python 3.5学习笔记(第三章)
本章内容
1、集合及其运算
2、文件操作
3、字符编码与转码
4、函数与函数式编程
5、局部变量与全局变量
6、递归
7、补充知识点
一、集合及其运算
1、概念:
set集合是一个不重复元素集,用 { } 括起来,元素用 , 隔开,并且集合是无序的,无法通过下标进行索引
2、集合的创建
list_1 = [1,2,3,4,5,6,7,8]
set_1 = set(list_1)
set_2 = set([2,4,6,8,10])
print(set_1,set_2)
>>>{1, 2, 3, 4, 5, 6, 7, 8} {8, 2, 10, 4, 6}
3、求集合交集的两种方法
set_1 = {1,2,3,4,5,6,7,8}
set_2 = {2,4,6,8,10}
print(set_1.intersection(set_2))
print(set_1 & set_2)
>>>
{8, 2, 4, 6}
{8, 2, 4, 6}
4、求集合并集的两种方法
set_1 = {1,2,3,4,5,6,7,8}
set_2 = {2,4,6,8,10}
print(set_1.union(set_2))
print(set_1 | set_2)
>>>
{1, 2, 3, 4, 5, 6, 7, 8, 10}
{1, 2, 3, 4, 5, 6, 7, 8, 10}
5、求集合差集的两种方法
set_1 = {1,2,3,4,5,6,7,8}
set_2 = {2,4,6,8,10}
print(set_1.difference(set_2))
print(set_1 - set_2)
>>>
{1, 3, 5, 7}
{1, 3, 5, 7}
6、判断子集关系
set_1 = {1,2,3,4,5,6,7,8}
set_2 = {2,4,6,8,10}
set_3 = set([1,2,3,4,5,6])
print(set_1.issubset(set_2))
print(set_3.issubset(set_1))
>>>
False
True
7、判断父集关系
set_1 = {1,2,3,4,5,6,7,8}
set_2 = {2,4,6,8,10}
set_3 = {1,2,3,4,5,6}
print(set_1.issuperset(set_2))
print(set_1.issuperset(set_3))
>>>
False
True
8、对称差集
set_1 = {1,2,3,4,5,6,7,8}
set_2 = {2,4,6,8,10}
print(set_1.symmetric_difference(set_2))
print(set_1 ^ set_2)
>>>
{1, 3, 5, 7, 10}
{1, 3, 5, 7, 10}
9、判断是否没有交集,是则返回True
set_1 = {1,2,3,4,5,6,7,8}
set_2 = {2,4,6,8,10}
set_3 = {1,2,3,4,5,6}
print(set_1.isdisjoint(set_3))
>>>False
10、在集合中添加一个元素
set_1 = {1,2,3,4,5,6,7,8}
set_1.add(0)
print(set_1)
>>>{0, 1, 2, 3, 4, 5, 6, 7, 8}
11、在集合中添加多个元素
set_1 = {1,2,3,4,5,6,7,8}
set_1.update([9,10,11,12,13])
print(set_1)
>>>{1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13}
12、删除集合中的某一个指定元素,如果该元素不存在,则会报错
set_3 = {1,2,3,4,5,6}
print("set_3:",set_3)
set_3.remove(5)
print("set_3:",set_3)
>>>
set_3: {1, 2, 3, 4, 5, 6}
set_3: {1, 2, 3, 4, 6}
13、计算集合的长度
set_1 = {1,2,3,4,5,6,7,8}
print(len(set_1))
>>>8
14、测试某一个元素是否是该集合的成员
set_1 = {1,2,3,4,5,6,7,8}
print(5 in set_1)
print(5 not in set_1)
>>>
True
False
15、删除并返回任意一个元素
set_1 = {1,2,3,4,5,6,7,8}
print(set_1.pop())
>>>
16、删除一个指定的元素,如果不存在,不会报错
1 set_1 = {1,2,3,4,5,6,7,8}
2 set_1.discard(7)
3 print(set_1)
>>>{1, 2, 3, 4, 5, 6, 8}
二、文件操作
1、文件与文件路径
文件有两个关键属性:“文件名”和“路径”。
路径路径指明了文件在计算机上的位置,包括“绝对路径”和“相对路径”。
1.1 windows上的倒斜杠和Mac os、Linux上的正斜杠
在Windows上,路径书写使用倒斜杠作为文件夹之间的分隔符,但是在Mac os和Linux上使用正斜杠作为文件夹之间的分隔符,如果想要在所有的系统上使用程序,就要考虑这两种情况。
可以使用os.path.join()函数来将文件和路径上的文件夹名字连起来,函数会返回一个文件路径的字符串,包含正确的路径分隔符。
import os
print(os.path.join('user','test.txt'))
>>>
user\test.txt
1.2 当前工作目录
利用os.getcwd()函数可以获取当前工作路径的字符串,并且通过os.chdir()来改变它。
import os
a = os.getcwd()
print(a)
os.chdir("E:")
