博文推荐|多图详解 Apache Pulsar 消息存储模型
关于 Apache Pulsar
Apache Pulsar 是 Apache 软件基金会顶级项目,是下一代云原生分布式消息流平台,集消息、存储、轻量化函数式计算为一体,采用计算与存储分离架构设计,支持多租户、持久化存储、多机房跨区域数据复制,具有强一致性、高吞吐、低延时及高可扩展性等流数据存储特性。
GitHub 地址:http://github.com/apache/pulsar/
背景
Apache Pulsar 系列文章为读者们详细解释了 Pulsar 的消息保留和过期策略,本文是系列第二篇,主要从 Pulsar 设计的原理以及在 BookKeeper 中如何存储做一个梳理。
在社区中,我们经常可以看到用户有关 Backlog,storage size 和 retention 等策略的困惑,比较常见的一些问题,诸如:
- 我没有设置 Retention 策略,为什么通过 topics stats 可以查看到 storage size 远大于 backlog size?
- 我的 msg backlog size 很小,但是 storage size 确一直在增长?
- …
Pulsar 的消息模型
首先,我们先来看一下 Pulsar 的消息模型
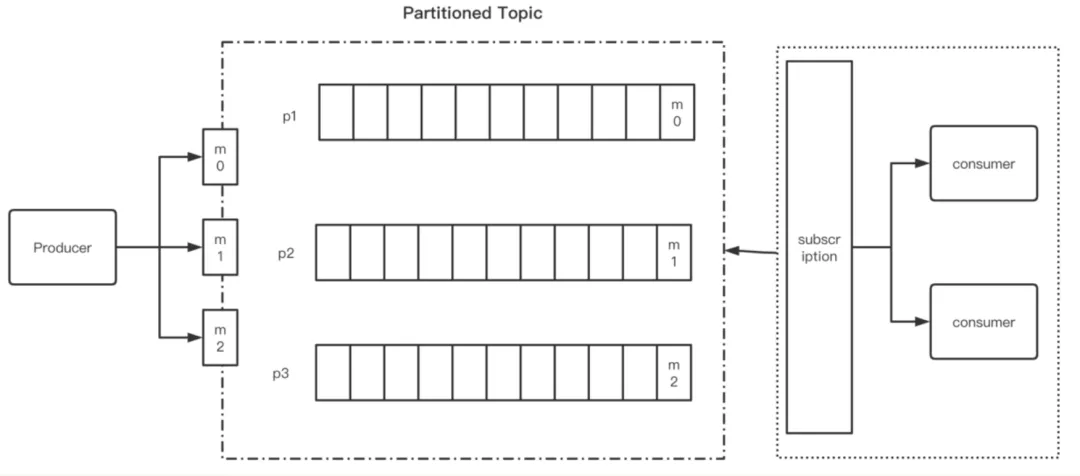
如上图所示,Pulsar 提供了最基本的 pub-sub 的处理模型。
Producer
首先 Producer 端生产消息,将消息以 append 的形式追加到 Topic 中,这里具体分发到哪一个 Topic 中,根据消息是否设置了 msg key 会有所不同。
- 设置了 msg key,消息会基于 key 做 hash,将消息分发到不同的 partitions 中
- 未设置 msg key,消息会以 round robin 的形式,分发到不同的 partitions 中
在消息分发的模型中,Pulsar 与 Kafka 类似。
Consumer
在 Consumer 之外,Pulsar 抽象了一层订阅层,用于订阅 Topic。通过订阅层的抽象,Pulsar 可以灵活的支持 Queue 和 Streaming 这两种类型的消息队列。每一个 sub 都可以拿到这个 Topic 中所有数据的完整 copy,有点类似 Kafka 中的 consumer group。根据订阅类型的不同,每一个订阅下面可以有一个或者多个 Consumer 来接收消息。
目前,Pulsar 支持如下四种消息订阅模型:
- Exclusive
- Failover
- Shared
- Key_Shared
存储模型
消息在每个 Partition Topic 的分布式日志中只存储一次
这就意味着,当 Producer 成功发送消息到 Topic 之后,这个消息只会在存储层存储一次,无论你有多少个 Subscription 订阅到这个 Topic 中,实际上操作的都是同一份数据。基于这个基础,我们可以看到 Apache Pulsar 从上到下的层级抽象概念如下图所示:
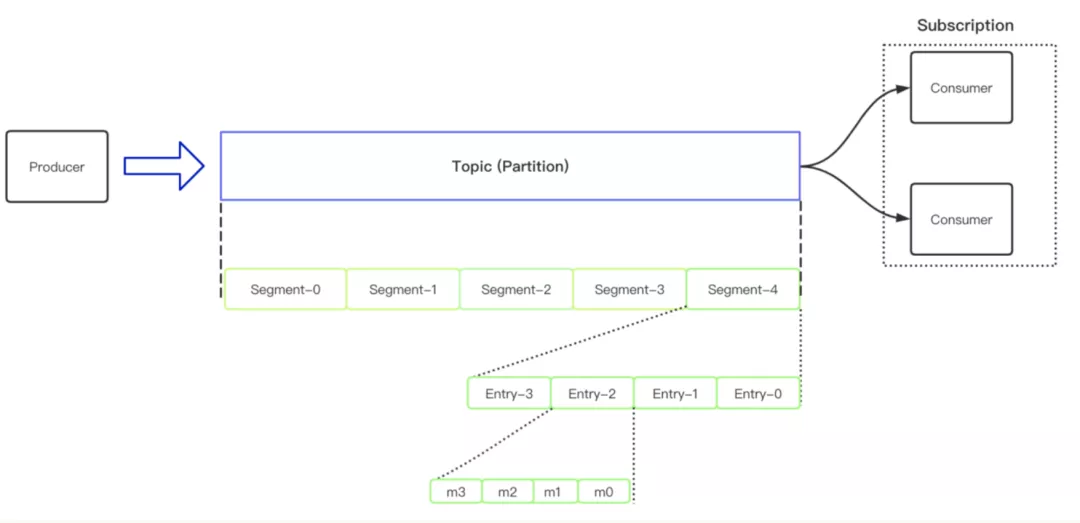
首先第一层抽象是 Topic(Partition),用来存储 Producer 追加的 messages 信息,Topic 之下对应的是一个个的 ledger,ledger 里面又划分为一个个的分片,在一个个的分片中存储了更小粒度的 ertries,entries 中存储的是 【一条】或者 【一个 batch】 的消息。
- Tips: 在 Pulsar 中,一个 batch 在 broker 端会被当作一条消息来处理,batch 解析的具体逻辑是在 consumer 端接收消息时候去操作的。
- Node: 在 Bookkeeper 中,对数据操作的最小单元是按照 segment 这个粒度来进行操作的。
为什么需要做分层抽象呢?
