TensorFlow笔记-可视化Tensorboard
可视化Tensorboard
•数据序列化-events文件
TensorBoard 通过读取 TensorFlow 的事件文件来运行
•tf.summary.FileWriter('/tmp/tensorflow/summary/test/',graph=
default_graph)
返回filewriter,写入事件文件到指定目录(最好用绝对路径),以提供给tensorboard使用
•开启
tensorboard --logdir=/tmp/tensorflow/summary/test/
一般浏览器打开为127.0.0.1:6006 或者 localhost:6006
注:修改程序后,再保存一遍会有新的事件文件,打开默认为最新
import tensorflow as tf
import os
# 防止警告
os.environ['TF_CPP_MIN_LOG_LEVEL'] = ''
input1 = tf.placeholder(tf.float32)
input2 = tf.placeholder(tf.float32)
output = tf.add(input1,input2)
with tf.Session() as sess:
print(sess.run([output],feed_dict={input1:10.0,input2:20.0}))
summary_writer = tf.summary.FileWriter('./tmp/summary/test/', graph=sess.graph)


Scalar merge
目的:观察模型的参数、损失值等变量值的变化
1、收集变量
•tf.summary.scalar(name=’’,tensor)收集对于损失函数和准确率等单值变量,name为变量的名字,tensor为值
•tf.summary.histogram(name=‘’,tensor)收集高维度的变量参数
•tf.summary.image(name=‘’,tensor) 收集输入的图片张量能显示图片
cross_entropy = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y_label, logits=y))
# 梯度下降
train_step = tf.train.GradientDescentOptimizer(0.5).minimize(cross_entropy)
# 比较真实标签
correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(y_label, 1))
# tf.cast(xx,tf.float32)改变tensor类型
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32)) tf.summary.scalar("loss",cross_entropy) tf.summary.scalar("accuracy", accuracy) tf.summary.histogram("W",W)
2、合并变量写入事件文件
•merged= tf.summary.merge_all()
•运行合并:summary= sess.run(merged),每次迭代都需运行
•添加:FileWriter.add_summary(summary,i),i表示第几次的值
merged = tf.summary.merge_all()
summary_writer = tf.summary.FileWriter(FLAGS.summary_dir, graph=sess.graph)
summary = sess.run(merged)
summary_writer.add_summary(summary,i)
来个复杂一点的:
import tensorflow as tf
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '' graph = tf.Graph()
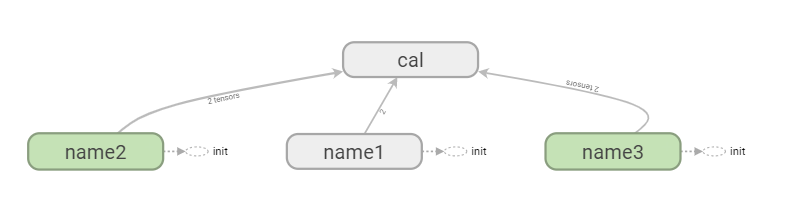
with graph.as_default():
with tf.name_scope("name1") as scope:
a = tf.Variable([1.0,2.0],name="a")
with tf.name_scope("name2") as scope:
b = tf.Variable(tf.zeros([20]),name="b")
c = tf.Variable(tf.ones([20]),name="c")
with tf.name_scope("name3") as scope:
a1 = tf.Variable(tf.constant(21.0), name="a1")
b1 = tf.Variable(tf.constant(13.0), name="b1")
with tf.name_scope("cal") as scope:
d = tf.concat([b,c],0)
e = tf.add(a,57)
c1 = tf.add(a1, b1) with tf.Session(graph=graph) as sess:
tf.global_variables_initializer().run()
# merged = tf.summary.merge_all()
summary_writer = tf.summary.FileWriter('./tmp/summary/test/', graph=sess.graph)
# print(sess.run([d, e, c1]))
TensorFlow笔记-可视化Tensorboard的更多相关文章
- tensorflow笔记(三)之 tensorboard的使用
tensorflow笔记(三)之 tensorboard的使用 版权声明:本文为博主原创文章,转载请指明转载地址 http://www.cnblogs.com/fydeblog/p/7429344.h ...
- tensorflow笔记:模型的保存与训练过程可视化
tensorflow笔记系列: (一) tensorflow笔记:流程,概念和简单代码注释 (二) tensorflow笔记:多层CNN代码分析 (三) tensorflow笔记:多层LSTM代码分析 ...
