【集合系列】- 深入浅出分析HashMap
作者:炸鸡可乐
原文出处:www.pzblog.cn
一、摘要
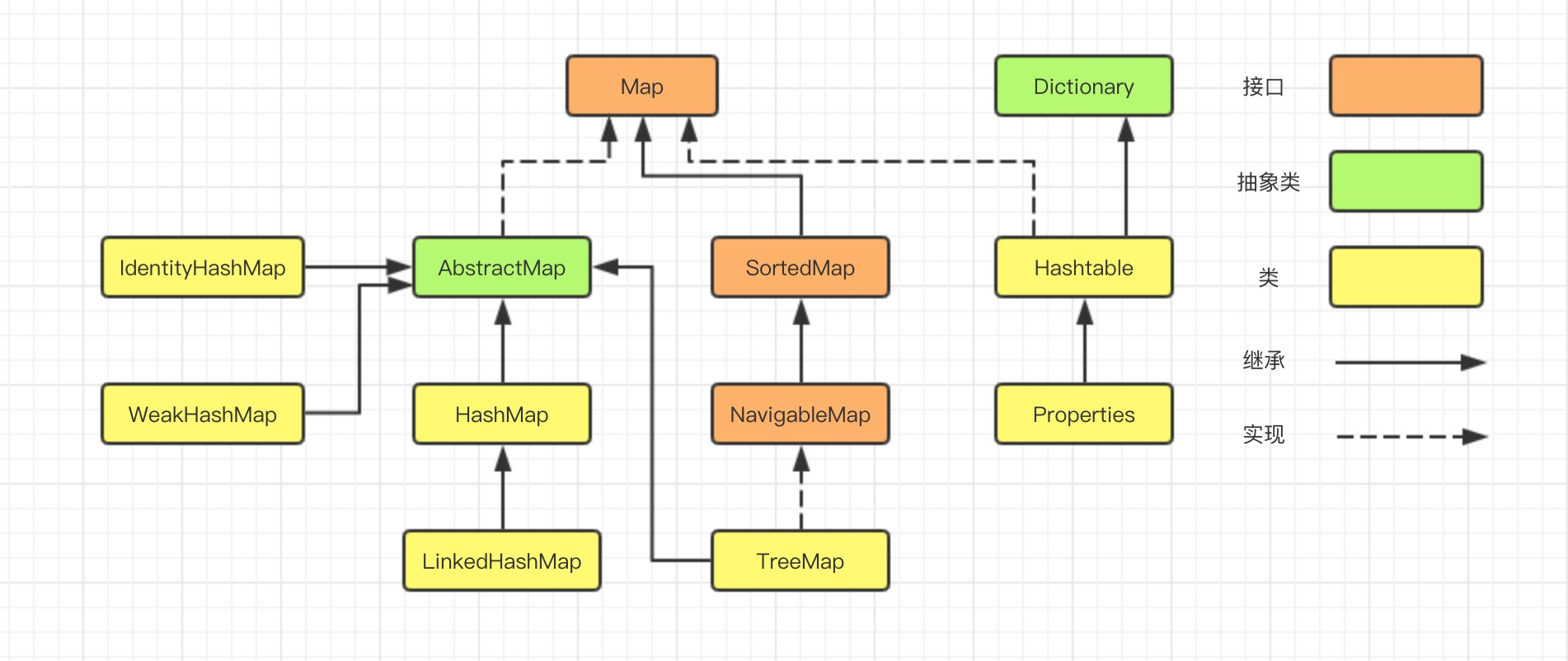
在集合系列的第一章,咱们了解到,Map的实现类有HashMap、LinkedHashMap、TreeMap、IdentityHashMap、WeakHashMap、Hashtable、Properties等等。
关于HashMap,一直都是一个非常热门的话题,只要你出去面试,我保证一定少不了它!
本文主要结合JDK1.7和JDK1.8的区别,就HashMap的数据结构和实现功能,进行深入探讨,废话也不多说了,直奔主题!
二、简介
在程序编程的时候,HashMap是一个使用非常频繁的容器类,它允许键值都放入null元素。除该类方法未实现同步外,其余跟Hashtable大致相同,但跟TreeMap不同,该容器不保证元素顺序,根据需要该容器可能会对元素重新哈希,元素的顺序也会被重新打散,因此不同时间迭代同一个HashMap的顺序可能会不同。
HashMap容器,实质还是一个哈希数组结构,但是在元素插入的时候,存在发生hash冲突的可能性;
对于发生Hash冲突的情况,冲突有两种实现方式,一种开放地址方式(当发生hash冲突时,就继续以此继续寻找,直到找到没有冲突的hash值),另一种是拉链方式(将冲突的元素放入链表)。Java HashMap采用的就是第二种方式,拉链法。
在jdk1.7中,HashMap主要是由数组+链表组成,当发生hash冲突的时候,就将冲突的元素放入链表中。
从jdk1.8开始,HashMap主要是由数组+链表+红黑树实现的,相比jdk1.7而言,多了一个红黑树实现。当链表长度超过8的时候,就将链表变成红黑树,如图所示。
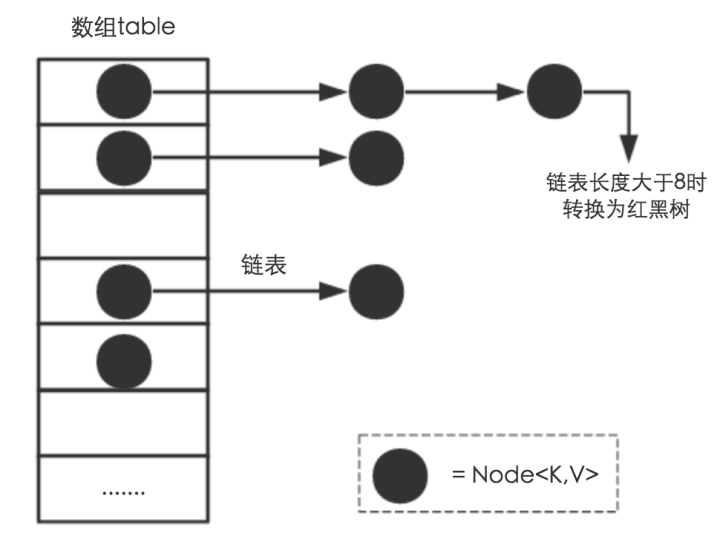
关于红黑树的实现,因为篇幅太长,在《集合系列》文章中红黑树设计,也有所介绍,这里就不在详细介绍了。
三、源码解析
直接打开HashMap的源码分析,可以看到,主要有5个关键参数:
- threshold:表示容器所能容纳的key-value对极限。
- loadFactor:负载因子。
- modCount:记录修改次数。
- size:表示实际存在的键值对数量。
- table:一个哈希桶数组,键值对就存放在里面。
public class HashMap<K,V> extends AbstractMap<K,V>
implements Map<K,V>, Cloneable, Serializable {
//所能容纳的key-value对极限
int threshold;
//负载因子
final float loadFactor;
//记录修改次数
int modCount;
//实际存在的键值对数量
int size;
//哈希桶数组
transient Node<K,V>[] table;
}
接着来看看Node这个类,Node是HashMap的一个内部类,实现了Map.Entry接口,本质是就是一个映射(键值对)
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;//hash值
final K key;//k键
V value;//value值
Node<K,V> next;//链表中下一个元素
}
在HashMap的数据结构中,有两个参数可以影响HashMap的性能:初始容量(inital capacity)和负载因子(load factor)。
初始容量(inital capacity)是指table的初始长度length(默认值是16);
负载因子(load factor)用指自动扩容的临界值(默认值是0.75);
threshold是HashMap所能容纳的最大数据量的Node(键值对)个数,计算公式threshold = capacity * Load factor。当entry的数量超过capacity*load_factor时,容器将自动扩容并重新哈希,扩容后的HashMap容量是之前容量的两倍,所以数组的长度总是2的n次方。
初始容量和负载因子也可以修改,具体实现方式,可以在对象初始化的时候,指定参数,比如:
Map map = new HashMap(int initialCapacity, float loadFactor);
但是,默认的负载因子0.75是对空间和时间效率的一个平衡选择,建议大家不要修改,除非在时间和空间比较特殊的情况下,如果内存空间很多而又对时间效率要求很高,可以降低负载因子Load factor的值;相反,如果内存空间紧张而对时间效率要求不高,可以增加负载因子loadFactor的值,这个值可以大于1。 同时,对于插入元素较多的场景,可以将初始容量设大,减少重新哈希的次数。
HashMap的内部功能实现有很多,本文主要从以下几点,进行逐步分析。
- 通过K获取数组下标;
- put方法的详细执行;
- resize扩容过程;
- get方法获取参数值;
- remove删除元素;
3.1、通过K获取数组下标
不管增加、删除还是查找键值对,定位到数组的位置都是很关键的第一步,打开hashMap的任意一个增加、删除、查找方法,从源码可以看出,通过key获取数组下标,主要做了3步操作,其中length指的是容器数组的大小。
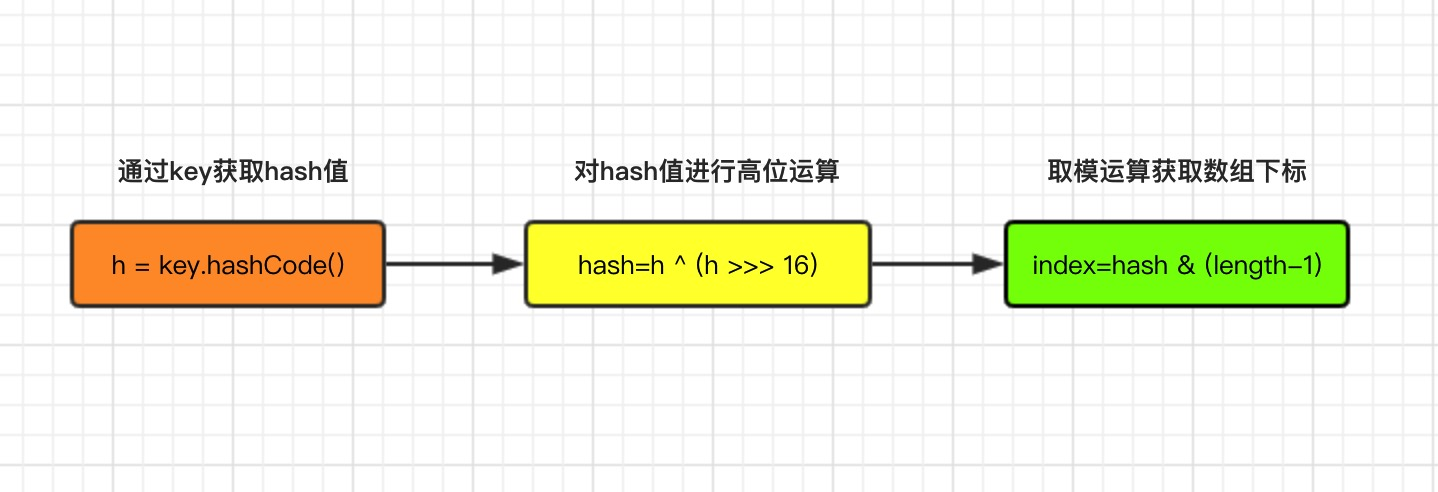
源码部分:
/**获取hash值方法*/
static final int hash(Object key) {
int h;
// h = key.hashCode() 为第一步 取hashCode值(jdk1.7)