在这里最直白的解释其实就是,为了确保数据被在每一个 bk 节点中打的足够散,分布的足够均匀。这也是分层分片架构设计的好处之一。
Ack 机制
在 Pulsar 中支持了两种 Ack 的机制,分别是单条 Ack 和批量 Ack。单条 Ack(AckIndividual)是指 Consumer 可以根据消息的 messageID 来针对某一个特定的消息进行 Ack 操作;批量 Ack(AckCumulative)是指一次 Ack 多条消息。
订阅机制
为了更好的理解 Strorage Size 以及 Backlog, 我们首先需要去了解 Pulsar 中的订阅机制,如下图所示:
当有消息积压时,你可以通过 clear-backlog 来清除积压的消息。清除 backlog 中积压的消息是相对危险的操作,所以系统会提示你,是否确认要删除 backlog 中的消息, clear-backlog 提供了 -f(--force) 的参数来屏蔽该提示。
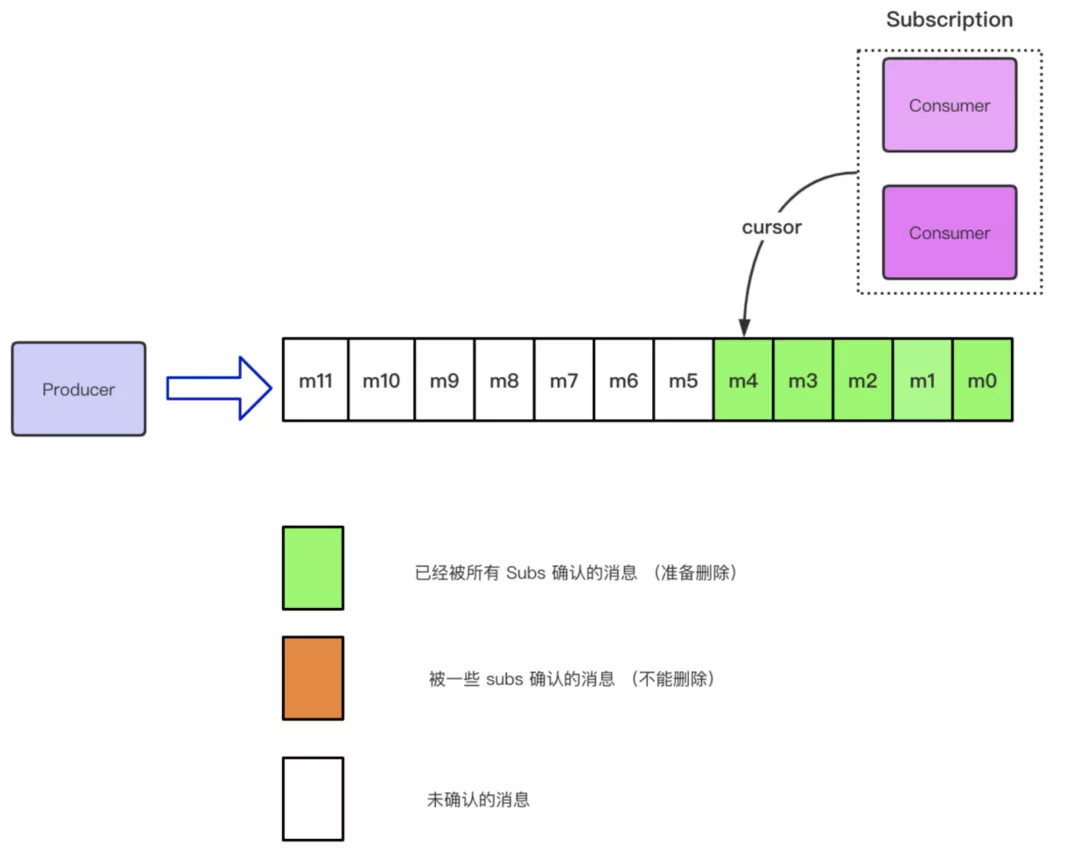
Producer 还是按照追加的形式不断往 Topic 中发送消息,Consumer 端会创建一个 Subscription 去订阅这个 Topic,当成功订阅时,会初始化一个 Cursor 指向具体的消息的位置,默认情况下是 Latest。
Cursor 是用来存储一个订阅中消费的状态信息
上图中,我们可以看到该订阅下面的 Topic 已经成功 Receive 并且 Ack 掉了 m4 这条消息。那么包含 m4 在内的所有的消息状态都会被标记为可删除的状态。在 Pulsar 中,使用 MarkDeletePosition 来标记这个位置。之后的所有消息,代表这个订阅还没有消费的消息。
