SQL优化之SQL 进阶技巧(下)
上文( SQL优化之SQL 进阶技巧(上) )我们简述了 SQL 的一些进阶技巧,一些朋友觉得不过瘾,我们继续来下篇,再送你 10 个技巧
一、 使用延迟查询优化 limit [offset], [rows]
经常出现类似以下的 SQL 语句:
SELECT * FROM film LIMIT 100000, 10
offset 特别大!
这是我司出现很多慢 SQL 的主要原因之一,尤其是在跑任务需要分页执行时,经常跑着跑着 offset 就跑到几十万了,导致任务越跑越慢。
LIMIT 能很好地解决分页问题,但如果 offset 过大的话,会造成严重的性能问题,原因主要是因为 MySQL 每次会把一整行都扫描出来,扫描 offset 遍,找到 offset 之后会抛弃 offset 之前的数据,再从 offset 开始读取 10 条数据,显然,这样的读取方式问题。
可以通过延迟查询的方式来优化
假设有以下 SQL,有组合索引(sex, rating)
SELECT <cols> FROM profiles where sex='M' order by rating limit 100000, 10;则上述写法可以改成如下写法
SELECT <cols>
FROM profiles
inner join
(SELECT id form FROM profiles where x.sex='M' order by rating limit 100000, 10)
as x using(id);
这里利用了覆盖索引的特性,先从覆盖索引中获取 100010 个 id,再丢充掉前 100000 条 id,保留最后 10 个 id 即可,丢掉 100000 条 id 不是什么大的开销,所以这样可以显著提升性能
二、 利用 LIMIT 1 取得唯一行
数据库引擎只要发现满足条件的一行数据则立即停止扫描,,这种情况适用于只需查找一条满足条件的数据的情况
三、 注意组合索引,要符合最左匹配原则才能生效
假设存在这样顺序的一个联合索引“col_1, col_2, col_3”。这时,指定条件的顺序就很重要。
○ SELECT * FROM SomeTable WHERE col_1 = 10 AND col_2 = 100 AND col_3 = 500;
○ SELECT * FROM SomeTable WHERE col_1 = 10 AND col_2 = 100 ;
× SELECT * FROM SomeTable WHERE col_2 = 100 AND col_3 = 500 ;前面两条会命中索引,第三条由于没有先匹配 col_1,导致无法命中索引, 另外如果无法保证查询条件里列的顺序与索引一致,可以考虑将联合索引 拆分为多个索引。
四、使用 LIKE 谓词时,只有前方一致的匹配才能用到索引(最左匹配原则)
× SELECT * FROM SomeTable WHERE col_1 LIKE '%a';
× SELECT * FROM SomeTable WHERE col_1 LIKE '%a%';
○ SELECT * FROM SomeTable WHERE col_1 LIKE 'a%';
上例中,只有第三条会命中索引,前面两条进行后方一致或中间一致的匹配无法命中索引
五、 简单字符串表达式
模型字符串可以使用 _ 时, 尽可能避免使用 %, 假设某一列上为 char(5)
不推荐
SELECT
first_name,
last_name,
homeroom_nbr
FROM Students
WHERE homeroom_nbr LIKE 'A-1%';推荐
SELECT first_name, last_name
homeroom_nbr
FROM Students
