带你从头到尾捋一遍MySQL索引结构(1)
前言
Hello我又来了,快年底了,作为一个有抱负的码农,我想给自己攒一个年终总结。索性这次把数据库中最核心的也是最难搞懂的内容,也就是索引,分享给大家。
这篇博客我会谈谈对于索引结构我自己的看法,以及分享如何从零开始一层一层向上最终理解索引结构。
从一个简单的表开始
create table user(
id int primary key,
age int,
height int,
weight int,
name varchar(32)
)engine = innoDb;
相信只要入门数据库的同学都可以理解这个语句,我们也将从这个最简单的表开始,一步步地理解MySQL的索引结构。
首先,我们往这个表中插入一些数据。
INSERT INTO user(id,age,height,weight,name)VALUES(2,1,2,7,'小吉');
INSERT INTO user(id,age,height,weight,name)VALUES(5,2,1,8,'小尼');
INSERT INTO user(id,age,height,weight,name)VALUES(1,4,3,1,'小泰');
INSERT INTO user(id,age,height,weight,name)VALUES(4,1,5,2,'小美');
INSERT INTO user(id,age,height,weight,name)VALUES(3,5,6,7,'小蔡');
我们来查一下,看看这些数据是否已经放入表中。
select * from user;
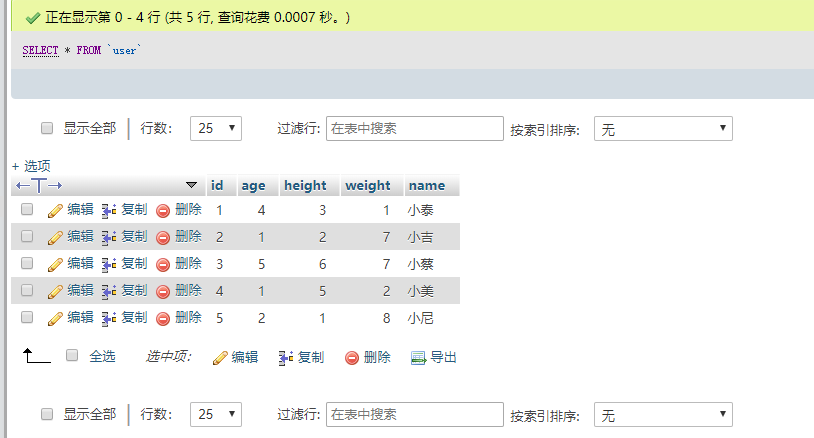
可以看到,数据已经完整地放到了我们创建的user表中。
但是不知道大家发现了什么没有,好像发生了一件非常诡异的事情,我们插入的数据好像乱序了…
MySQL好像悄悄的给我们按照id排了个序。
为什么会出现MySQL在我们没有显式排序的情况下,默默帮我们排了序呢?它是在什么时候进行排序的?
页的引入
不知道大家毕业多长时间了,作为一个刚复习完操作系统不久的学渣,页的概念依旧在脑中还没有变凉。其实MySQL中也有类似页的逻辑存储单位,听我慢慢道来。
在操作系统的概念中,当我们往磁盘中取数据,假设要取出的数据的大小是1KB,但是操作系统并不会只取出这1kb的数据,而是会取出4KB的数据,因为操作系统的一个页表项的大小是4KB。那为什么我们只需要1KB的数据,但是操作系统要取出4KB的数据呢?