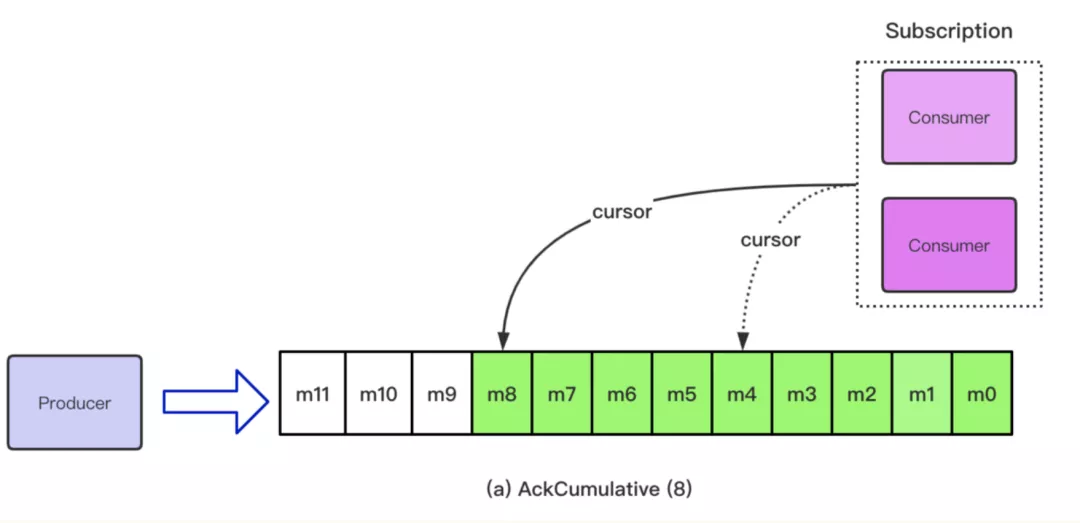
随着时间的推移,假设在 AckCumulative 的场景下,上述订阅中的 Consumer 又消费了一些消息,目前 Cursor 的位置移动到了 m8 的位置,意味着 m8 之前的消息都可以进入删除状态。
假设是在 AckIndividual 的场景下,上述订阅中的 Consumer 只消费了 m7 这条消息并且发送了 Ack 请求,m5, m6 这两条消息仍然没有被成功消费,那么目前处于可删除状态的消息是 m4 之前的消息和 m7 这条消息。也就是说,在这种场景下,由于使用单条 Ack 导致 Topic 中间出现了 Ack 的空洞。
Cursor = Offset + IndevidualDeletes, Ack 会触发 Cursor 的移动,但是不会删除任何消息
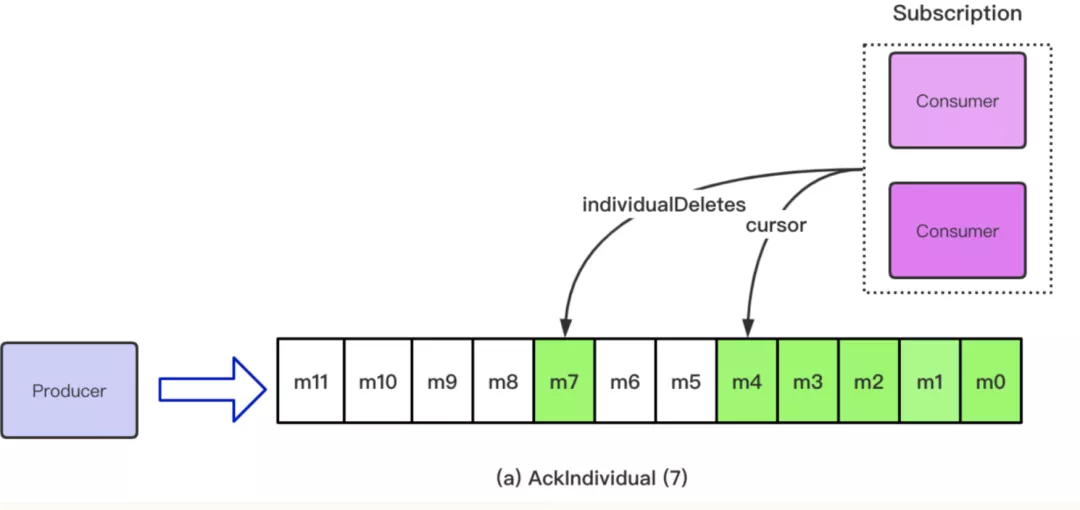
随着时间的推移,在单条 Ack 的场景下,Ack 的空洞可能会自己消失,如下图所示:
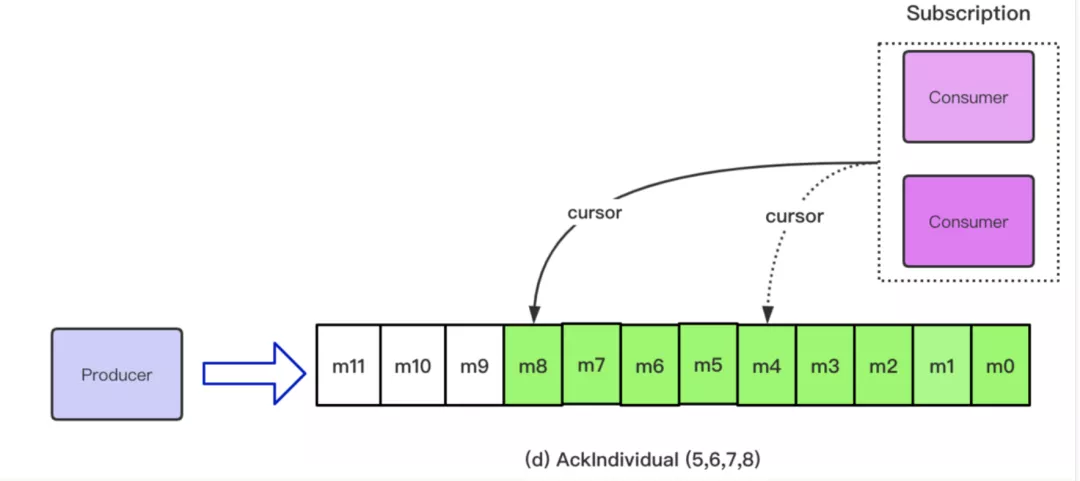
上面我们描述了,单个订阅在单条 Ack 和批量 Ack 混合的场景下,Topic 中 cursor 的移动情况。假设目前有多个 Subscription 订阅了这个 Topic,那么每一个 Subscription 都可以拿到这个 Topic 中数据的完整 Copy,也就是一个 Subscription 会在这个 Topic 中初始化一个新的 Cursor, 每一个 Cursor 之间消费的进度是没有交集、互不影响的,所以就可能出现下图中的情况:
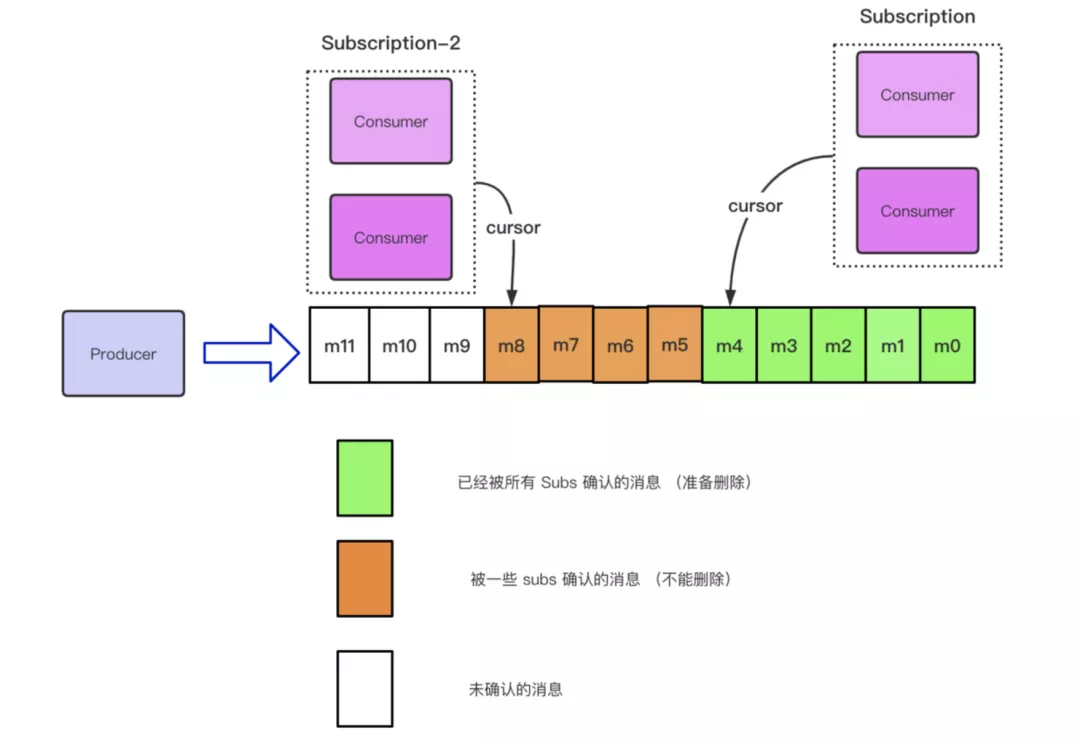
