一步一步剖析Dictionary实现原理
目录
- 关键的字段和Entry结构
- 添加键值(Add)
- 取键值(Find)
- 移除键值(Remove)
- 再插入键值
本文是对c#中Dictionary内部实现原理进行简单的剖析。如有表述错误,欢迎指正。
主要对照源码来解析,目前对照源码的版本是.Net Framwork 4.8,源码地址。
1. 关键的字段和Entry结构
struct Entry
{
public int hashCode; // key的hashCode & 0x7FFFFFFF
public int next; // 指向链表下一个元素的地址(实际就是entries的索引),最后一个元素为-1
public TKey key;
public TValue value;
}
Entry[] entries; //存放键值
int[] buckets; //存储entries最新元素的索引,其存储位置由取模结果决定。例:假设键值存储在entries的第1元素的位置上,且hashCode和长度的取模结果为2,那么buckets[2] = 1
int count = ; //已存储键值的个数
int version; //记录版本,防止迭代过程中集合被更改
IEqualityComparer<TKey> _comparer;
int freeList; //entries中最新空元素的索引
int freeCount; //entries中空元素的个数
2. 添加键值(Add)
public void Add(TKey key, TValue value) {
Insert(key, value, true);
}
private void Insert(TKey key, TValue value, bool add) {
if( key == null ) {
ThrowHelper.ThrowArgumentNullException(ExceptionArgument.key);
}
if (buckets == null) Initialize();
int hashCode = comparer.GetHashCode(key) & 0x7FFFFFFF;
//取模
int targetBucket = hashCode % buckets.Length;
#if FEATURE_RANDOMIZED_STRING_HASHING
int collisionCount = ;
#endif
for (int i = buckets[targetBucket]; i >= ; i = entries[i].next) {
if (entries[i].hashCode == hashCode && comparer.Equals(entries[i].key, key)) {
if (add) {
ThrowHelper.ThrowArgumentException(ExceptionResource.Argument_AddingDuplicate);
}
//对于已存在的Key重新赋值
entries[i].value = value;
version++;
return;
}
#if FEATURE_RANDOMIZED_STRING_HASHING
collisionCount++;
#endif
}
int index;
if (freeCount > ) {
//存在entries中存在空元素
index = freeList;
freeList = entries[index].next;
freeCount--;
}
else {
if (count == entries.Length)
{
//扩容:取大于count * 2的最小素数作为entries和bucket的新容量(即数组长度.Length)
Resize();
targetBucket = hashCode % buckets.Length;
}
index = count;
count++;
}
entries[index].hashCode = hashCode;
entries[index].next = buckets[targetBucket];
entries[index].key = key;
entries[index].value = value;
//存取链表的头元素的索引(即entries最后存入的元素的在enties中的索引)
//便于取Key的时每次从链表的头元素开始遍历,详细见FindEntry(TKey key)函数
buckets[targetBucket] = index;
version++;
#if FEATURE_RANDOMIZED_STRING_HASHING
#if FEATURE_CORECLR
// In case we hit the collision threshold we'll need to switch to the comparer which is using randomized string hashing
// in this case will be EqualityComparer<string>.Default.
// Note, randomized string hashing is turned on by default on coreclr so EqualityComparer<string>.Default will
// be using randomized string hashing
if (collisionCount > HashHelpers.HashCollisionThreshold && comparer == NonRandomizedStringEqualityComparer.Default)
{
comparer = (IEqualityComparer<TKey>) EqualityComparer<string>.Default;
Resize(entries.Length, true);
}
#else
if(collisionCount > HashHelpers.HashCollisionThreshold && HashHelpers.IsWellKnownEqualityComparer(comparer))
{
//如果碰撞次数(单链表长度)大于设置的最大碰撞阈值,需要扩容
comparer = (IEqualityComparer<TKey>) HashHelpers.GetRandomizedEqualityComparer(comparer);
Resize(entries.Length, true);
}
#endif // FEATURE_CORECLR
#endif
}
******************************************************************************************************************************************
static void Foo()
{
var dicData = new Dictionary<int, int>();
//添加键值
new List<int> { , , }.ForEach(item => Add(item, dicData));
new List<int> { , , , }.ForEach(item => Add(item, dicData));
}
static void Add(int key, Dictionary<int, int> dicData)
{
dicData.Add(key, key);
}
2.1 数组entries和buckets初始化
private void Initialize(int capacity) {
//取大于capacity的最小质数(素数)
int size = HashHelpers.GetPrime(capacity);
buckets = new int[size];
for (int i = ; i < buckets.Length; i++) buckets[i] = -;
entries = new Entry[size];
freeList = -;
}
****************************************************
internal static class HashHelpers
{
......