b = os.getcwd()
print(b)
>>>
C:\Users\pc\Desktop
E:\
1.3 绝对路径和相对路径
绝对路径总是从根文件夹开始。
相对路径是相对于程序的当前工作目录。
对于点(.)和点点(..)文件夹,是用在路径中的特殊名称,“点”用作文件夹名称时表示“当前目录”,“点点”用作文件夹名称时表示父文件夹。
1.4 用os.makedirs()创建新文件夹
import os
os.makedirs(r'E:\test')
1.5 os.path模块
os.path模块中包含了许多与文件名和文件路径相关的函数,比如前面使用的os.path.join()。使用os.path模块的时候,只要导入os模块即可。
1.6 处理绝对路径和相对路径
1.6.1 调用os.path.abspath(path)将返回参数的绝对路径的字符串 【将相对路径转换为绝对路径的简单方法】
1.6.2 调用os.path.isabs(path),判断参数是否为一个绝对路径,如果是返回True。
1.6.3 调用os.path.relpath(path, start)将返回从start路径到path的相对路径的字符串。如果没有设置start,就默认选择当前工作目录为开始路径。
1.6.4 调用os.path.dirname(path)将返回一个字符串,它包含path参数中最后一个斜杠之前的所有内容。
1.6.5 调用os.path.basename(path)将返回一个字符串,它包含path参数中最后一个斜杠之后的所有内容。基本名和文件名一致。
1.6.6 如果同时需要一个路径的目录名称和基本名称,可以调用os.path.split(),获取这两个名字的元组形式。
import os
print(os.path.split(r'E:\computer_code'))
>>>
('E:\\', 'computer_code')
1.7 查看文件大小和文件夹内容
1.7.1 调用os.path.getsize(path)将返回path参数中文件的字节数。
1.7.2 调用os.listdir(path)将返回文件名字符串的列表,包含path参数中的每一个文件。
import os
print(os.listdir(r'E:'))
>>>
['Tools', 'Soft']
1.8 检查路径有效性
1.8.1 调用os.path.exists(path),如果参数path所指的文件夹或文件存在,则返回True。
1.8.2 调用os.path.isfile(path),如果path存在,且是一个文件,则返回True。
1.8.3 调用os.apth.isdir(path),如果path存在,且是一个文件夹,则返回True。
2、文件读写
2.1 打开并读取文件
data = open("my_file","r",encoding="utf-8").read()
#encoding="utf-8" 用于告诉程序该文件的编码格式
print(data)
如果想要在之后对打开的文件进行下一步操作,最好把这个文件的内存对象赋给一个变量,然后通过这个变量来读取文件的内容,比如:
f = open("my_file","r",encoding="utf-8")
data_1 = f.read()
注意:同一个文件在不能同时读取两次,因为第一次读完后,光标被移动到了文件的末尾,如果此时想再次读取文件中的内容,就要把光标移动到前面,这个方法后面会提到。
2.2 写入文件
f = open("my_file","w",encoding="utf-8")
data = f.write("只写模式实际上是创建一个新的文件来覆盖原文件,并在新文件中写入")
print(data)
2.3 在文件末尾追加内容
f = open("my_file","a",encoding="utf-8")
data = f.write("追加模式直接在文件末尾写入内容,当文件不存在的时候会创建新文件")
2.4 按行读取文件中的内容
f = open ("my_file","r",encoding="utf-8")
print(f.readline())
print(f.readline())
print(f.readline())
#读取前三行的内容
示例:
利用for 循环和 if 判断读取文件中的每一行,但是跳过第3行
f = open ("my_file","r",encoding="utf-8")
for index, line in enumerate(f.readlines()):
if index == 3 :
print("------------")
continue
print(line.strip())#.strip()方法用于去除多余的空格
上述问题还可以通过迭代器实现,以减少对内存的使用
f = open ("my_file","r",encoding="utf-8")
count = 0
for line in f :
if count == 3 :
count += 1
continue
print(line.strip())
count += 1
2.5 tell():返回程序读取了多少个字符
f = open("my_file","r",encoding = "utf-8")
print(f.read())
print(f.tell())
2.6 seek():将光标移动到指定位置,以解决程序无法同时读取两次文件内容的问题
f = open("my_file","r",encoding = "utf-8")
print(f.read())
f.seek(0)
print("--------------")
print(f.read())
2.7 encoding :返回文件的编码格式
f = open("my_file2","r",encoding = "utf-8")