WHERE homeroom_nbr LIKE 'A-1__'; --模式字符串中包含了两个下划线六、尽量使用自增 id 作为主键
比如现在有一个用户表,有人说身份证是唯一的,也可以用作主键,理论上确实可以,不过用身份证作主键的话,一是占用空间相对于自增主键大了很多,二是很容易引起频繁的页分裂,造成性能问题(什么是页分裂,请参考这篇文章)
主键选择的几个原则:自增,尽量小,不要对主键进行修改
七、如何优化 count(*)
使用以下 sql 会导致慢查询
SELECT COUNT(*) FROM SomeTable
SELECT COUNT(1) FROM SomeTable原因是会造成全表扫描,有人说 COUNT(*) 不是会利用主键索引去查找吗,怎么还会慢,这就要谈到 MySQL 中的聚簇索引和非聚簇索引了,聚簇索引叶子节点上存有主键值+整行数据,非聚簇索叶子节点上则存有辅助索引的列值 + 主键值,如下
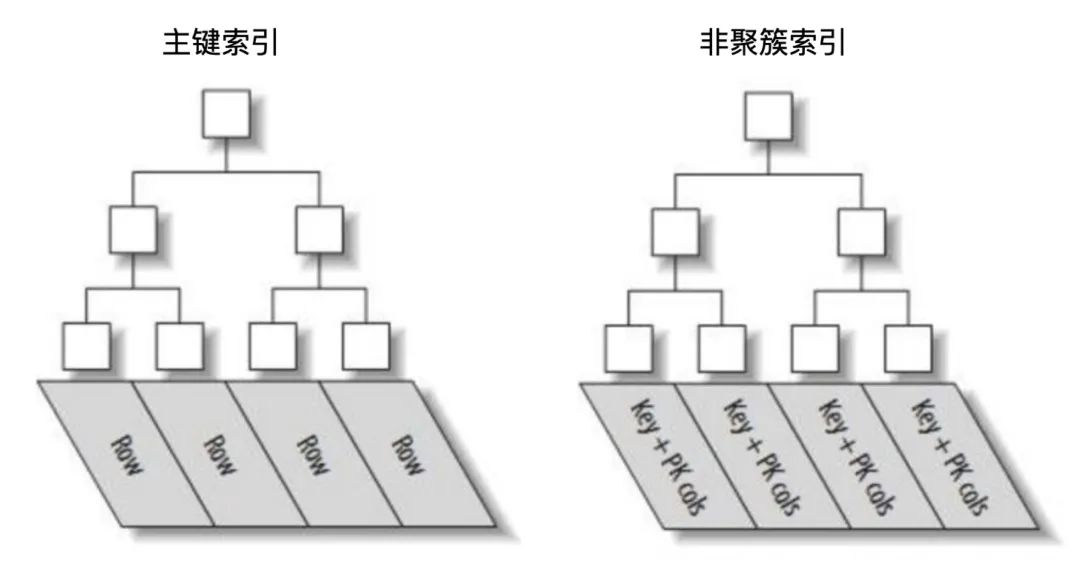
所以就算对 COUNT(*) 使用主键查找,由于每次取出主键索引的叶子节点时,取的是一整行的数据,效率必然不高,但是非聚簇索引叶子节点只存储了「列值 + 主键值」,这也启发我们可以用非聚簇索引来优化,假设表有一列叫 status, 为其加上索引后,可以用以下语句优化:
SELECT COUNT(status) FROM SomeTable有人曾经测过(见文末参考链接),假设有 100 万行数据,使用聚簇索引来查找行数的,比使用 COUNT(*) 查找速度快 10 几倍。不过需要注意的是通过这种方式无法计算出 status 值为 null 的那些行
如果主键是连续的,可以利用 MAX(id) 来查找,MAX 也利用到了索引,只需要定位到最大 id 即可,性能极好,如下,秒现结果
SELECT MAX(id) FROM SomeTable说句题句话,有人说用 MyISAM 引擎调用 COUNT(*) 非常快,那是因为它提前把行数存在磁盘中了,直接拿,当然很快,不过如果有 WHERE 的限制,用 COUNT(*) 还是很慢!
八、避免使用 SELECT * ,尽量利用覆盖索引来优化性能
SELECT * 会提取出一整行的数据,如果查询条件中用的是组合索引进行查找,还会导致回表(先根据组合索引找到叶子节点,再根据叶子节点上的主键回表查询一整行),降低性能,而如果我们所要的数据就在组合索引里,只需读取组合索引列,这样网络带宽将大大减少,假设有组合索引列 (col_1, col_2)
推荐用
SELECT col_1, col_2
FROM SomeTable
WHERE col_1 = xxx AND col_2 = xxx不推荐用
SELECT *
FROM SomeTable
WHERE col_1 = xxx AND col_2 = xxx九、 如有必要,使用 force index() 强制走某个索引
业务团队曾经出现类似以下的慢 SQL 查询
SELECT *
FROM SomeTable
WHERE `status` = 0
AND `gmt_create` > 1490025600
AND `gmt_create` < 1490630400
AND `id` > 0
AND `post_id` IN ('67778', '67811', '67833', '67834', '67839', '67852', '67861', '67868', '67870', '67878', '67909', '67948', '67951', '67963', '67977', '67983', '67985', '67991', '68032', '68038'/*... omitted 480 items ...*/)
