基于C#的机器学习--旅行推销员问题
我们有一个必须在n个城市之间旅行的推销员。他不在乎什么顺序。他最先或最后访问的城市除外。他唯一关心的是他会去拜访每一个人,每个城市只有一次,最后一站是他得家。
每个城市都是一个节点,每个节点通过一条边与其他封闭节点相连(可以将其想象成公路、飞机、火车、汽车等)
每个连接都有一个或多个权值与之相关,我们称之为成本。
成本描述了沿着该连接旅行的困难程度,如机票成本、汽车所需的汽油量等。
他的首要任务是尽可能降低成本和旅行距离。
对于那些学过或熟悉图论的人,希望你们还记得无向加权图。
城市是顶点,路径是边,路径距离是边的权值。本质上,我们有一个最小化的问题,即在访问了其他每个顶点一次之后,从一个特定的顶点开始和结束。实际上,当我们完成的时候,可能会得到一个完整的图,其中每一对顶点都由一条边连接起来。
接下来,我们必须讨论不对称和对称的问题,因为这个问题最终可能是其中之一。到底是什么意思?我们有一个非对称旅行推销员问题或者一个对称旅行推销员问题。这完全取决于两座城市之间的距离。如果每个方向上的距离相等,我们有一个对称的旅行推销员问题,对称性帮助我们得到可能的解。如果两个方向上的路径不存在,或者距离不同,我们就有一个有向图。下图显示了前面的描述:
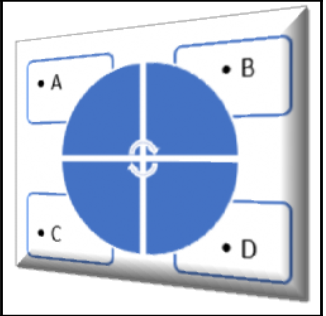
旅行推销员问题可以是对称的,也可以是非对称的。让我们从对将要发生的事情从最简描述开始。
在生物界,当我们想要创建一个新的基因型时,我们会从父a那里取一点,从父b那里取一点。这叫做交叉突变。在这之后,这些基因型就会受到轻微的干扰或改变。这被称为突变。这就是遗传物质产生的过程。
接下来,我们删除原始代,代之以新的代,并测试每个基因型。更新的基因型,作为其先前组成部分的更好部分,现在将向更高的适应度倾斜;平均而言,这一代人的得分应该高于上一代人。
这一过程将持续许多代,随着时间的推移,人口的平均适应度将不断进化和提高。在现实生活中,这并不总是有效的,但一般来说,它是有效的。
在后面会有一个遗传算法编程的讲解,以便让我们深入研究我们的应用程序。
下面是我们的示例应用程序。它是基于Accord.NET框架的。在定义了需要访问的房屋数量之后,只需单击生成按钮:
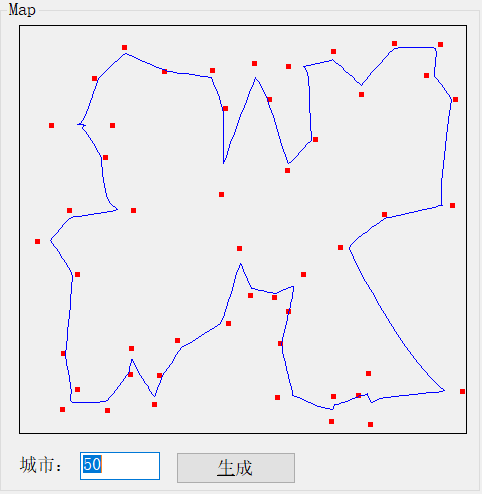
在我们的测试应用程序中,我们可以非常容易地更改我们想要访问的房屋的数量,如高亮显示的区域所示。
我们可以得到一个非常简单的空间问题或者更复杂的空间问题。这是一个非常简单的空间问题的例子:
这是一个更复杂的空间问题的例子:
最后,设置我们希望算法使用的迭代总数。点击计算路线按钮,假设一切顺利,我们的地图看起来应该像这样:
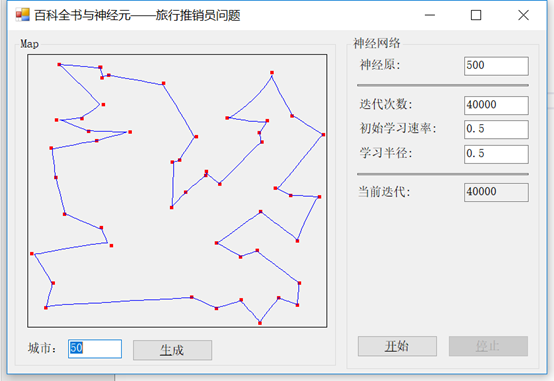
让我们看看当我们选择我们想要的城市数量,然后点击生成按钮,会发生什么:
/// <summary>
/// 重新生成地图
/// </summary>
private void GenerateMap()
{
Random rand = new Random((int)DateTime.Now.Ticks); // 创建坐标数组
map = new double[citiesCount, ]; for (int i = ; i < citiesCount; i++)
{
map[i, ] = rand.Next();
map[i, ] = rand.Next();
} //设置地图
chart.UpdateDataSeries("cities", map);