// h ^ (h >>> 16) 为第二步 高位参与运算(jdk1.7)
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);//jdk1.8
}
/**获取数组下标方法*/
static int indexFor(int h, int length) {
//jdk1.7的源码,jdk1.8没有这个方法,但是实现原理一样的
return h & (length-1); //第三步 取模运算
}
3.2、put方法的详细执行
put(K key, V value)方法是将指定的key, value对添加到map里。该方法首先会对map做一次查找,看是否包含该K,如果已经包含则直接返回;如果没有找到,则将元素插入容器。具体插入过程如下:
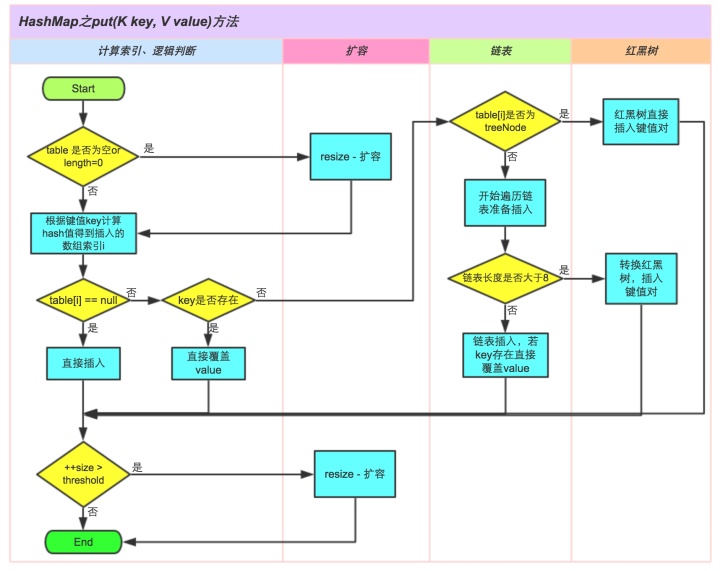
具体执行步骤
- 1、判断键值对数组table[i]是否为空或为null,否则执行resize()进行扩容;
- 2、根据键值key计算hash值得到插入的数组索引i,如果table[i]==null,直接新建节点添加;
- 3、当table[i]不为空,判断table[i]的首个元素是否和传入的key一样,如果相同直接覆盖value;
- 4、判断table[i] 是否为treeNode,即table[i] 是否是红黑树,如果是红黑树,则直接在树中插入键值对;
- 5、遍历table[i],判断链表长度是否大于8,大于8的话把链表转换为红黑树,在红黑树中执行插入操作,否则进行链表的插入操作;遍历过程中若发现key已经存在直接覆盖value即可;
- 6、插入成功后,判断实际存在的键值对数量size是否超多了最大容量threshold,如果超过,进行扩容操作;
put方法源码部分
/**
* put方法
*/
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
插入元素方法
/**
* 插入元素方法
*/
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
//1、判断数组table是否为空或为null
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
//2、判断数组下标table[i]==null
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
//3、判断table[i]的首个元素是否和传入的key一样
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
//4、判断table[i] 是否为treeNode
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
//5、遍历table[i],判断链表长度是否大于8
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
//长度大于8,转红黑树结构
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
//传入的K元素已经存在,直接覆盖value
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
//6、判断size是否超出最大容量
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
其中,与jdk1.7有区别的地方,第4步新增了红黑树插入方法,源码部分:
/**
* 红黑树的插入操作
*/
final TreeNode<K,V> putTreeVal(HashMap<K,V> map, Node<K,V>[] tab,
int h, K k, V v) {
Class<?> kc = null;
boolean searched = false;
TreeNode<K,V> root = (parent != null) ? root() : this;
for (TreeNode<K,V> p = root;;) {
//dir:遍历的方向, ph:p节点的hash值
int dir, ph; K pk;
//红黑树是根据hash值来判断大小
// -1:左孩子方向 1:右孩子方向
if ((ph = p.hash) > h)
dir = -1;
else if (ph < h)
dir = 1;
//如果key存在的话就直接返回当前节点
else if ((pk = p.key) == k || (k != null && k.equals(pk)))
return p;
//如果当前插入的类型和正在比较的节点的Key是Comparable的话,就直接通过此接口比较
else if ((kc == null &&
(kc = comparableClassFor(k)) == null) ||
(dir = compareComparables(kc, k, pk)) == 0) {
if (!searched) {
TreeNode<K,V> q, ch;
searched = true;
//尝试在p的左子树或者右子树中找到了目标元素
if (((ch = p.left) != null &&
(q = ch.find(h, k, kc)) != null) ||
((ch = p.right) != null &&
(q = ch.find(h, k, kc)) != null))
return q;
}
//获取遍历的方向
dir = tieBreakOrder(k, pk);