这就涉及到一个程序局部性的概念,具体的概念我背不清了,大概就是“一个程序在访问了一条数据之后,在之后会有极大的可能再次访问这条数据和访问这条数据的相邻数据”,所以索性直接加载4KB的数据到内存中,下次要访问这一页的数据时,直接从内存中找,可以减少磁盘IO次数,我们知道,磁盘IO是影响程序性能主要的因素,因为磁盘IO和内存IO的速度是不可同日而语的。
或许看完上面那一大段描述,还是有些抽象,所以我们索性回到数据库层面中,重新理解页的概念。
抛开所有东西不谈,假设还是我们刚才插入的那些数据,我们现在要找id = 5的数据,依照最原始的方式,我们一定会想到的就是——遍历,没错,这也是我们刚开始学计算机的时候最常用的寻找数据的方式。那么我们就来看看,以遍历的方式,我们找到id=5的数据,需要经历几次磁盘IO。
首先,我们得先从id=1的数据开始读起,然后判断是否是我们需要的数据,如果不是,就再取id=2的数据,再进行判断,循环往复。毋庸置疑,在MySQL帮我们排好序之后,我们需要经历五次磁盘IO,才能将5号数据找到并读出来。
那么我们再来看看引入页的概念之后,我们是如何读数据的。
在引入页的概念之后,MySQL会将多条数据存在一个叫“页”的数据结构中,当MySQL读取id=1的数据时,会将id=1数据所在的页整页读到内存中,然后在内存中进行遍历判断,由于内存的IO速度比磁盘高很多,所以相对于磁盘IO,几乎可以忽略不计,那么我们来看看这样读取数据我们需要经历几次磁盘IO(假设每一页可以存4条数据)。
那么我们第一次会读取id=1的数据,并且将id=1到id=4的数据全部读到内存中,这是第一次磁盘IO,第二次将读取id=5的数据到内存中,这是第二次磁盘IO。所以我们只需要经历2次磁盘IO就可以找到id=5的这条数据。
但其实,在MySQL的InnoDb引擎中,页的大小是16KB,是操作系统的4倍,而int类型的数据是4个字节,其它类型的数据的字节数通常也在4000字节以内,所以一页是可以存放很多很多条数据的,而MySQL的数据正是以页为基本单位组合而成的。
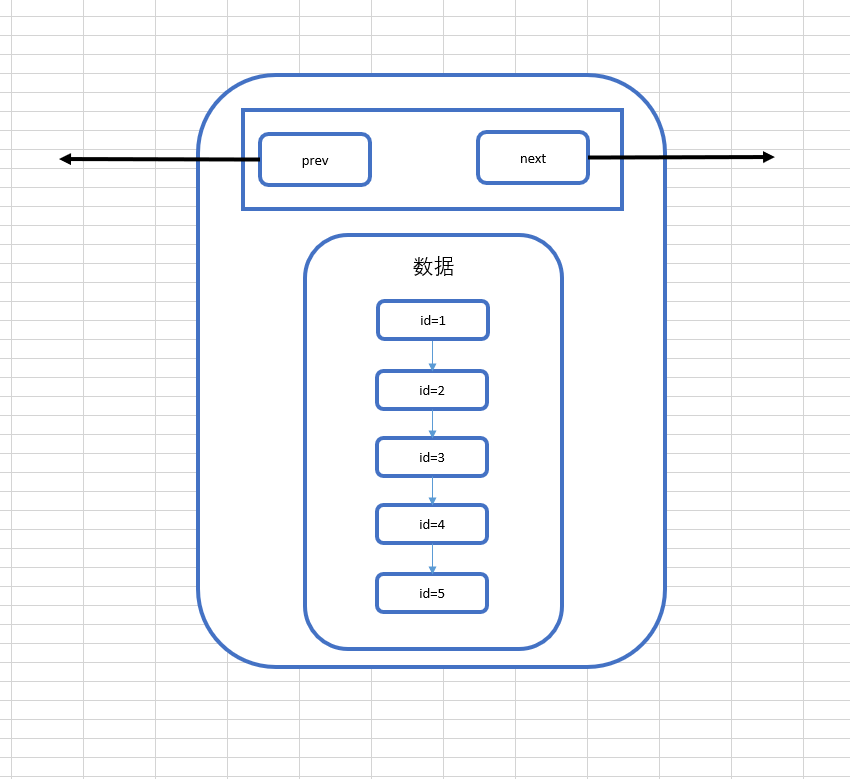
上图就是我们目前为止所理解的页的结构,他包含我们的多条数据,另外,MySQL的数据以页组成,那么它有指向下一页的指针和指向上一页的指针。
那么说到这里,其实可以回答第一个问题了,MySQL实际上就是在我们插入数据的时候,就帮我们在页中排好了序,至于为什么要排序,这里先卖个关子,接着往下看。
排序对性能的影响
上文中我们提了一个问题,为什么数据库在插入数据时要对其进行排序呢?我们按正常顺序插入数据不是也挺好的吗?