print(f.encoding)
2.8 name :返回文件名
f = open("my_file","r",encoding = "utf-8")
print(f.name)
2.9 seekable():判断文件是否可以移动光标
f = open("my_file2","r",encoding = "utf-8")
print(f.seekable())
2.10 readable():文件是否可读
f = open("my_file2","r",encoding = "utf-8")
print(f.readable())
2.11 writeable():文件是否可写
f = open("my_file2","r",encoding = "utf-8")
print(f.writable())
2.12 flush():每执行一次循环就强制将结果写入硬盘,而不是等待缓存结束一次性写入硬盘
import sys, time
for i in range(20):
sys.stdout.write(">")#这种写法不会换行
sys.stdout.flush()
time.sleep(0.1)
2.13 closed :判断文件是否关闭
f = open("my_file2","r",encoding = "utf-8")
print(f.closed)
2.14 truncate(): 清空文件
f = open("my_file2","w",encoding = "utf-8")
f.truncate()
2.15 文件读写: r+ (打开原文件进行操作,不会覆盖先前的文件)
f = open("my_file","r+",encoding = "utf-8")
print(f.readable())
print(f.writable())
2.16 文件写读: w+ (先创建一个文件,再进行操作,会覆盖先前的文件)
f = open("my_file2","w+",encoding = "utf-8")
print(f.readable())
print(f.writable())
2.17 追加读写: a+
f = open("my_file2","a+",encoding = "utf-8")
print(f.readable())
print(f.writable())
2.18 以二进制模式读文件
f = open("my_file2","rb")
print(f.readable())
print(f.writable())
2.19 以二进制模式写入(不是写入二进制内容)
f = open("my_file2","wb")
print(f.readable())
print(f.writable())
f.write(b"")
f.write("你好,世界".encode())#当要写入字符串的时候,要进行转码
2.20 文件修改
文件修改有两种方法:
(1)加载到内存中修改,然后存入文件中 ; (2)修改完写入新的文件中 。
下面利用方法(2)修改文件中的指定内容。
思路:一行一行读,边读边写入另一个新文件中,当找到目标时,将内容修改后写入新文件 。
f_1 = open ("my_file","r",encoding= "utf-8")
f_2 = open ("my_file3","w",encoding= "utf-8")
for line in f_1:
if "你的美一缕飘散" in line:
line = line.replace("你的美一缕飘散","你的美永远不散")
f_2.write(line)
f_1.close()
f_2.close()
2.21 with语句
为了避免文件打开后忘记关闭,可以使用with语句在代码执行完后自动关闭文件
with open ("my_file","r") as f:
pass
print(f.closed)
#同时打开多个文件
with open ("my_file","r") as obj1, \
open ("my_file2","r") as obj2:
pass
三、字符编码与转码
以下部分内容引用自:http://www.cnblogs.com/luotianshuai/articles/5735051.html
如有侵权,联系删除。
1、常见编码:
(1)gb2312:
https://baike.baidu.com/item/%E4%BF%A1%E6%81%AF%E4%BA%A4%E6%8D%A2%E7%94%A8%E6%B1%89%E5%AD%97%E7%BC%96%E7%A0%81%E5%AD%97%E7%AC%A6%E9%9B%86?fromtitle=GB2312&fromid=483170
(2)gb18030:
https://baike.baidu.com/item/gb18030/3204518?fr=aladdin
(3)GBK:
https://baike.baidu.com/item/GBK%E5%AD%97%E5%BA%93?fromtitle=GBK&fromid=481954
(4)ASCII:
https://baike.baidu.com/item/ASCII
(5)unicode:
https://baike.baidu.com/item/Unicode
(6)utf-8:
https://baike.baidu.com/item/UTF-8
2、utf-8 、unicode 和 gbk 之间的互相转换
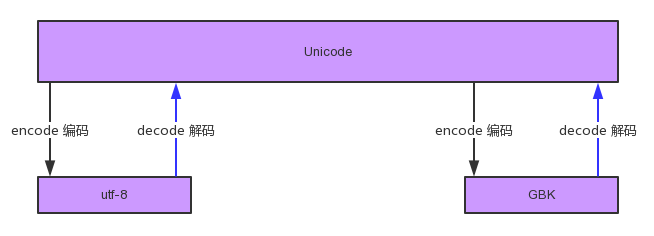
GBK转换为utf-8的流程:
(1)首先通过decode解码成unicode
(2)再由unicode编码encode成utf-8
3、总结:
(1)所有字符集之间的转换都要经过unicode
(2)GBK和unicode之间必须进行转换后才可以打印对应的内容,而utf-8 和 unicode之间可以不转换直接打印
