jieba库及wordcloud库的使用
知识内容:
1.jieba库的使用
2.wordcloud库的使用
参考资料:
https://github.com/fxsjy/jieba
https://blog.csdn.net/fontthrone/article/details/72775865
一、jieba库的使用
1.jieba库介绍
jieba是优秀的中文分词第三方库,使用pip安装后可以使用其来对中文文本进行分词
特点:
支持三种分词模式:
- 精确模式,试图将句子最精确地切开,适合文本分析,单词无冗余;
- 全模式,把句子中所有的可以成词的词语都扫描出来, 速度非常快,但是不能解决歧义,存在冗余;
- 搜索引擎模式,在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词。
支持繁体分词
支持自定义词典
MIT 授权协议
2.jieba库方法
(1)jieba库3种分词方法(3种模式)
3种模式对应的方法如下:
- cut(s)和lcut(s) # 精确模式
- lcut(s, cut_all=True) # 全模式(存在冗余)
- cut_for_search(s)和lcut_for_search(s) # 搜索模式(存在冗余)
注:cut()和lcut()的不同:cut返回的是生成器,lcut返回的是列表。cut_for_search()和lcut_for_search()也是前者返回生成器,后者返回列表
另外:
cut方法lcut方法接受三个输入参数: 需要分词的字符串;cut_all 参数用来控制是否采用全模式;HMM 参数用来控制是否使用 HMM 模型cut_for_search方法和lcut_for_searchlcut_for_search接受两个参数:需要分词的字符串;是否使用 HMM 模型。该方法适合用于搜索引擎构建倒排索引的分词,粒度比较细- 待分词的字符串可以是 unicode 或 UTF-8 字符串、GBK 字符串。注:不建议直接输入 GBK 字符串,可能无法预料地错误解码成 UTF-8
示例:
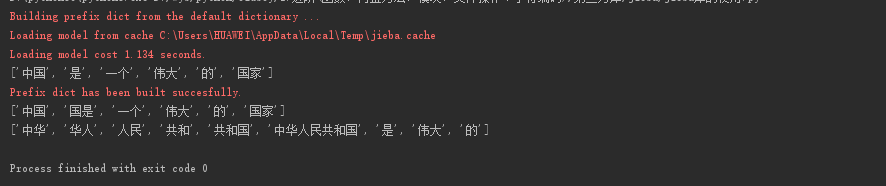
import jieba s = "中国是一个伟大的国家"
res1 = jieba.lcut(s) # 精确模式
res2 = jieba.lcut(s, cut_all=True) # 全模式(存在冗余)
res3 = jieba.lcut_for_search("中华人民共和国是伟大的") # 搜索模式(存在冗余) print(res1, res2, res3, sep="\n")
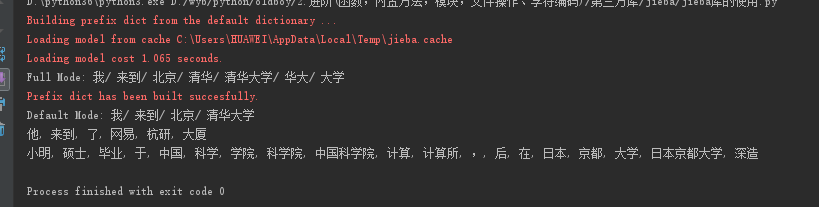
import jieba
seg_list = jieba.cut("我来到北京清华大学", cut_all=True)
print("Full Mode: " + "/ ".join(seg_list)) # 全模式
seg_list = jieba.cut("我来到北京清华大学", cut_all=False)
print("Default Mode: " + "/ ".join(seg_list)) # 精确模式
seg_list = jieba.cut("他来到了网易杭研大厦") # 默认是精确模式
print(", ".join(seg_list))
seg_list = jieba.cut_for_search("小明硕士毕业于中国科学院计算所,后在日本京都大学深造") # 搜索引擎模式
print(", ".join(seg_list))
结果:
(2)向字典中添加新词或添加自定义词典
使用 add_word(word, freq=None, tag=None) 和 del_word(word) 可在程序中动态修改词典,当然也可以使用load_userdict(file_name)来导入自定义字典
最简单的用法:add_word() 直接向分词词典中添加新词
示例:
s = "李小福是创新办主任也是云计算方面的专家"
print(jieba.lcut(s))
jieba.add_word("创新办")
print(jieba.lcut(s))

还可以使用load_userdict(file_name)导入自定义字典
示例:
自定义字典文件dict.txt内容如下:
云计算 5
李小福 2 nr
创新办 3 i
easy_install 3 eng
好用 300
s = "李小福是创新办主任也是云计算方面的专家"
print(jieba.lcut(s))
jieba.load_userdict("dict.txt")
print(jieba.lcut(s))

3.文本词频统计通用代码
import string
import jieba
# 统计哈姆雷特和三国演义的词频 # 统计hamlet的词频 -> 可以用做英文的通用分词和统计
class Hamlet(object):
def __init__(self, name):
"""
:param name: 文本名字或路径
"""
self.text_name = name def get_text(self):
"""
获取文本并进行相关处理
:return: 返回文本内容
"""