这就要涉及到一个数据库查询流程的问题了,无论如何,我们是绝对不会去平白无故地在插入数据时增加一个操作来让流程复杂化的,所以插入数据时排序一定有其目的,就是优化查询的效率。
而我们不难看出,页内部存放数据的模块,实质上就是一个链表的结构,链表的特点也就是增删快,查询慢,所以优化查询的效率是必须的。
基于单页模式存储的查询流程
还是基于我们第一节中的那张页图来谈,我们插入了五条数据,id分别是从1-5,那么假设我要找一个表中不存在的id,假设id=-1,那么现在的查询流程就是:
将id=1的这一整页数据取出,进行逐个比对,那么当我们找到id=1的这条数据时,发现这个id大于我们所需要找的哪个id,由于数据库在插入数据时,已经进行过排序了,那么在id=1的数据后面,都是id>1的数据,所以我们就不需要再继续往下寻找了。
如果在插入时没有进行排序,那毋庸置疑,我们需要再继续往下进行寻找,逐条查找直到到结尾也没有找到这条数据,才能返回不存在这条数据。
当然,这只是排序优化的冰山一角,接着往下看。
上述页模式可能带来的问题
说完了排序,下面就来分析一下我们在第一节中的那幅图,对于大数据量下有什么弊端,或者换一个说法,我们可以怎么对这个模式进行优化。
我们不难看出,在现阶段我们了解的页模式中,只有一个功能,就是在查询某条数据的时候直接将一整页的数据加载到内存中,以减少硬盘IO次数,从而提高性能。但是,我们也可以看到,现在的页模式内部,实际上是采用了链表的结构,前一条数据指向后一条数据,本质上还是通过数据的逐条比较来取出特定的数据。
那么假设,我们这一页中有一百万条数据,我们要查的数据正好在最后一个,那么我们是不是一定要从前往后找到这一条数据呢?如果是这样,我们需要查找的次数就达到了一百万次,即使是在内存中查找,这个效率也是不高的。那么有什么办法来优化这种情况下的查找效率呢?
页目录的引入
