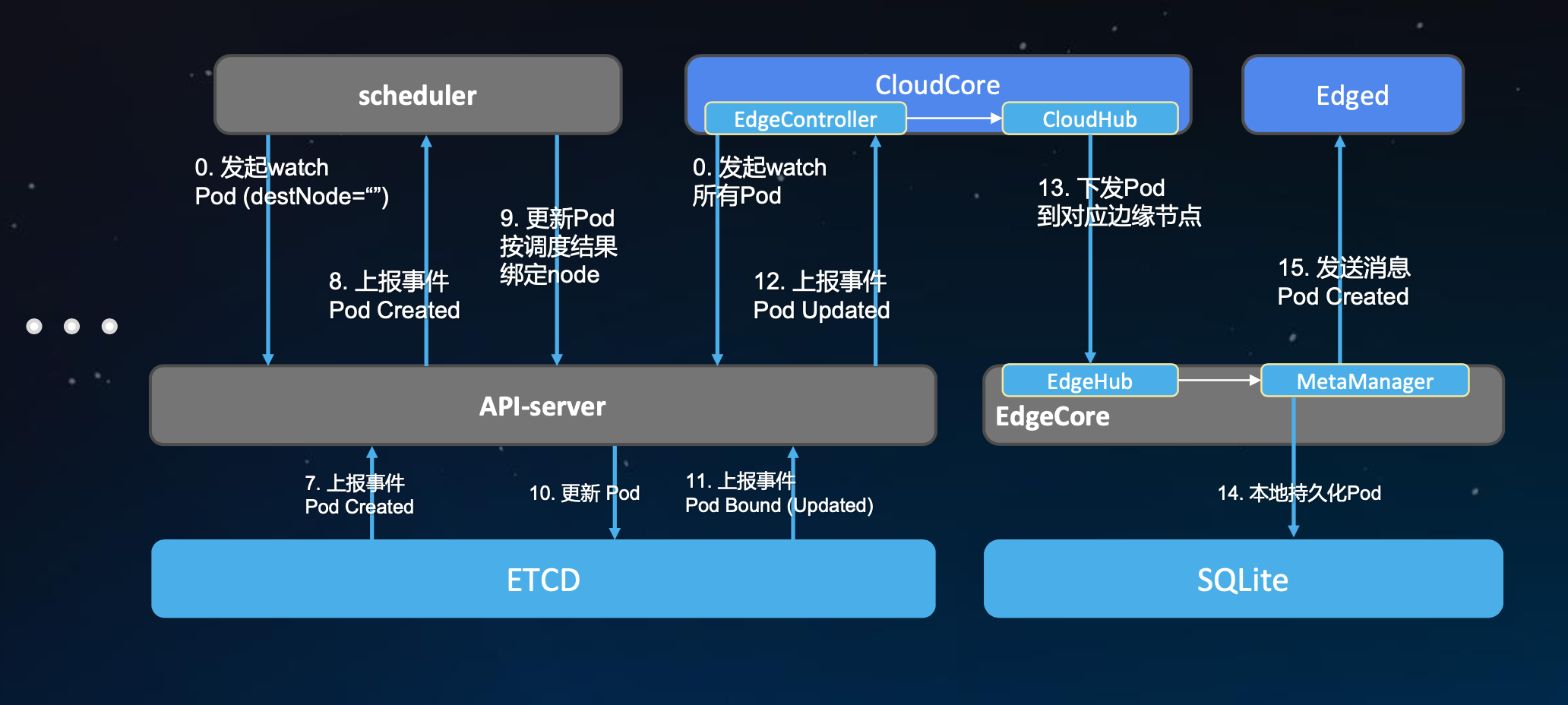
前面部分都一样,系统起来的时候,CloudCore里面的EdgeController会watch很多资源,对于pod来说,它会watch所有pod,但它里面会有一个过滤,但是过滤不会反映在list-watch上, 只在内部做下发的时候处理。
12. CloudCore收到pod变更通知后,会在内部循环中做条件的判断,看pod中的nodeName字段是不是在它所管理的边缘节点范围。如果是,它会做一个事件的封装发送到CloudHub中去
13. CloudHub对事件做完消息的封装和编码后会通过websocket通道发送到每个边缘的节点,边缘节点的EdgeHub收到消息后解开去查看pod的信息,然后发送到MetaManager组件
14. MetaManager会把收到的pod进行本地持久化
15. MetaManager在把pod信息发送到Edged(轻量化的kubelet),去拉起应用
Device CRD和DeviceController的设计
这个完全是一个operator的典型设计和实现,有一个自定义的API对象以及有一个相应的自定义controller去管理该对象的生命周期。
DeviceModel设备模版抽象
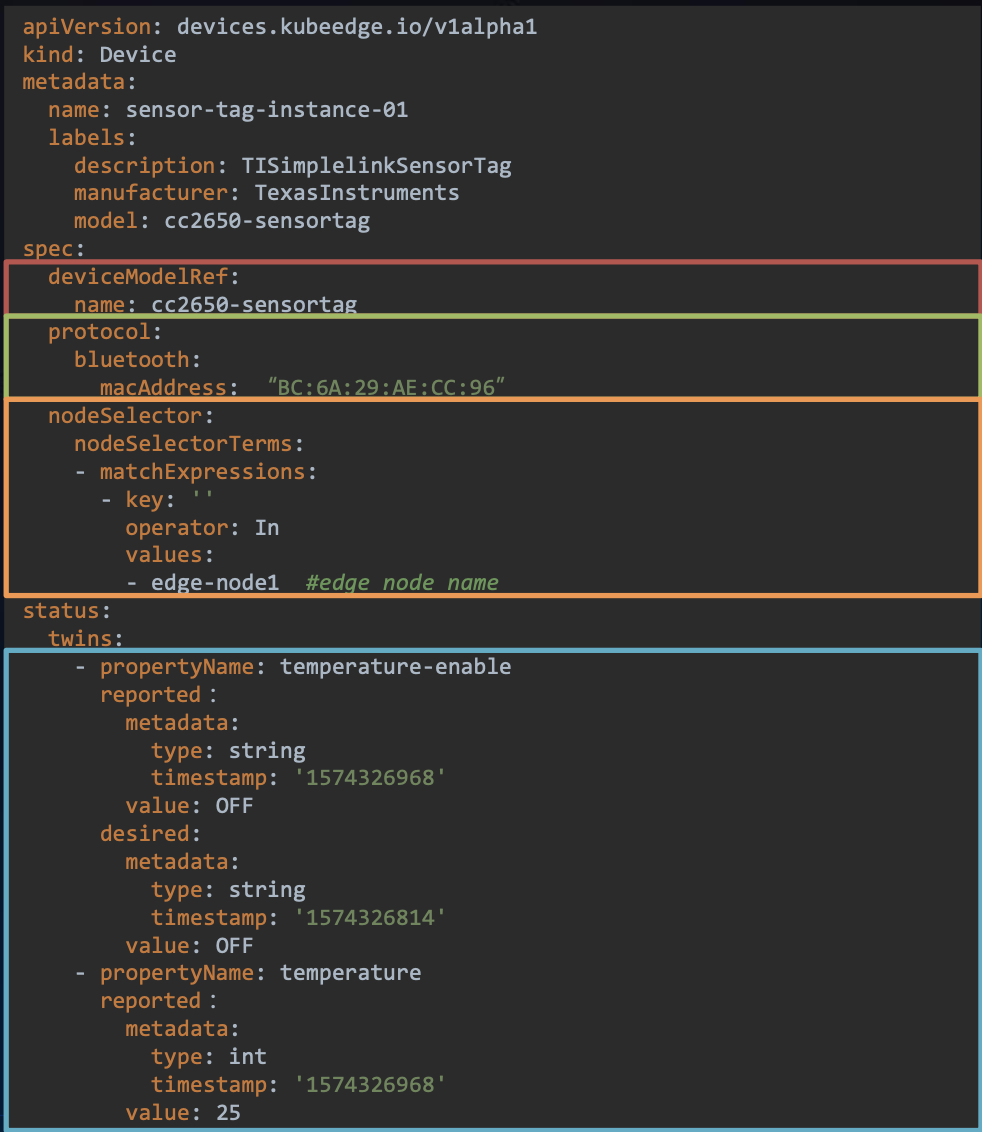