在上图中,针对该 Topic,有两个订阅:Subscription-1 和 Subscription-2。Subscription-1中的 Consumer 消费掉了 m4 之前的消息,Subscription-2 中的 Consumer 消费掉了 m8 之前的消息。而 m4-m8 之间的这四条消息,虽然被 Subscription-2 消费完成,但是 Subscription-1 还没有消费完成这部分数据,所以这部分消息还不可以被删除。目前处于可删除状态的消息是 m4 之前的消息,即这个 Topic 中消费进度最慢的那个 Subscription 所消费完成的消息。那么这就会有一个问题,假设我目前 Subscription-1 掉线了,它的 Cursor 的位置一直没有变化,这就会导致这个 Topic 中的数据一直处于不可删除的状态。
针对上述场景,Pulsar 引入了 TTL 的概念,即允许用户设置 TTL 的时间,当消息到达 TTL 指定的阈值 Cursor 仍然没有移动的话,那么会触发 TTL 的机制,将 Cursor 自动向后移到指定的位置。在这里需要注意的一点是,我们一直强调的是 TTL 会移动 Cursor 的位置,到目前为止,我们还没有提到消息删除的概念,不要将二者混淆了。TTL 会做的只是去移动 Cursor 的位置,不会有任何跟消息删除的逻辑。
Backlog
为了更好的表述 Topic 中没有被消费的数据,Pulsar 引入了 Backlog 的概念来描述这一部分消息。Backlog 可以分为如下两种形式:
- Topic Backlog: 最慢的那个订阅的 Backlog 的集合
- Subscription Backlog: 指针对单个订阅级别的没有消费的数据的集合
