Scrapy的Spider类和CrawlSpider类
Scrapy shell
用来调试Scrapy 项目代码的 命令行工具,启动的时候预定义了Scrapy的一些对象
设置 shell
Scrapy 的shell是基于运行环境中的python 解释器shell
本质上就是通过命令调用shell,并在启动的时候预定义需要使用的对象
scrapy允许通过在项目配置文件”scrapy.cfg”中进行配置来指定解释器shell,例如:
[settings]
shell = ipython
启动 shell
启动Scrapy shell的命令语法格式:scrapy shell [option] [url|file]
url 就是你想要爬取的网址,分析本地文件时一定要带上路径,scrapy shell默认当作url
Spider类
运行流程
首先生成初始请求以爬取第一个URL,并指定要使用从这些请求下载的响应调用的回调函数
在回调函数中,解析响应(网页)并返回,Item对象、Request对象或这些对象的可迭代的dicts
最后,从蜘蛛返回的项目通常会持久保存到数据库(在某些项目管道中)或导出写入文件
属性

name: spider的名称、必须是唯一的
start_urls: 起始urls、初始的Request请求来源
customer_settings: 自定义设置、运行此蜘蛛时将覆盖项目范围的设置。必须将其定义为类属性,因为在实例化之前更新了设置
logger: 使用Spider创建的Python日志器
方法
from_crawler:创建spider的类方法
start_requests:开始请求、生成request交给引擎下载返回response
parse:默认的回调方法,在子类中必须要重写
close:spider关闭时调用
CrawlSpider类
Spider类 是匹配url,然后返回request请求
CrawlSpider类 根据url规则,自动生成request请求
创建CrawlSpider类爬虫文件
crapy genspider -t crawl 爬虫名 域名
LinkExtractor参数

allow:正则表达式,满足的url会被提取出来
deny:正则表达式,满足的url不会被提取出来
estrict_xpaths:路径表达式,符合路径的标签提取出来
Rule参数