关于设备的API有两个:DeviceModel(来定义一种型号的设备),另一个是Device设备实例的API,这两个的关系就像是类和对象的关系。
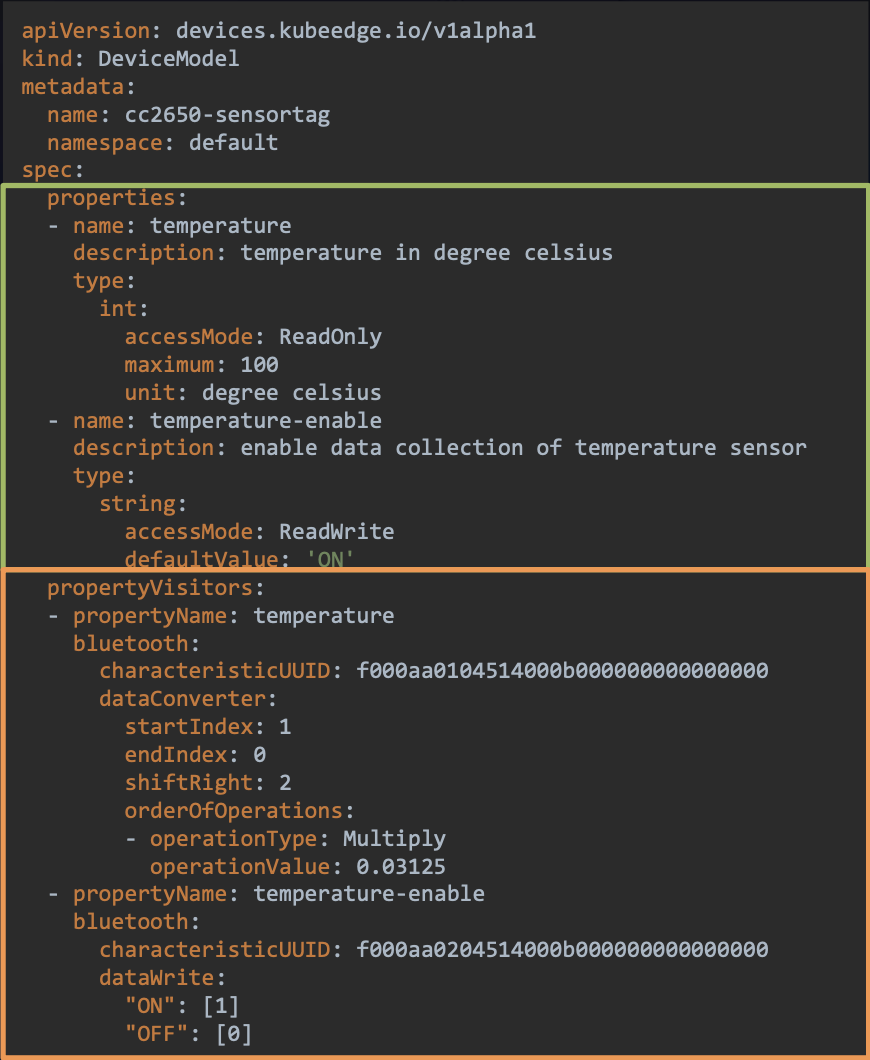
DeviceInstance设备实例的定义
DeviceController
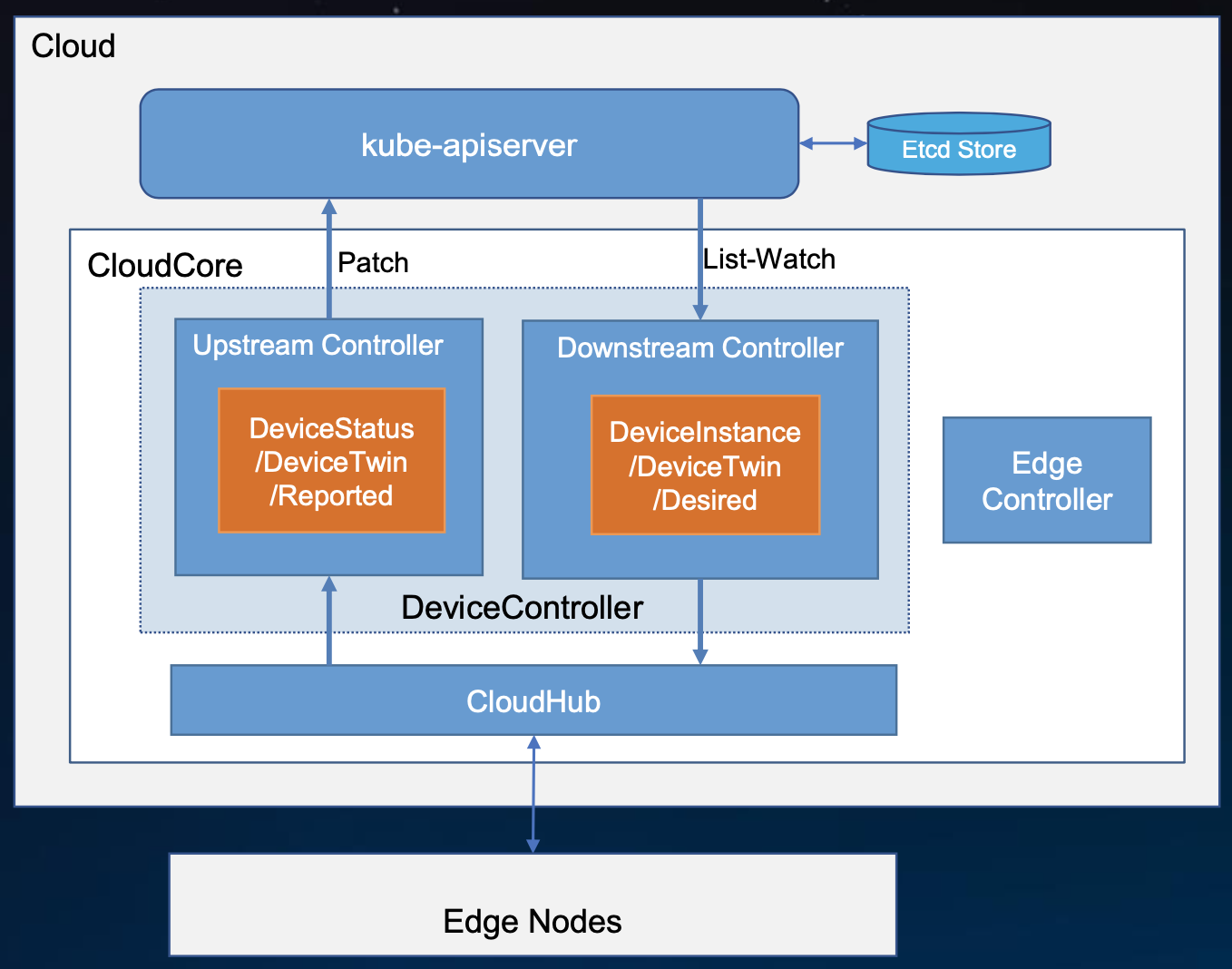
DeviceController的内部设计跟EdgeController是很相像的,主要也是上行和下行。
边缘存储的集成与设计
边缘存储所需要的工作量会大很多,主要因为存储的后端本身交互上有一些额外的操作。
k8s推荐的CSI部署方式
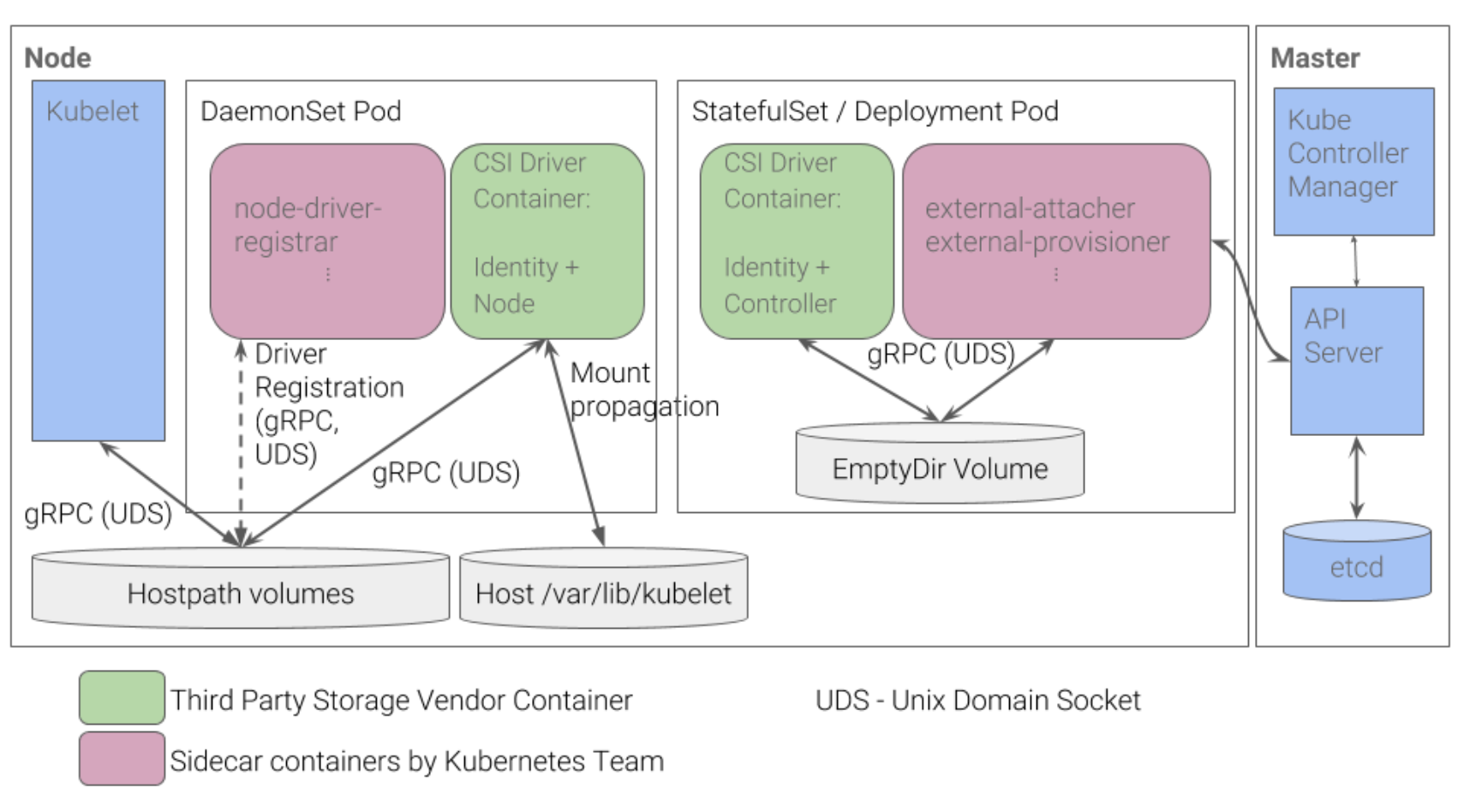
KubeEdge中CSI部署方案
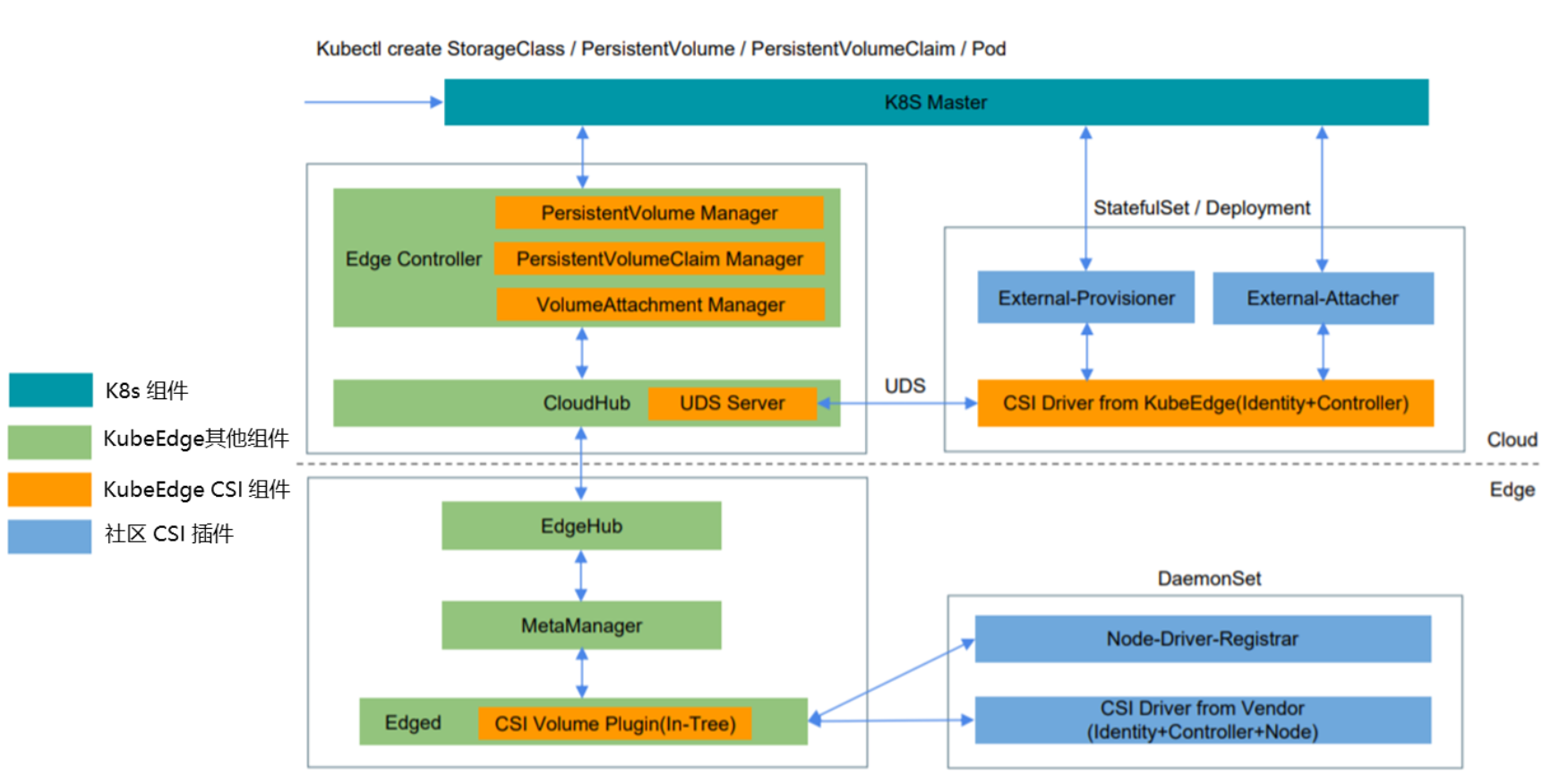
经过几种方案的选择Kubeedge最终把kubernetes社区提供的存储相关组件放到云上去,把存储方案提供商相关组件放到边缘去。这里有一个问题:当进行Provisioner操作和Attacher操作的时候所调用的存储后端在边缘,这里采取的做法是伪装一个存储后端,即CSI Driver from KubeEdge这个组件的外部行为。