//删除路径
chart.UpdateDataSeries("path", null);
}
我们要做的第一件事就是初始化随机数生成器并对其进行种子化。接下来,我们得到用户指定的城市总数,然后从中创建一个新数组。最后,我们绘制每个点并更新地图。这张地图是来自Accord.NET的图表控件,它将为我们提供大量可视化绘图。完成这些之后,我们就可以计算路径并解决问题了。
接下来,让我们看看我们的主要搜索解决方案是什么样的:
// 创建网络
DistanceNetwork network = new DistanceNetwork(, neurons); // 设置随机发生器范围
foreach (var neuron in network.Layers.SelectMany(layer => layer?.Neurons).Where(neuron => neuron != null))
{
neuron.RandGenerator = new UniformContinuousDistribution(new Range(, ));
} // 创建学习算法
ElasticNetworkLearning trainer = new ElasticNetworkLearning(network); double fixedLearningRate = learningRate / ;
double driftingLearningRate = fixedLearningRate * ; double[,] path = new double[neurons + , ];
double[] input = new double[];
int i = ; while (!needToStop)
{
// 更新学习速度和半径
trainer.LearningRate = driftingLearningRate * (iterations - i) / iterations + fixedLearningRate;
trainer.LearningRadius = learningRadius * (iterations - i) / iterations; // 设置网络输入
int currentCity = rand.Next(citiesCount);
input[] = map[currentCity, ];
input[] = map[currentCity, ]; // 运行一个训练迭代
trainer.Run(input); // 显示当前路径
for (int j = ; j < neurons; j++)
{
path[j, ] = network.Layers[].Neurons[j].Weights[];
path[j, ] = network.Layers[].Neurons[j].Weights[];
}
path[neurons, ] = network.Layers[].Neurons[].Weights[];
path[neurons, ] = network.Layers[].Neurons[].Weights[]; chart.UpdateDataSeries("path", path); i++; SetText(currentIterationBox, i.ToString()); if (i >= iterations)
break;
}
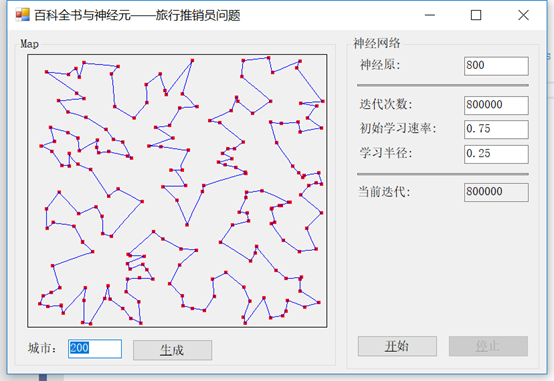
现在我们已经解决了问题,让我们看看是否可以应用我们在前面关于自组织映射(SOM)一章中学到的知识,从不同的角度来处理这个问题。
