[转]tppabs是什么?如何去除tppabs?
原文地址:http://www.cnblogs.com/gdsblog/archive/2017/03/25/6616561.html
不得不说,一款伟大的软件,就是用来解放人类双手的,Teleport Pro这款软件,是一款扒站软件,就是可以把别人的网站扒到你的本地,然后,细心的朋友会发现,呵!怎么多了一个莫名其妙的东西!也就是tppabs标签,怎么回事呢?请看下文介绍:

使用Teleport Pro软件的朋友应该知道他是一个离线浏览器,而他更大的作用则是可以用来下载别人的整站,软件的功能虽然好,但是却有一个很头疼的缺点,那就是下载下来 的网页它会在图片标签内插入tppabs标签以记录该图片的原始地址。因为这个标签不是合法标签,所以普通浏览器会忽略它。如图所示:

关键词:取出tppabs标记,去除tppabs标记,批量去除tppabs标记

如果手动清除的话,那将是一个不可想象的任务。其实可以在 DreamWeaver中使用正则表达式批量清除tppabs标签.
具体写法如下:
匹配tppabs标签:
\btppabs="h[^"]*"
替换为
(空)
匹配javascript代码:
href="javascript:if\(confirm\('htt[^"]*"
替换为
href="../"
注意替换的时候.应该勾选 "使用正则表达式"
如图所示:
EditPlus替换方法:

1.使用ep批量删除teleport下载页面中的多于标签
在使用teleport下载页面后,链接后面基本上都会添加tppabs="..."的标记,有些站外链接,还会加上javascript:if(confirm(...))window.location=...的语句,使用下面的方法,可以迅速清除这类标签:
用ep打开所有需要修改的文件,按下ctrl+h,勾选'正则表达式',查找内容输入
tppabs="[^"]+"
(注意最前面有空格),替换内容为空,范围选择所有打开的文件,全部替换
查找内容输入
javascript\:if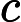

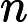
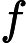
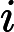
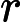
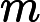


 confirm\([)]+\)window\.location='([^']+)'
confirm\([)]+\)window\.location='([^']+)'
替换内容输入\1,全部替换,ok,上面的信息都被清除
总结一下,在notepad++或者editplus中的替换规则:
[空格]tppabs="[^"]+" ==》 [空格]
/\*tpa=[^*]+\*/ ==》 [空格]
javascript\:ifconfirm\([)]+\)window\.location='([^']+)' ==》\1
[转]tppabs是什么?如何去除tppabs?的更多相关文章
- 批量去除Teleport Pro整站下载文件冗余代码
teleport pro tppabs标签批量删除 teleport pro tppabs标签批量删除 使 用Teleport Pro下载的网页代码中包含了很多垃圾代码,比如下载的html网页代码中会 ...
- 去除整站下载文件中的tppabs等冗余代码
用TeleprotUltra复制了一个网站,结果网页中出现了很多形如tppabs=””的冗余代码,点击vs中的“在文件中查找”图标,打开“查找和替换”对话框,转到“快速替换”,然后进行以下设置: “查 ...
- 去掉tppabs冗余代码,怎样批量去掉tppabs代码
去掉tppabs冗余代码,怎样批量去掉tppabs代码 刚用teleport pro拉了一个整站到本地 所有的超链都被强行加了一句tppabs=" 就玩了一把dw的替换功能 查找范围:整 ...
- Teleport Ultra 垃圾代码 tppabs的清理<转>
在使用整站下载软件Teleport Pro或Teleport Ultra下载的离线文件里会包含大量垃圾代码,下载后就需要清除整站下载文件中的冗余代码:tppabs等.这些代码本是Teleport自动添 ...
- 删除tppabs,href="javascript:if(confirm)...",、/*tpa=http://...
扒网站,据说是web从业人员的必备技能; 废话不多,下面应该是你想要的; 1: tppabs="h[^"]*" 2: href="javascript\:i ...
- dreamweaver中用正则表达式查找替换批量删除 tppabs标签的方法
查找替换 正则表达式 \btppabs="h[^"]*" 后面不能有空格 你懂得的 选中右下角的 √[使用正则表达式] 替换全部
- [转]最全的用正则批量去除Teleport Pro整站下载文件冗余代码
原文地址:http://www.jb51.net/article/43650.htm html原文件中tppabs标记是Teleport Pro软件留下的标记.该软件是离线浏览器,下载完整个网页后,它 ...
- sqlServer去除字符串空格
说起去除字符串首尾空格大家肯定第一个想到trim()函数,不过在sqlserver中是没有这个函数的,却而代之的是ltrim()和rtrim()两个函数.看到名字所有人都 知道做什么用的了,ltrim ...
- .Net 序列化(去除默认命名空间,添加编码)
1.序列化注意事项 (1).Net 序列化是基于对象的.所以只有实例字段呗序列化.静态字段不在序列化之中. (2)枚举永远是可序列化的. 2.XML序列化时去除默认命名空间xmlns:xsd和xmln ...
随机推荐
- ASP.NET Core Linux环境安装并运行项目
原文地址:https://blog.csdn.net/u014368040/article/details/79192622 一 安装环境 1. 从微软官网下载 Linux版本的.NetCoreSd ...
- formValidator输入验证、异步验证实例 + licenseImage验证码插件实例应用
实例技术:springmvc 实现功能:完整用户登录流程.输入信息规则校验.验证码异步校验. 功能清单: 1.springmvc控制器处理get请求(/member/login.html),进行静态页 ...
- elasticsearch实现按天翻滚索引
最近在做集中式日志,将应用的日志保存到Elasticsearch中,结合kibana实现集中化日志监控和报警.在设计ES存储的时候.考虑到日志的特殊性,打算采用Daily Indices方式.名称为: ...
- 一步一步掌握线程机制(六)---Atomic变量和Thread局部变量
前面我们已经讲过如何让对象具有Thread安全性,让它们能够在同一时间在两个或以上的Thread中使用.Thread的安全性在多线程设计中非常重要,因为race condition是非常难以重现和修正 ...
- 【转】我为什么离开 Cornell
我为什么离开 Cornell 很多人都知道,我曾经在 Cornell 博士就读,两年之后转学到了 Indiana 大学.几乎所有人,包括 Indiana 大学的人都感觉奇怪,为什么会有人从 Corne ...
- 如何在osx的终端下使用字典
因为各种原因我经常要在osx上查英文单词,在osx系统下,查字典其实是一件非常优雅的事情,三指轻触,简单快速.在terminal中其实也是这样,3指轻触需要查询的单词,释义一触即发,用户体验非常好.不 ...
- CListCtrl行高问题最终解决方法
原文链接: http://blog.csdn.net/benny5609/article/details/1967078 解决方案: 1. 设置List Control的属性 Owen Draw Fi ...
- wget for windows
那么,来尝试下wget for windows 吧. 什么是wget? wget是一个强力方便的命令行下的下载工具,可以通过HTTP和FTP协议(两种最广泛的互联网协议)从因特网中检索并获取文件. 此 ...
- SpringBoot+mybatis实现多数据源支持
什么是多数据源支持? 简单的说,就是一个项目里,同时可以访问多个不同的数据库. 实现原理 单个数据源在配置时会绑定一套mybatis配置,多个数据源时,不同的数据源绑定不同的mybatis配置就可以了 ...
- 91平台iOS接入demo
源码:http://pan.baidu.com/s/1DuBl6 今天整理硬盘,找到了一个有趣的demo.一年前,91助手游戏联运呈爆棚趋势,但是许多使用FlashAir开发的优秀的游戏和应用都卡在了 ...