[spark程序]统计人口平均年龄(本地文件)(详细过程)
一、题目描述
(1)编写Spark应用程序,该程序可以在本地文件系统中生成一个数据文件peopleage.txt,数据文件包含若干行(比如1000行,或者100万行等等)记录,每行记录只包含两列数据,第1列是序号,第2列是年龄。效果如下:
1 89
2 67
3 69
4 78
(2)编写Spark应用程序,对本地文件系统中的数据文件peopleage.txt的数据进行处理,计算出所有人口的平均年龄。
二、实现
1、生成数据文件peopleage.txt
1)创建程序的目录结构
创建一个存放代码的目录,进入目录下创建一个目录用来保存该题目所有文件(/swy/resource/spark/peopleage)
在peopleage目录下建立src/main/scala代码目录,专门用来保存scala代码文件,命令如下:

2)生成数据文件peopleage.txt的代码
创建一个代码文件GeneratePeopleAge.scala,用来生成数据文件peopleage.txt,命令如下:


代码如下:
import java.io.FileWriter
import java.io.File
import scala.util.Random object GeneratePeopleAge{ def main(args:Array[String]){
val fileWriter = new FileWriter(new File("/swy/resource/spark/peopleage/peopleage.txt"),false)
val rand = new Random()
for (i <- 1 to 1000){
fileWriter.write(i+" "+rand.nextInt(100))
fileWriter.write(System.getProperty("line.separator"))
}
fileWriter.flush()
fileWriter.close()
}
}
3)sbt打包
退回到people目录下:

输入如下:
name := "Simple Project"
version := "1.0"
scalaVersion := "2.11.12"
libraryDependencies += "org.apache.spark" %% "spark-core" % "2.1.0"
输入命令打包:
sbt package
打包成功:

4)运行文件,生成peopleage.txt

可以看到目录下已经生成peopleage.txt,查看文件:

2、计算所有人口的平均年龄
1)创建CountAvgage.scala

2)代码
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext object CountAvgAge {
def main(args:Array[String]) {
if (args.length < 1) {
println("Usage: CountAvgAge inputdatafile")
System.exit(1)
}
val conf = new SparkConf().setAppName("Count average age")
val sc = new SparkContext(conf)
val lines = sc.textFile(args(0),3)
val peopleNum =lines.count()
val totalAge = lines.map(line => line.split(" ")(1)).map(t => t.trim.toInt).collect().reduce((a,b) => a+b)
println("Total Age is: " +totalAge+ "; Number of People is: " +peopleNum)
val avgAge : Double = totalAge.toDouble / peopleNum.toDouble
println("Average Age is: " +avgAge)
}
}
3)打包
退回people文件夹,输入命令打包:

4)运行程序
输入如下命令:

结果:
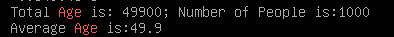
原文:http://dblab.xmu.edu.cn/blog/1756-2/
[spark程序]统计人口平均年龄(本地文件)(详细过程)的更多相关文章
- [spark程序]统计人口平均年龄(HDFS文件)(详细过程)
一.题目描述 (1)请编写Spark应用程序,该程序可以在分布式文件系统HDFS中生成一个数据文件peopleage.txt,数据文件包含若干行(比如1000行,或者100万行等等)记录,每行记录只包 ...
- 记录一次用宝塔部署微信小程序Node.js后端接口代码的详细过程
一直忙着写毕设,上一次写博客还是元旦,大半年过去了.... 后面会不断分享各种新项目的源码与技术.欢迎关注一起学习哈! 记录一次部署微信小程序Node.js后端接口代码的详细过程,使用宝塔来部署. 我 ...
- R语言—统计结果输出至本地文件方法总结
1.sink()在代码开始前加一行:sink(“output.txt”),就会自动把结果全部输出到工作文件夹下的output.txt文本文档.这时在R控制台的输出窗口中是看不到输出结果的.代码结束时用 ...
- JNI初级:android studio生成so文件详细过程
本文主要参考blog:http://blog.csdn.net/jkan2001/article/details/54316375 下面是本人结合blog生成so包过程中遇到一些问题和解决方法 (1) ...
- Spark保存到HDFS或本地文件相关问题
spark中saveAsTextFile如何最终生成一个文件 http://www.lxway.com/641062624.htm 一般而言,saveAsTextFile会按照执行task的多少生成多 ...
- 5、创建RDD(集合、本地文件、HDFS文件)
一.创建RDD 1.创建RDD 进行Spark核心编程时,首先要做的第一件事,就是创建一个初始的RDD.该RDD中,通常就代表和包含了Spark应用程序的输入源数据.然后在创建了初始的RDD之后,才可 ...
- Spark程序本地运行
Spark程序本地运行 本次安装是在JDK安装完成的基础上进行的! SPARK版本和hadoop版本必须对应!!! spark是基于hadoop运算的,两者有依赖关系,见下图: 前言: 1.环境 ...
- Spark学习笔记1——第一个Spark程序:单词数统计
Spark学习笔记1--第一个Spark程序:单词数统计 笔记摘抄自 [美] Holden Karau 等著的<Spark快速大数据分析> 添加依赖 通过 Maven 添加 Spark-c ...
- spark本地环境的搭建到运行第一个spark程序
搭建spark本地环境 搭建Java环境 (1)到官网下载JDK 官网链接:https://www.oracle.com/technetwork/java/javase/downloads/jdk8- ...
随机推荐
- cobalt strike和metasploit结合使用(互相传递shell会话
攻击机 192.168.5.173 装有msf和cs 受害机 192.168.5.179 win7 0x01 msf 派生 shell 给 Cobalt strike Msfvenom生成木马上线: ...
- Electron开发跨平台桌面程序入门教程
最近一直在学习 Electron 开发桌面应用程序,在尝试了 java swing 和 FXjava 后,感叹还是 Electron 开发桌面应用上手最快.我会在这一篇文章中实现一个HelloWord ...
- selenium驱动chrome浏览器问题
selenium是一个浏览器自动化测试框架,以下介绍其如何驱动chrome浏览器? 1.下载与本地chrome版本对应的chromedriver.exe ,下载地址为http://npm.taobao ...
- 2. Rsync-远程同步(上)
课程大纲: 1.什么是备份? 就是给源文件 增加 一个 副本. U盘 D --> E 2.为什么要做备份? 1.数据重要? 2.防止误操作 3.能够快速恢复 3.能不能不做备份? 可以, 不重要 ...
- git clone下代码window与unix换行问题
项目中避免不了会写一些shell脚本,使用ln软连接到一个目录.当git clone到windows中,ln连接显示无比怪异(如../xx),打开.sh文件后(仅仅是打开了),git status会看 ...
- vue-cli2、vue-cli3脚手架详细讲解
前言: vue脚手架指的是vue-cli它是vue官方提供的一个快速构建单页面(SPA)环境配置的工具,cli 就是(command-line-interface ) 命令行界面 .vue-cli是 ...
- Unity C#数据持久化与xml
最近工作需要用到数据持久化,所以在此分享一下,通过查阅资料,数据持久化大体都是通过xml或者json来进行的.unity为我们自定义了数据持久化方法,但是比较局限,还需要自己来完成数据持久化方法. ( ...
- 2018.8.9 python中的动态传参与命名空间
主要内容: 1.函数参数 ----动态传参 2.名称空间与作用域 3.函数的嵌套 4.global,nonlocal关键字 一.函数参数 ------动态传参 形参的第三种:动态传参 动态传参分为两种 ...
- 面向对象的7个设计原则->开车理解->贴近生活
设计模式在我们的开发中是不可或缺的一部分,很多人会说,我没用那些设计模式啊,我也开发的挺好的,其实不然,我们在开发中都用到了这些设计模式,只不过我们并没有在意这些,今天我就用开车的方法来解释一下我们的 ...
- java中的时区转换
目录 java中的时区转换 一.时区的说明 二.时间的表示 三.时间戳 四.Date类和时间戳 五.java中的时区转换 java中的时区转换 一.时区的说明 地球表面按经线从东到西,被划成一个个区域 ...