}
//上面的所有if-else判断都是在判断下一次进行遍历的方向,即dir
TreeNode<K,V> xp = p;
//当下面的if判断进去之后就代表找到了目标操作元素,即xp
if ((p = (dir <= 0) ? p.left : p.right) == null) {
Node<K,V> xpn = xp.next;
//插入新的元素
TreeNode<K,V> x = map.newTreeNode(h, k, v, xpn);
if (dir <= 0)
xp.left = x;
else
xp.right = x;
//因为TreeNode今后可能退化成链表,在这里需要维护链表的next属性
xp.next = x;
//完成节点插入操作
x.parent = x.prev = xp;
if (xpn != null)
((TreeNode<K,V>)xpn).prev = x;
//插入操作完成之后就要进行一定的调整操作了
moveRootToFront(tab, balanceInsertion(root, x));
return null;
}
}
}
3.3、resize扩容过程
在说jdk1.8的HashMap动态扩容之前,我们先来了解一下jdk1.7的HashMap扩容实现,因为jdk1.8代码实现比Java1.7复杂了不止一倍,主要是Java1.8引入了红黑树设计,但是实现思想大同小异!
3.3.1、jdk1.7的扩容实现
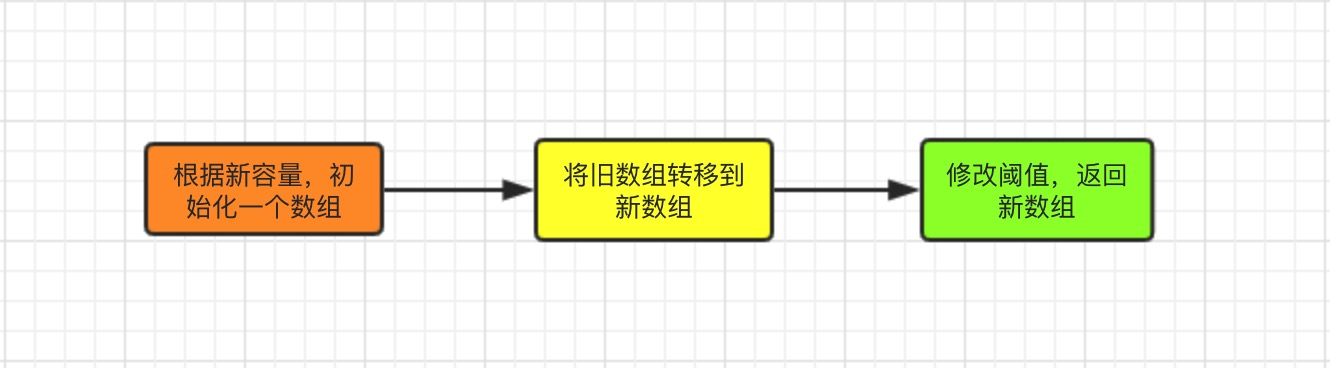
源码部分
/**
* JDK1.7扩容方法
* 传入新的容量
*/
void resize(int newCapacity) {
//引用扩容前的Entry数组
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
//扩容前的数组大小如果已经达到最大(2^30)了
if (oldCapacity == MAXIMUM_CAPACITY) {
//修改阈值为int的最大值(2^31-1),这样以后就不会扩容了
threshold = Integer.MAX_VALUE;
return;
}
//初始化一个新的Entry数组
Entry[] newTable = new Entry[newCapacity];
//将数据转移到新的Entry数组里,这里包含最重要的重新定位
transfer(newTable);
//HashMap的table属性引用新的Entry数组
table = newTable;
threshold = (int) (newCapacity * loadFactor);//修改阈值
}
transfer复制数组方法,源码部分:
//遍历每个元素,按新的容量进行rehash,放到新的数组上
void transfer(Entry[] newTable) {
//src引用了旧的Entry数组
Entry[] src = table;
int newCapacity = newTable.length;
for (int j = 0; j < src.length; j++) {
//遍历旧的Entry数组
Entry<K, V> e = src[j];
//取得旧Entry数组的每个元素
if (e != null) {
//释放旧Entry数组的对象引用(for循环后,旧的Entry数组不再引用任何对象)
src[j] = null;
do {
Entry<K, V> next = e.next;
//重新计算每个元素在数组中的位置
//实现逻辑,也是上文那个取模运算方法
int i = indexFor(e.hash, newCapacity);
//标记数组
e.next = newTable[i];
//将元素放在数组上
newTable[i] = e;
//访问下一个Entry链上的元素,循环遍历
e = next;
} while (e != null);
}
}
}
jdk1.7扩容总结:newTable[i]的引用赋给了e.next,也就是使用了单链表的头插入方式,同一位置上新元素总会被放在链表的头部位置;这样先放在一个索引上的元素终会被放到Entry链的尾部(如果发生了hash冲突的话),这一点和Jdk1.8有区别。在旧数组中同一条Entry链上的元素,通过重新计算索引位置后,有可能被放到了新数组的不同位置上。
3.3.2、jdk1.8的扩容实现
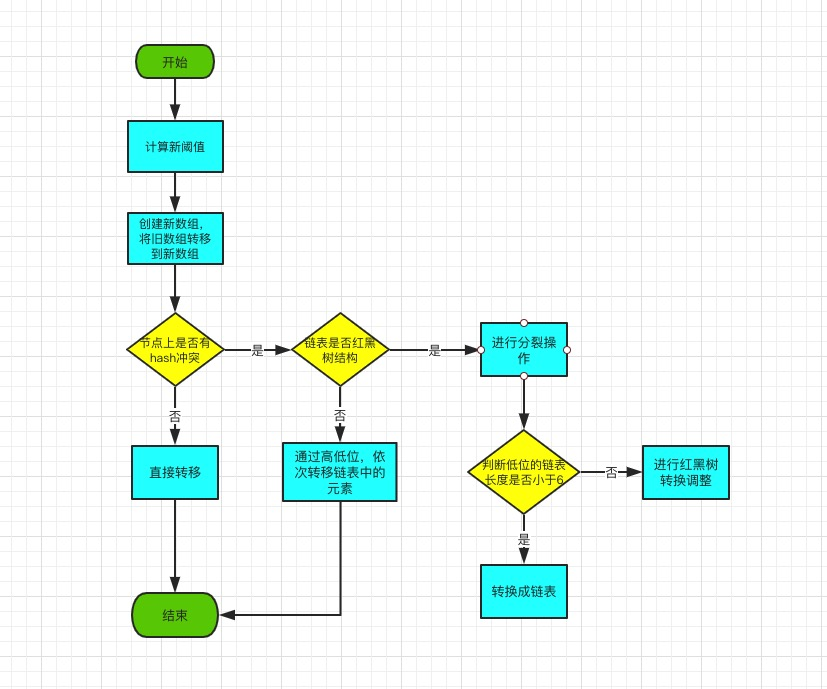
源码如下
final Node<K,V>[] resize() {
//引用扩容前的node数组
Node<K,V>[] oldTab = table;
//旧的容量
int oldCap = (oldTab == null) ? 0 : oldTab.length;
//旧的阈值
int oldThr = threshold;
//新的容量、阈值初始化为0
int newCap, newThr = 0;
if (oldCap > 0) {
//如果旧容量已经超过最大容量,让阈值也等于最大容量,以后不再扩容
threshold = Integer.MAX_VALUE;
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
// 没超过最大值,就扩充为原来的2倍
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
//如果旧容量翻倍没有超过最大值,且旧容量不小于初始化容量16,则翻倍
newThr = oldThr << 1; // double threshold
}