在Provisionner看来,通过UDS访问的CSI Driver就是一个真正的存储方案的Driver,但实际上是kubeedge里面伪装出来。它的实际实现是把这个请求按照云边协同的消息格式做封装传给CloudHub直到边缘的Edged,这里CSI Volume Plugin是之前kubelet的关于存储的一段代码,在Edged相应对等的位置有一个csi的实现,它会将消息解开去调用处在边缘的存储后端。
CloudHub与EdgeHub的通信机制
下行-通过CloudHub下发元数据
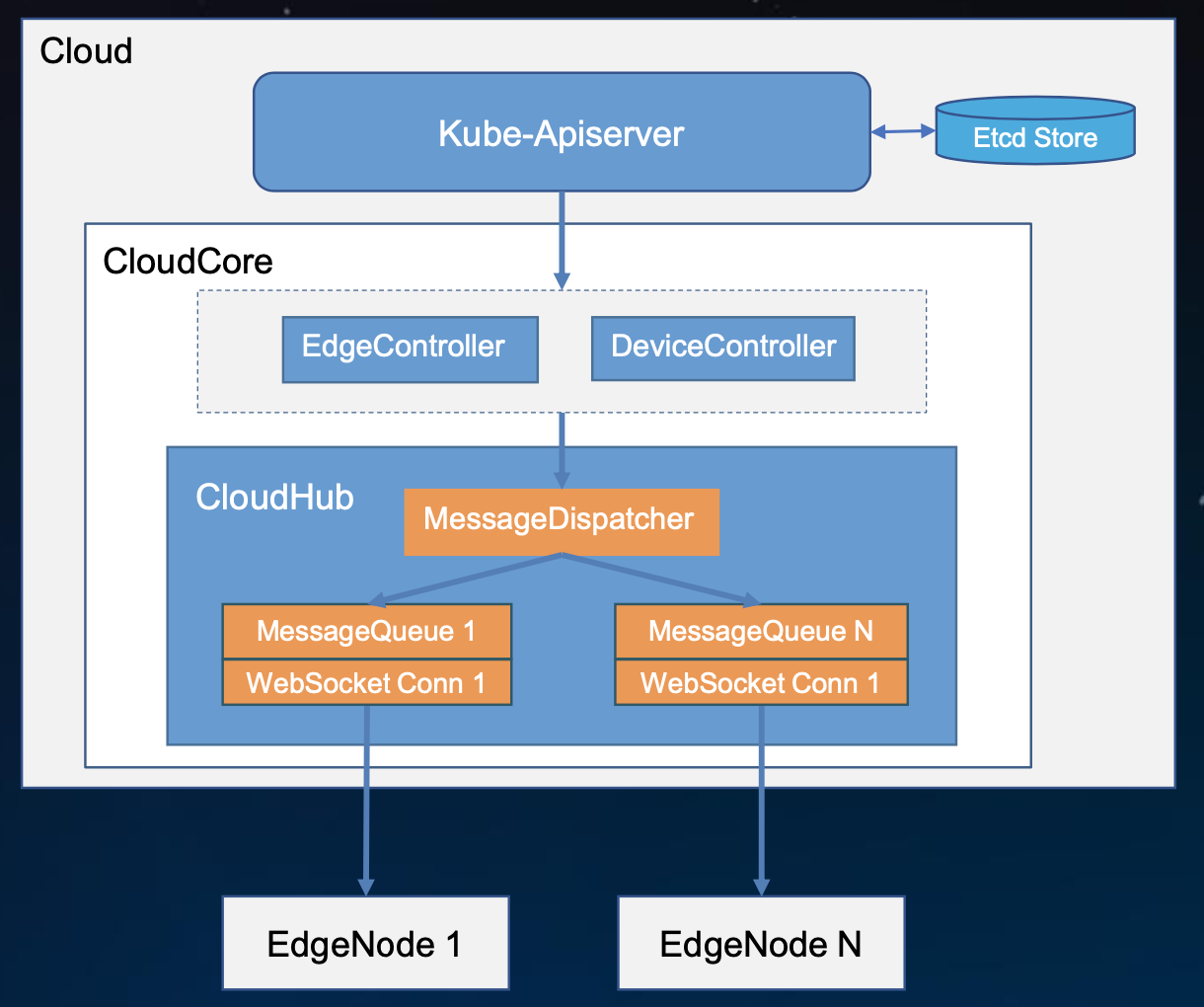
CloudHub的实现上比较简单。MessageDispatcher在下发元数据的时候会用到,KubeEdge的设计是每个节点上通过websocket需要维护一个长连接,所以会有一个连接池这么一层。在这个连接池之上每个websocket会有一个对应的MessageQueue,因为从云上下发到边缘上的数据会比较多的,虽然说比原生的kubernetes的list-watch下发的少,但同一时刻不可能只有一个数据等着下发。
EdgeController、DeviceController下发的数据会经过MessageDispatcher分发到每一个节点对应的待发送队列中,因为每个EdgeNode有它自己关心的数据,如果是一些通用的数据比如configMap,那么dispatcher就会往每一个队列中去丢消息的副本。