我们可以打个比方,我们在看书的时候,如果要找到某一节,而这一节我们并不知道在哪一页,我们是不是就要从前往后,一节一节地去寻找我们需要的内容的页码呢?答案是否定的,因为在书的前面,存在目录,它会告诉你这一节在哪一页,例如,第一节在第1页、第二节在第13页。在数据库的页中,实际上也使用了这种目录的结构,这就是页目录。
那么引入页目录之后,我们所理解的页结构,就变成了这样:
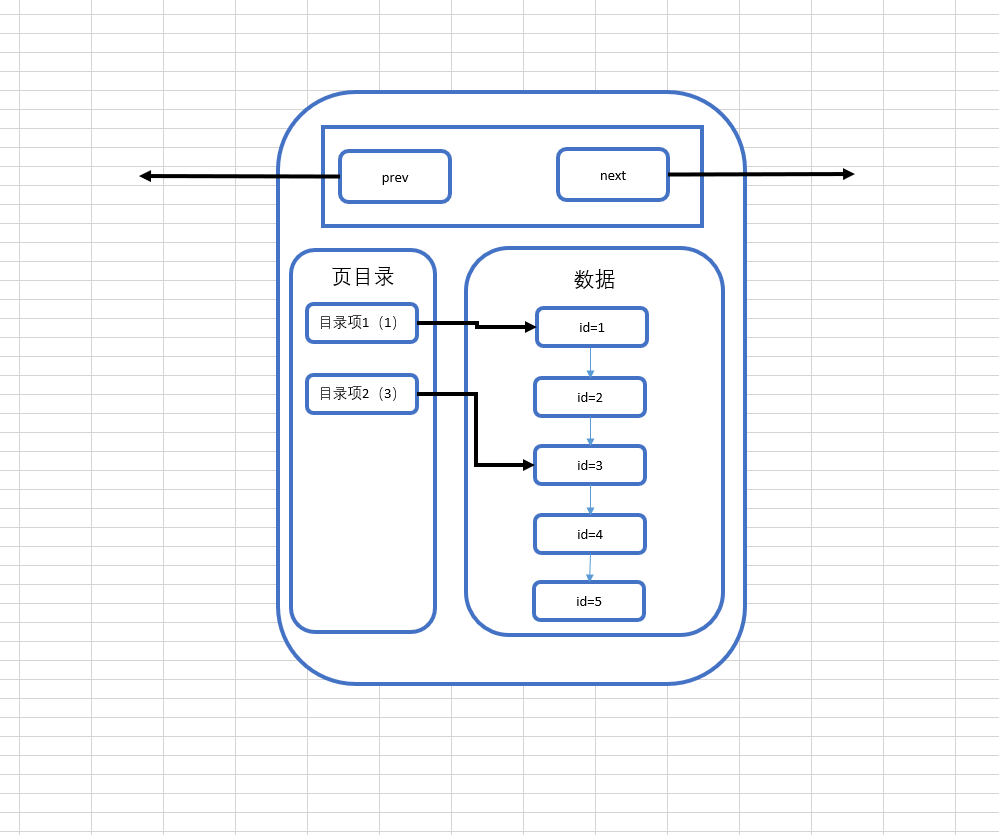
分析一下这张图,实际上页目录就像是我们在看书的时候书本的目录一样,目录项1就相当于第一节,目录项2就相当于第二节,而每一条数据就相当于书本的每一页,这张图就可以解释成,第一节从第一页开始,第二节从第三页开始,而实际上,每个目录项会存放自己这个目录项当中最小的id,也就是说,目录项1中会存放1,而目录项2会存放3。
那么对比一下数据库在没有页目录时候的查找流程,假设要查找id=3的数据,在没有页目录的情况下,需要查找id=1、id=2、id=3,三次才能找到该数据,而如果有页目录之后,只需要先查看一下id=3存在于哪个目录项下,然后直接通过目录项进行数据的查找即可,如果在该目录项下没有找到这条数据,那么就可以直接确定这条数据不存在,这样就大大提升了数据库的查找效率,但是这种页目录的实现,首先就需要基于数据是在已经进行过排序的的场景下,才可以发挥其作用,所以看到这里,大家应该明白第二个问题了,为什么数据库在插入时会进行排序,这才是真正发挥排序的作用的地方。
页的扩展
在上文中,我们基本上说明白了MySQL数据库中页的概念,以及它是如何基于页来减少磁盘IO次数的,以及排序是如何优化查询的效率的。
那么我们现在再来思考第三个问题:在开头说页的概念的时候,我们有说过,MySQL中每一页的大小只有16KB,不会随着数据的插入而自动扩容,所以这16KB不可能存下我们所有的数据,那么必定会有多个页来存储数据,那么在多页的情况下,MySQL中又是怎么组织这些页的呢?