如下图所示:Backlog A 属于 Topic Backlog;Backlog A 属于 Subscription-1 Backlog;Backlog B 属于 Subscription-2 的 Backlog。
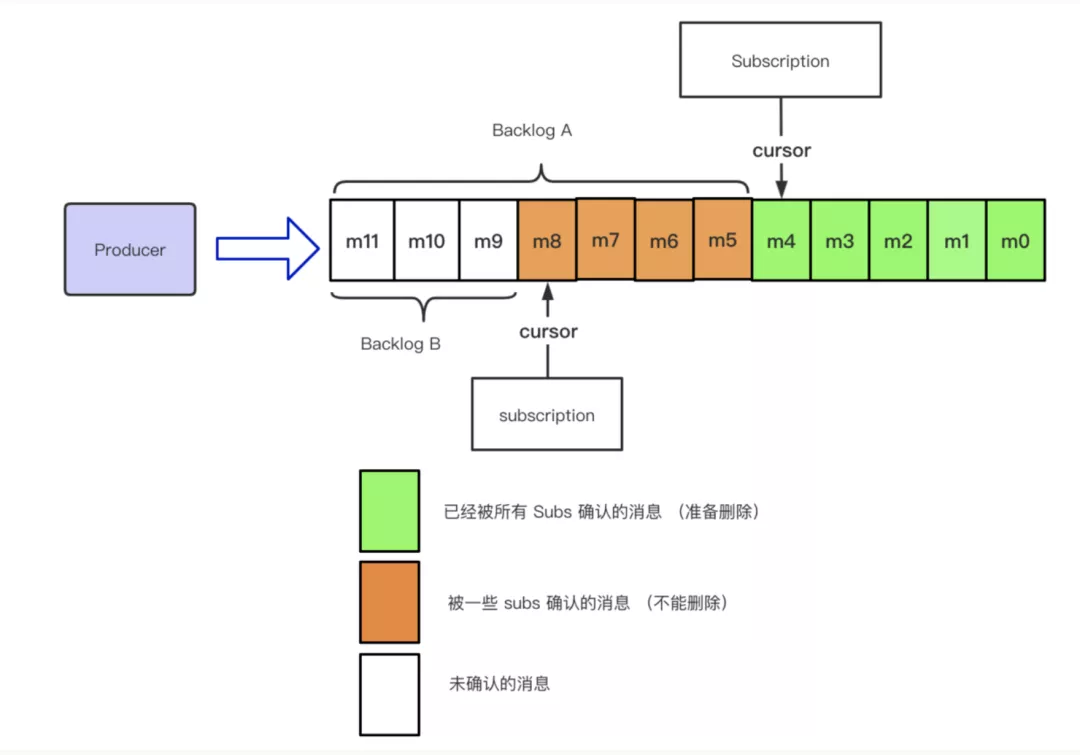
随着时间的推移,Backlog 的会不断的变化,如下图所示:
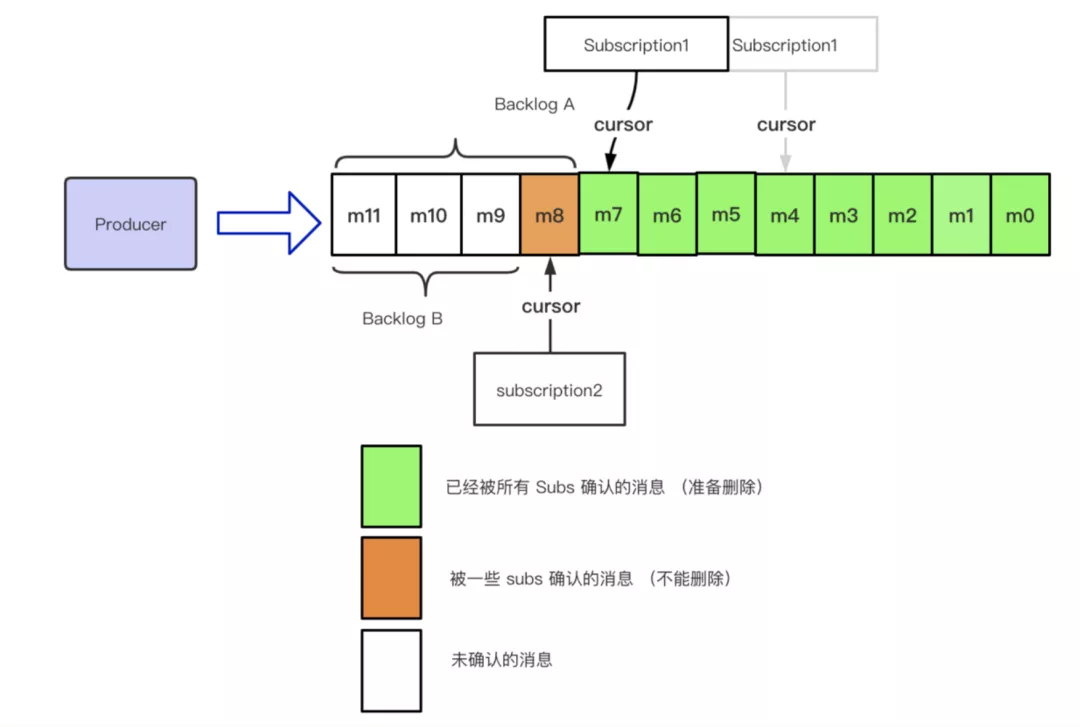
在这里需要说明的一点是,这里的 backlogSize 记录的是带 batch 的消息,也就是一个 batch 会被当作一条消息来进行处理。因为在 broker 端去解析整个 batch 会给 broker 带来一定的负担,同时浪费大量的 CPU 资源,所以,具体 batch 逻辑的解析放到了 Consumer 端来进行处理。所以 Backlog 本质上记录的是上面我们提到的 entries 的数量。
在 Pulsar 中,针对 Backlog 有两个指标,具体如下:
- msgBacklog: 记录的是所有未被 Ack 的 entries 的集合
- backlogSize:记录的是所有没有被 Ack 的消息的大小
Retention 机制
在 Apache Pulsar 中,使用了 BookKeeper 来作为存储层,允许用户将消息持久化,为了确保消息不会无限期的持久化下去,Pulsar 引入了 Retention 的机制,允许用户来配置消息持久化的策略。默认情况下,持久化的机制是关闭的,即消息被 Ack 之后,就会进入删除的逻辑。
配置 Retention 策略时,有如下两个参数可以指定:
- size:指持久化大小的阈值。0 代表不配置 Retention 大小策略,-1 代表设置的大小无限大
