图解Janusgraph系列-图数据底层序列化源码分析(Data Serialize)
图解Janusgraph系列-图数据底层序列化源码分析(Data Serialize)
大家好,我是洋仔,JanusGraph图解系列文章,实时更新~
图数据库文章总目录:
- 整理所有图相关文章,请移步(超链):图数据库系列-文章总目录
- 地址:https://liyangyang.blog.csdn.net/article/details/111031257
源码分析相关可查看github(码文不易,求个star~): https://github.com/YYDreamer/janusgraph
下述流程高清大图地址:https://www.processon.com/view/link/5f471b2e7d9c086b9903b629
版本:JanusGraph-0.5.2
转载文章请保留以下声明:
作者:洋仔聊编程
微信公众号:匠心Java
原文地址:https://liyangyang.blog.csdn.net/
正文
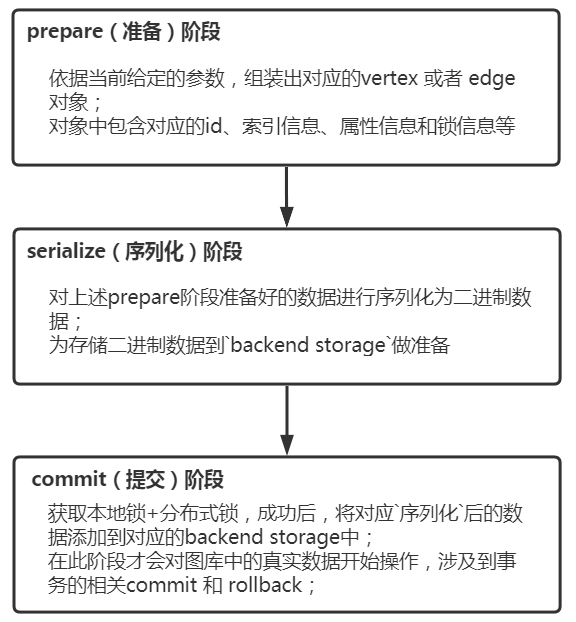
JanusGraph的数据导入过程主要分为三阶段:prepare(准备)、serialize(序列化)、commit(提交);不同阶段有不同的作用,如下:
下面我们分别从导入vertex节点和edge边两部分来分析写流程
建议依据源码同步看本文章,便于理解!
一:vertex数据写流程
下面vertex节点数据的导入,
prepare阶段
主要是依据当前给定的参数,组装出对应的vertex 或者 edge 对象;对象中包含对应的id、索引信息、属性信息和锁信息等;
过程中包含以下几种作用:
- 默认添加
vertex exist属性,值为true,标识当前节点是否存在 - 默认添加
label edge边,标识当前的节点 或者 边是什么label - 生成
vertex、edge、property的全局分布式唯一id - 自定义属性验证是否满足唯一性约束
主要流程如下图(建议依照源码一块查看,上述github地址已给出):

serialize阶段
主要是对上述prepare阶段准备好的数据进行序列化为二进制数据,为存储二进制数据到backend storage做准备; 另外获取本地锁 + 分布式锁数据插入(此处只是将数据插入到Hbase,插入成功并不代表获取成功)
过程中包含以下几种作用:
- 序列化所有
relation数据并存储,包含属性、label edge、normal edge - 获取属性对应
index需要更新的数据,并序列化存储; 包含组合索引和mixed index的处理 - 获取基于图实例的本地锁
- 获取了本地锁的前提前,获取
edge lock和index lock分布式锁(此处的获取锁只是将对应的KLV存储到Hbase中!存储成功并不代表获取锁成功,在commit阶段才会去检查是不是获取分布式锁成功!)