linkextractor:提取链接的实例对象
callback:回调函数
follow:指定是否应该从使用此规则提取的每个响应中跟踪链接
process_links:用于过滤连接的回调函数
process_request:用于过滤请求的回调函数
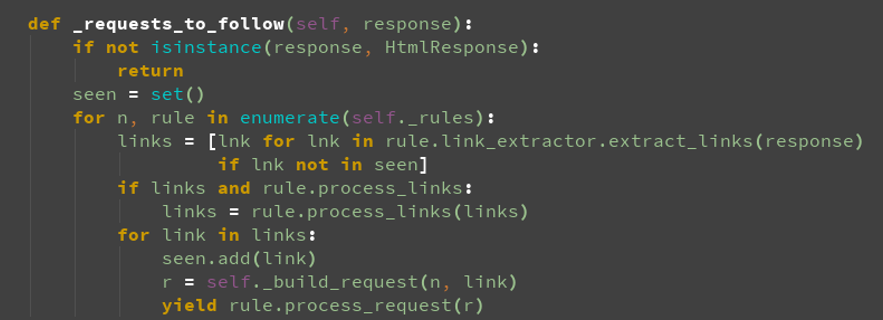
url去重
Scrapy的Spider类和CrawlSpider类的更多相关文章
- Scrapy框架——CrawlSpider类爬虫案例
Scrapy--CrawlSpider Scrapy框架中分两类爬虫,Spider类和CrawlSpider类. 此案例采用的是CrawlSpider类实现爬虫. 它是Spider的派生类,Spide ...
- 13.CrawlSpider类爬虫
1.CrawlSpider介绍 Scrapy框架中分两类爬虫,Spider类和CrawlSpider类. 此案例采用的是CrawlSpider类实现爬虫. 它是Spider的派生类,Spider类的设 ...
- python爬虫入门(八)Scrapy框架之CrawlSpider类
CrawlSpider类 通过下面的命令可以快速创建 CrawlSpider模板 的代码: scrapy genspider -t crawl tencent tencent.com CrawSpid ...
- scrapy的CrawlSpider类
了解CrawlSpider 踏实爬取一般网站的常用spider,其中定义了一些规则(rule)来提供跟进link的方便机制,也许该spider不适合你的目标网站,但是对于大多数情况是可以使用的.因此, ...
- scrapy项目4:爬取当当网中机器学习的数据及价格(CrawlSpider类)
scrapy项目3中已经对网页规律作出解析,这里用crawlspider类对其内容进行爬取: 项目结构与项目3中相同如下图,唯一不同的为book.py文件 crawlspider类的爬虫文件book的 ...
- scrapy系列(四)——CrawlSpider解析
CrawlSpider也继承自Spider,所以具备它的所有特性,这些特性上章已经讲过了,就再在赘述了,这章就讲点它本身所独有的. 参与过网站后台开发的应该会知道,网站的url都是有一定规则的.像dj ...
- Scrapy(五):CrawlSpider的使用
Scrapy(五):CrawlSpider的使用 说明 :CrawlSpider,就是一个类,是Spider的一个子类,也是一个官方类,因为是子类,所以功能更加的强大,多了一项功能:去指定的页面中来抓 ...
- 爬虫07 /scrapy图片爬取、中间件、selenium在scrapy中的应用、CrawlSpider、分布式、增量式
爬虫07 /scrapy图片爬取.中间件.selenium在scrapy中的应用.CrawlSpider.分布式.增量式 目录 爬虫07 /scrapy图片爬取.中间件.selenium在scrapy ...
- Scrapy框架-Spider
目录 1. Spider 2.Scrapy源代码 2.1. Scrapy主要属性和方法 3.parse()方法的工作机制 1. Spider Spider类定义了如何爬取某个(或某些)网站.包括了爬取 ...
随机推荐
- k8s采坑记 - 解决二进制安装环境下证书过期问题
前言 上一篇k8s采坑记 - 证书过期之kubeadm重新生成证书阐述了如何使用kubeadm解决k8s证书过期问题. 本篇阐述使用二进制安装的kubernetes环境,如何升级过期证书? k8s配置 ...
- asp.net core 3.0获取web应用的根目录
目录 1.需求 2.解决方案 1.需求 asp.net core 3.0的web项目中,在controller中,想要获取wwwroot下的imgs/banners文件夹下的所有文件: 在传统的asp ...
- Python 之列表切片的四大常用操作
最近在爬一个网站的文档的时候,老师要求把一段文字切割开来,根据中间的文本分成两段 故学习了一段时间的切片操作,现把学习成果po上来与大家分享 1.何为切片? 列表的切片就是处理列表中的部分元素,是把整 ...
- 如何判断IE OCX插件正常安装?
项目中用到了一个第三方的ie ocx控件,而经常遇到客户和测试小伙伴反馈相关功能无法正常使用,也没有友好提示.考虑到这个问题,必须要有一个ie ocx控件的检查机制. 检查原理 创建ActiveXOb ...
- 数据库索引的优化及SQL处理过程
想要设计出好的索引,首先必须了解SQL语句在数据库服务器中的处理过程,本文介绍数据库索引设计与优化中几个对索引优化非常重要的概念. 谓词 谓词就是条件表达式. SQL语句的where子句由一个或者多个 ...
- Android Studio出现Failed to open zip file问题的解决方法
直接在网上找到gradle-3.3-all.zip下载下来,不要解压缩,放在类似下面的目录中 C:\Users\Administrator\.gradle\wrapper\dists\gradle-3 ...
- windows 本地链接 VMware虚拟机 redis服务
使用本地Windows链接 VMware虚拟机 redis服务 我用的虚拟机系统是:windows Server 2012 先把Redis服务器拷贝到服务器并解压,目录如下 这里仅仅作为演示,所以就不 ...
- C lang: Compound literal
Xx_Introduction C99 stantard. Upate array and struct a compound literal. Literal is date type value. ...
- python发送邮件(smtplib)
我们在测试完成后,都会发一份邮件也就是我们的测试报告,那么既然要自动化,是不是也可以通过python帮助我们发送邮件?当然这么强大的python可以帮助你完成这个需求 SMTP SMTP(Simple ...
- BZOJ2301/LG2522 「HAOI2011」Problem B 莫比乌斯反演 数论分块
问题描述 BZOJ2301 LG2522 积性函数 若函数 \(f(x)\) 满足对于任意两个最大公约数为 \(1\) 的数 \(m,n\) ,有 \(f(mn)=f(m) \times f(n)\) ...