public const int HashCollisionThreshold = ; //碰撞阈值
......
public static readonly int[] primes = {
, , , , , , , , , , , , , , , , , , , , , , ,
, , , , , , , , , , , , , , ,
, , , , , , , , , , , , ,
, , , , , , , , , , , ,
, , , , , , , , }; //质数(素数)组
......
public static int GetPrime(int min)
{
if (min < )
throw new ArgumentException(Environment.GetResourceString("Arg_HTCapacityOverflow"));
Contract.EndContractBlock();
//查找primes是否有满足的质数(素数)
for (int i = ; i < primes.Length; i++)
{
int prime = primes[i];
if (prime >= min) return prime;
}
//outside of our predefined table.
//compute the hard way.
//primes没有查找到满足的质数(素数),自行计算
for (int i = (min | ); i < Int32.MaxValue;i+=)
{
if (IsPrime(i) && ((i - ) % Hashtable.HashPrime != ))
return i;
}
return min;
}
}

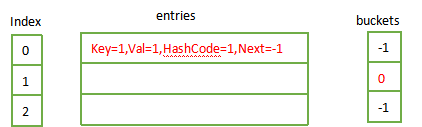
2.2 添加键值{1,1},则
hashCode = ;
targetBucket = hasCode % buckets.Length; //targetBucket = 1
next = buckets[targetBucket]; //next = -1
buckets[targetBucket] = index; //buckets[1] = 0
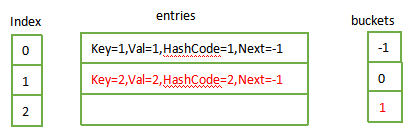
2.3 添加键值{2,2},则
hashCode = ;
targetBucket = hasCode % buckets.Length; //targetBucket = 2
next = buckets[targetBucket]; //next = -1
buckets[targetBucket] = index; //buckets[2] = 1
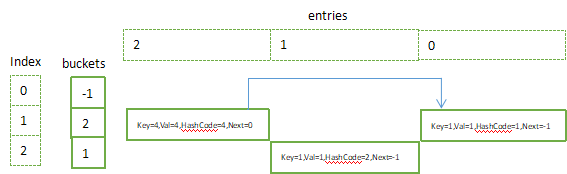
2.4 添加键值{4,4},则
hashCode = ;
targetBucket = hasCode % buckets.Length; //targetBucket = 1
next = buckets[targetBucket]; //next = 0
buckets[targetBucket] = index; //buckets[1] = 2

接下来将entries数组以单链表的形式呈现(即enteries数组横向);
2.5 在继续添加键值之前,需要扩容操作,因为entries数组长度为3且都已有元素。扩容后需要对buckets和entries每个元素的Next需要重新赋值;
private void Resize() {
//扩容的大小:取大于(当前容量*2)的最小素数
//例:
Resize(HashHelpers.ExpandPrime(count), false);
}
private void Resize(int newSize, bool forceNewHashCodes) {
Contract.Assert(newSize >= entries.Length);
//实例化buckets,并将每个元素置为-1
int[] newBuckets = new int[newSize];
for (int i = ; i < newBuckets.Length; i++) newBuckets[i] = -;
Entry[] newEntries = new Entry[newSize];
Array.Copy(entries, , newEntries, , count);
//如果是Hash碰撞扩容,使用新HashCode函数重新计算Hash值
if(forceNewHashCodes) {
for (int i = ; i < count; i++) {
if(newEntries[i].hashCode != -) {
newEntries[i].hashCode = (comparer.GetHashCode(newEntries[i].key) & 0x7FFFFFFF);
}
}
}
//重建单链表
for (int i = ; i < count; i++) {
if (newEntries[i].hashCode >= ) {
//取模重新设置next值和buckets
int bucket = newEntries[i].hashCode % newSize;
newEntries[i].next = newBuckets[bucket];
newBuckets[bucket] = i;
}
}
buckets = newBuckets;
entries = newEntries;
}
*******************************************************************
internal static class HashHelpers
{
......
public static readonly int[] primes = {
, , , , , , , , , , , , , , , , , , , , , , ,
, , , , , , , , , , , , , , ,
, , , , , , , , , , , , ,
, , , , , , , , , , , ,
, , , , , , , , }; //质数(素数)组
......