我们将使用一种叫做弹性网络训练的技术来解决我们遇到的问题,这是一种很好的无监督的方法。
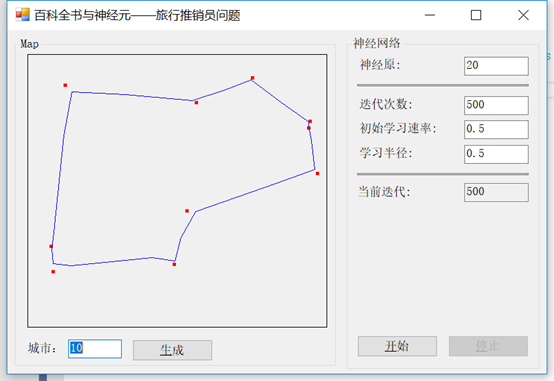
首先简单介绍一下什么是弹性映射。
弹性映射为创建非线性降维提供了一种工具。它们是数据空间中的弹性弹簧系统,近似于低维流形。利用这种能力,我们可以从完全无结构聚类(无弹性)到更接近线性主成分分析流形(高弯曲/低拉伸)的弹簧。
在使用我们的示例应用程序时,您将看到这些线并不一定像在以前的解决方案中那样僵硬。在许多情况下,它们甚至不可能进入我们所访问的城市的中心(这条线从中心生成),而是只接近城市边界的边缘,如前面的示例所示。
接下来,介绍下神经元。这次我们将有更多的控制,通过指定我们的学习速率和半径。与前面的示例一样,我们将能够指定销售人员今天必须访问的城市总数。
首先,我们将访问50个城市,使用0.3的学习率和0.75的半径。最后,我们将运行50,000次迭代(不用担心,这很快的)。我们的输出是这样的:
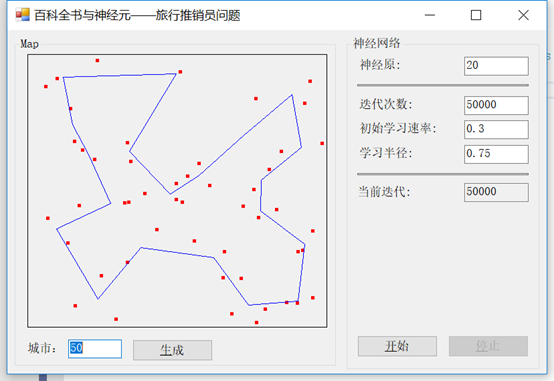
现在,如果我们改变半径为不同的值,比如0.25,会发生什么?注意我们在一些城市之间的角度变得更加明显:
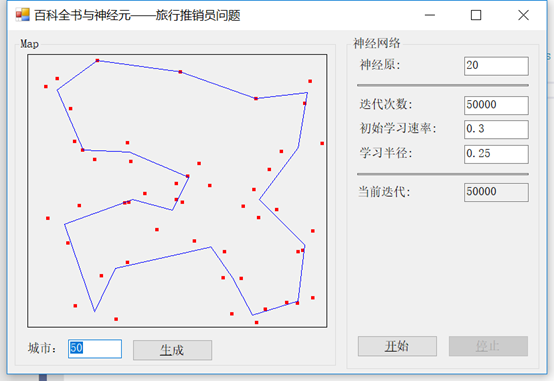
接下来,我们将学习率从0.3改为0.75:
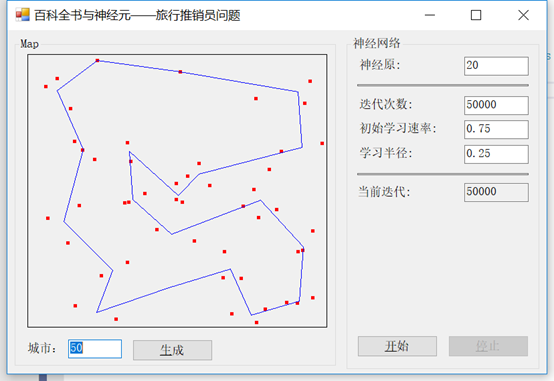
尽管得到路线最终看起来非常相似,但有一个重要的区别。在前面的示例中,直到所有迭代完成,才绘制销售人员的路由路径。
我们所做的第一件事就是创建一个DistanceNetwork对象。这个对象只包含一个DistanceLayer,它是一个距离神经元的单层。距离神经元将其输出计算为其权值与输入值之间的距离,即权值与输入值之间的绝对差值之和。所有这些组成了SOM,更重要的是,我们的弹性网络。
接下来,我们必须用一些随机权值来初始化我们的网络。我们将为每个神经元创建一个均匀连续的分布。均匀连续分布,或称矩形分布,是一种对称的概率分布,对于族中的每一个成员,在分布的支撑点上相同长度的所有区间具有相同的概率。你通常会看到这写成U(a, b)参数a和b分别是最小值和最大值。
// 设置随机发生器范围
foreach (var neuron in network.Layers.SelectMany(layer => layer?.Neurons).Where(neuron => neuron != null))
{
neuron.RandGenerator = new UniformContinuousDistribution(new Range(, ));
}
接下来,我们创建弹性学习对象,它允许我们训练我们的距离网络:
// 创建学习算法
ElasticNetworkLearning trainer = new ElasticNetworkLearning(network);
下面是ElasticNetworkLearning构造函数内部的样子:
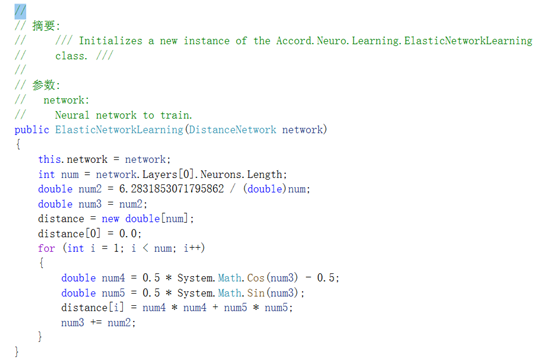
现在我们计算学习速率和半径:
double fixedLearningRate = learningRate / ;
double driftingLearningRate = fixedLearningRate * ;
最后,进入我们的主循环:
while (!needToStop)
{
// 更新学习速度和半径