order by id asc limit 200;post_id 也加了索引,理论上走 post_id 索引会很快查询出来,但实际通过 EXPLAIN 发现走的却是 id 的索引(这里隐含了一个常见考点,在多个索引的情况下, MySQL 会如何选择索引),而 id > 0 这个查询条件没啥用,直接导致了全表扫描, 所以在有多个索引的情况下一定要慎用,可以使用 force index 来强制走某个索引,以这个例子为例,可以强制走 post_id 索引,效果立杆见影。
这种由于表中有多个索引导致 MySQL 误选索引造成慢查询的情况在业务中也是非常常见,一方面是表索引太多,另一方面也是由于 SQL 语句本身太过复杂导致, 针对本例这种复杂的 SQL 查询,其实用 ElasticSearch 搜索引擎来查找更合适,有机会到时出一篇文章说说。
十、 使用 EXPLAIN 来查看 SQL 执行计划
上个点说了,可以使用 EXPLAIN 来分析 SQL 的执行情况,如怎么发现上文中的最左匹配原则不生效呢,执行 「EXPLAIN + SQL 语句」可以发现 key 为 None ,说明确实没有命中索引

我司在提供 SQL 查询的同时,也贴心地加了一个 EXPLAIN 功能及 sql 的优化建议,建议各大公司效仿 ^_^,如图示
十一、 批量插入,速度更快
当需要插入数据时,批量插入比逐条插入性能更高
推荐用
-- 批量插入
INSERT INTO TABLE (id, user_id, title) VALUES (1, 2, 'a'),(2,3,'b');不推荐用
INSERT INTO TABLE (id, user_id, title) VALUES (1, 2, 'a');
INSERT INTO TABLE (id, user_id, title) VALUES (2,3,'b');
批量插入 SQL 执行效率高的主要原因是合并后日志量 MySQL 的 binlog 和 innodb 的事务让日志减少了,降低日志刷盘的数据量和频率,从而提高了效率
十二、 慢日志 SQL 定位
前面我们多次说了 SQL 的慢查询,那么该怎么定位这些慢查询 SQL 呢,主要用到了以下几个参数
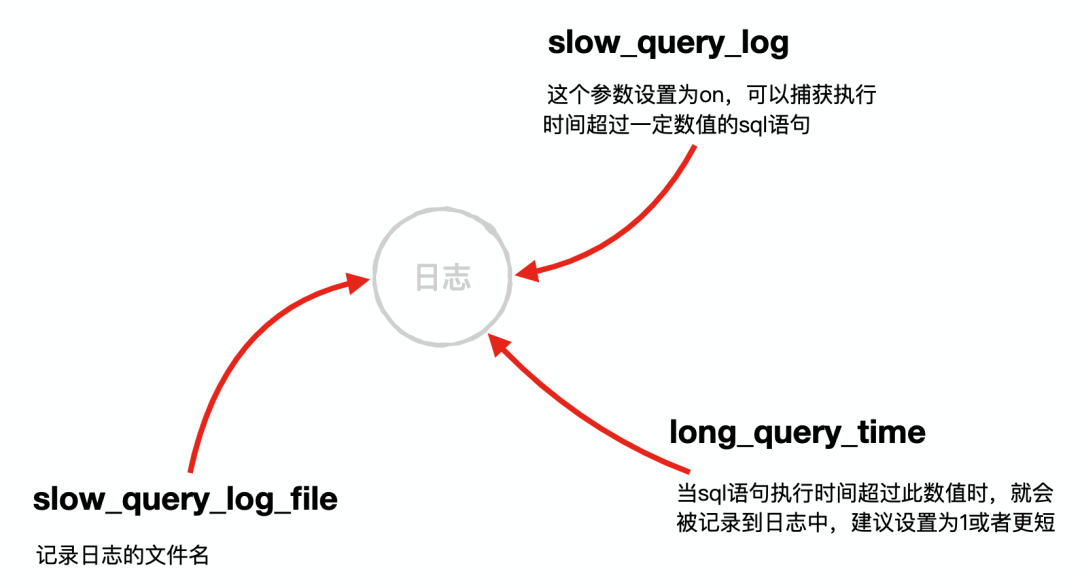
这几个参数一定要配好,再根据每条慢查询对症下药,像我司每天都会把这些慢查询提取出来通过邮件给形式发送给各个业务团队,以帮忙定位解决
总结
业务生产中可能还有很多 CASE 导致了慢查询,其实细细品一下,都会发现这些都和 MySQL 索引的底层数据 B+ 树 有莫大的关系,强烈建议大家看一下我的另一篇介绍 B+ 树的文章,好评如潮!相信大家看了之后,以上出现的问题会有一个更深层次的理解,掌握底层,以不变应万变!
相关文章
SQL优化之SQL 进阶技巧(下)的更多相关文章
- SQL优化之SQL 进阶技巧(上)
由于工作需要,最近做了很多 BI 取数的工作,需要用到一些比较高级的 SQL 技巧,总结了一下工作中用到的一些比较骚的进阶技巧,特此记录一下,以方便自己查阅,主要目录如下: SQL 的书写规范 SQL ...
- [terry笔记]Oracle SQL 优化之sql tuning advisor (STA)
前言:经常可以碰到优化sql的需求,开发人员直接扔过来一个SQL让DBA优化,然后怎么办? 当然,经验丰富的DBA可以从各种方向下手,有时通过建立正确索引即可获得很好的优化效果,但是那些复杂SQL错综 ...
- SQL优化(SQL TUNING)可大幅提升性能的实战技巧之一——让计划沿着索引跑
我们进行SQL优化时,经常会碰到对大量数据集进行排序,然后从排序后的集合取前部分结果的需求,这种情况下,当我们按照常规思路去写SQL时,系统会先读取过滤获得所有集合,然后进行排序,再从排序结果取出极少 ...