else if (oldThr > 0) // initial capacity was placed in threshold
//初始化容量设置为阈值
newCap = oldThr;
else { // zero initial threshold signifies using defaults
//0的时候使用默认值初始化
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
//计算新阈值,如果新容量或新阈值大于等于最大容量,则直接使用最大值作为阈值,不再扩容
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
//设置新阈值
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
//创建新的数组,并引用
table = newTab;
//如果老的数组有数据,也就是是扩容而不是初始化,才执行下面的代码,否则初始化的到这里就可以结束了
if (oldTab != null) {
//轮询老数组所有数据
for (int j = 0; j < oldCap; ++j) {
//以一个新的节点引用当前节点,然后释放原来的节点的引用
Node<K,V> e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
//如果e没有next节点,证明这个节点上没有hash冲突,则直接把e的引用给到新的数组位置上
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode)
//!!!如果是红黑树,则进行分裂
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else {
// 链表优化重hash的代码块
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
//从这条链表上第一个元素开始轮询,如果当前元素新增的bit是0,则放在当前这条链表上,如果是1,则放在"j+oldcap"这个位置上,生成“低位”和“高位”两个链表
do {
next = e.next;
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
//元素是不断的加到尾部的,不会像1.7里面一样会倒序
loTail.next = e;
//新增的元素永远是尾元素
loTail = e;
}
else {
//高位的链表与低位的链表处理逻辑一样,不断的把元素加到链表尾部
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
//低位链表放到j这个索引的位置上
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
//高位链表放到(j+oldCap)这个索引的位置上
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}
1.7与1.8处理逻辑大同小异,区别主要还是在树节点的分裂((TreeNode<K,V>)e).split() 这个方法上
/**
* 红黑树分裂方法
*/
final void split(HashMap<K,V> map, Node<K,V>[] tab, int index, int bit) {
//当前这个节点的引用,即这个索引上的树的根节点
TreeNode<K,V> b = this;
// Relink into lo and hi lists, preserving order
TreeNode<K,V> loHead = null, loTail = null;
TreeNode<K,V> hiHead = null, hiTail = null;
//高位低位的初始树节点个数都设成0
int lc = 0, hc = 0;
for (TreeNode<K,V> e = b, next; e != null; e = next) {
next = (TreeNode<K,V>)e.next;
e.next = null;
//bit=oldcap,这里判断新bit位是0还是1,如果是0就放在低位树上,如果是1就放在高位树上,这里先是一个双向链表
if ((e.hash & bit) == 0) {
if ((e.prev = loTail) == null)
loHead = e;
else
loTail.next = e;
loTail = e;
++lc;
}
else {
if ((e.prev = hiTail) == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
++hc;
}
}
if (loHead != null) {
if (lc <= UNTREEIFY_THRESHOLD)
//!!!如果低位的链表长度小于阈值6,则把树变成链表,并放到新数组中j索引位置
tab[index] = loHead.untreeify(map);
else {
tab[index] = loHead;
//高位不为空,进行红黑树转换
if (hiHead != null) // (else is already treeified)
loHead.treeify(tab);
}
}
if (hiHead != null) {
if (hc <= UNTREEIFY_THRESHOLD)
tab[index + bit] = hiHead.untreeify(map);
else {
tab[index + bit] = hiHead;