trainer.LearningRate = driftingLearningRate * (iterations - i) / iterations + fixedLearningRate;
trainer.LearningRadius = learningRadius * (iterations - i) / iterations; // 设置网络输入
int currentCity = rand.Next(citiesCount);
input[] = map[currentCity, ];
input[] = map[currentCity, ]; // 运行一个训练迭代
trainer.Run(input); // 显示当前路径
for (int j = ; j < neurons; j++)
{
path[j, ] = network.Layers[].Neurons[j].Weights[];
path[j, ] = network.Layers[].Neurons[j].Weights[];
}
path[neurons, ] = network.Layers[].Neurons[].Weights[];
path[neurons, ] = network.Layers[].Neurons[].Weights[]; chart.UpdateDataSeries("path", path); i++; SetText(currentIterationBox, i.ToString()); if (i >= iterations)
break;
}
在前面的循环中,训练器每次循环增量运行一个epoch(迭代)。这是trainer.Run函数的样子,我们可以看到发生了什么。基本上,该方法找到获胜的神经元(权重值最接近指定输入向量的神经元)。然后更新它的权重以及相邻神经元的权重:

这个方法的两个主要功能是计算网络和获得获胜者(突出显示的项目)。
现在,简要介绍一下我们可以在屏幕上输入的参数。
学习速率
学习速率是决定学习速度的一个参数。更正式地说,它决定了我们根据损失梯度调整网络权重的程度。如果太低,我们沿着斜坡向下的速度就会变慢。即使我们希望有一个较低的学习率,这可能意味着我们将需要很长时间来达到趋同。学习速率也会影响我们的模型收敛到最小值的速度。
在处理神经元时,它决定了有权重用于训练的神经元的获取时间(对新体验做出反应所需的时间)。
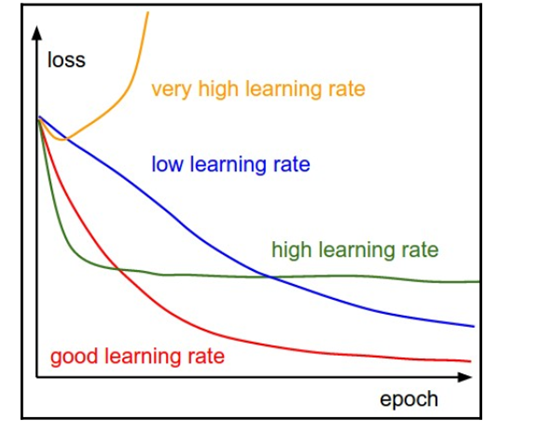
学习半径
学习半径决定了获胜神经元周围要更新的神经元数量。在学习过程中,半径圆内的任何神经元都会被更新。神经元越靠近,发生的更新就越多。距离越远,数量越少。
总结
在这一章中,我们学习了神经元,还学习了著名的旅行推销员问题,它是什么,以及我们如何用电脑解决它。这个小例子在现实世界中有着广泛的应用。
在下一章中,我们将回答我们所有开发人员都面临的问题:我应该接受这份工作吗?
基于C#的机器学习--旅行推销员问题的更多相关文章
- 基于Python的机器学习实战:KNN
1.KNN原理: 存在一个样本数据集合,也称作训练样本集,并且样本集中每个数据都存在标签,即我们知道样本集中每一个数据与所属分类的对应关系.输入没有标签的新数据后,将新数据的每个特征与样本集中数据对应 ...
- Spark学习之基于MLlib的机器学习
Spark学习之基于MLlib的机器学习 1. 机器学习算法尝试根据训练数据(training data)使得表示算法行为的数学目标最大化,并以此来进行预测或作出决定. 2. MLlib完成文本分类任 ...