- Tensorflow 笔记 -- tensorboard 的使用
Tensorflow 笔记 -- tensorboard 的使用 TensorFlow提供非常方便的可视化命令Tensorboard,先上代码 import tensorflow as tf a = ...
- tensorflow笔记(一)之基础知识
tensorflow笔记(一)之基础知识 版权声明:本文为博主原创文章,转载请指明转载地址 http://www.cnblogs.com/fydeblog/p/7399701.html 前言 这篇no ...
- tensorflow笔记(二)之构造一个简单的神经网络
tensorflow笔记(二)之构造一个简单的神经网络 版权声明:本文为博主原创文章,转载请指明转载地址 http://www.cnblogs.com/fydeblog/p/7425200.html ...
- 学习笔记TF039:TensorBoard
首先向大家和<TensorFlow实战>的作者说句不好意思.我现在看的书是<TensorFlow实战>.但从TF024开始,我在学习笔记的参考资料里一直写的是<Tenso ...
- tensorflow笔记:使用tf来实现word2vec
(一) tensorflow笔记:流程,概念和简单代码注释 (二) tensorflow笔记:多层CNN代码分析 (三) tensorflow笔记:多层LSTM代码分析 (四) tensorflow笔 ...
- tensorflow笔记:多层LSTM代码分析
tensorflow笔记:多层LSTM代码分析 标签(空格分隔): tensorflow笔记 tensorflow笔记系列: (一) tensorflow笔记:流程,概念和简单代码注释 (二) ten ...
- TensorFlow笔记-08-过拟合,正则化,matplotlib 区分红蓝点
TensorFlow笔记-08-过拟合,正则化,matplotlib 区分红蓝点 首先提醒一下,第7讲的最后滑动平均的代码已经更新了,代码要比理论重要 今天是过拟合,和正则化,本篇后面可能或更有兴趣, ...
随机推荐
- HTTPS上线过程说明(阿里云提供免费证书)
一.上马HTTPS的原因: ①.苹果App Store强制其平台上的app均要使用HTTPS ②.网站经常被劫持,用户和领导希望使用HTTPS ③.跟随HTTPS的大趋势 二.应用上马HTTPS之部门 ...
- C++的 RTTI 观念和用途(非常详细)
自从1993年Bjarne Stroustrup [注1 ]提出有关C++ 的RTTI功能之建议﹐以及C++的异常处理(exception handling)需要RTTI:最近新推出的C++ 或多或少 ...
- 【产品】张小龙《微信背后的产品观》之PPT完整文字版
张小龙<微信背后的产品观>之PPT完整文字版 附:PPT下载地址:https://wenku.baidu.com/view/99d2910290c69ec3d5bb7573.html 微 ...
- 条款14:在资源管理类中小心copying行为
请牢记: 1.复制RAII对象必须一并复制它所管理的资源,所以资源的copying行为决定RAII对象的copying行为. 2.普遍常见的RAII class copying行为是:抑制copyin ...
- python网络爬虫(10)分布式爬虫爬取静态数据
目的意义 爬虫应该能够快速高效的完成数据爬取和分析任务.使用多个进程协同完成一个任务,提高了数据爬取的效率. 以百度百科的一条为起点,抓取百度百科2000左右词条数据. 说明 参阅模仿了:https: ...
- yii DAO操作总结
数据库代码: /* Navicat MySQL Data Transfer Source Server : lonxom Source Server Version : 50524 S ...
- shell遍历文件
取文件每行的数据,需要按列取 可以 sed 加管道 使用 awk 取列 platform="list.txt" line=`grep -vc '^$' $platform` ; ...
- Codeforces Gym100502A:Amanda Lounges(DFS染色)
http://codeforces.com/gym/100502/attachments 题意:有n个地点,m条边,每条边有一个边权,0代表两个顶点都染成白色,2代表两个顶点都染成黑色,1代表两个顶点 ...
- scrapy实战5 POST方法抓取ajax动态页面(以慕课网APP为例子):
在手机端打开慕课网,fiddler查看如图注意圈起来的位置 经过分析只有画线的page在变化 上代码: items.py import scrapy class ImoocItem(scrapy.It ...
- Char.Js 学习使用
<script src="../js/Chart.js"></script> <div " style="float:left;& ...