待发送队列会将消息通过websocket发送到边缘去,然后边缘节点再去做后续的处理。
实际上整个过程就是一个分发塞队列的过程。
上行-通过CloudHub刷新状态
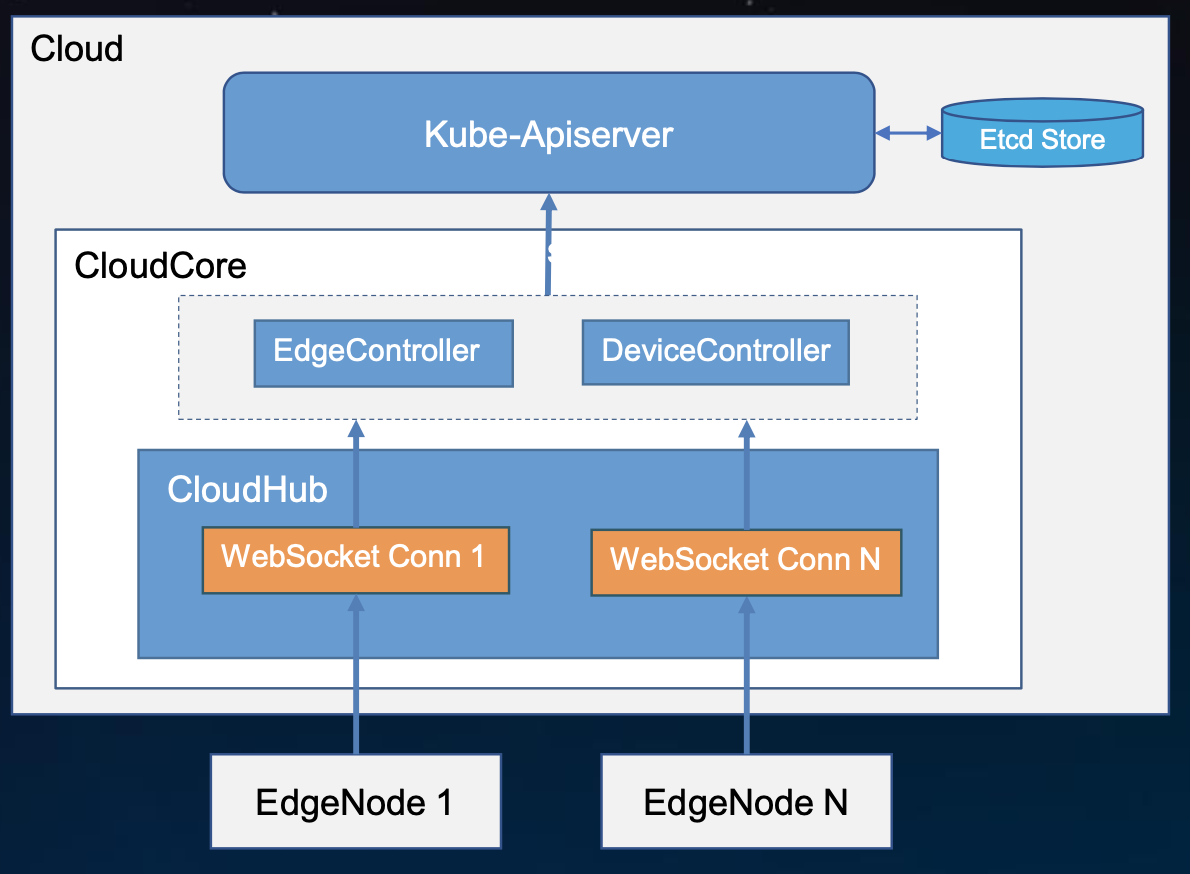
上行会更简单一点,因为上行会直接到Controller里去,没有经过队列的处理了,controller在通过api-server去做相应的变更通知,这里controller本身内部会有消息处理的队列 。因此上行时候不会经过待发送队列以及MessageDispatcher。
CloudHub与Controller的通信是用beehive模块间通信的框架来实现的。
消息格式的封装
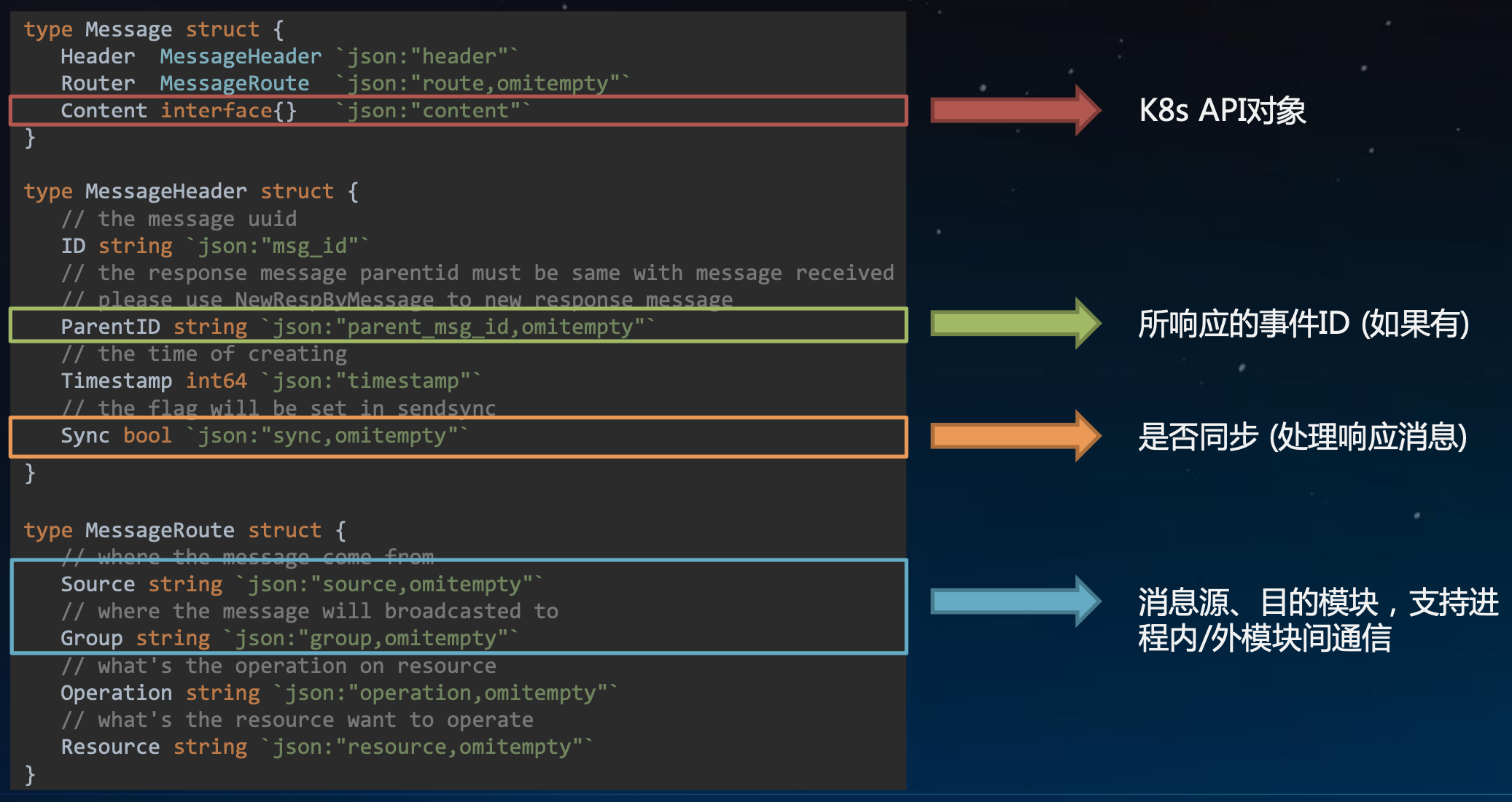
消息格式的封装是云边协同设计的核心,云边协同里面封装的消息其实是K8s的API对象,kubernetes中采用的是声明式api设计,对象上某个字段的变化实际上都是一个期望值或者是最终的一个状态。之所以选择把整个k8s的api对象原封不动的丢进Message结构体里,就是为了保留这种设计的理念,即最终对象的变化需要产生什么样的动作,相应组件会去处理比较来产生差异,然后去更新,而不是提前计算好差异在往下丢。