(3)decode()要告诉机器原来的编码是什么,因为所有的decode都是解码成unicode,而encode()要告诉机器目标编码是什么,因为所有的encode都是从unicode来的
(4)python中的默认数据类型是unicode,与文件编码无关(开头的注释表示文件编码)
(5)python3中的encode不仅转换了编码,还将内容转换成了bytes类型
4、补充:
python中查看默认编码格式的方法
import sys
print(sys.getdefaultencoding())
四、函数与函数式编程
1、函数概念:
(1)数学中的概念:给定一个数集A,假设其中的元素为x。现对A中的元素x施加对应法则f,记作f(x),得到另一数集B。假设B中的元素为y。则y与x之间的等量关系可以用y=f(x)表示。我们把这个关系式就叫函数关系式,简称函数。
(2)python中的概念:函数是组织好的,可重复使用的,用来实现单一,或相关联功能的代码段。函数是逻辑结构化和过程化的一种编程方法
2、函数的定义:
def test():
print("in the test")
return 0
用def来定义一个函数。
注意:函数要有返回值,而过程实际上是一个返回值为None的函数。
3、函数的调用:
test()
4、函数的优势:
(1)代码重用:同一个函数可不断的被调用
(2)保持一致性:修改函数中的内容,就可以使每一各调用该函数的地方都跟着改变
(3)可扩展性 :函数可以根据需要进一步扩展
5、函数中return的作用是:结束函数并返回值(return后面的程序不会再执行),返回值可以是一个,也可以是多个内容
def test1():
print("in the test1")
def test2():
print("in the test2")
return 0
def test3():
print("in the test3")
return {"name":"Mr"},["MR","Python"],1
x = test1()
y = test2()
z = test3()
print(x,"\n",y,"\n",z)
>>>
in the test1
in the test2
in the test3
None
0
({'name': 'Mr'}, ['MR', 'Python'], 1)
总结:
(1)返回值个数=0 :返回None
(2)返回值个数=1 :返回object
(3)返回值个数>1 :返回tuple
6、函数参数:
(1)形参:全称为“形式参数”是在定义函数名和函数体的时候使用的参数,目的是用来接收调用该函数时传递的参数。
(2)实参:实参,actual parameters,全称为"实际参数"是在调用时传递给函数的参数,即传递给被调用函数的值。实参可以是常量、变量、表达式、函数等,无论实参是何种类型的量,在进行函数调用时,它们都必须具有确定的值,以便把这些值传送给形参。
(3)位置参数:调用函数时根据函数定义的参数位置来传递参数。
def func1(x,y):
print("a=",x*2)
print("b=",y*2)
func1(2,1)
>>>
a= 4
b= 2
(4)关键字参数:用在函数调用中,通过“键-值”形式加以指定,不需要考虑参数顺序的问题。
def func1(x,y):
print("a=",x*2)
print("b=",y*2)
func1(x=2,y=1)
>>>
a= 4
b= 2
注意:形参和实参必须一一对应,并且关键字参数不能写在位置参数前面
(5)默认参数:默认参数用在定义函数时给函数提供默认值,在调用该函数时,对于默认参数可以传值也可以不传值,但是不管是函数的定义还是调用,所有的位置参数都要放在默认参数前面。
def test(x,y=2):
print(x)
print(y) test(1)
test(1,y=3)
>>>
1
2
1
3
(6)可变参数:在定义函数的时候,有时候不确定在调用的时候需要多少个参数,这个时候就可以通过可变参数来实现参数的扩展
第一种: *args
def test(*args): #变量名随意,主要是以*开头来表示参数组
print(args) test(1,2,3,4,5)
test(*[1,2,3,4,5]) # *args = *[1,2,3,4,5] 传入5个参数
test([1,2,3,4,5]) # *args = [1,2,3,4,5] 传入1个参数(列表)
>>>
(1, 2, 3, 4, 5)
(1, 2, 3, 4, 5)
([1, 2, 3, 4, 5],) #注意打印的结果里面有一个逗号,表示这是一个tuple
*args接受N个参数,传入的实参会被放入元组中一起传递给形参args
第二种:**kwargs
def test2(**kwargs):
print(kwargs)
print(kwargs["name"])
print(kwargs["age"]) test2(name = 'MR', age = 18)
test2(**{"name":"Mr","age":""})
>>>
{'name': 'MR', 'age': 18}
MR
18
{'name': 'Mr', 'age': '18'}
Mr
18
**kwargs 把N个 关键字 参数转换成字典的方式
(7)关键字参数和可变参数组混合使用
def test3(name,**kwargs):
print(name)
print(kwargs) test3("mr",xxx="yyy")
>>>
mr
{'xxx': 'yyy'}
7、函数式编程:
函数式编程是一种“编程范式”,也就是如何编写程序的方法论,主要思想是把运算过程尽量写成一系列嵌套的函数调用。 函数式编程的一个特点是:允许把函数本身作为参数传入另一个函数中,还允许返回一个函数!