// This is the maximum prime smaller than Array.MaxArrayLength
public const int MaxPrimeArrayLength = 0x7FEFFFFD; //数组最大长度的最小质数
public static int ExpandPrime(int oldSize)
{
//翻倍
int newSize = * oldSize;
// Allow the hashtables to grow to maximum possible size (~2G elements) before encoutering capacity overflow.
// Note that this check works even when _items.Length overflowed thanks to the (uint) cast
//翻倍的大小不能超过【数组最大长度的最小质数】
if ((uint)newSize > MaxPrimeArrayLength && MaxPrimeArrayLength > oldSize)
{
Contract.Assert( MaxPrimeArrayLength == GetPrime(MaxPrimeArrayLength), "Invalid MaxPrimeArrayLength");
return MaxPrimeArrayLength;
}
//取最小的质数(素数)
return GetPrime(newSize);
}
public static int GetPrime(int min)
{
if (min < )
throw new ArgumentException(Environment.GetResourceString("Arg_HTCapacityOverflow"));
Contract.EndContractBlock();
//查找primes是否有满足的质数(素数)
for (int i = ; i < primes.Length; i++)
{
int prime = primes[i];
if (prime >= min) return prime;
}
//outside of our predefined table.
//compute the hard way.
//primes没有查找到满足的质数(素数),自行计算
for (int i = (min | ); i < Int32.MaxValue;i+=)
{
if (IsPrime(i) && ((i - ) % Hashtable.HashPrime != ))
return i;
}
return min;
}
}

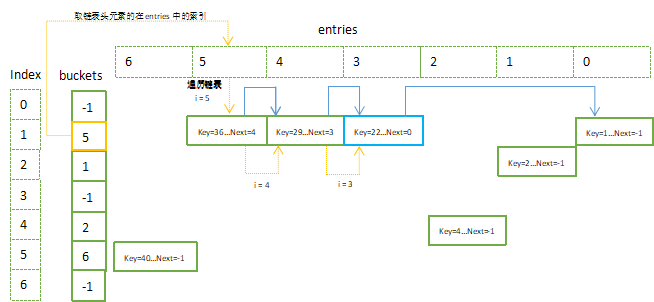
2.6 继续添加键值{22,22},{29,29},{36,36},{40,40},添加完后其内部存储结果如下

3. 取键值(Find)
public TValue this[TKey key] {
get {
//取Key对应值在entries的索引
int i = FindEntry(key);
if (i >= ) return entries[i].value;
ThrowHelper.ThrowKeyNotFoundException();
return default(TValue);
}
set {
//更新Key对应的值
Insert(key, value, false);
}
}
private int FindEntry(TKey key) {
if( key == null) {
ThrowHelper.ThrowArgumentNullException(ExceptionArgument.key);
}
if (buckets != null) {
int hashCode = comparer.GetHashCode(key) & 0x7FFFFFFF;
//遍历单链表
for (int i = buckets[hashCode % buckets.Length]; i >= ; i = entries[i].next) {
if (entries[i].hashCode == hashCode && comparer.Equals(entries[i].key, key)) return i;
}
}
return -;
}
*********************************************************************************************
static void Foo()
{
......
//取Key=22
var val =dicData[];
}
简化取Key对应值的代码
var hashCode =comparer.GetHashCode(key) & 0x7FFFFFFF; //
var targetBuget = hashCode % buckets.Length; //取模运算 1
var i = bucket[targetBuget]; //链表头元素的索引 bucket[1] = 5
//遍历单链表
for (; i >= ; i = entries[i].next) {
if (entries[i].hashCode == hashCode && comparer.Equals(entries[i].key, key)) return i;
}
4. 移除键值(Remove)
public bool Remove(TKey key) {
if(key == null) {
ThrowHelper.ThrowArgumentNullException(ExceptionArgument.key);
}
if (buckets != null) {
int hashCode = comparer.GetHashCode(key) & 0x7FFFFFFF;
int bucket = hashCode % buckets.Length;
int last = -;
//其原理先取出键值,然后记录entries空闲的索引(freeList)和空闲个数(freeCount)
for (int i = buckets[bucket]; i >= ; last = i, i = entries[i].next) {
if (entries[i].hashCode == hashCode && comparer.Equals(entries[i].key, key)) {
if (last < ) {
buckets[bucket] = entries[i].next;
}
else {
entries[last].next = entries[i].next;
}
entries[i].hashCode = -;
//建立空闲链表
entries[i].next = freeList;
entries[i].key = default(TKey);
entries[i].value = default(TValue);
//保存entryies中空元素的索引
//便于插入新键值时,放在当前索引的位置,减少entryies空间上的浪费
freeList = i;
//空元素的个数加1
freeCount++;
version++;
return true;
}
}
}
return false;
}
*******************************************************************
static void Foo()
{
......