提前计算好差异往下丢带来的问题是:计算差异的时候需要感知befor、after这两个对象,before对象的获取会有一个时间差,如果在获取处理的过程中这个对象被其他组件更新发生变化,这时候计算的差异就是不准的。所以把这个对象原封不动往下丢,丢到最后在去做diff。
声明式 API是 Kubernetes 项目编排能力“赖以生存”的核心所在:
首先,“声明式”指的就是只需要提交一个定义好的 API 对象来“声明”,所期望的状态是什么样子;
其次,“声明式 API”允许有多个 API 写端,以 PATCH 的方式对 API 对象进行修改,而无需关心本地原始 YAML 文件的内容;
最后,也是最重要的,有了上述两个能力,Kubernetes 项目才可以基于对 API 对象的增、 删、改、查,在完全无需外界干预的情况下,完成对“实际状态”和“期望状态”的调谐 (Reconcile)过程。
Header主要用来存message的id和parentID用来形成会话的信息,比如边缘发起一个查询,云端做响应 。message是多次的割裂的请求,parentId用来说明是对哪一个message的响应来形成一个关联。Sync这个字段是一个比较高级的设计:虽然大多数情况下消息的发送都是异步的,但也会有同步处理响应的情况,比如前面存储方案的集成,provisioner和attacher对于存储后端的调用是一个同步调用,它需要立刻获取这个volume是否成功的被存储后端获取。