python对于函数式编程提供部分支持,但是由于python允许使用变量,所以python不是纯粹的函数式编程语言。
8、高阶函数:
变量可以指向函数,函数的参数能接收变量,那么一个函数就可以接收另一个函数作为参数,这种函数就称为高阶函数
def add(x,y,f):
return f(x) + f(y) res = add(3,-6,abs)
print(res)
>>>9
五、局部变量与全局变量
1、局部变量:在函数中定义的变量,它的作用域只在该函数中,在函数外是无法调用的。
2、全局变量:在程序的顶层定义的变量就是全局变量,其作用域为整个程序。
注意:
(1)如果要在函数中定义(修改)全局变量,就要在函数中先声明这个变量是一个全局变量,但是不建议这样做。
global 变量名
(2)只有字符串或者整数这种全局变量不能在函数中修改,而像列表、字典等是可以在函数中修改的。
name = ["MR","ZX","五千"]
def change():
name[1] = "CY"
print(name) change()
print(name)
>>>
['MR', 'CY', '五千']
['MR', 'CY', '五千']
#可以看到列表已经彻底改变了
(3)当全局变量与局部变量重名时,在定义局部变量的子程序内,局部变量起作用,在其他地方全局变量起作用。
六、递归
1、概念:
在函数内部,可以调用其他函数,如果一个函数调用它自己,那么这个函数就叫做递归函数。
2、特性:
(1)必须有一个明确的结束条件,否则就会进入死循环。
(2)每一次进入更深一层递归时,问题的规模就会比上一次递归都应该有所减少
(3)递归的效率不高,递归层次过多会导致栈溢出。
3、实现斐波那契数列
(1)迭代法
def factorial(n):
result = n
for i in range(1,n):
result *= i
return result number = int (input("请输入一个整数:"))
result = factorial(number)
print("%d的阶乘是:%d" % (number,result))
(2)递归法
def factorial(n):
if n==1:
return 1
else:
return n * factorial(n-1) number = int (input("请输入一个整数:"))
result = factorial(number)
print("%d的阶乘是:%d" % (number,result))
七、补充知识点
1、在程序中添加当前的时间
import time
time_format = "%Y-%m-%d %X"
time_current = time.strftime(time_format)
print (time_current)
python 3.5学习笔记(第三章)的更多相关文章
- 《DOM Scripting》学习笔记-——第三章 DOM
<Dom Scripting>学习笔记 第三章 DOM 本章内容: 1.节点的概念. 2.四个DOM方法:getElementById, getElementsByTagName, get ...
- The Road to learn React书籍学习笔记(第三章)
The Road to learn React书籍学习笔记(第三章) 代码详情 声明周期方法 通过之前的学习,可以了解到ES6 类组件中的生命周期方法 constructor() 和 render() ...
- [HeadFrist-HTMLCSS学习笔记]第三章构建模块:Web页面建设
[HeadFrist-HTMLCSS学习笔记]第三章构建模块:Web页面建设 敲黑板!! <q>元素添加短引用,<blockquote>添加长引用 在段落里添加引用就使用< ...