//移除
new List<int> { , }.ForEach(item => dicData.Remove(item));
}
4.1 移除Key=22后,freeList = 3, freeCount = 1,
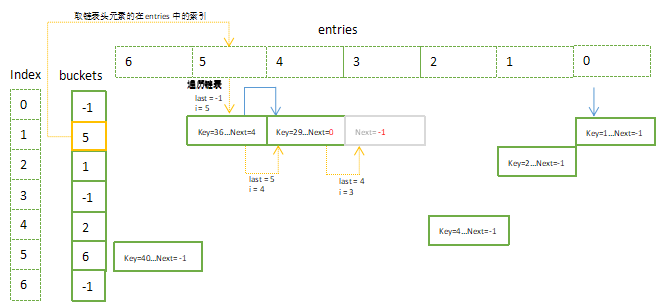
4.2 移除Key=36后,freeList = 5, freeCount = 2,
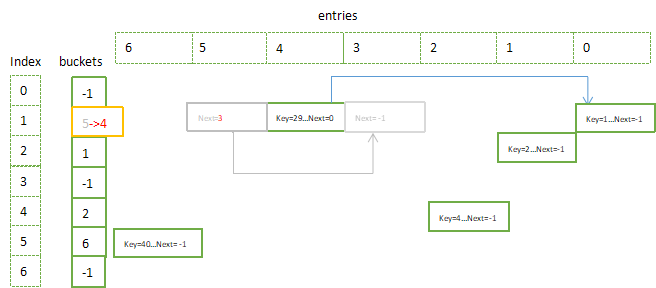
5. 再插入键值
- 给entries[5]赋值,freeList = 3, freeCount = 1;
- 给entries[3]赋值,freeList = -1, freeCount = 0;
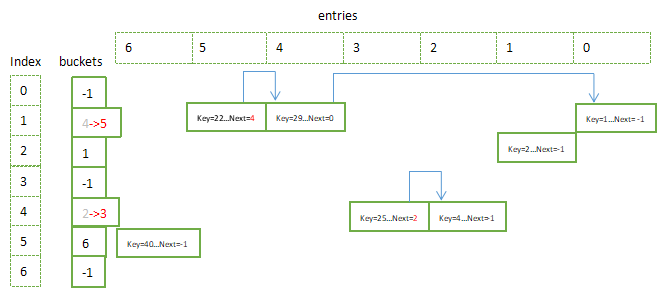
希望此文能够让你对于Dictionary内部实现有所认识。
一步一步剖析Dictionary实现原理的更多相关文章
- 一步一步从原理跟我学邮件收取及发送 2.邮箱的登录和绕不开的base64
一步一步从原理跟我学邮件收取及发送 2.邮箱的登录和绕不开的base64 好了,经过本系列上一篇文章 "1.网络命令的发送",假设大家已经掌握了 email 电子邮件的命令发送的方 ...
- Vue双向绑定原理,教你一步一步实现双向绑定
当今前端天下以 Angular.React.vue 三足鼎立的局面,你不选择一个阵营基本上无法立足于前端,甚至是两个或者三个阵营都要选择,大势所趋. 所以我们要时刻保持好奇心,拥抱变化,只有在不断的变 ...
- xmppmini 项目详解:一步一步从原理跟我学实用 xmpp 技术开发 2.登录的实现
第二章登录的实现 金庸<倚天屠龙记> 张三丰缓缓摇头,说道:“少林派累积千年,方得达成这等绝技,决非一蹴而至,就算是绝顶聪明之人,也无法自创.”他顿了一顿,又道:“我当年在少林寺中住过,只 ...