针对这个问题,我们继续来画出我们现在所了解的多页的结构图:
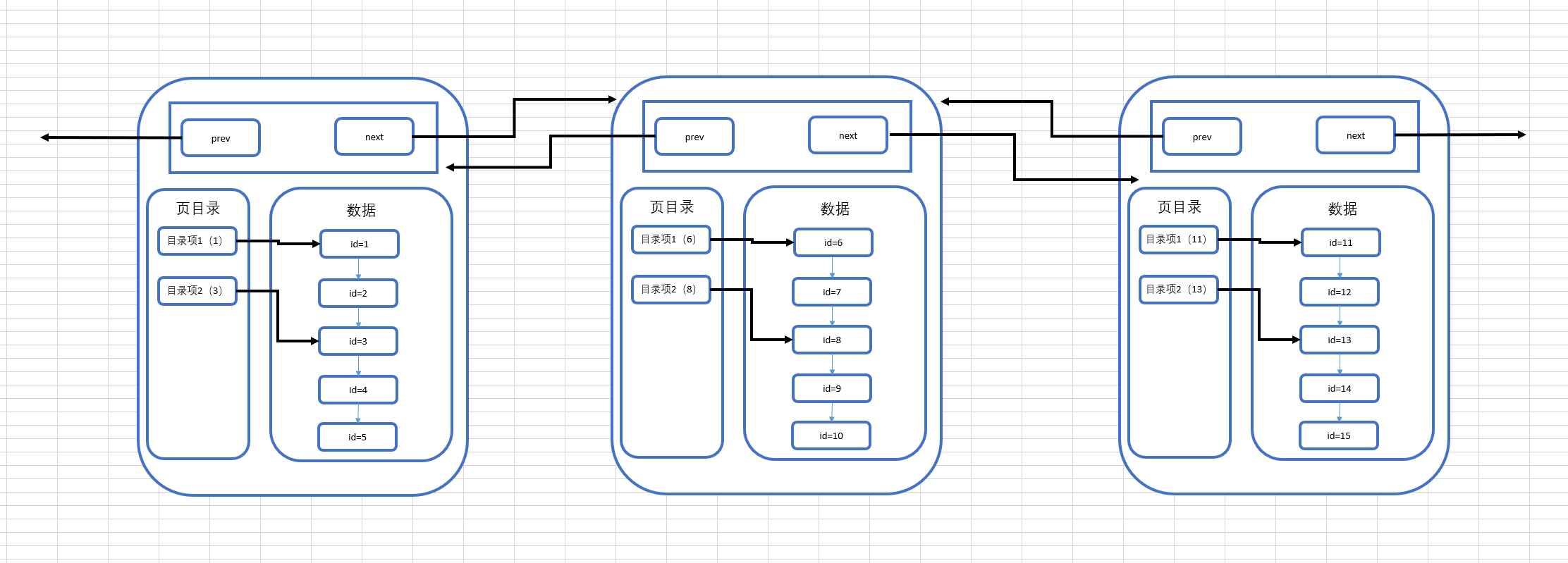
可以看到,在数据不断变多的情况下,MySQL会再去开辟新的页来存放新的数据,而每个页都有指向下一页的指针和指向上一页的指针,将所有页组织起来,第一页中存放id为1-5的数据,第二页存放id为6-10的数据,第三页存放id为11-15的数据,需要注意的是在开辟新页的时候,我们插入的数据不一定是放在新开辟的页上,而是要进行所有页的数据比较,来决定这条插入的数据放在哪一页上,而完成数据插入之后,最终的多页结构就会像上图中画的那样。
带你从头到尾捋一遍MySQL索引结构(1)的更多相关文章
- 索引很难么?带你从头到尾捋一遍MySQL索引结构,不信你学不会!
前言 Hello我又来了,快年底了,作为一个有抱负的码农,我想给自己攒一个年终总结.自上上篇写了手动搭建Redis集群和MySQL主从同步(非Docker)和上篇写了动手实现MySQL读写分离and故 ...
- 带你从头到尾捋一遍MySQL索引结构(2)
前言 Hello我又来了,快年底了,作为一个有抱负的码农,我想给自己攒一个年终总结.索性这次把数据库中最核心的也是最难搞懂的内容,也就是索引,分享给大家. 这篇博客我会谈谈对于索引结构我自己的看法,以 ...
- 带你从头到尾捋一遍MySQL索引结构
索性这次把数据库中最核心的也是最难搞懂的内容,也就是索引,分享给大家. 这篇博客我会谈谈对于索引结构我自己的看法,以及分享如何从零开始一层一层向上最终理解索引结构. 从一个简单的表开始 create ...
- MYSQL索引结构原理、性能分析与优化
[转]MYSQL索引结构原理.性能分析与优化 第一部分:基础知识 索引 官方介绍索引是帮助MySQL高效获取数据的数据结构.笔者理解索引相当于一本书的目录,通过目录就知道要的资料在哪里, 不用一页一页 ...