- time:指持久化时间的阈值。0 代表不配置 Retention 时间策略,-1 代表时间无限大
在引入 Retention 策略之后,整个 Topic 表示的视图如下所示,m0-m5 代表已经被所有订阅确认的消息并且已经超过了 Retention 策略的阈值,即这些消息正在准备删除。注意,我这里描述的是 【准备删除】具体是否可以被删除,现在还不能确定。
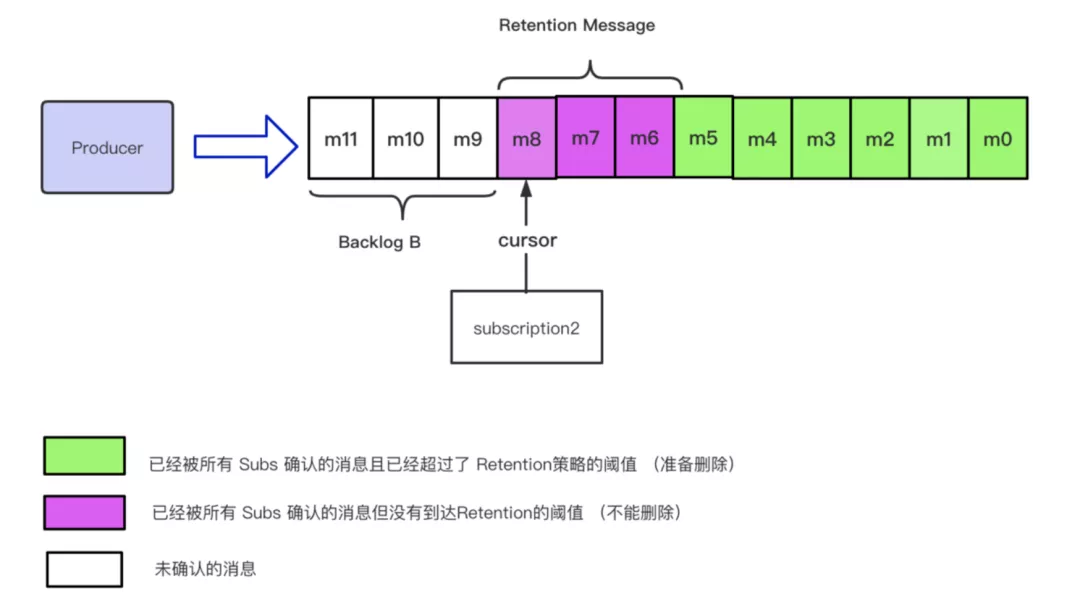
在最开始,我们从最上层的 Topic 一步步抽象到了一条具体的 msg,(在这里为了方便描述,我们忽略掉 batch 的概念,即一条 msg 等价于一个 entry)现在我们再反过来把所有的概念都叠加回去。因为在 bk 中,允许操作的最小的单元是一个 segment,所以在具体的 msg(entry)级别,是没办法针对一条消息进行删除的,删除操作需要针对一个 segment 来进行操作。如下图所示:
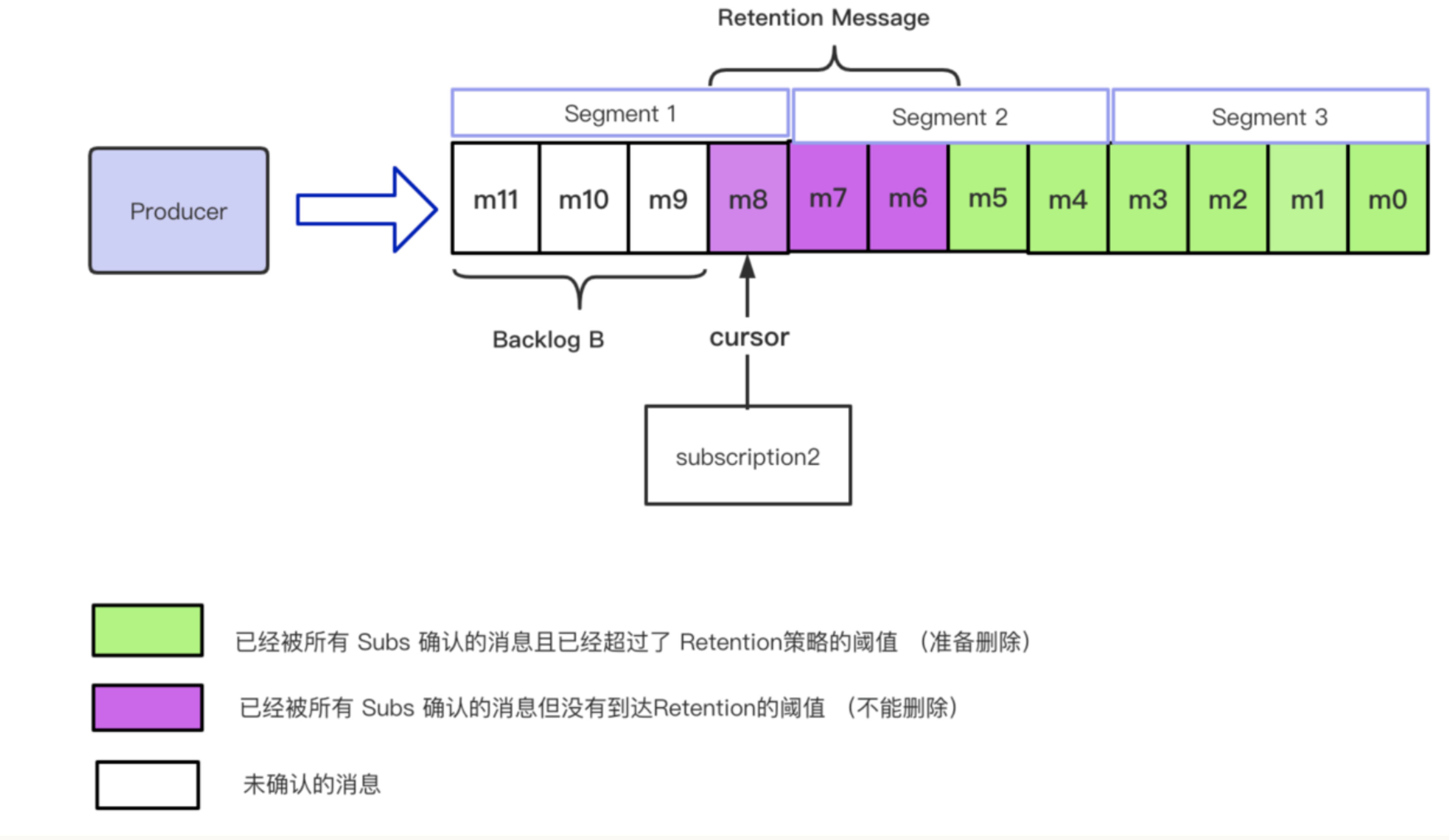
假设 m0-m3 属于 segment3;m4-m7 属于segment2;m8-m11 属于 segment1。按照上图的描述,m0-m5 的消息都可以进行删除操作, 但是 segment 2 中包含了 m6, m7 并没有达到 Retention 的阈值,所以 segment 目前还不可以被删除。
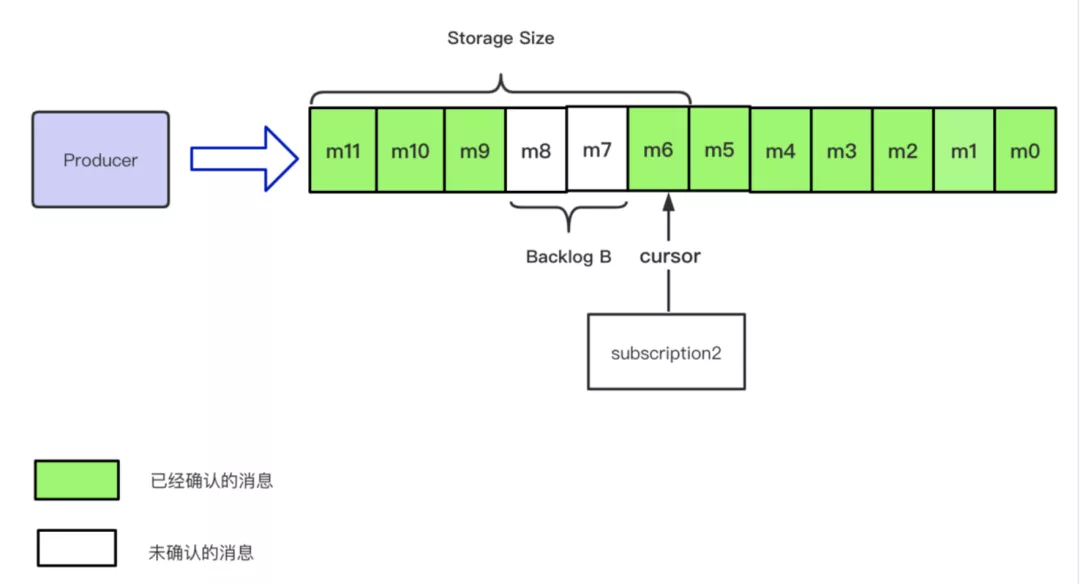
Storage Size
为了更方便的表述当前消息占用的存储空间的大小,Pulsar 引入了 storageSize 来描述整个概念。如下图所示:当 backlog B 与 storage Size 标识的消息相同时,backlogSize 等价于 storageSize。