if (loHead != null)
hiHead.treeify(tab);
}
}
}
untreeify方法,将树转变为单向链表
/**
* 将树转变为单向链表
*/
final Node<K,V> untreeify(HashMap<K,V> map) {
Node<K,V> hd = null, tl = null;
for (Node<K,V> q = this; q != null; q = q.next) {
Node<K,V> p = map.replacementNode(q, null);
if (tl == null)
hd = p;
else
tl.next = p;
tl = p;
}
return hd;
}
treeify方法,将链表转换为红黑树,会根据红黑树特性进行颜色转换、左旋、右旋等
/**
* 链表转换为红黑树,会根据红黑树特性进行颜色转换、左旋、右旋等
*/
final void treeify(Node<K,V>[] tab) {
TreeNode<K,V> root = null;
for (TreeNode<K,V> x = this, next; x != null; x = next) {
next = (TreeNode<K,V>)x.next;
x.left = x.right = null;
if (root == null) {
x.parent = null;
x.red = false;
root = x;
}
else {
K k = x.key;
int h = x.hash;
Class<?> kc = null;
for (TreeNode<K,V> p = root;;) {
int dir, ph;
K pk = p.key;
if ((ph = p.hash) > h)
dir = -1;
else if (ph < h)
dir = 1;
else if ((kc == null &&
(kc = comparableClassFor(k)) == null) ||
(dir = compareComparables(kc, k, pk)) == 0)
dir = tieBreakOrder(k, pk);
TreeNode<K,V> xp = p;
if ((p = (dir <= 0) ? p.left : p.right) == null) {
x.parent = xp;
if (dir <= 0)
xp.left = x;
else
xp.right = x;
//进行左旋、右旋调整
root = balanceInsertion(root, x);
break;
}
}
}
}
moveRootToFront(tab, root);
}
jdk1.8在进行重新扩容之后,会重新计算hash值,因为n变为2倍,假设初始 tableSize = 4 要扩容到 8 来说就是 0100 到 1000 的变化(左移一位就是 2 倍),在扩容中只用判断原来的 hash 值与左移动的一位(newtable 的值)按位与操作是 0 或 1 就行,0 的话索引就不变,1 的话索引变成原索引 + oldCap;
其实现如下流程图所示:
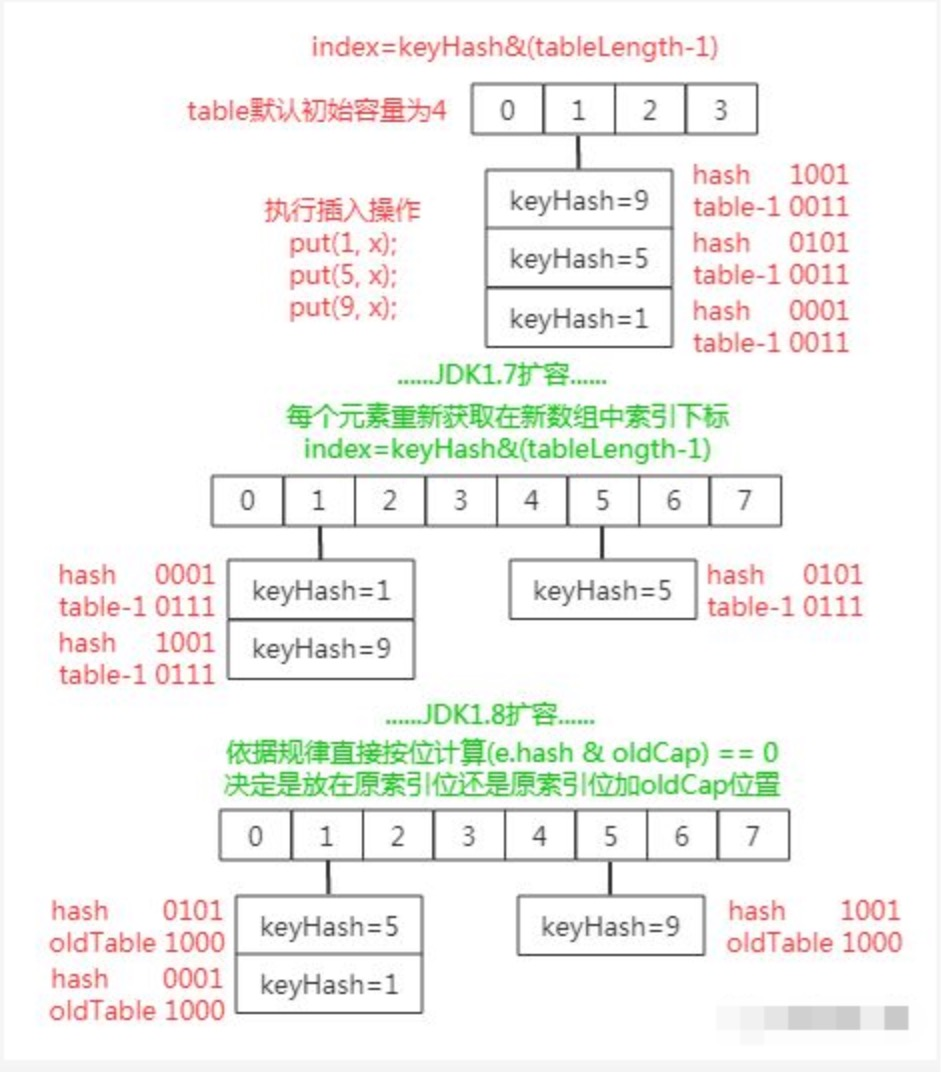
可以看见,因为 hash 值本来就是随机性的,所以 hash 按位与上 newTable 得到的 0(扩容前的索引位置)和 1(扩容前索引位置加上扩容前数组长度的数值索引处)就是随机的,所以扩容的过程就能把之前哈希冲突的元素再随机的分布到不同的索引去,这算是 JDK1.8 的一个优化点。
此外,JDK1.7中rehash的时候,旧链表迁移新链表的时候,如果在新表的数组索引位置相同,则链表元素会倒置,但是从上图可以看出,JDK1.8不会倒置。
同时,由于 JDK1.7 中发生哈希冲突时仅仅采用了链表结构存储冲突元素,所以扩容时仅仅是重新计算其存储位置而已。而 JDK1.8 中为了性能在同一索引处发生哈希冲突到一定程度时,链表结构会转换为红黑数结构存储冲突元素,故在扩容时如果当前索引中元素结构是红黑树且元素个数小于链表还原阈值时就会把树形结构缩小或直接还原为链表结构(其实现就是上面代码片段中的 split() 方法)。
3.4、get方法获取参数值
get(Object key)方法根据指定的key值返回对应的value,getNode(hash(key), key))得到相应的Node对象e,然后返回e.value。因此getNode()是算法的核心。
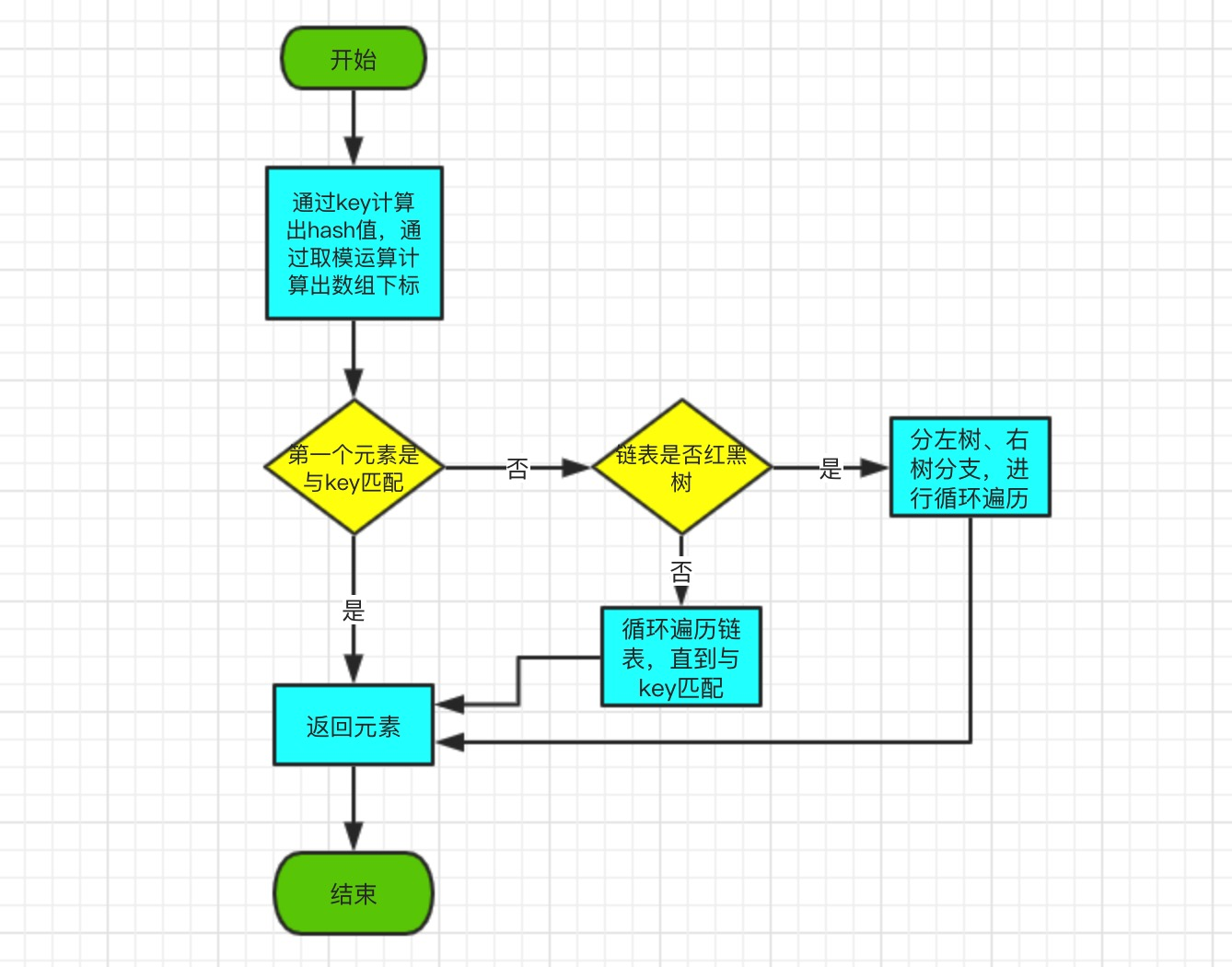
get方法源码部分:
/**
* JDK1.8 get方法
* 通过key获取参数值
*/
public V get(Object key) {
Node<K,V> e;
return (e = getNode(hash(key), key)) == null ? null : e.value;
}
通过hash值和key获取节点Node方法,源码部分:
final Node<K,V> getNode(int hash, Object key) {
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) {
//1、判断第一个元素是否与key匹配
if (first.hash == hash &&
((k = first.key) == key || (key != null && key.equals(k))))
return first;
if ((e = first.next) != null) {
//2、判断链表是否红黑树结构
