【Ensemble methods】组合方法&集成方法
机器学习的算法中,讨论的最多的是某种特定的算法,比如Decision Tree,KNN等,在实际工作以及kaggle竞赛中,Ensemble methods(组合方法)的效果往往是最好的,当然需要消耗的训练时间也会拉长。
所谓Ensemble methods,就是把几种机器学习的算法组合到一起,或者把一种算法的不同参数组合到一起。
打一个比方,单个的学习器,我们把它类比为一个独裁者。而组合起来的学习器(Ensemble methods),我们把它类比为一个决策委员会。前者由一个人来根据经验来决策一个事件(对于回归问题,我们类比为预测一个数字)。后者有一系列的委员来决定。我们假设二者享有的经验(训练数据)是相同的。前者的个人能力可能比后者中的任意一个委员都要强大,但它也有它的缺陷。然而,对于后者,委员的各自能力或许不是很突出,但是各有所长,各有所短,对于一个事件,大家按照各自的优势做出判断,最后投票(可能是加权的投票)做出决定(对于回归问题,我们类比为对各自的预测值做平均,同样,可能是加权的平均)。
从人类社会的发展来看,后者更像一个民主国家,前者是一个独裁的国家。无疑,后者更加有优势,尤其是当经验中有很多不靠谱的地方,或者是记忆不清的地方的时候。对这个决策委员会来说,我们更希望其中的委员要各有所长,优劣互补,这样做出的决定更靠谱,如果委员都非常相似的话,这个委员会的价值就会大大地降低。同样,我们或许还希望,根据各自的表现,对委员在投票或者预测中的说话分量产生影响,这样,其中的精英会产生更大的影响。
基本上分为如下两类:
1、Averaging methods(平均方法)
就是利用训练数据的全集或者一部分数据训练出几个算法或者一个算法的几个参数,最终的算法是所有这些算法的算术平均。比如Bagging Methods(装袋算法),Forest of Randomized Trees(随机森林)等。
实际上这个比较简单,主要的工作在于训练数据的选择,比如是不是随机抽样,是不是有放回,选取多少的数据集,选取多数训练数据。后续的训练就是对各个算法的分别训练,然后进行综合平均。
这种方法的基础算法一般会选择很强很复杂的算法,然后对其进行平均,因为单一的强算法很容易就导致过拟合(overfit现象),而经过aggregate之后就消除了这种问题。
2、boosting methods(提升算法),
就是利用一个基础算法进行预测,然后在后续的其他算法中利用前面算法的结果,重点处理错误数据,从而不断的减少错误率。其动机是使用几种简单的弱算法来达到很强大的组合算法。所谓提升就是把“弱学习算法”提升(boost)为“强学习算法,是一个逐步提升逐步学习的过程;某种程度上说,和neural network有些相似性。经典算法 比如AdaBoost(Adaptive Boost,自适应提升),Gradient Tree Boosting(GBDT)。
这种方法一般会选择非常简单的弱算法作为基础算法,因为会逐步的提升,所以最终的几个会非常强。
Adaboost算法。
先介绍强可学习与弱可学习,如果存在一个多项式的学习算法能够学习它并且正确率很高,那么就称为强可学习,相反弱可学习就是学习的正确率仅比随机猜测稍好。
提升方法有两个问题:1. 每一轮如何改变训练数据的权重或概率分布 2. 如何将弱分类器整合为强分类器。
很朴素的思想解决提升方法中的两个问题:第1个问题-- 提高被前一轮弱分类器错误分类的权值,而降低那些被正确分类样本权值 ,这样导致结果就是 那些没有得到正确分类的数据,由于权值加重受到后一轮弱分类器的更大关注。 第2个问题 adaboost 采取加权多数表决方法,加大分类误差率小的弱分类器的权值,使其在表决中起到较大的作用,相反较小误差率的弱分类的权值,使其在表决中较小的作用。
具体说来,整个Adaboost 迭代算法就3步:
- 初始化训练数据的权值分布。如果有N个样本,则每一个训练样本最开始时都被赋予相同的权重:1/N。
- 训练弱分类器。具体训练过程中,如果某个样本点已经被准确地分类,那么在构造下一个训练集中,它的权重就被降低;相反,如果某个样本点没有被准确地分类,那么它的权重就得到提高。然后,权重更新过的样本集被用于训练下一个分类器,整个训练过程如此迭代地进行下去。
- 将各个训练得到的弱分类器组合成强分类器。各个弱分类器的训练过程结束后,加大分类误差率小的弱分类器的权重,使其在最终的分类函数中起着较大的决定作用,而降低分类误差率大的弱分类器的权重,使其在最终的分类函数中起着较小的决定作用。换言之,误差率低的弱分类器在最终分类器中占的权重较大,否则较小。
Adaboost算法流程
给定一个训练数据集T={(x1,y1), (x2,y2)…(xN,yN)},其中实例 ,而实例空间
,而实例空间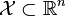 ,yi属于标记集合{-1,+1},Adaboost的目的就是从训练数据中学习一系列弱分类器或基本分类器,然后将这些弱分类器组合成一个强分类器。
,yi属于标记集合{-1,+1},Adaboost的目的就是从训练数据中学习一系列弱分类器或基本分类器,然后将这些弱分类器组合成一个强分类器。
Adaboost的算法流程如下:
- 步骤1. 首先,初始化训练数据的权值分布。每一个训练样本最开始时都被赋予相同的权重:1/N。

