Attention机制全解
前言
之前已经提到过好几次Attention的应用,但还未对Attention机制进行系统的介绍,之后的实践模型attention将会用到很多,因此这里对attention机制做一个总结。
Seq2Seq
注意力机制(Attention Mechanism)首先是用于解决 Sequence to Sequence 问题提出的,因此我们了解下研究者是怎样设计出Attention机制的。
Seq2Seq,即序列到序列,指的是用Encoder-Decoder框架来实现的端到端的模型,最初用来实现英语-法语翻译。Encoder-Decoder框架是一种十分通用的模型框架,其抽象结构如下图所示:

其中,Encoder和Decoder具体使用什么模型都是由研究者自己定的,CNN/RNN/Transformer均可。Encoder的作用就是将输入序列映射成一个固定长度的上下文向量C,而Decoder则将上下文向量C作为预测\(Y_1\)输出的初始向量,之后将其作为背景向量,并结合上一个时间步的输出来对下一个时间步进行预测。
由于Encoder-Decoder模型在编码和解码阶段始终由一个不变的语义向量C来联系着,这也造成了如下一些问题:
- 所有的输入单词 X 对生成的所有目标单词 Y 的影响力是相同的
- 编码器要将整个序列的信息压缩进一个固定长度的向量中去,使得语义向量无法完全表示整个序列的信息
- 最开始输入的序列容易被后输入的序列给覆盖掉,会丢失许多细节信息,这点在长序列上表现的尤为明显
Attention机制的引入
Attention机制的作用就是为模型增添了注意力功能,使其倾向于根据需要来选择句子中更重要的部分。
加入加入Attention机制的Seq2Seq模型框架如下图所示:
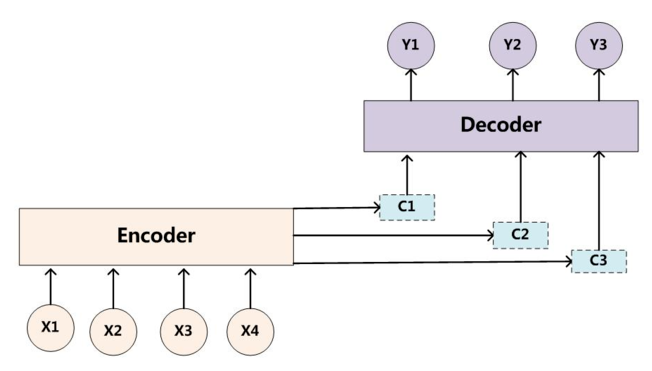
与传统的语义向量C不同的是,带有注意力机制的Seq2Seq模型与传统Seq2Seq模型的区别如下:
- 其为每一次预测都有不同的上下文信息\(C_i\)
\[P(y_i|y_1, y_2, ..., y_{i-1}, X) = P(y_i-1, s_i, c_i)\]
其中\(s_i\)表示Decoder上一时刻的输出状态,\(c_i\)为当前的时刻的中间语义向量
- 当前的时刻的中间语义向量\(c_i\)为对输入信息注意力加权求和之后得到的向量,即:
\[c_i = \sum_{j=1}^{Tx}\alpha_{ij}h_j\]
其中\(h_j\)为Encoder端的第j个词的隐向量,\(\alpha_{ij}\)表示Decoder端的第i个词对Encoder端的第j个词的注意力大小,即输入的第j个词对生成的第i个词的影响程度。这意味着在生成每个单词\(Y_i\)的时候,原先都是相同的中间语义表示\(C\)会替换成根据当前生成单词而不断变化的\(c_i\)。生成\(C_i\)最关键的部分就是注意力权重\(\alpha_{ij}\)的计算,具体的计算方法我们下面再讨论。
Hard or Soft
之前我们提到的为Soft Attention的一般形式,还有一种Hard Attention,其与Soft Attention的区别在于,其通过随机采样或最大采样的方式来选取特征信息(Soft Attention是通过甲醛求和的方式),这使得其无法使用反向传播算法进行训练。因此我们常用的通常是Soft Attention
Global or Local
Global Attention 与 Local Attention 的区别在于二者的关注范围不同。Global Attention 关注的是整个序列的输入信息,相对来说需要更大的计算量。而 Local Attention 仅仅关注限定窗口范围内的序列信息,但窗口的限定使得中心词容易忽视不在窗口范围内的信息,因此窗口的大小设定十分重要。在实践中,默认使用的是Global Attention。
注意力的计算
我们之前已经讨论过,中间语义向量\(c_i\)为对输入信息注意力加权求和之后得到的向量,即:
\[c_i = \sum_{j=1}^{Tx}\alpha_{ij}h_j\]
而注意力权重\(\alpha_{ij}\)表示Decoder端的第i个词对Encoder端的第j个词的注意力大小,即输入的第j个词对生成的第i个词的影响程度。其基本的计算方式如下:
\[\alpha_{ij} = \frac{exp(e_{ij})}{\sum_{k=1}^{T_x}exp(e_{ik})}\]
\[e_{ij} = Score(s_{i-1}, h_j)\]
其中,\(s_{i-1}\)需要根据具体任务进行选择,对于机器翻译等生成任务,可以选取 Decoder 上一个时刻的隐藏层输出,对于阅读理解等问答任务,可以选择问题或问题+选项的表征,对于文本分类任务,可以是自行初始化的上下文向量。而\(h_j\)为 Encoder 端第j个词的隐向量,分析上面公式,可以将Attention的计算过程总结为3个步骤:
- 将上一时刻Decoder的输出与当前时刻Encoder的隐藏词表征进行评分,来获得目标单词 Yi 和每个输入单词对应的对齐可能性(即一个对齐模型),Score(·)为一个评分函数,一般可以总结为两类:
- 点积/放缩点积:
\[e_{ij} = Score(s_{i-1}, h_j) = s_{i-1} \cdot h_j\]
\[e_{ij} = Score(s_{i-1}, h_j) = \frac{s_{i-1} \cdot h_j}{||s_{i-1}||\cdot||h_j||}\]
- MLP网络:
\[e_{ij} = Score(s_{i-1}, h_j) = MLP(s_{i-1}, h_j)\]
\[e_{ij} = Score(s_{i-1}, h_j) = s_{i-1}Wh_{j}\]
\[e_{ij} = Score(s_{i-1}, h_j) = W|h_j;s_{i-1}|\]
- 点积/放缩点积:
得到对齐分数之后,用Softmx函数将其进行归一化,得到注意力权重
最后将注意力权重与 Encoder 的输出进行加权求和,得到需要的中间语义向量\(c_i\)
将公式整合一下:
\[c_{i,j} = Attention(Query, Keys, Values) = Softmax(Score(Query, Keys)) * Values\]
其中,\(Query\)为我们之前提到的\(s_{i-1}\),\(Keys\) 和 \(Values\)为 \(h\)
Self-Attention
重温一下我们讲解Transformer时提到的Self-Attention,其 \(Query\),\(Keys\) 和 \(Values\) 均为词表征通过一个简单的线性映射矩阵得到的,即可将其表示为
\[Attention(Q,K,V) = Attention(W^QX,W^KX,W^VX)\]
从其注意力分数的计算方法上来看也是一种典型的缩放点积,其关键在于仅对句子本身进行注意力权值计算,使其更能够把握句子中词与词之前的关系,从而提取出句子中的句法特征或语义特征。

小结
这一块对Attention的原理基本已经全部总结了,主要是对自己只是的巩固,以及对之后的实践工作做铺垫,之后有时间再将Attention这块相关的代码写出来。
参考链接
https://zhuanlan.zhihu.com/p/31547842
https://zhuanlan.zhihu.com/p/59698165
https://zhuanlan.zhihu.com/p/53682800
https://zhuanlan.zhihu.com/p/43493999
Attention机制全解的更多相关文章
- Js中this机制全解
JavaScript中有很多令人困惑的地方,或者叫做机制. 但是,就是这些东西让JavaScript显得那么美好而与众不同. 比方说函数也是对 象.闭包.原型链继承等等,而这其中就包括颇让人费解的th ...
- “全栈2019”Java多线程第三十二章:显式锁Lock等待唤醒机制详解
难度 初级 学习时间 10分钟 适合人群 零基础 开发语言 Java 开发环境 JDK v11 IntelliJ IDEA v2018.3 文章原文链接 "全栈2019"Java多 ...
- “全栈2019”Java多线程第二十四章:等待唤醒机制详解
难度 初级 学习时间 10分钟 适合人群 零基础 开发语言 Java 开发环境 JDK v11 IntelliJ IDEA v2018.3 文章原文链接 "全栈2019"Java多 ...