if (first instanceof TreeNode)
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
//3、如果不是红黑树结构,直接循环判断
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null;
}
在红黑树中找到指定k的TreeNode,源码部分:
/**
* 这里面情况分很多中,主要是因为考虑了hash相同但是key值不同的情况,查找的最核心还是落在key值上
*/
final TreeNode<K,V> find(int h, Object k, Class<?> kc) {
TreeNode<K,V> p = this;
do {
int ph, dir; K pk;
TreeNode<K,V> pl = p.left, pr = p.right, q;
//判断要查询元素的hash是否在树的左边
if ((ph = p.hash) > h)
p = pl;
//判断要查询元素的hash是否在树的右边
else if (ph < h)
p = pr;
//查询元素的hash与当前树节点hash相同情况
else if ((pk = p.key) == k || (k != null && k.equals(pk)))
return p;
//上面的三步都是正常的在二叉查找树中寻找对象的方法
//如果hash相等,但是内容却不相等
else if (pl == null)
p = pr;
else if (pr == null)
p = pl;
//如果可以根据compareTo进行比较的话就根据compareTo进行比较
else if ((kc != null ||
(kc = comparableClassFor(k)) != null) &&
(dir = compareComparables(kc, k, pk)) != 0)
p = (dir < 0) ? pl : pr;
//根据compareTo的结果在右孩子上继续查询
else if ((q = pr.find(h, k, kc)) != null)
return q;
//根据compareTo的结果在左孩子上继续查询
else
p = pl;
} while (p != null);
return null;
}
get方法,首先通过hash()函数得到对应数组下标,然后依次判断。
- 1、判断第一个元素与key是否匹配,如果匹配就返回参数值;
- 2、判断链表是否红黑树,如果是红黑树,就进入红黑树方法获取参数值;
- 3、如果不是红黑树结构,直接循环判断,直到获取参数为止;
3.5、remove删除元素
remove(Object key)的作用是删除key值对应的Node,该方法的具体逻辑是在removeNode(hash(key), key, null, false, true)里实现的。
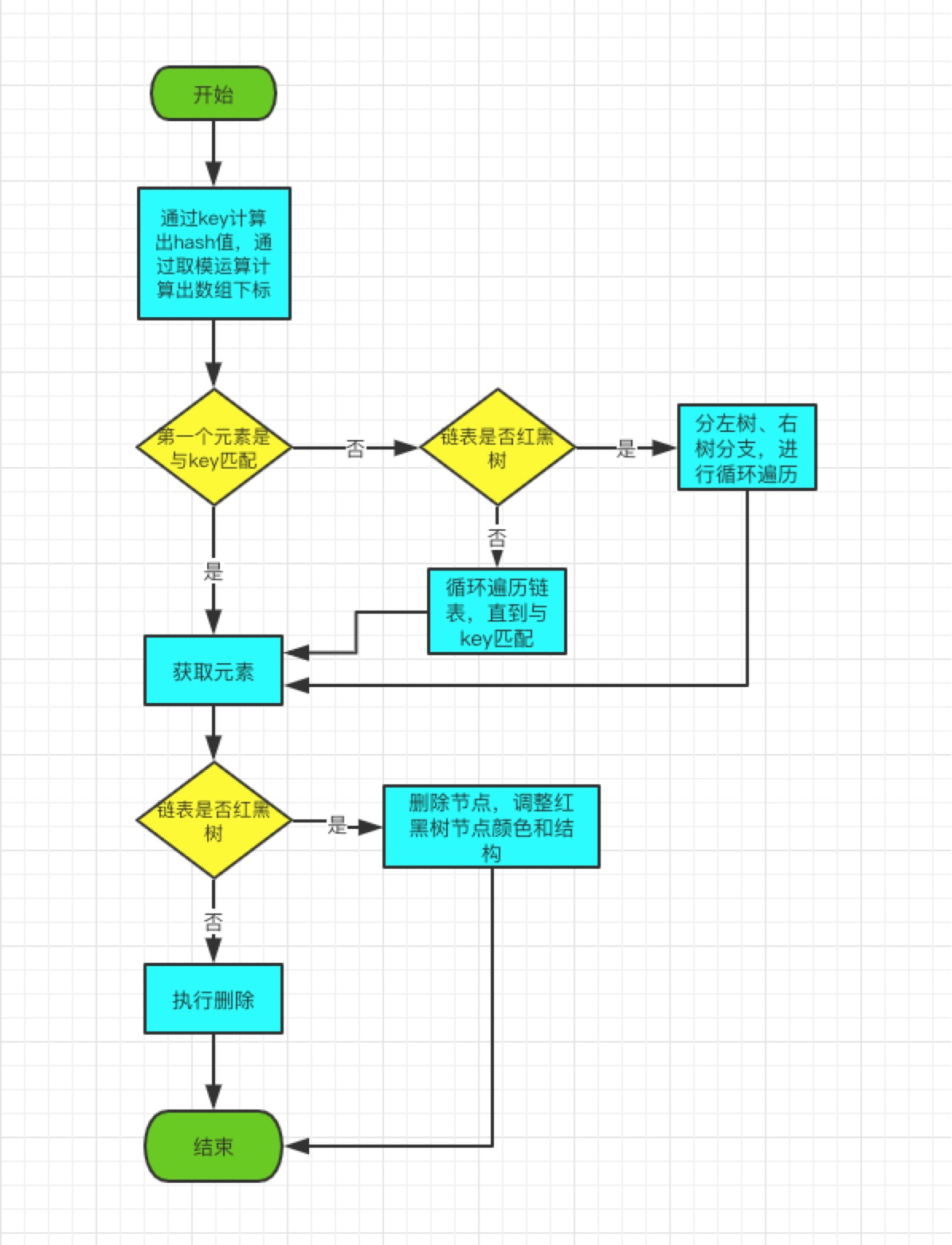
remove方法,源码部分:
/**
* JDK1.8 remove方法
* 通过key移除对象
*/
public V remove(Object key) {
Node<K,V> e;
return (e = removeNode(hash(key), key, null, false, true)) == null ?
null : e.value;
}
通过key移除Node节点方法,源码部分:
/**
* 通过key移除Node节点
*/
final Node<K,V> removeNode(int hash, Object key, Object value,
boolean matchValue, boolean movable) {
Node<K,V>[] tab; Node<K,V> p; int n, index;
//1、判断要删除的元素,是否存在
if ((tab = table) != null && (n = tab.length) > 0 &&
(p = tab[index = (n - 1) & hash]) != null) {
Node<K,V> node = null, e; K k; V v;
//2、判断第一个元素是不是我们要找的元素
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
node = p;
else if ((e = p.next) != null) {
//3、判断当前冲突链表是否红黑树结构
if (p instanceof TreeNode)
node = ((TreeNode<K,V>)p).getTreeNode(hash, key);
else {
//4、循环在链表中找到需要删除的元素
do {
if (e.hash == hash &&
((k = e.key) == key ||
(key != null && key.equals(k)))) {
node = e;
break;
}
p = e;
} while ((e = e.next) != null);
}
}
//上面的逻辑,基本都是为了找到要删除元素的节点
if (node != null && (!matchValue || (v = node.value) == value ||
(value != null && value.equals(v)))) {
//5、如果当前冲突链表结构是红黑树,执行红黑树删除方法
if (node instanceof TreeNode)
((TreeNode<K,V>)node).removeTreeNode(this, tab, movable);