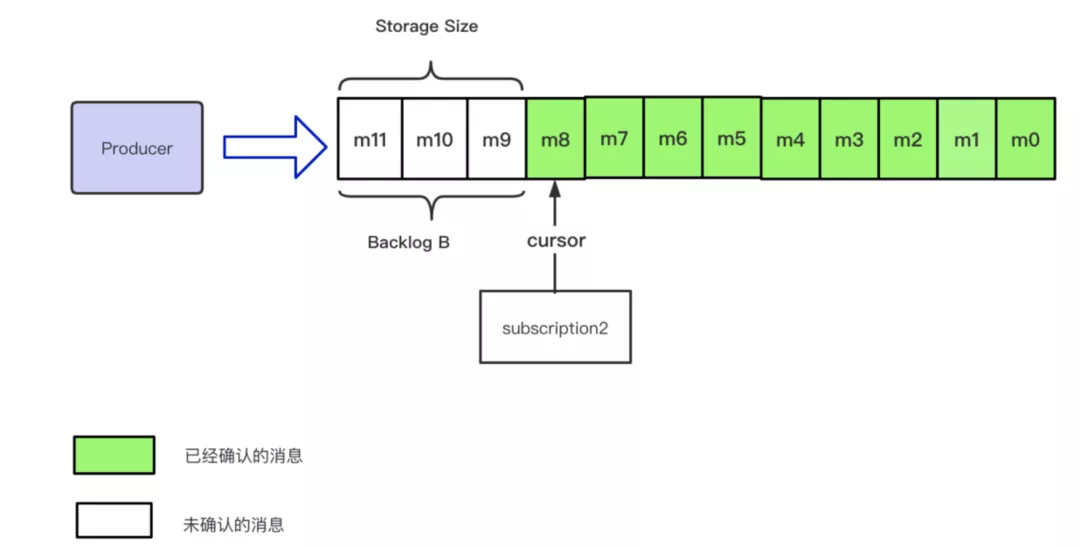
当由于引入单条 Ack,Retention 策略以及 Bookkeeper 基于 segment 删除的设定,那么很有可能造成 Storage Size 大于 backlog Size 的场景,如下图所示:
总结
- 消息在每个 Partition Topic 的分布式日志中只会存储一次
- Cursor 是用来存储一个订阅下 Consumer 的消费状态的
- Cursor 等价于 offset(kafka)+ individualDeletes
- Ack 会去更新 Topic 中 Cursor 的位置
- 当某条消息被所有订阅者都 Ack 之后,这条消息进入【可以被删除】的状态
- 所有没有被确认的消息会一直保存在 Subscription backlog 中
- TTL 可以通过设定一个时间阈值来自动更新 Cursor 的位置
- Retention 策略是用来操作那些被 Ack 之后的消息应该怎么处理
- 消息的删除是以 segment 为单位的,而不是 entry。
关于作者
冉小龙,腾讯云微服务产品中心研发工程师,Apache Pulsar Committer,Apache BookKeeper Contributor
相关推荐
博文推荐|多图详解 Apache Pulsar 消息存储模型的更多相关文章
- 转】Mahout推荐算法API详解
原博文出自于: http://blog.fens.me/mahout-recommendation-api/ 感谢! Posted: Oct 21, 2013 Tags: itemCFknnMahou ...