txt = open(self.text_name, "r").read().lower()
for ch in string.punctuation:
txt = txt.replace(ch, " ")
return txt def count(self):
"""
统计单词出现的次数并输出结果
"""
hamlet_txt = self.get_text()
words = hamlet_txt.split()
counts = {}
for word in words:
counts[word] = counts.get(word, 0) + 1
items = list(counts.items())
# key指定用列表中每一项中第二个值作为排序依据, reverse设置排序顺序 设为True的排序顺序为从大到小
items.sort(key=lambda x: x[1], reverse=True)
for i in range(10):
print(items[i][0], items[i][1]) # 统计三国演义中人物名字的词频 -> 可以用做中文的通用分词及统计
class ThreeKindDom(object):
def __init__(self, name):
"""
:param name: 文本名字或路径
"""
self.text_name = name def get_text(self):
"""
获取文本并进行相关处理
:return: 返回文本内容
"""
txt = open(self.text_name, "r", encoding="utf-8").read()
return txt def split_txt(self):
"""
对文本进行分词
:return: 返回分词后的列表
"""
threekingdom_txt = self.get_text()
words = jieba.lcut(threekingdom_txt)
return words def count(self):
"""
统计单词出现的次数并输出结果
"""
words = self.split_txt()
# excludes为要去掉的词
excludes = {"将军", "却说", "二人", "不可", "荆州", "不能", "如此", "商议", "如何", "左右",
"军马", "引兵", "军士", "次日", "主公", "大喜", "天下", "东吴", "于是", "今日", "魏兵"}
counts = {}
for word in words:
rword = word
if len(word) == 1:
continue
# 对一些特殊的词进行处理
elif word == "诸葛亮" or word == "孔明" or word == "孔明曰":
rword = "孔明"
elif word == "关公" or word == "云长":
rword = "关羽"
elif word == "玄德" or word == "玄德曰":
rword = "刘备"
elif word == "孟德" or word == "丞相":
rword = "曹操"
counts[rword] = counts.get(rword, 0) + 1
for word in excludes:
del counts[word]
items = list(counts.items())
# key指定用列表中每一项中第二个值作为排序依据, reverse设置排序顺序 设为True的排序顺序为从大到小
items.sort(key=lambda x: x[1], reverse=True)
for i in range(8):
print(items[i][0], items[i][1]) if __name__ == '__main__':
# s1 = Hamlet("hamlet.txt")
# s1.count() s2 = ThreeKindDom("threekingdoms.txt")
s2.count()
二、wordcloud库的使用
1.wordcloud库介绍
wordcloud库是基于Python的词云生成类库,很好用,而且功能强大
词云如下所示:

2.wordcloud库基本使用

实例:
import wordcloud c = wordcloud.WordCloud() # 生成词云对象
c.generate("wordcloud by Python") # 加载词云文本
c.to_file("wordcloud.png") # 输出词云文件
WordCloud方法的参数如下:
- width:指定词云对象生成的图片的宽度(默认为200px)
- height:指定词云对象生成的图片的高度(默认为400px)
- min_font_size:指定词云中字体最小字号,默认为4
- max_font_size:指定词云中字体最大字号
- font_step:指定词云中字体之间的间隔,默认为1
- font_path:指定字体文件路径
- max_words:指定词云中能显示的最多单词数,默认为200
- stop_words:指定在词云中不显示的单词列表
- background_color:指定词云图片的背景颜色,默认为黑色
指定词云形状:
import jieba
import wordcloud
from scipy.misc import imread mask = imread("yun.png") # 读取图片数据到mask中 f = open("文档.txt", "r", encoding="utf-8")
data = f.read()
f.close() ls = jieba.lcut(data) # 分词
txt = " ".join(ls) # 将列表中的单词连接成一个字符串 w = wordcloud.WordCloud(mask=mask) # 指定词云形状
w.generate(txt)
w.to_file("output.png")
3.生成词云通用代码
import jieba
import wordcloud
from scipy.misc import imread def make_cloud(input_file, output_file, **kwargs):
"""
制作词云的通用代码
:param input_file: 输入文本的路径或名字
:param output_file: 输出图片的路径或名字
:param kwargs: WordCloud的参数(width、height、background_color、font_path、max_words)
:return:
"""
width = kwargs.get("width")
height = kwargs.get("height")
background_color = kwargs.get("background_color")
font_path = kwargs.get("font_path")
max_words = kwargs.get("max_words") f = open(input_file, "r", encoding="utf-8")
data = f.read()
f.close() ls = jieba.lcut(data) # 分词
txt = " ".join(ls) # 将列表中的单词连接成一个字符串 w = wordcloud.WordCloud(width=width, height=height, background_color=background_color, font_path=font_path,
max_words=max_words)
w.generate(txt)
w.to_file(output_file) def make_cloud_png(input_file, output_file, png_file, **kwargs):
"""
用特殊图形制作词云的通用代码
:param input_file: 输入文本的路径或名字
:param output_file: 输出图片的路径或名字
:param png_file: 设置词云的图片形状的文件路径或名字
:param kwargs: WordCloud的参数(width、height、background_color、font_path、max_words)
:return:
"""
width = kwargs.get("width")
height = kwargs.get("height")
background_color = kwargs.get("background_color")
font_path = kwargs.get("font_path")
max_words = kwargs.get("max_words")
mask = imread(png_file) f = open(input_file, "r", encoding="utf-8")
data = f.read()
f.close() ls = jieba.lcut(data) # 分词
txt = " ".join(ls) # 将列表中的单词连接成一个字符串 w = wordcloud.WordCloud(width=width, height=height, background_color=background_color, font_path=font_path,
max_words=max_words, mask=mask)
w.generate(txt)
w.to_file(output_file)
jieba库及wordcloud库的使用的更多相关文章
- 使用jieba库与wordcloud库第三方库进行词频统计
一.jieba库与wordcloud库的使用 1.jieba库与wordcloud库的介绍 jieba 库的分词原理是利用一个中文词库,将待分词的内容与分词词库进行比对,通过图结构和动态规划方法找到最 ...
- python预课05 爬虫初步学习+jieba分词+词云库+哔哩哔哩弹幕爬取示例(数据分析pandas)
结巴分词 import jieba """ pip install jieba 1.精确模式 2.全模式 3.搜索引擎模式 """ txt ...
- python词云生成-wordcloud库
python词云生成-wordcloud库 全文转载于'https://www.cnblogs.com/nickchen121/p/11208274.html#autoid-0-0-0' 一.word ...