else if (node == p)
tab[index] = node.next;
else
p.next = node.next;
++modCount;
--size;
afterNodeRemoval(node);
return node;
}
}
return null;
}
removeTreeNode移除红黑树节点方法,源码部分:
final void removeTreeNode(HashMap<K,V> map, Node<K,V>[] tab,
boolean movable) {
int n;
if (tab == null || (n = tab.length) == 0)
return;
int index = (n - 1) & hash;
TreeNode<K,V> first = (TreeNode<K,V>)tab[index], root = first, rl;
TreeNode<K,V> succ = (TreeNode<K,V>)next, pred = prev;
if (pred == null)
tab[index] = first = succ;
else
pred.next = succ;
if (succ != null)
succ.prev = pred;
if (first == null)
return;
if (root.parent != null)
root = root.root();
if (root == null || root.right == null ||
(rl = root.left) == null || rl.left == null) {
tab[index] = first.untreeify(map); // too small
return;
}
TreeNode<K,V> p = this, pl = left, pr = right, replacement;
if (pl != null && pr != null) {
TreeNode<K,V> s = pr, sl;
while ((sl = s.left) != null) // find successor
s = sl;
boolean c = s.red; s.red = p.red; p.red = c; // swap colors
TreeNode<K,V> sr = s.right;
TreeNode<K,V> pp = p.parent;
if (s == pr) { // p was s's direct parent
p.parent = s;
s.right = p;
}
else {
TreeNode<K,V> sp = s.parent;
if ((p.parent = sp) != null) {
if (s == sp.left)
sp.left = p;
else
sp.right = p;
}
if ((s.right = pr) != null)
pr.parent = s;
}
p.left = null;
if ((p.right = sr) != null)
sr.parent = p;
if ((s.left = pl) != null)
pl.parent = s;
if ((s.parent = pp) == null)
root = s;
else if (p == pp.left)
pp.left = s;
else
pp.right = s;
if (sr != null)
replacement = sr;
else
replacement = p;
}
else if (pl != null)
replacement = pl;
else if (pr != null)
replacement = pr;
else
replacement = p;
if (replacement != p) {
TreeNode<K,V> pp = replacement.parent = p.parent;
if (pp == null)
root = replacement;
else if (p == pp.left)
pp.left = replacement;
else
pp.right = replacement;
p.left = p.right = p.parent = null;
}
//判断是否需要进行红黑树结构调整
TreeNode<K,V> r = p.red ? root : balanceDeletion(root, replacement);
if (replacement == p) { // detach
TreeNode<K,V> pp = p.parent;
p.parent = null;
if (pp != null) {
if (p == pp.left)
pp.left = null;
else if (p == pp.right)
pp.right = null;
}
}
if (movable)
moveRootToFront(tab, r);
}
jdk1.8的删除逻辑实现比较复杂,相比jdk1.7而言,多了红黑树节点删除和调整:
- 1、默认判断链表第一个元素是否是要删除的元素;
- 2、如果第一个不是,就继续判断当前冲突链表是否是红黑树,如果是,就进入红黑树里面去找;
- 3、如果当前冲突链表不是红黑树,就直接在链表中循环判断,直到找到为止;
- 4、将找到的节点,删除掉,如果是红黑树结构,会进行颜色转换、左旋、右旋调整,直到满足红黑树特性为止;
四、总结
1、如果key是一个对象,记得在对象实体类里面,要重写equals和hashCode方法,不然在查询的时候,无法通过对象key来获取参数值!
