Spark如何进行动态资源分配
一、操作场景
对于Spark应用来说,资源是影响Spark应用执行效率的一个重要因素。当一个长期运行的服务,若分配给它多个Executor,可是却没有任何任务分配给它,而此时有其他的应用却资源紧张,这就造成了很大的资源浪费和资源不合理的调度。
动态资源调度就是为了解决这种场景,根据当前应用任务的负载情况,实时的增减Executor个数,从而实现动态分配资源,使整个Spark系统更加健康。
二、动态资源策略
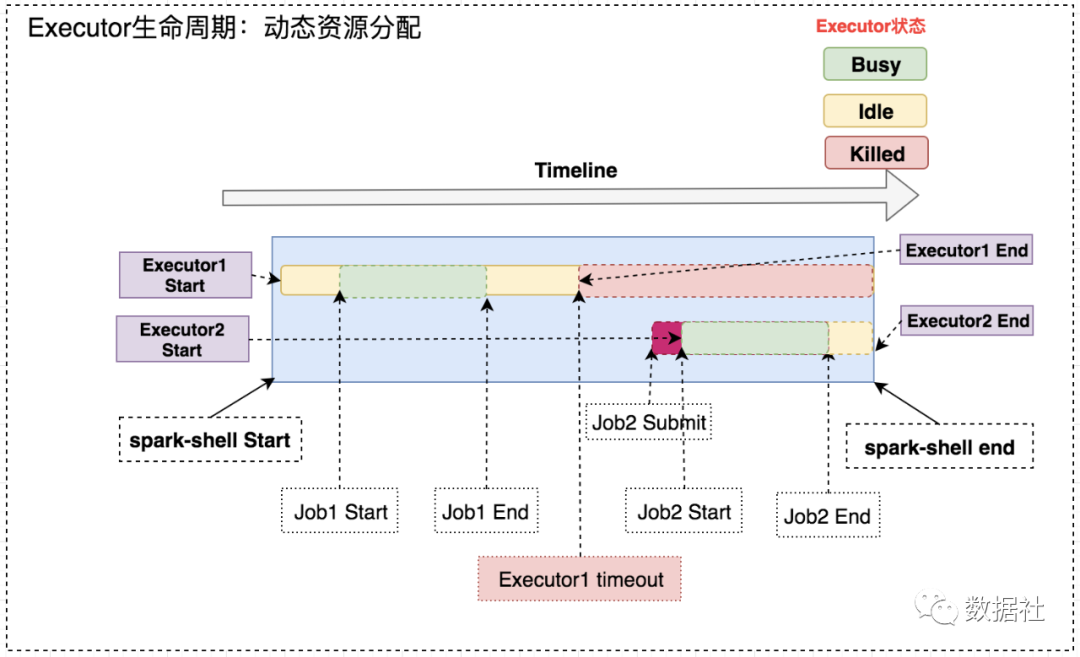
1、资源分配策略
开启动态分配策略后,application会在task因没有足够资源被挂起的时候去动态申请资源,这种情况意味着该application现有的executor无法满足所有task并行运行。spark一轮一轮的申请资源,当有task挂起或等待spark.dynamicAllocation.schedulerBacklogTimeout(默认1s)`时间的时候,会开始动态资源分配;之后会每隔spark.dynamicAllocation.sustainedSchedulerBacklogTimeout(默认1s)时间申请一次,直到申请到足够的资源。每次申请的资源量是指数增长的,即1,2,4,8等。
之所以采用指数增长,出于两方面考虑:其一,开始申请的少是考虑到可能application会马上得到满足;其次要成倍增加,是为了防止application需要很多资源,而该方式可以在很少次数的申请之后得到满足。
2、资源回收策略
当application的executor空闲时间超过spark.dynamicAllocation.executorIdleTimeout(默认60s)后,就会被回收。
三、操作步骤
1、yarn的配置
首先需要对YARN进行配置,使其支持Spark的Shuffle Service。
修改每台集群上的yarn-site.xml:
- 修改
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle,spark_shuffle</value>
</property>
- 增加
<property>
<name>yarn.nodemanager.aux-services.spark_shuffle.class</name>
<value>org.apache.spark.network.yarn.YarnShuffleService</value>
</property>
<property>
<name>spark.shuffle.service.port</name>
<value>7337</value>
</property>
将$SPARKHOME/lib/spark-X.X.X-yarn-shuffle.jar拷贝到每台NodeManager的${HADOOPHOME}/share/hadoop/yarn/lib/下, 重启所有修改配置的节点。
2、Spark的配置
配置$SPARK_HOME/conf/spark-defaults.conf,增加以下参数:
spark.shuffle.service.enabled true //启用External shuffle Service服务
spark.shuffle.service.port 7337 //Shuffle Service默认服务端口,必须和yarn-site中的一致
spark.dynamicAllocation.enabled true //开启动态资源分配
spark.dynamicAllocation.minExecutors 1 //每个Application最小分配的executor数
spark.dynamicAllocation.maxExecutors 30 //每个Application最大并发分配的executor数
spark.dynamicAllocation.schedulerBacklogTimeout 1s
spark.dynamicAllocation.sustainedSchedulerBacklogTimeout 5s
四、启动
使用spark-sql On Yarn执行SQL,动态分配资源。以yarn-client模式启动ThriftServer:
cd $SPARK_HOME/sbin/
./start-thriftserver.sh \
--master yarn-client \
--conf spark.driver.memory=10G \
--conf spark.shuffle.service.enabled=true \
--conf spark.dynamicAllocation.enabled=true \
--conf spark.dynamicAllocation.minExecutors=1 \
--conf spark.dynamicAllocation.maxExecutors=300 \
--conf spark.dynamicAllocation.sustainedSchedulerBacklogTimeout=5s
启动后,ThriftServer会在Yarn上作为一个长服务来运行。
Spark如何进行动态资源分配的更多相关文章
- spark on yarn 动态资源分配报错的解决:org.apache.hadoop.yarn.exceptions.InvalidAuxServiceException: The auxService:spark_shuffle does not exist
组件:cdh5.14.0 spark是自己编译的spark2.1.0-cdh5.14.0 第一步:确认spark-defaults.conf中添加了如下配置: spark.shuffle.servic ...