Route结构体主要存消息的来源和目的模块,Resouce字段的作用:保存所操作对象的信息,因为一个完整的kubernetes api对象数据量还是比较大的,序列化/反序列化的代价还是比较高的,用Resource字段来标记它操作的是kubernetes中的哪个API对象,这样在消息的转发处理时候看一下Resource中的内容就可以直接处理消息的转发,以比较低的代价完成消息的路由。Operation是http中动作字段put/post/get等。
消息可靠性设计
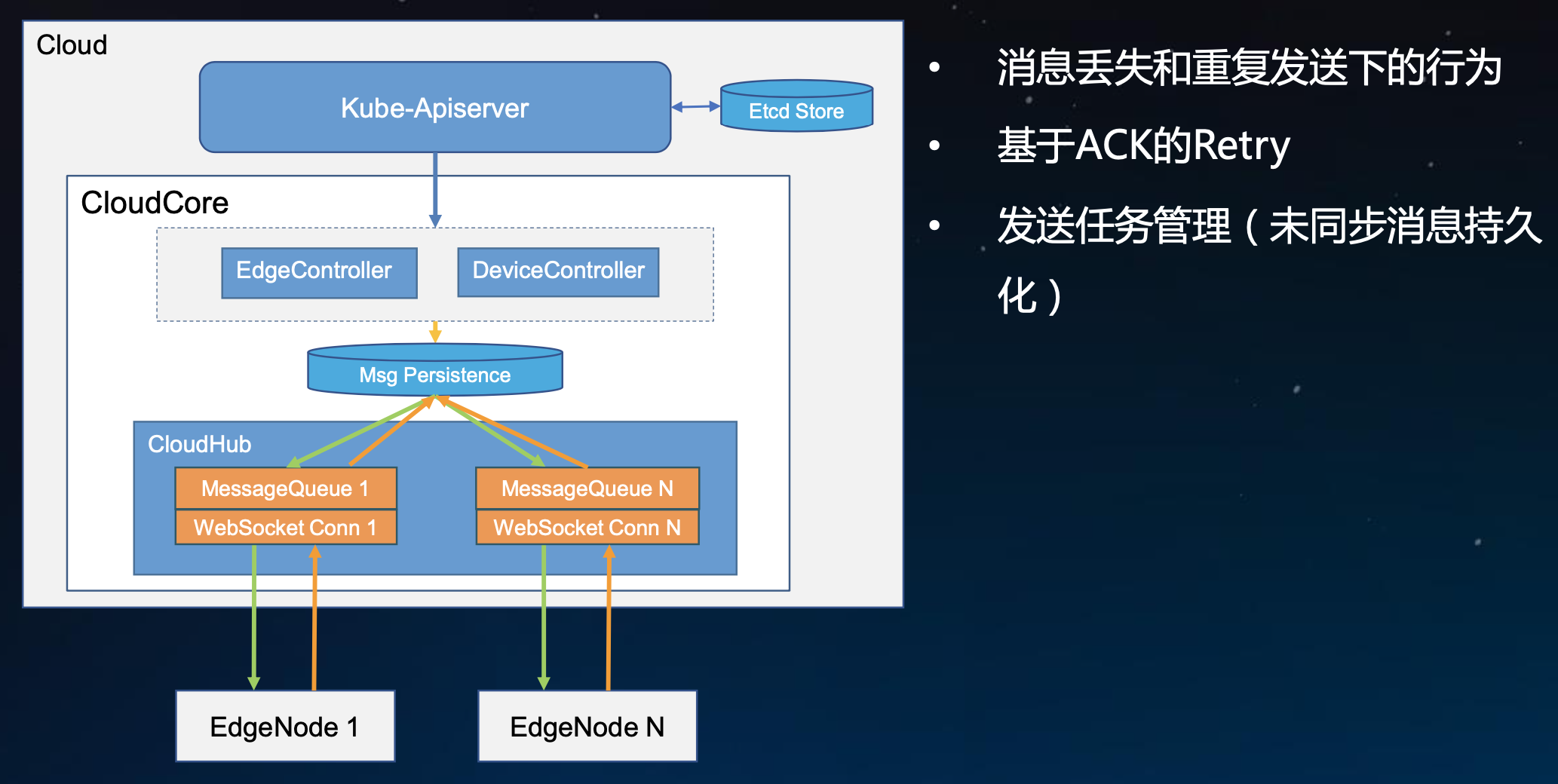
KubeEdge基于websocket能够实现高时延、低带宽的情况下能够良好的工作,但是websocket本身不能保证消息不丢失,因此在云边协同过程中还需要引入可靠性的机制。功能还在开发中,目前这个设计的理念。其实它有好几种方案:一种是云上能够主动发现边缘是否连接正常,可以选择在协议层做一些设计;另一种就是采用一种简单的响应方式来确认。
这里需要权衡的几点:消息的丢失对云和边的状态的一致性会不会有影响;重复发送的数据会不会有影响。