- wordcloud库基本介绍和使用方法
一.wordcloud库基本介绍 1.1 wordcloud库概述 wordcloud是优秀的词云展示第三方库 词云以词语为基本单位,更加直观和艺术的展示文本 1.2wordcloud库的安装 pip ...
- python爬虫——京东评论、jieba分词、wordcloud词云统计
接上一章,动态页面抓取——抓取京东评论区内容. url=‘https://club.jd.com/comment/productPageComments.action?callback=fetchJS ...
- Python常用的标准库以及第三方库
Python常用的标准库以及第三方库有哪些? 20个必不可少的Python库也是基本的第三方库 读者您好.今天我将介绍20个属于我常用工具的Python库,我相信你看完之后也会觉得离不开它们.他们 ...
- 【转】iOS动态库和静态库的简要介绍
静态库与动态库的区别 首先来看什么是库,库(Library)说白了就是一段编译好的二进制代码,加上头文件就可以供别人使用. 什么时候我们会用到库呢?一种情况是某些代码需要给别人使用,但是我们不希望别人 ...
- C++ 系列:静态库与动态库
转载自http://www.cnblogs.com/skynet/p/3372855.html 这次分享的宗旨是——让大家学会创建与使用静态库.动态库,知道静态库与动态库的区别,知道使用的时候如何选择 ...
- C++静态库与动态库
C++静态库与动态库 这次分享的宗旨是--让大家学会创建与使用静态库.动态库,知道静态库与动态库的区别,知道使用的时候如何选择.这里不深入介绍静态库.动态库的底层格式,内存布局等,有兴趣的同学,推荐一 ...
随机推荐
- C++ 和 Java 对类继承的差异
#include <iostream> using namespace std; class Base { public: int i; Base() { i = ; fun(); } v ...
- .NET练习计算平方根
1.新建Windows窗体 2.窗体中添加控件:TextBox(文本框).Button(按钮).和Label(标签) 3.为Button对象添加点击事件代码 点击事件代码设计思路 ①从文本框中获取输入 ...
- FREESWITCH 填坑指南
转接 1.查看网关注册状态 sofia status 2.桥接(未实践) http://wiki.freeswitch.org.cn/wiki/Mod_lua.html#jump10237 frees ...
- ZOJ - 3216:Compositions (DP&矩阵乘法&快速幂)
We consider problems concerning the number of ways in which a number can be written as a sum. If the ...
- CF1143F/1142C U2
CF1143F/1142C U2 巧妙的思维题.注意到这里只用两个点就可以确定一根抛物线,联想到两点确定一条直线,尝试转化. \(y=x^2+bx+c\) 就可以写成 \(y-x^2=bx+c\) , ...
- prisma 服务器端订阅试用
graphql 协议是支持数据的实时订阅功能的(一般基于websocket 进行实现) prisma 支持客户端订阅以及服务器端订阅(类似webhook),可以方便将 数据推送后端服务 目的 pr ...
- StreamSets 多线程 Pipelines
以下为官方文档: Multithreaded Pipeline Overview A multithreaded pipeline is a pipeline with an origin that ...
- POSIX 线程具体解释(3-相互排斥量:"固定加锁层次"/“试加锁-回退”)
有时一个相互排斥量是不够的: 比方: 当多个线程同一时候訪问一个队列结构时,你须要2个相互排斥量,一个用来保护队列头,一个用来保护队列元素内的数据. 当为多线程建立一个树结构时.你可能须要为每一个节点 ...
- HTTP协议中的长连接、短连接、长轮询、短轮询
长连接.短连接,指的是TCP连接.长连接是为了复用TCP连接. 长轮询中,服务器如果检测到库存量没有变化的话,将会把当前请求挂起一段时间(这个时间也叫作超时时间,一般是几十秒).在这个时间里,服务器会 ...
- Angular 4 绑定
一.事件绑定 1. 创建doOnClick函数 2. 网页中绑定doOnClick方法 3. 效果图 二. 属性绑定 1. 定义imgUrl的网址 2. 定义img src属性 另外一种写法 3. ...