- 记一次有关spark动态资源分配和消息总线的爬坑经历
问题: 线上的spark thriftserver运行一段时间以后,ui的executor页面上显示大量的active task,但是从job页面看,并没有任务在跑.此外,由于在yarn mode下, ...
- Spark动态资源分配-Dynamic Resource Allocation
微信搜索lxw1234bigdata | 邀请体验:数阅–数据管理.OLAP分析与可视化平台 | 赞助作者:赞助作者 Spark动态资源分配-Dynamic Resource Allocation S ...
- 利用动态资源分配优化Spark应用资源利用率
背景 在某地市开展项目的时候,发现数据采集,数据探索,预处理,数据统计,训练预测都需要很多资源,现场资源不够用. 目前该项目的资源3台旧的服务器,每台的资源 内存为128G,cores 为24 (co ...
- spark提交至yarn的的动态资源分配
1.为什么开启动态资源分配 ⽤户提交Spark应⽤到Yarn上时,可以通过spark-submit的num-executors参数显示地指定executor 个数,随后,ApplicationMast ...
- 「Spark从精通到重新入门(二)」Spark中不可不知的动态资源分配
前言 资源是影响 Spark 应用执行效率的一个重要因素.Spark 应用中真正执行 task 的组件是 Executor,可以通过spark.executor.instances 指定 Spark ...
- Spark Streaming资源动态申请和动态控制消费速率剖析
本期内容 : Spark Streaming资源动态分配 Spark Streaming动态控制消费速率 为什么需要动态处理 : Spark 属于粗粒度资源分配,也就是在默认情况下是先分配好资源然后再 ...
- Spark的动态资源分配
跑spark程序的时候,公司服务器需要排队等资源,参考一些设置,之前不知道,跑的很慢,懂得设置之后简直直接起飞. 简单粗暴上设置代码: def conf(self): conf = super(Tbt ...
- spark任务调度模式,动态资源分配
官网链接: http://spark.apache.org/docs/latest/job-scheduling.html 主要介绍: 1 application级调度方式 2 单个applicati ...
随机推荐
- C#开发PACS医学影像处理系统(六):加载Dicom影像
对于一款软件的扩展性和维护性来说,上层业务逻辑和UI表现一定要自己开发才有控制权,否则项目上线之后容易被掣肘, 而底层图像处理,我们不需要重复造轮子,这里推荐使用fo-dicom,同样基于Dicom3 ...
- 安装Linux的CentOS操作系统 - 初学者系列 - 学习者系列文章
Linux系统对于一些熟悉Windows操作系统的用户来说可能比较陌生,但是它也是一种多用户.多任务的操作系统,现在也发展成为了多种版本的操作系统了.如果想对该系统进行学习,请下载这个学习文档:htt ...
- redis哨兵机制--配置文件sentinel.conf详解
转载自 https://blog.csdn.net/u012441222/article/details/80751390 Redis的哨兵机制是官方推荐的一种高可用(HA)方案,我们在使用Redis ...
- python3 函数的参数
函数的参数 形参(函数定义时) + 实参(函数调用时) 形参:形式参数 在函数的定义处定义的参数,比如def func(参数1, 参数2, 参数3...) 普通参数(位置参数), 默认参数,普通收集参 ...
- 使用vue-cli(vue脚手架)快速搭建项目-2
接上一篇文章,这篇文章对如何使用IDEA打开并运行项目做教程 1.将在窗口模式启动的Vue关闭 只需要按住Ctrl+C,输入Y就可以了 2.打开idea 3.复制你项目所在地址,然后点击OK 4.下面 ...
- 2.Scala安装配置和使用
- javaweb开发中的常见错误
Javaweb中的最常见错误及其解决方法 1.200:表示成功处理业务. 2.400 请求出错: 由于语法格式有误,服务器无法理解此请求.不作修改,客户程序就 无法重复此请求. 解决办法:,遇到400 ...
- ASP.NET Core 3.x启动时运行异步任务(二)
这一篇是接着前一篇在写的.如果没有看过前一篇文章,建议先去看一下前一篇,这儿是传送门 一.前言 前一篇文章,我们从应用启动时异步运行任务开始,说到了必要性,也说到了几种解决方法,及各自的优缺点.最 ...
- jstl中ftm标签用法
<fmt:formatDate value="${dateTime}" pattern="yyyy/MM/dd HH:mm:ss"/>
- 结合 Shell 对 Koa 应用运行环境检查
在开发环境中,启动一个koa 应用服务,通常还需要同时启动数据库.比如.Mongodb.mysql 等 如果一直开着数据库服务,在不使用的话,电脑会占一定的性能.然而如果每次手动去启动服务,效率又不高 ...