Spark Streaming 在数据平台日志解析功能的应用
https://mp.weixin.qq.com/s/bGXhC9hvDj4lzK7wYYHGDg
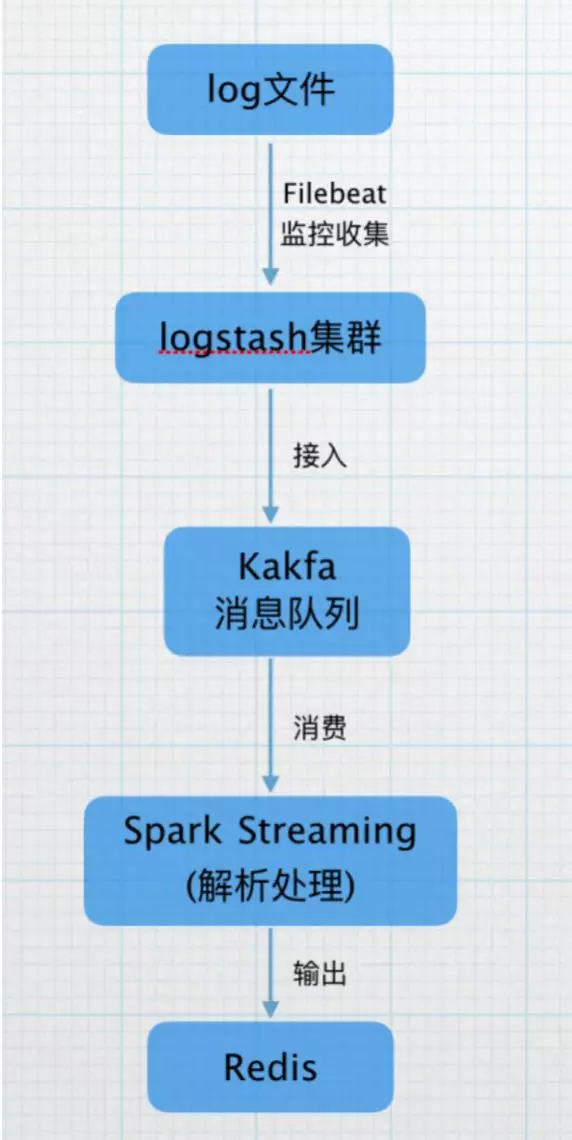
目前,我们使用Filebeat监控日志产生的目录,收集产生的日志,打到logstash集群,接入kafka的topic,再由Spark Streaming 进行实时解析,将解析的结果打入Redis缓存,供后续统计查询使用。
Spark Streaming 在数据平台日志解析功能的应用的更多相关文章
- 苏宁基于Spark Streaming的实时日志分析系统实践 Spark Streaming 在数据平台日志解析功能的应用
https://mp.weixin.qq.com/s/KPTM02-ICt72_7ZdRZIHBA 苏宁基于Spark Streaming的实时日志分析系统实践 原创: AI+落地实践 AI前线 20 ...
- 大数据技术之_19_Spark学习_04_Spark Streaming 应用解析 + Spark Streaming 概述、运行、解析 + DStream 的输入、转换、输出 + 优化
第1章 Spark Streaming 概述1.1 什么是 Spark Streaming1.2 为什么要学习 Spark Streaming1.3 Spark 与 Storm 的对比第2章 运行 S ...
- 3.spark streaming Job 架构和容错解析
一.Spark streaming Job 架构 SparkStreaming框架会自动启动Job并每隔BatchDuration时间会自动触发Job的调用. Spark Streaming的Job ...
- 65、Spark Streaming:数据接收原理剖析与源码分析
一.数据接收原理 二.源码分析 入口包org.apache.spark.streaming.receiver下ReceiverSupervisorImpl类的onStart()方法 ### overr ...
- Spark Streaming之二:StreamingContext解析
1.1 创建StreamingContext对象 1.1.1通过SparkContext创建 源码如下: def this(sparkContext: SparkContext, batchDurat ...
- Spark Streaming性能优化: 如何在生产环境下应对流数据峰值巨变
1.为什么引入Backpressure 默认情况下,Spark Streaming通过Receiver以生产者生产数据的速率接收数据,计算过程中会出现batch processing time > ...
- 4. Spark Streaming解析
4.1 初始化StreamingContext import org.apache.spark._ import org.apache.spark.streaming._ val conf = new ...
- Spark Streaming消费Kafka Direct方式数据零丢失实现
使用场景 Spark Streaming实时消费kafka数据的时候,程序停止或者Kafka节点挂掉会导致数据丢失,Spark Streaming也没有设置CheckPoint(据说比较鸡肋,虽然可以 ...
- Spark Streaming源码解读之流数据不断接收全生命周期彻底研究和思考
本期内容 : 数据接收架构设计模式 数据接收源码彻底研究 一.Spark Streaming数据接收设计模式 Spark Streaming接收数据也相似MVC架构: 1. Mode相当于Rece ...
随机推荐
- 8 -- 深入使用Spring -- 1...3 容器后处理器
8.1.3 容器后处理器(BeanFactoryPostProcessor) 容器后处理器负责处理容器本身. 容器后处理器必须实现BeanFacotryPostProcessor接口.实现该接口必须实 ...
- D盾 v2.0.6.42 测试记录
0x01 前言 之前发了一篇博客<Bypass D盾_IIS防火墙SQL注入防御(多姿势)>,D哥第一时间联系我,对问题进行修复.这段时间与D哥聊了挺多关于D盾这款产品的话题,实在是很佩服 ...
- 系统头文件cmath,cstdlib报错
>C:\Program Files (x86)\Microsoft Visual Studio\\Community\VC\Tools\MSVC\\include\cstdlib(): erro ...
- React Native(六)——PureComponent VS Component
先看两段代码: export class ywg extends PureComponent { …… render() { return ( …… ); } } export class ywg e ...
- webform的学习(2)
突然回想一下,两周之后放假回家,三周之后重返学习,四周之后就要真正的面对社会,就这样有好多的舍不得在脑海中回旋,但是又是兴奋的想快点拥有自己的小生活,似乎太多的人在说程序的道路甚是艰难,我不知道我的选 ...
- 小北微信小程序之小白教程系列之 -- 样式(WXSS)
为了适应广大的前端开发者,WXSS 具有 CSS 大部分 特性.同时为了更适合开发微信小程序,WXSS 对 CSS 进行了扩充以及修改.与 CSS 相比,WXSS 扩展的特性有:尺寸单位和样式导入. ...
- Find–atime –ctime –mtime的用法与区别总结
转自 周五有同事问起find命令中-mtime n.-mtime –n以及-mtime +n的用法区别,当时虽然记得这里n是n个24个小时的意思,也是对所有这几个属性详细的用法却一知半解,索性周末仔细 ...
- Underscore.js(JavaScript对象操作方法)
Underscore封装了常用的JavaScript对象操作方法,用于提高开发效率.(Underscore还可以被使用在Node.js运行环境.) 在学习Underscore之前,你应该先保存它的AP ...
- 【python系列】python初识
前言 Python是一种高层次,解释,互动性和面向对象的脚本语言,Python被设计成具有很强的可读性语言.它采用应用关键字,而其他语言一般使用标点符号,并且具有比其他语言有较少的语法结构. Pyth ...
- smali-2.2.4.jar & baksmali-2.2.4.jar
https://bitbucket.org/JesusFreke/smali/downloads/