虽然KubeEdge保留了Kubernetes声明式API的理念,但是它精简了很多不必要的master和node的交互过程,因此如果你少发了一次消息,并不能在一个很短的周期内有一个新的一次交互把这个更新的内容带到节点上去。所以带来的问题是:如果你丢失了一个消息,你可能很长的一段时间云和边的状态是不同步的,当然最简单粗暴的解决方式就是重发;第二个问题是如果重复发了消息会怎样,这就体现了声明式API的好处,因为声明式API体现的是最终的一个状态,而不是一个差异值或变化值,那么重复发送的数据并不会造成什么影响。
基于这几点考虑呢,可以去引入ACK机制,边缘节点收到消息后发一个ACK,云上收到ACK后就认为消息发送成功了,否则会反复Retry。如果发生CloudHub宕机等使得消息没有发送成功,那么这些消息就会丢失,未来CloudHub还会做水平扩容,尽可能做一个无状态的实现,把消息做一个持久化,把发送成功的消息删除掉,目前这一块在选型上还没有确定,初步考虑是新引入一个CRD,通过CRD保存,或者采用业界其他常用的持久化方式来做。
KubeEdge云边协同设计原理的更多相关文章
- KubeEdge边缘自治设计原理
这一篇内容主要是KubeEdge中边缘节点组件EdgeCore的原理介绍. KubeEdge架构-EdgeCore 上图中深蓝色的都是kubeedg自己实现的组件,亮蓝色是k8s社区原生组件.这篇主要 ...