- [转]Mahout推荐算法API详解
Mahout推荐算法API详解 Hadoop家族系列文章,主要介绍Hadoop家族产品,常用的项目包括Hadoop, Hive, Pig, HBase, Sqoop, Mahout, Zookeepe ...
- CAS (6) —— Nginx代理模式下浏览器访问CAS服务器网络顺序图详解
CAS (6) -- Nginx代理模式下浏览器访问CAS服务器网络顺序图详解 tomcat版本: tomcat-8.0.29 jdk版本: jdk1.8.0_65 nginx版本: nginx-1. ...
- SPI总线协议及SPI时序图详解
SPI,是英语Serial Peripheral Interface的缩写,顾名思义就是串行外围设备接口.SPI,是一种高速的,全双工,同步的通信总线,并且在芯片的管脚上只占用四根线,节约了芯片的管脚 ...
- (转)CAS (4) —— CAS浏览器SSO访问顺序图详解(CAS Web Flow Diagram by Example)
CAS (4) —— CAS浏览器SSO访问顺序图详解(CAS Web Flow Diagram by Example) tomcat版本: tomcat-8.0.29 jdk版本: jdk1.8.0 ...
- SPI总线协议及SPI时序图详解【转】
转自:https://www.cnblogs.com/adylee/p/5399742.html SPI,是英语Serial Peripheral Interface的缩写,顾名思义就是串行外围设备接 ...
- 十图详解tensorflow数据读取机制(附代码)转知乎
十图详解tensorflow数据读取机制(附代码) - 何之源的文章 - 知乎 https://zhuanlan.zhihu.com/p/27238630
- CAS (4) —— CAS浏览器SSO访问顺序图详解(CAS Web Flow Diagram by Example)
CAS (4) -- CAS浏览器SSO访问顺序图详解(CAS Web Flow Diagram by Example) tomcat版本: tomcat-8.0.29 jdk版本: jdk1.8.0 ...
- UML类图详解_关联关系_一对多
对于一对多的示例,可以想象一个账户可以多次申购.在申购的时候没有固定上限,下限为0,那么就可以使用容器类(container class)来搞,最常见的就是vector了. 下面我们来看一个“一对多” ...
随机推荐
- Web 全栈开发 MySQL 面试题
Web 全栈开发 MySQL 面试题 MySQL MySQL 读写分离 读写分离原理 MySQL的主从复制和MySQL的读写分离两者有着紧密联系,首先部署主从复制,只有主从复制完了,才能在此基础上进行 ...
- GitHub Packages
GitHub Packages https://github.com/xgqfrms?tab=packages // Step 1: Use `publishConfig` option in you ...
- vue & template & v-else & v-for bug
vue & template & v-else & v-for bug nested table bug https://codepen.io/xgqfrms/pen/wvaG ...
- perl 打印目录结构
更多 #!/usr/bin/perl # 递归打印目录结构 use v5.26; use strict; use utf8; use autodie; use warnings; use Encode ...
- CNN专访灵石CTO:Baccarat流动性挖矿能否持续?
近日,CNN记者Robert独家专访Baccarat的项目团队CTO STEPHEN LITAN,跟他特别聊了聊DeFi的近况. 以下是专访全文: Robert:推出Baccarat的契机是什么? S ...
- SSL/TLS协议详解(上):密码套件,哈希,加密,密钥交换算法
本文转载自SSL/TLS协议详解(上):密码套件,哈希,加密,密钥交换算法 导语 作为一名安全爱好者,我一向很喜欢SSL(目前是TLS)的运作原理.理解这个复杂协议的基本原理花了我好几天的时间,但只要 ...
- mysql 8.0.18 小白安装教程
1. 下载 官网下载:https://dev.mysql.com/downloads/mysql/ 嫌官网网速慢可以加q群,在群文件里下载: 1.下载第一个download 2.解压在自己建的目录(各 ...
- TERSUS无代码开发(笔记02)-简单实例加法
简单实例加法 1.用户端元件(显示元件)(40个) 图标 英文名称 元件名称 使用说明 服务器端 客户端 Pane 显示块 是一个显示块,是HTML的div标签 √ Row 行 行元件中的显示元件 ...
- Vue学习笔记-Vue.js-2.X 学习(五)===>脚手架Vue-CLI(PyCharm)
Vue项目在pycharm中配置 退出运行: ctrl+c Vue学习笔记-Vue.js-2.X 学习(六)===>脚手架Vue-CLI(项目说明)
- Redis集群简介及部署
1简介 在 Redis 3.0 之前,使用 哨兵(sentinel)机制来监控各个节点之间的状态.Redis Cluster 是 Redis 的 分布式解决方案,在 3.0 版本正式推出,有效地解决了 ...