- javascript 函数 add(1)(2)(3)(4)实现无限极累加 —— 一步一步原理解析
问题:我们有一个需求,用js 实现一个无限极累加的函数, 形如 add(1) //=> 1; add(1)(2) //=> 2; add(1)(2)(3) //=> 6; add ...
- 剖析Promise内部结构,一步一步实现一个完整的、能通过所有Test case的Promise类
本文写给有一定Promise使用经验的人,如果你还没有使用过Promise,这篇文章可能不适合你,建议先了解Promise的使用 Promise标准解读 1.只有一个then方法,没有catch,ra ...
- 一步一步开发Game服务器(四)地图线程
时隔这么久 才再一次的回归正题继续讲解游戏服务器开发. 开始讲解前有一个问题需要修正.之前讲的线程和定时器线程的时候是分开的. 但是真正地图线程与之前的线程模型是有区别的. 为什么会有区别呢?一个地图 ...
- 全面剖析Redis Cluster原理和应用 (转)
1.Redis Cluster总览 1.1 设计原则和初衷 在官方文档Cluster Spec中,作者详细介绍了Redis集群为什么要设计成现在的样子.最核心的目标有三个: 性能:这是Redis赖以生 ...
- 老李推荐:第6章2节《MonkeyRunner源码剖析》Monkey原理分析-事件源-事件源概览-获取命令字串
老李推荐:第6章2节<MonkeyRunner源码剖析>Monkey原理分析-事件源-事件源概览-获取命令字串 从上一节的描述可以知道,MonkeyRunner发送给Monkey的命令 ...
- 【DG】[三思笔记]一步一步学DataGuard
[DG][三思笔记]一步一步学DataGuard 它有无数个名字,有人叫它dg,有人叫它数据卫士,有人叫它data guard,在oracle的各项特性中它有着举足轻理的地位,它就是(掌声)..... ...
随机推荐
- SPOJ - VFMUL - Very Fast Multiplication FFT加速高精度乘法
SPOJ - VFMUL:https://vjudge.net/problem/SPOJ-VFMUL 这是一道FFT求高精度的模板题. 参考:https://www.cnblogs.com/Rabbi ...
- 背包形动态规划 fjutoj2375 金明的预算方案
金明的预算方案 TimeLimit:1000MS MemoryLimit:128MB 64-bit integer IO format:%lld Problem Description 金明今天 ...
- 百度之星 资格赛 1003 度度熊与邪恶大魔王 dp(背包)
度度熊与邪恶大魔王 Accepts: 1141 Submissions: 6840 Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 3 ...
- SpringDataJpa入门案例及查询详细解析
SpringDataJpaSpring Data JPA 让我们解脱了DA0层的操作,基本上所有CRUD都可以依赖于它来实现,在实际的工作工程中,推荐使用Spring Data JPA+ORM(如:h ...
- java 高薪计划
一.基础 集合类,并发包,IO/NIO,JVM,内存模型,泛型,异常,反射,等有深入了解,最好是看过源码了解底层的设计. 二.需要全面的互联网主流技术相关知识 深入了解mysql,redis,mong ...
- 【DataBase】事务
一.事务概述 二.事务的四大特性(ACID) 三.事务的隔离性导致的问题 四.数据库的四个隔离级别 五.数据库中的锁机制: 六.更新丢失 七.并发事务所带来的的问题 一.事务概述 事务的概念:事务是指 ...
- Linux基础提高_sudo,行为审计,跳板机
sudo 临时给普通用户赋予root权限的一种方式 echo "%wheel ALL=(ALL) NOPASSWD: ALL" >>/etc/ ...
- 分享个人学习js的笔记
1.回到顶部效果. 2.滚动条向上滚动式,滑动滚轮.解决bug的方法. 3.有关Document. 4.getElementByClassName();获取元素类名的封装.单个类名的元素.任然不完美. ...
- 漏洞复现:MS17-010缓冲区溢出漏洞(永恒之蓝)
MS17-010缓冲区溢出漏洞复现 攻击机:Kali Linux 靶机:Windows7和2008 1.打开攻击机Kali Linux,msf更新到最新版本(现有版本5.x),更新命令:apt-get ...
- opencv边缘检测报错
cnts = cv2.findContours(edged_image.copy(), cv2.RETR_LIST, cv2.CHAIN_APPROX_SIMPLE)cnts = cnts[0] if ...