文本查重算法SimHash
1.介绍
爬虫采集了大量的文本数据,如何进行去重?可以使用文本计算MD5,然后与已经抓取下来的MD5集合进行比较,但这种做法有个问题,文本稍有不同MD5值都会大相径庭,
无法处理文本相似问题。另一种方式是本文要介绍的SimHash,这是谷歌提出的一种局部敏感哈希算法,在吴军老师的《数学之美》里也有介绍,这种算法可以将文本降维成一个
数字,极大地减少了去重操作的计算量。SimHash算法主要分为以下几个步骤:
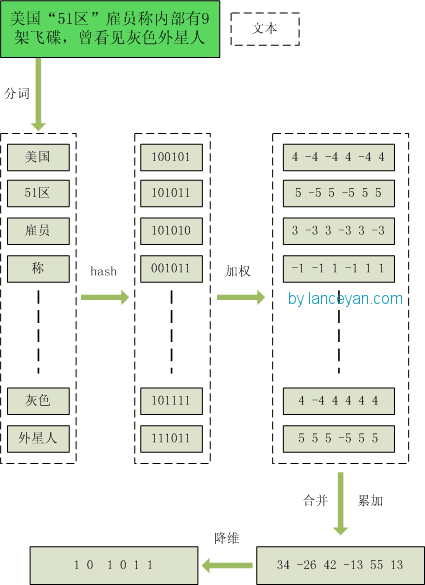
1.分词,并为每个词加上权重,代表这个词在这句话中的重要程度(可以考虑使用TF-IDF算法)
2.哈希,分好每个词映射为哈希值
3.加权,按照单词的权重形成加权数字串,比如“美国”的hash值为“100101”,通过加权计算为“4 -4 -4 4 -4 4”;“51区”的hash值为“101011”,通过加权计算为 “ 5 -5 5 -5 5 5”。
4.合并,把上面各个单词算出来的序列值累加,变成只有一个序列串
5.降维,如果序列串每一位大于0 记为 1,小于0 记为 0。最后算出结果为:“1 0 1 0 1 1”。
2.SimHash的比较
根据上面的步骤可以计算出每个文本的一个SimHash值,两个SimHash的相似度就是通过比较不同二者数位的个数,这叫做海明距离,比如10101 和 00110 ,海明距离
为3。
3.比较效率的提高
加入我们已经有了一个simhash库,现在有一个query过来需要查询是否库里存在与这个query海明距离为1到3的文本,如何查询?
方式1. 将这个query的海明距离为1到3的结果实时计算出来,然后依次在库里查找,缺点:海明距离为1到3的结果可能有上万个,逐个查询效率肯定很低。
方式2.将库里每个simhash海明距离为1到3的结果事先离线计算出来,这样每个查询只需要O(1)的复杂度。缺点:需要的存储空间非常大。
待续。。。。
文本查重算法SimHash的更多相关文章
- simhash进行文本查重 Simhash算法原理和网页查重应用
simhash进行文本查重http://blog.csdn.net/lgnlgn/article/details/6008498 Simhash算法原理和网页查重应用http://blog.jobbo ...
- python 手把手教你基于搜索引擎实现文章查重
前言 文章抄袭在互联网中普遍存在,很多博主都收受其烦.近几年随着互联网的发展,抄袭等不道德行为在互联网上愈演愈烈,甚至复制.黏贴后发布标原创屡见不鲜,部分抄袭后的文章甚至标记了一些联系方式从而使读者获 ...
- python简单实现论文查重(软工第一次项目作业)
前言 软件工程 https://edu.cnblogs.com/campus/gdgy/informationsecurity1812 作业要求 https://edu.cnblogs.com/cam ...
- .NET下文本相似度算法余弦定理和SimHash浅析及应用
余弦相似性 原理:首先我们先把两段文本分词,列出来所有单词,其次我们计算每个词语的词频,最后把词语转换为向量,这样我们就只需要计算两个向量的相似程度. 我们简单表述如下 文本1:我/爱/北京/ ...