- Mysql索引结构及常见索引的区别
一.Mysql索引主要有两种结构:B+Tree索引和Hash索引 Hash索引 mysql中,只有Memory(Memory表只存在内存中,断电会消失,适用于临时表)存储引擎显示支持Hash索引,是M ...
- 【转】由浅入深探究mysql索引结构原理、性能分析与优化
摘要: 第一部分:基础知识 第二部分:MYISAM和INNODB索引结构 1.简单介绍B-tree B+ tree树 2.MyisAM索引结构 3.Annode索引结构 4.MyisAM索引与Inno ...
- B-/B+树 MySQL索引结构
索引 索引的简介 简单来说,索引是一种数据结构 其目的在于提高查询效率 可以简单理解为“排好序的快速查找结构” 一般来说,索引本身也很大,不可能全部存储在内存中,因此索引往往以索引文件的形式存储在中磁 ...
- MySQL 索引结构 hash 有序数组
MySQL 索引结构 hash 有序数组 除了最常见的树形索引结构,Hash索引也有它的独到之处. Hash算法 Hash本身是一种函数,又被称为散列函数. 它的思路很简单:将key放在数组里,用 ...
- 一天五道Java面试题----第七天(mysql索引结构,各自的优劣--------->事务的基本特性和隔离级别)
这里是参考B站上的大佬做的面试题笔记.大家也可以去看视频讲解!!! 文章目录 1 .mysql索引结构,各自的优劣 2 .索引的设计原则 3 .mysql锁的类型有哪些 4 .mysql执行计划怎么看 ...
随机推荐
- NOIP模拟26
把题解沽了好久了,今天还是不想写,我们靠的B卷其实挺水的,但是我就是想吐槽一下!咋还带题目里面放题解的?题里一点题解的线索都没有,但是玄机竟然在题目里! 我也是醉了,T1就是一个贪心,题目说贪婪,T2 ...
- mysql select自增变量(包括读取当前第几行)
mysql select自增变量(包括读取当前第几行) SET @rownum =0;select id,@rownum := @rownum +1 as i from ceshi order by ...
- Spark(一)—— 大数据处理入门
一.Spark介绍 Apache Spark is a fast and general-purpose cluster computing system. It provides high-leve ...
- thinkphp 比RBAC更好的权限认证方式(Auth类认证)
Auth 类已经在ThinkPHP代码仓库中存在很久了,但是因为一直没有出过它的教程, 很少人知道它, 它其实比RBAC更方便 . RBAC是按节点进行认证的,如果要控制比节点更细的权限就有点困难了, ...
- nyoj 23-取石子(一)(博弈)
23-取石子(一) 内存限制:64MB 时间限制:3000ms Special Judge: No accepted:20 submit:33 题目描述: 一天,TT在寝室闲着无聊,和同寝的人玩起了取 ...
- suseoj 1211: 子集和问题 (dfs)
1211: 子集和问题 时间限制: 1 Sec 内存限制: 128 MB提交: 2 解决: 2[提交][状态][讨论版][命题人:liyuansong] 题目描述 子集和问题的一个实例为<S ...
- 【并发编程】synchronized的使用场景和原理简介
1. synchronized使用 1.1 synchronized介绍 在多线程并发编程中synchronized一直是元老级角色,很多人都会称呼它为重量级锁.但是,随着Java SE 1.6对sy ...
- ubuntu 16.04源码编译和配置caffe详细教程 | Install and Configure Caffe on ubuntu 16.04
本文首发于个人博客https://kezunlin.me/post/b90033a9/,欢迎阅读! Install and Configure Caffe on ubuntu 16.04 Series ...
- ArcGIS 用QueryTask查询上限1000的问题
1.打开ArcGIS Server找到自己发布的服务,右键Service Properties,左侧点击Parameters,右侧有一个Maximum number of records return ...
- python--debug神器pysnooper
使用它你可以获得什么优势: (1)无需用print就可以获得变量的值: (2)以日志地形式进行保存,方便随时查看: (3)可以根据需要,设置调用函数的深度: (4)多个函数的日志,可以设置前缀进行标识 ...