- 基于python的机器学习开发环境安装(最简单的初步开发环境)
一.安装Python 1.下载安装python3.6 https://www.python.org/getit/ 2.配置环境变量(2个) 略...... 二.安装Python算法库 安装顺序:Num ...
- 基于Apache Spark机器学习的客户流失预测
流失预测是个重要的业务,通过预测哪些客户可能取消对服务的订阅来最大限度地减少客户流失.虽然最初在电信行业使用,但它已经成为银行,互联网服务提供商,保险公司和其他垂直行业的通用业务. 预测过程是大规模数 ...
- 基于C#的机器学习--贝叶斯定理-执行数据分析解决肇事逃逸之谜
贝叶斯定理-执行数据分析解决肇事逃逸之谜 在这一章中,我们将: 应用著名的贝叶斯定理来解决计算机科学中的一个非常著名的问题. 向您展示如何使用贝叶斯定理和朴素贝叶斯来绘制数据,从真值表中发现异常值 ...
- 基于C#的机器学习--目录
转载请注明出处:https://www.cnblogs.com/wangzhenyao1994/p/10223666.html 文章发表的另一个地址:https://blog.csdn.net/wyz ...
- 基于C#的机器学习--面部和动态检测-图像过滤器
在本章中,我们将展示两个独立的例子,一个用于人脸检测,另一个用于动态检测,以及如何快速地将这些功能添加到应用程序中. 在这一章中,我们将讨论: 面部检测 动态检测 将检测添加到应用程序中 面部检测 人 ...
- 基于C#的机器学习--我应该接受这份工作吗-使用决策树
决策树 要使决策树完整而有效,它必须包含所有的可能性.事件序列也必须提供,并且是互斥的,这意味着如果一个事件发生,另一个就不能发生. 决策树是监督机器学习的一种形式,因为我们必须解释输入和输出应该是什 ...
- 基于C#的机器学习--深层信念网络
我们都听说过深度学习,但是有多少人知道深度信念网络是什么?让我们从本章开始回答这个问题.深度信念网络是一种非常先进的机器学习形式,其意义正在迅速演变.作为一名机器学习开发人员,对这个概念有一定的了解是 ...
随机推荐
- maven_默认新建项目jdk1.6_默认配置
<?xml version="1.0" encoding="UTF-8"?> <settings xmlns="http://mav ...
- c#中的访问修饰符Protected,privet ,public, internal,和internal protected
Protected,privet ,public, internal,和internal protected的区别 Private修饰的,只能值类内部使用,外部不可以使用,子类不能直接访问,但可以通过 ...
- socket编程详解,转自http://www.sme-cn.com:82/archives/669
一 Socket简介 Socket翻译过来是套接字,具体含义可自行百度,简言之就是IP:Port的组合,是网络通信的一个窗口,IP就是地址和门牌号(比如长沙市韶山北路81号),Port就是房间号(比 ...
- Android零基础入门第1节:Android的前世今生
原文:Android零基础入门第1节:Android的前世今生 现在网上有很多各色Android资料了,但相对来说还是比较零散,Android覆盖的范围极广,最近刚好有机会全部拉通整理一遍,也保存起来 ...
- mysqldump数据库备份与恢复
mysqldump -u 用户名 -p 数据库名> 备份的文件名 本文中因服务器为多实例,所以在执行登陆等命令时指定了-S参数,即指定其中一个数据库 备份: mysqldump -u root ...
- Linux日志系统
常见的日志 常见的日志一般存储在/var/log中.常见的日志查看使用:ls/ll,cat/more/less查看即可:wtmp,lastlog使用last和lastlog提取其信息即可 配置日志 较 ...
- 利用消息机制实现VC与Delphi之间的通讯(发送自定义消息)
摘要: 本文介绍了使用Windows消息机制实现由不同语言编制的程序之间的相互通讯.联系,并以当前较为流行的两种语言Microsoft Visual C++ 6.0和Borland delphi 5. ...
- iOS11中iOS处理GIF图片的方式
GIF 五部走如下 : 1 从相册中取出GIF图的Data 2 通过腾讯的IM发送Gif图 3 展示GIF图 4 GIF图URL缓存机制 5 将展示的GIF图存到相册中 一 从相册中 ...
- 利用Rsync同步工具上传、删除目标文件
Rsync是文件备份工具,当然也可以当做传输工具,管理远程服务器的文件 上传 rsync -avzP --progress --port 9106 /path/.../指定文件 root@192.16 ...
- jquery中的ajax应用集锦
一,原生JS实现ajax: 1 2 3 4 5 6 7 8 9 10 11 function AjaxGet() { var xhrObj; ...