- 【NLP】Python实例:基于文本相似度对申报项目进行查重设计
Python实例:申报项目查重系统设计与实现 作者:白宁超 2017年5月18日17:51:37 摘要:关于查重系统很多人并不陌生,无论本科还是硕博毕业都不可避免涉及论文查重问题,这也对学术不正之风起 ...
- 海量文件查重SimHash和Minhash
SimHash 事实上,传统比较两个文本相似性的方法,大多是将文本分词之后,转化为特征向量距离的度量,比如常见的欧氏距离.海明距离或者余弦角度等等.两两比较固然能很好地适应,但这种方法的一个最大的缺点 ...
- 【NLP】Python实例:申报项目查重系统设计与实现
Python实例:申报项目查重系统设计与实现 作者:白宁超 2017年5月18日17:51:37 摘要:关于查重系统很多人并不陌生,无论本科还是硕博毕业都不可避免涉及论文查重问题,这也对学术不正之风起 ...
- 数据结构与算法—simhash
引入 随着信息爆炸时代的来临,互联网上充斥着着大量的近重复信息,有效地识别它们是一个很有意义的课题. 例如,对于搜索引擎的爬虫系统来说,收录重复的网页是毫无意义的,只会造成存储和计算资源的浪费: 同时 ...
- 高效网页去重算法-SimHash
记得以前有人问过我,网页去重算法有哪些,我不假思索的说出了余弦向量相似度匹配,但如果是数十亿级别的网页去重呢?这下糟糕了,因为每两个网页都需要计算一次向量内积,查重效率太低了!我当时就想:论查找效率肯 ...
随机推荐
- 夯实Java基础系列9:深入理解Class类和Object类
目录 Java中Class类及用法 Class类原理 如何获得一个Class类对象 使用Class类的对象来生成目标类的实例 Object类 类构造器public Object(); register ...
- 快速入门和使用HTML–使用Django建立你的第一个网站
一 前记 你每天浏览的网页,通过网络看的新闻,看着淘宝京东的绚丽多彩的界面.是否想过这个问题,它是怎么实现的呢?有没有搜过相关的知识呢?假如没有,假如你是一位对事物好奇的主或者是做计算机相关东西的人. ...
- Scrapy入门操作
一.安装Scrapy: 如果您还未安装,请参考https://www.cnblogs.com/dalyday/p/9277212.html 二.Scrapy基本配置 1.创建Scrapy程序 cd D ...
- Redis 主从,哨兵,集群实战
下载地址及版本说明 Redis 各版本下载地址: http://download.redis.io/releases/ 版本说明:一般来说版本号第二位,偶数是稳定版本,奇数是在开发中的版本 本文基于R ...
- 【IT技术概念】WebAPI与传统的WebService有哪些不同?
在.net平台下,有大量的技术让你创建一个HTTP服务,像Web Service,WCF,现在又出了Web API.在.net平台下,你有很多的选择来构建一个HTTP Services.我分享一下我对 ...
- SUSE Ceph 快速部署 - Storage6
学习 SUSE Storage 系列文章 (1)SUSE Storage6 实验环境搭建详细步骤 - Win10 + VMware WorkStation (2)SUSE Linux Enterpri ...
- 一条SQL查询语句是如何执行的?
本篇文章将通过一条 SQL 的执行过程来介绍 MySQL 的基础架构. 首先有一个 user_info 表,表里有一个 id 字段,执行下面这条查询语句: select * from user_inf ...
- 谷歌助力,快速实现 Java 应用容器化
原文地址:梁桂钊的博客 博客地址:http://blog.720ui.com 欢迎关注公众号:「服务端思维」.一群同频者,一起成长,一起精进,打破认知的局限性. Google 在 2018 年下旬开源 ...
- (4)一起来看下mybatis框架的缓存原理吧
本文是作者原创,版权归作者所有.若要转载,请注明出处.本文只贴我觉得比较重要的源码,其他不重要非关键的就不贴了 我们知道.使用缓存可以更快的获取数据,避免频繁直接查询数据库,节省资源. MyBatis ...
- tesseract 测试样例
该图片的链接为https://raw.githubusercontent.com/Python3WebSpider/TestTess/master/image.png,可以直接保存或下载. 首先用命令 ...