- SQL优化- 数据库SQL优化——使用EXIST代替IN
数据库SQL优化——使用EXIST代替IN 1,查询进行优化,应尽量避免全表扫描 对查询进行优化,应尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索引 . 尝试下面的 ...
- Oracle自带工具sql优化集-SQL Tuning Advisor (使用心得体会)
如何有效的诊断和监控高负载的SQL对于DBA来说并非是件容易的事情,对SQL语句手工调优需要很多的经验和技巧, 结合个人经验常见如下问题: . 对SQL语句本身进行优化以便获得更优的 ...
- 【SQL优化】SQL优化工具
SQLAdvisor 是由美团点评公司北京DBA团队开发维护的 SQL 优化工具:输入SQL,输出索引优化建议. 它基于 MySQL 原生词法解析,再结合 SQL 中的 where 条件以及字段选择度 ...
- oracle11g中SQL优化(SQL TUNING)新特性之SQL Plan Management(SPM)
1. 简介 Oracle Database11gR1引进了SQL PlanManagement(简称SPM),一套允许DBA捕获和保持任意SQL语句执行计划最优的新工具,这样,限制了刷新优化器统计 ...
- Oracle12c中SQL优化(SQL TUNING)新特性之SQL计划指令
SQL计划指令是Oracle12c中自适应查询优化的功能之一.SQL计划指令就像“额外的提醒” ,用以提醒优化器你先前选择了的计划并不是最优的,典型的是因为错误的势评估.错误的势评估往往是由统计信息缺 ...
- SQL优化工具 - SQL Server Profiler与数据库引擎优化顾问
最近项目做到几千个学生分别去人脸识别记录(目前约630000行)中查询最后一次记录,可想而知性能这块是个麻烦.于是乎,GET到了SQL Server Profiler和数据库引擎优化顾问这俩工SHEN ...
随机推荐
- [Luogu P4777] 【模板】扩展中国剩余定理(EXCRT) (扩展中国剩余定理)
题面 传送门:洛咕 Solution 真*扩展中国剩余定理模板题.我怎么老是在做模板题啊 但是这题与之前不同的是不得不写龟速乘了. 还有两个重点 我们在求LCM的时候,记得先/gcd再去乘另外那个数, ...
- Go读取论文并转换为simhahs
package main import ( "fmt" _"flag" _ "os" _ "io/ioutil" _&q ...
- python详细图像仿射变换讲解
仿射变换简介 什么是放射变换 图像上的仿射变换, 其实就是图片中的一个像素点,通过某种变换,移动到另外一个地方. 从数学上来讲, 就是一个向量空间进行一次线形变换并加上平移向量, 从而变换到另外一个向 ...
- AES的数学基础
有限域 有限域上的运算 加法 两个多项式进行加法运算,就是两个多项式对应系数模2相加 乘法 两个多项式进行乘法运算:两个多项式相乘 若运算结果超过7次方,则必须对此结果进行一个多项式m(x)模运算,其 ...
- 如何让Visual Studio 2019更好用(VS2019配置指南)
今天电脑没带,借用外面的电脑配环境来用.刚下载完的VS是这样的: UI挺好看的,但代码窗口看起来就和上个世纪的VC6没什么区别,快捷键用起来也不顺手.(2333) 接下来,我们将一步步优化编写环境,让 ...
- SpringBoot进阶教程(六十四)注解大全
在Spring1.x时代,还没出现注解,需要大量xml配置文件并在内部编写大量bean标签.Java5推出新特性annotation,为spring的更新奠定了基础.从Spring 2.X开始spri ...
- SpringBoot整合JWT实战详解
jwt 介绍就不多说了,下面通过代码演示开发过程中jwt 的使用. (1)在pom.xml中引入对应的jar <dependency> <groupId>io.jsonwebt ...
- JavaScript变量声明与变量声明提前
JavaScript变量声明 JavaScript中存储数据的容器称为变量.用关键字和标识符创建新变量的语句,称为变量声明.可以通过关键字var进行变量声明,在ES6中增加了let.const关键字声 ...
- 美团面试官问我: ZGC 的 Z 是什么意思
本文的阅读有一定的门槛,请先了解 GC 的基本只知识. 现代垃圾收集器的演进大部分都是往减少停顿方向发展. 像 CMS 就是分离出一些阶段使得应用线程可以和垃圾回收线程并发,当然还有利用回收线程的并行 ...
- 没找到Wkhtmltopdf,报表会被显示为html
windows10 odoo 打印报表时提示 没找到Wkhtmltopdf,报表会被显示为html 现象 原因 没有安装Wkhtmltopdf,没有配置环境变量,odoo在电脑系统中找不到Wkhtml ...