- kafka入门:简介、使用场景、设计原理、主要配置及集群搭建(转)
问题导读: 1.zookeeper在kafka的作用是什么? 2.kafka中几乎不允许对消息进行"随机读写"的原因是什么? 3.kafka集群consumer和producer状 ...
- html5设计原理(转)
转自: http://www.cn-cuckoo.com/2010/10/21/the-design-of-html5-2151.html 今天我想跟大家谈一谈HTML5的设计.主要分两个方面:一 ...
- 学习HTML5必读之《HTML5设计原理》
引子:很久前看过的一遍受益匪浅的文章,今天再次转过来,希望对学习HTML5的朋友有所帮助. 今天我想跟大家谈一谈HTML5的设计.主要分两个方面:一方面,当然了,就是HTML5.我可以站在这儿只讲HT ...
- SAP分析云及协同计划
大家好, 我是SAP成都研究院S/4HANA Sales 团队的软件工程师Derek.四年前我从SAP Consulting团队转到SAP Labs从事Sales Analytics相关应用的开发,在 ...
- 中间件 | kafka简介、使用场景、设计原理、主要配置及集群搭建
开源Java学习 公众号 一.入门 1.简介 Kafka is a distributed,partitioned,replicated commit logservice.它提供了类似于JMS的特性 ...
- [转帖]kafka入门:简介、使用场景、设计原理、主要配置及集群搭建
kafka入门:简介.使用场景.设计原理.主要配置及集群搭建 http://www.aboutyun.com/thread-9341-1-1.html 还没看完 感觉挺好的. 问题导读: 1.zook ...
- Atitit ati licenseService 设计原理
Atitit ati licenseService 设计原理 C:\0workspace\AtiPlatf\src_atibrow\com\attilax\license\LicenseX.ja ...
- 基于 Angularjs&Node.js 云编辑器架构设计及开发实践
基于 Angularjs&Node.js 云编辑器架构设计及开发实践 一.产品背景 二.总体架构 1. 前端架构 a.前端层次 b.核心基础模块设计 c.业务模块设计 2. Node.js端设 ...
随机推荐
- iPadOS 14 memoji 无法使用 bug
iPadOS 14 memoji 无法使用 bug iPadOS 14 bug refs 如何在 iPhone 和 iPad Pro 上使用动话表情 https://support.apple.com ...
- SVG image tag
SVG image tag https://developer.mozilla.org/en-US/docs/Web/SVG/Tutorial/SVG_Image_Tag <?xml versi ...
- npm & config settings
npm & config settings how to check npm config settings https://docs.npmjs.com/cli/config $ npm c ...
- css 设置多行文本的行间距
css 设置多行文本的行间距 block element span .ticket-card-info{ line-height:16px; display: inline-block; } .tic ...
- parcel bug & not support normal import React & ReactDOM module
bug report not support normal import React & ReactDOM module, why Code Sample OK import * as Rea ...
- PAUL ADAMS ARCHITECT:薪资追不上房价美一半家庭难买房
尽管上一年度美国经济遭受重创,但美国房价依旧持续蹿扬,据最新调查显示,美国大部分地区的房价已经到了一般家庭无法负担的水准. 美国房价上涨持续强劲,主要受益美国人居家办公需求(受大环境影响,目前美国有7 ...
- 新兴公链NGK Global如何借助Defi突围?
Defi正在掀起持续不减的热度,在过去的一段时间里,以Uniswap为代表的去中心化交易所,使得以太坊重新焕发生机.币价也较以往上涨了50%有余.而且这波热度同样波及到交易所和其他公链市场. 但是波及 ...
- 开源OA办公平台搭建教程:基于nginx的快速集群部署——端口分发
主机信息 主机1:172.16.98.8(linux) 主机2:172.16.98.9(linux) 集群需求 172.16.98.8:WEB服务器,应用服务器,文件存储服务器,中心服务器 172.1 ...
- 翻译:《实用的Python编程》02_03_Formatting
目录 | 上一节 (2.2 容器) | 下一节 (2.4 序列) 2.3 格式化 虽然本节稍微有点离题,但是当处理数据时,通常想要生成结构化的输出(如表格).示例: Name Shares Price ...
- TKMybatis
TKMybatis与Mybatis-plus都是mybatis的扩展,有相同的地方,也有不同的地方. 1.导入坐标 <!--mybatis依赖--> <dependency> ...