- 步骤2. 进行多轮迭代,用m = 1,2, ..., M表示迭代的第多少轮
a. 使用具有权值分布Dm的训练数据集学习,得到基本分类器:

b. 计算Gm(x)在训练数据集上的分类误差率
由上述式子可知,Gm(x)在训练数据集上的误差率em就是被Gm(x)误分类样本的权值之和。

由上述式子可知,em <= 1/2时,am >= 0,且am随着em的减小而增大,意味着分类误差率越小的基本分类器在最终分类器中的作用越大。

d. 更新训练数据集的权值分布(目的:得到样本的新的权值分布),用于下一轮迭代

使得被基本分类器Gm(x)误分类样本的权值增大,而被正确分类样本的权值减小。就这样,通过这样的方式,AdaBoost方法能“聚焦于”那些较难分的样本上。
其中,Zm是规范化因子,使得Dm+1成为一个概率分布:

- 步骤3. 组合各个弱分类器

从而得到最终分类器,如下:

在《统计学习方法》p140页有一个实际计算的例子可以自己计算熟悉算法过程。
Adaboost的误差界
通过上面的例子可知,Adaboost在学习的过程中不断减少训练误差e,直到各个弱分类器组合成最终分类器,那这个最终分类器的误差界到底是多少呢
事实上,Adaboost 最终分类器的训练误差的上界为:

下面,咱们来通过推导来证明下上述式子。
当G(xi)≠yi时,yi*f(xi)<0,因而exp(-yi*f(xi))≥1,因此前半部分得证。
关于后半部分,别忘了:

整个的推导过程如下:

这个结果说明,可以在每一轮选取适当的Gm使得Zm最小,从而使训练误差下降最快。接着,咱们来继续求上述结果的上界。
对于二分类而言,有如下结果:

其中,
继续证明下这个结论。
由之前Zm的定义式跟本节最开始得到的结论可知:

而这个不等式
值得一提的是,如果取γ1, γ2… 的最小值,记做γ(显然,γ≥γi>0,i=1,2,...m),则对于所有m,有:

这个结论表明,AdaBoost的训练误差是以指数速率下降的。另外,AdaBoost算法不需要事先知道下界γ,AdaBoost具有自适应性,它能适应弱分类器各自的训练误差率 。在统计学习方法第八章 中有关于这部分比较详细的讲述可以参考!!
3、Note
算法本身不重要,重要的是,什么是Ensemble Methods,以及如何做boost的过程。一旦决定了loss function,我们就可以用求偏导数+找梯度方向来处理boost的方向。
参考链接:
http://biancheng.dnbcw.net/1000wen/438893.html
http://blog.csdn.net/sandyzhs/article/details/47975423
http://blog.csdn.net/huruzun/article/details/41323065?utm_source=tuicool&utm_medium=referral
【Ensemble methods】组合方法&集成方法的更多相关文章
- 深度学习的集成方法——Ensemble Methods for Deep Learning Neural Networks
本文主要参考Ensemble Methods for Deep Learning Neural Networks一文. 1. 前言 神经网络具有很高的方差,不易复现出结果,而且模型的结果对初始化参数异 ...
- 【机器学习实战】第7章 集成方法 ensemble method
第7章 集成方法 ensemble method 集成方法: ensemble method(元算法: meta algorithm) 概述 概念:是对其他算法进行组合的一种形式. 通俗来说: 当做重 ...
- 决策树和基于决策树的集成方法(DT,RF,GBDT,XGBT)复习总结
摘要: 1.算法概述 2.算法推导 3.算法特性及优缺点 4.注意事项 5.实现和具体例子 内容: 1.算法概述 1.1 决策树(DT)是一种基本的分类和回归方法.在分类问题中它可以认为是if-the ...
- 决策树和基于决策树的集成方法(DT,RF,GBDT,XGB)复习总结
摘要: 1.算法概述 2.算法推导 3.算法特性及优缺点 4.注意事项 5.实现和具体例子 内容: 1.算法概述 1.1 决策树(DT)是一种基本的分类和回归方法.在分类问题中它可以认为是if-the ...
- 集成方法:渐进梯度回归树GBRT(迭代决策树)
http://blog.csdn.net/pipisorry/article/details/60776803 单决策树C4.5由于功能太简单.而且非常easy出现过拟合的现象.于是引申出了很多变种决 ...
- 【机器学习实战】第7章 集成方法(随机森林和 AdaBoost)
第7章 集成方法 ensemble method 集成方法: ensemble method(元算法: meta algorithm) 概述 概念:是对其他算法进行组合的一种形式. 通俗来说: 当做重 ...
- 机器学习——打开集成方法的大门,手把手带你实现AdaBoost模型
本文始发于个人公众号:TechFlow,原创不易,求个关注 今天是机器学习专题的第25篇文章,我们一起来聊聊AdaBoost. 我们目前为止已经学过了好几个模型,光决策树的生成算法就有三种.但是我们每 ...
- 7.2 Database Backup Methods 数据备份方法:
7.2 Database Backup Methods 数据备份方法: 本节总结了一些常用的备份方法: 使用MySQL Enterprise Backup 进行Hot Backup MySQL Ent ...
- Swift编程语言学习12 ——实例方法(Instance Methods)和类型方法(Type Methods)
方法是与某些特定类型相关联的函数.类.结构体.枚举都能够定义实例方法:实例方法为给定类型的实例封装了详细的任务与功能.类.结构体.枚举也能够定义类型方法:类型方法与类型本身相关联.类型方法与 Obje ...
随机推荐
- Ubuntu Linux 环境变量PATH设置
前俩天编译linux下rar解压软件的时候说找不到 /usr/local/linux 路径,在设定path变量的时候,忽然就想看看,path最原始的变量值是多少....(在环境变量文件中保存.... ...
- JAVA中线程池的简单使用
比如现在有10个线程,但每次只想运行3个线程,当这3个线程中的任何一个运行完后,第4个线程接着补上.这种情况可以使用线程池来解决,线程池用起来也相当的简单,不信,你看: package com.dem ...
- Http网络协议
目录结构: contents structure [-] 什么是HTTP协议 Http协议的发展历史 Http的报文结构 客户端请求 服务端响应消息 Content-Type application/ ...
- 用copy 还是 strong?
NSArray与NSMutableArray用copy修饰还是strong 这个是原文 http://blog.csdn.net/winzlee/article/details/51752354 一 ...
- Swift 基本运算符
前言 Swift 语言支持大部分标准 C 语言的运算符,并且改进了许多特性来使我们的代码更加规范,其中主要包含算数运算符.区间运算符.逻辑运算符.关系运算符.赋值运算符.自增自减运算符.溢出运算符等. ...
- Oracle 12C -- purge dba_recyclebin
SQL> create user abce identified by abce; User created. SQL> grant resource,connect to abce; G ...
- poj3041(最小顶点覆盖)
链接:点击打开链接 题意:N*N的矩阵中有一些点代表陨石.每次仅仅能消灭一行或一列连,问须要多少次才干所有消灭 代码: #include <map> #include <queue& ...
- [转]SSH 原理和基本使用:ssh 安全配置 以及ssh key 认证登录
一.什么是 SSH ? SSH全称(Secure SHell)是一种网络协议,顾名思义就是非常安全的shell,主要用于计算机间加密传输.早期,互联网通信都是基于明文通信,一旦被截获,内容就暴露无遗. ...
- alibaba fastjson TypeReference 通过字符串反射返回对象
TypeReferenceEditNew Page温绍 edited this page Nov 3, 2017 · 8 revisions1. 基础使用在fastjson中提供了一个用于处理泛型反序 ...
- Python——验证码识别 Pillow + tesseract-ocr
至于安装教程在这里不再重复说了,可以参考博客,网上有大把的教程 https://blog.csdn.net/testcs_dn/article/details/78697730 要是别的验证码是如下类 ...