2、相比JDK1.7,JDK1.8引入红黑树设计,当链表长度大于8的时候,链表会转化为红黑树结构,发生冲突的链表如果很长,红黑树的实现很大程度优化了HashMap的性能,使查询效率比JDK1.7要快一倍!
3、对于大数组的情况,可以提前给Map初始化一个容量,避免在插入的时候,频繁的扩容,因为扩容本身就比较消耗性能!
五、参考
1、JDK1.7&JDK1.8 源码
2、美团技术团队 - Java 8系列之重新认识HashMap
【集合系列】- 深入浅出分析HashMap的更多相关文章
- Java 集合系列10之 HashMap详细介绍(源码解析)和使用示例
概要 这一章,我们对HashMap进行学习.我们先对HashMap有个整体认识,然后再学习它的源码,最后再通过实例来学会使用HashMap.内容包括:第1部分 HashMap介绍第2部分 HashMa ...
- Java集合系列(四):HashMap、Hashtable、LinkedHashMap、TreeMap的使用方法及区别
本篇博客主要讲解Map接口的4个实现类HashMap.Hashtable.LinkedHashMap.TreeMap的使用方法以及三者之间的区别. 注意:本文中代码使用的JDK版本为1.8.0_191 ...
- java集合系列——Map之HashMap介绍(八)
1.HashMap的简介 (JDK1.7.0_79版本) HashMap是基于哈希表的Map实现的的,一个Key对应一个Value,允许使用null键和null值,不保证映射的顺序,特别是它不保证该顺 ...
- 【Java集合系列五】HashMap解析
2017-07-31 19:36:00 一.简介 1.HashMap作用及使用场景 HashMap利用数组+单向链表的方式,实现了key-value型数据的存储功能.HashMap的size永远是2^ ...
- 【转】Java 集合系列10之 HashMap详细介绍(源码解析)和使用示例
概要 这一章,我们对HashMap进行学习.我们先对HashMap有个整体认识,然后再学习它的源码,最后再通过实例来学会使用HashMap.内容包括:第1部分 HashMap介绍第2部分 HashMa ...
- 深入理解JAVA集合系列三:HashMap的死循环解读
由于在公司项目中偶尔会遇到HashMap死循环造成CPU100%,重启后问题消失,隔一段时间又会反复出现.今天在这里来仔细剖析下多线程情况下HashMap所带来的问题: 1.多线程put操作后,get ...
- 深入理解JAVA集合系列一:HashMap源码解读
初认HashMap 基于哈希表(即散列表)的Map接口的实现,此实现提供所有可选的映射操作,并允许使用null值和null键. HashMap继承于AbstractMap,实现了Map.Cloneab ...
- Java 集合系列14之 Map总结(HashMap, Hashtable, TreeMap, WeakHashMap等使用场景)
概要 学完了Map的全部内容,我们再回头开开Map的框架图. 本章内容包括:第1部分 Map概括第2部分 HashMap和Hashtable异同第3部分 HashMap和WeakHashMap异同 转 ...
- 深入java集合系列文章
搞懂java的相关集合实现原理,对技术上有很大的提高,网上有一系列文章对java中的集合做了深入的分析, 先转载记录下 深入Java集合学习系列 Java 集合系列目录(Category) HashM ...
随机推荐
- python购物车小案例
python购物车小案例# 案列描述:有一个小型水果店里面有水果(苹果:¥8/kg,香蕉:¥5/kg,芒果:¥15/kg,葡萄:¥12/kg),客户带了100元钱进店选购水果.# 1.客户输入相应序号 ...
- SSM简易版
技术准备 Java: 基础知识 框架: Spring,SpringMVC,Mybatis 数据库: Mysq 开发工具: Eclipse,Maven 项目结构 数据库设计 创建数据库:student ...
- 【已解决】ArcGIS Engine无法创建拓扑的问题(CreateTopology)
也许,你的问题是这样的 ①System.Runtime.InteropServices.COMException:"未找到拓扑." ②myTopology结果是null,程序跳转到 ...
- Linux性能分析
生产环境服务器变慢,诊断思路和性能评估 整机:top 代码 public class JavaDemo2 { public static void main(String[] args) { whil ...
- Java基础系列二:Java泛型
该系列博文会告诉你如何从入门到进阶,一步步地学习Java基础知识,并上手进行实战,接着了解每个Java知识点背后的实现原理,更完整地了解整个Java技术体系,形成自己的知识框架. 一.泛型概述 1.定 ...
- [考试反思]0917csp-s模拟测试45:天命
又倒一了. 关于心态,有不少想说的. 首先旁边坐了一个kx.他上来入手T1没多久就切了然后开始对拍拍了几十万组AC. 然而我觉得T1是神仙题.先进T2. 挺简单的,5分钟出正解,然后在打出来的时候突然 ...
- 深入了解 Java Resource && Spring Resource
在Java中,为了从相对路径读取文件,经常会使用的方法便是: xxx.class.getResource(); xxx.class.getClassLoader().getResource(); 在S ...
- Kubernetes5-集群上搭建基于redis和docker的留言薄
一.简介 1.环境依旧是kubernetes之前文章的架构 2.需要docker的镜像 1)php-forntend web 前端镜像 docker.io-kubeguide-guestbook-ph ...
- Pycharm创建项目时 自动添加头部信息
1.打开PyCharm,选择File--Settings 2.依次选择Editor---Code Style-- File and Code Templates---Python Script 3.. ...
- jquery手指触摸滑动放大图片的方法(比较靠谱的方法)
jquery手指触摸滑动放大图片的方法(比较靠谱的方法) <pre><!DOCTYPE html><html lang="zh-cn">< ...