主要流程如下图:

commit阶段
主要是获取本地锁+分布式锁成功后,将对应序列化后的数据添加到对应的backend storage中;完成图数据插入过程! 在此阶段才会对图库中的真实数据开始影响,才会涉及到事务的回滚机制;
过程中包含以下几种作用:
- 判断分布式锁的状态,获取成功则进行数据持久化;不成功则失败
- 持久化
relation数据 - 持久化
index数据,包含组合索引存储到第三方存储;mixed index存储到第三方索引库中 - 删除对应的本地锁 和 分布式锁的占用
主要流程如下图:

二:edge数据写流程
针对于edge的写数据流程,整体的流程和vertex节点的数据写入相同,有几点不同,下面一一列出:
1、生成分布式唯一id的过程
导入Edge数据在生成edge的唯一id时,partition id的获取不再是随机获取,而是尝试获取边对应的out vertex的partition id; id的组成部分也不同,没有idPadding部分;
具体解释请看:《JanusGraph-分布式id生成策略》文章
2、在edge的导入中,没有同vertex数据导入,添加默认的节点是否存在属性和节点和节点对应label的边
3、获取edge对应的属性的index update时不同
在导入vertex数据时,将节点对应的属性作为relation存放在addRelation中,然后收集所有的属性relation循环获取index uodate;如下伪代码:
for (InternalRelation add : Iterables.filter(addedRelations,filter)) {
if (add.isProperty()) mutatedProperties.put(vertex,add); // 此处只操作属性类型的
mutations.put(vertex.longId(), add);
}
// 此处,收集节点对应属性对应的索引需要更新的数据、增加或删除节点时才有作用; 针对于插入edge的操作,不涉及此处
for (InternalVertex v : mutatedProperties.keySet()) {
indexUpdates.addAll(indexSerializer.getIndexUpdates(v,mutatedProperties.get(v)));
}
而在edge数据导入中,只将edge这条边作为relation插入到addRelation中,所以无法获取属性relation,转而通过收集过程中,对每个edge对应的所有属性进行分别获取;如下伪代码:
for (InternalRelation add : Iterables.filter(addedRelations,filter)) {
if (add.isProperty()) mutatedProperties.put(vertex,add); // 此处只操作属性类型的
mutations.put(vertex.longId(), add);
// 获取边包含的属性;在节点插入时没有作用,插入边数据时,获取边上的属性对应的索引; 只有edge操作中包含边属性,并且包含索引!
indexUpdates.addAll(indexSerializer.getIndexUpdates(add));
}
4、edge对应的relation数据,也就是当前插入的这个边,需要被序列化两次
一次是源节点+边关系,一次是目标节点+边关系(因为jansugraph是通过edge cut方式存储图数据的)
5、edge的数据插入过程中,edge的序列化组成部分不同于vertex的序列化组成部分;
不同点请看《Janusgraph-存储结构》文章
6、edge的数据插入中,edge的property和vertex的property组成不同!
edge中针对于sort key和signature key配置的属性,只将property value存储在对应位置。其他未被配置的属性值包含proeprty key label id + property value;
不同于vertex数据中的属性组成包含:proeprty key label id + property 唯一id +property value
三:源码分析
源码分析已经push到github:https://github.com/YYDreamer/janusgraph
数据写入的流程源码过多,就不在文章中给出分析了,具体请看github中源码分析注释吧
四:应用
基于数据序列化导入的源码博主将图数据的序列化逻辑抽取出来,生成一个工具包;
主要用于图数据的迁移和图数据库的初始化,适用于大数据量的导入,主要流程如下:
- 生成schema到图中
- 获取schema信息,缓存到内存中
- 调用api占用对应的id blocker,用于离线数据的分布式唯一id生成
- 调用抽取的序列化逻辑序列化节点和边数据
- 生成Hfile
- 将hfile导入到Hbase中
上述流程已经经过严格的验证并在生产环境中使用,具体之后会再出一篇文章介绍一下详细的设计与流程
五:总结
对于JanusGraph图数据的写入,主要分为3部分:
- schema的创建
- vertex节点数据的导入
- edge边数据的导入
上述主要分析了vertex和edge的数据导入,大致流程相似;也分析了两部分导入数据的差异;
其中涉及的分布式唯一id的生成逻辑 和 锁机制获取的逻辑,请看《图解Janusgraph系列-Lock锁机制(本地锁+分布式锁)分析》和《图解Janusgraph系列-分布式id生成策略分析》两篇文章!
针对于第三方索引的序列化存储逻辑,逻辑相对简单,此处没有给出,具体读者可以自主分析一下源码
码字不易,求个赞和star~
图解Janusgraph系列-图数据底层序列化源码分析(Data Serialize)的更多相关文章
- Eureka 系列(04)客户端源码分析
Eureka 系列(04)客户端源码分析 [TOC] 0. Spring Cloud 系列目录 - Eureka 篇 在上一篇 Eureka 系列(01)最简使用姿态 中对 Eureka 的简单用法做 ...
- Golang package轻量级KV数据缓存——go-cache源码分析
作者:Moon-Light-Dream 出处:https://www.cnblogs.com/Moon-Light-Dream/ 转载:欢迎转载,但未经作者同意,必须保留此段声明:必须在文章中给出原文 ...