- 深度学习之seq2seq模型以及Attention机制
RNN,LSTM,seq2seq等模型广泛用于自然语言处理以及回归预测,本期详解seq2seq模型以及attention机制的原理以及在回归预测方向的运用. 1. seq2seq模型介绍 seq2se ...
- Java 反射 设计模式 动态代理机制详解 [ 转载 ]
Java 反射 设计模式 动态代理机制详解 [ 转载 ] @author 亦山 原文链接:http://blog.csdn.net/luanlouis/article/details/24589193 ...
- Java IO编程全解(二)——传统的BIO编程
前面讲到:Java IO编程全解(一)——Java的I/O演进之路 网络编程的基本模型是Client/Server模型,也就是两个进程之间进行相互通信,其中服务端提供位置信息(绑定的IP地址和监听端口 ...
- js原型、原型链、作用链、闭包全解
https://www.2cto.com/kf/201711/698876.html [对象.变量] 一个对象就是一个类,可以理解为一个物体的标准化定义.它不是一个具体的实物,只是一个标准.而通过对象 ...
- Springboot整合log4j2日志全解
目录 常用日志框架 日志门面slf4j 为什么选用log4j2 整合步骤 引入Jar包 配置文件 配置文件模版 配置参数简介 Log4j2配置详解 简单使用 使用lombok工具简化创建Logger类 ...
- JVM类加载机制详解(二)类加载器与双亲委派模型
在上一篇JVM类加载机制详解(一)JVM类加载过程中说到,类加载机制的第一个阶段加载做的工作有: 1.通过一个类的全限定名(包名与类名)来获取定义此类的二进制字节流(Class文件).而获取的方式,可 ...
随机推荐
- Netty源码分析 (八)----- write过程 源码分析
上一篇文章主要讲了netty的read过程,本文主要分析一下write和writeAndFlush. 主要内容 本文分以下几个部分阐述一个java对象最后是如何转变成字节流,写到socket缓冲区中去 ...
- elk安装和使用
elk安装和使用 使用的版本都是5.2.0 elasticsearch-5.2.0安装 在官网 下载 elasticsearch tar包 解压安装 tar zxf elasticsearch-5.2 ...
- Spring Boot 利用 nginx 实现生产环境的伪热更新
当我们在服务器部署Java程序,特别是使用了 Spring Boot 生成单一 Jar 文件部署的时候,单一文件为我们开发单来的极大的便利性,保障程序的完整性.但同时对我们修改程序中的任何一处都带来重 ...
- 配置phpmyadmin连接远程 MySQL数据库
引言:1.phpmyadmin程序所在服务器:192.168.1.1,访问地址为:http://192.168.1.1/phpmyadmin2.MySQL数据库所在服务器:192.168.1.2, ...
- 进击的.NET 在云原生时代的蜕变
你一定看过这篇文章 <进击的 Java ,云原生时代的蜕变>, 本篇文章的灵感来自于这篇文章.明天就将正式发布.NET Core 3.0, 所以写下这篇文章让大家全面认识.NET Cor ...
- 如何使用WordPress搭建个人博客
目录 如何使用WordPress搭建个人博客 一.在安装Linux服务器管理工具WDCP面板 二.在WDCP面板创建一个站点 二.上传博客程序到服务器 @(如何使用WordPress搭建个人博客) 如 ...
- windows下安装vue教程
前言:前段时间学习了下vue,也算是能简单开发了,今天就记录下怎么通过vue-cli来安装vue. 因vue是基于node环境的,如果你还不会安装的话,可以看下我的这个教程:安装node.js和npm ...
- Spring——面向切面编程(AOP)详解
声明:本博客仅仅是一个初学者的学习记录.心得总结,其中肯定有许多错误,不具有参考价值,欢迎大佬指正,谢谢!想和我交流.一起学习.一起进步的朋友可以加我微信Liu__66666666 这是简单学习一遍之 ...
- [Leetcode][动态规划] 零钱兑换
一.题目描述 给定不同面额的硬币 coins 和一个总金额 amount.编写一个函数来计算可以凑成总金额所需的最少的硬币个数.如果没有任何一种硬币组合能组成总金额,返回 -1. 示例 1: 输入: ...
- lvm创建逻辑卷技巧
公司使用的服务器都是虚拟机,是虚拟机管理员通过模板创建的. 创建的所有逻辑卷都是使用的sda盘. 而我们在部署应用时需要和系统所在盘分离.(提高磁盘读写速度,避免系统盘被占满) 以前都是先创建新的逻辑 ...