- JVM学习笔记-第三章-垃圾收集器与内存分配策略
JVM学习笔记-第三章-垃圾收集器与内存分配策略 tips:对于3.4之前的章节可见博客:https://blog.csdn.net/sanhewuyang/article/details/95380 ...
- python学习笔记——第三章 串
第三章 字符串学习 1.字符串不灵活, 它不能被分割符值 >>> format = "hello, %s. %s enough for ya?" >> ...
- Python基础教程学习笔记:第一章 基础知识
Python基础教程 第二版 学习笔记 1.python的每一个语句的后面可以添加分号也可以不添加分号:在一行有多条语句的时候,必须使用分号加以区分 2.查看Python版本号,在Dos窗口中输入“p ...
- JavaScript高级编程学习笔记(第三章之一)
继续记笔记,JavaScript越来越有意思了. 继续... 第三章:JavaScript基础 ECMAScript语法在很大程度上借鉴了C和其它类似于C的语言,比如Java和Perl. 大小写敏感: ...
- [HeadFirst-JSPServlet学习笔记][第三章:实战MVC]
第三章 实战MVC J2EE如何集成一切 Java2企业版(Java 2 Enterprise Editon,J2EE)是一种超级规范.规定了servlets2.4,JSP2.0,EJB2.1(Ent ...
- c#高级编程第七版 学习笔记 第三章 对象和类型
第三章 对象和类型 本章的内容: 类和结构的区别 类成员 按值和按引用传送参数 方法重载 构造函数和静态构造函数 只读字段 部分类 静态类 Object类,其他类型都从该类派生而来 3.1 类和结构 ...
- o'Reill的SVG精髓(第二版)学习笔记——第三章
第三章:坐标系统 3.1视口 文档打算使用的画布区域称作视口.我们可以在<svg>元素上使用width和height属性确定视口的大小.属性的值可以是一个数字,该数字会被当作用户坐标下的像 ...
随机推荐
- Android零基础入门第11节:简单几步带你飞,运行Android Studio工程
原文:Android零基础入门第11节:简单几步带你飞,运行Android Studio工程 之前讲过Eclipse环境下的Android虚拟设备的创建和使用,现在既然升级了Android Studi ...
- 【转载】动态载入DLL所需要的三个函数详解(LoadLibrary,GetProcAddress,FreeLibrary)
原文地址:https://www.cnblogs.com/westsoft/p/5936092.html 动态载入 DLL 动态载入方式是指在编译之前并不知道将会调用哪些 DLL 函数, 完全是在运行 ...
- 浅析 C++ 调用 Python 模块
浅析 C++ 调用 Python 模块 作为一种胶水语言,Python 能够很容易地调用 C . C++ 等语言,也能够通过其他语言调用 Python 的模块. Python 提供了 C++ 库,使得 ...
- list 多行表头 表头合并
http://blog.csdn.net/safedebug/article/details/52971685
- 利用POi3.8导出excel产生大量xml临时文件怎么办?
在实际项目中,经常会用到POI3.8来导出excel.而导出excel的时候,会因为残留大量以.xml结尾的文件而导致服务器存储空间急剧增长,最后导致系统挂了.为此,该怎么办呢? .xml后缀残留文件 ...
- 最全java多线程学习总结1--线程基础
<java 核心技术>这本书真的不错,知识点很全面,翻译质量也还不错,本系列博文是对该书中并发章节的一个总结. 什么是线程 官方解释:线程是操作系统能够进行运算调度的最小单位,包含 ...
- 如何使用VS Code编写Spring Boot (第二弹)
本篇文章是续<如何使用VS Code编写Spring Boot> 之后,结合自己.net经验捣鼓的小demo,一个简单的CRUD,对于习惯了VS操作模式的.net人员非常方便,强大的智能提 ...
- python 之 面向对象基础(定义类、创建对象,名称空间)
第七章面向对象 1.面向过程编程 核心是"过程"二字,过程指的是解决问题的步骤,即先干什么再干什么 基于该思想编写程序就好比在编写一条流水线,是一种机械式的思维方式 优点:复杂的问 ...
- if while 条件语句练习题
1.使用while循环输入123456 8910 n = 1 while n < 11 if n == 7 pass else print(n) n= n + 1 2.求1-100内所有数的和. ...
- Shell学习笔记1》转载自runnoob
无论是shell 还是bat,都是与操作系统结合非常紧密的东西,所以在此占坑,希望有朝一日能够把这些东西融会贯通,于是在此占坑~ 学习地址:http://www.runoob.com/linux/li ...