- Spring系列28:@Transactional事务源码分析
本文内容 @Transactional事务使用 @EnableTransactionManagement 详解 @Transactional事务属性的解析 TransactionInterceptor ...
- Django(44)drf序列化源码分析(1)
序列化与反序列化 一般后端数据返回给前端的数据格式都是json格式,简单易懂,但是我们使用的语言本身并不是json格式,像我们使用的Python如果直接返回给前端,前端用的javascript语言 ...
- 大数据之Oozie——源码分析(一)程序入口
工作中发现在oozie中使用sqoop与在shell中直接调度sqoop性能上有很大的差异.为了更深入的探索其中的缘由,开始了oozie的源码分析之路.今天第一天阅读源码,由于没有编译成功,不能运行测 ...
- Java 集合系列(四)—— ListIterator 源码分析
以脑图的形式来展示Java集合知识,让零碎知识点形成体系 Iterator 对比 Iterator(迭代器)是一种设计模式,是一个对象,用于遍历集合中的所有元素. Iterator 包含四个方法 ...
- Redis学习之底层链表源码分析
Redis底层链表的源码分析: 一.链表结点的结构(单个结点): // listNode 双端链表节点 typedef struct listNode { // 前置节点 struct listNod ...
- vue系列---snabbdom.js使用及源码分析(九)
一:什么是snabbdom? 在学习Vue或React中,我们了解最多的就是虚拟DOM,虚拟DOM可以看作是一颗模拟了DOM的Javascript树,主要是通过vnode实现一个无状态的组件,当组件状 ...
- Spring源码系列(二)--bean组件的源码分析
简介 spring-bean 组件是 Spring IoC 的核心,我们可以使用它的 beanFactory 来获取所需的对象,对象的实例化.属性装配和初始化等都可以交给 spring 来管理. 本文 ...
随机推荐
- 视频剪辑软件Camtasia的快捷键大全
今天来给大家介绍一下Camtasia快捷键的相关内容,Camtasia也是一个十分好用的电脑屏幕录制与视频剪辑制作软件了,可能有些朋友用过,毕竟它在视频录制与制作上确实比较好用. 首先在菜单栏中点击& ...
- 无效的HTTP_主机头Invalid HTTP_HOST header: '192.168.56.100:8888'. You may need to add '192.168.56.100' to ALLOWED_HOSTS.
Invalid HTTP_HOST header: '192.168.56.100:8888'. You may need to add '192.168.56.100' to ALLOWED_HOS ...
- HDU4632 Palindrome subsequence
标签(空格分隔): 区间qp Palindrome subsequence \[求一个string的 回文子序列 的个数 \] 少废话,上代码. #include<bits/stdc++.h&g ...
- C语言讲义——链表的实现
节点(结构体描述) struct Node { int _id; char s[50]; struct Node* pre;// 指向前一个节点的地址 struct Node* next;// 指向下 ...
- python办公入门7:xlwt
xlwt写入excel步骤 创建工作簿 创建工作表 填充工作表内容 保存文件 1 import xlwt 2 3 #创建工作簿 4 wb=xlwt.Workbook() 5 #创建工作表 6 ws=w ...
- Java lambda 分组后多列求和
主要思路是reducing,可以像sql一样分组后多列求和处理成新对象等: select code,max(name)as name,sum(chengJi)as chengJi,sum(age)as ...
- 第一次UML作业
这个作业属于哪个课程 https://edu.cnblogs.com/campus/fzzcxy/2018SE2/ 这个作业要求在哪里 https://edu.cnblogs.com/campus/f ...
- 冲刺随笔——Day_Nine
这个作业属于哪个课程 软件工程 (福州大学至诚学院 - 计算机工程系) 这个作业要求在哪里 团队作业第五次--Alpha冲刺 这个作业的目标 团队进行Alpha冲刺 作业正文 正文 其他参考文献 无 ...
- python3 通过 pybind11 使用Eigen加速代码
python是很容易上手的编程语言,但是有些时候使用python编写的程序并不能保证其运行速度(例如:while 和 for),这个时候我们就需要借助c++等为我们的代码提速.下面是我使用pybind ...
- maven私服拉取jar失败(内网)
解决方案: 1.私服没jar,找私服负责人添加 2.私服有拉不下来,重启nexus服务端(负责人做) 3.本地有jar但是idea中没找到,先执行一下reimport,不行的话,随意修改下pom文件, ...