Spark学习之路(七)—— 基于ZooKeeper搭建Spark高可用集群
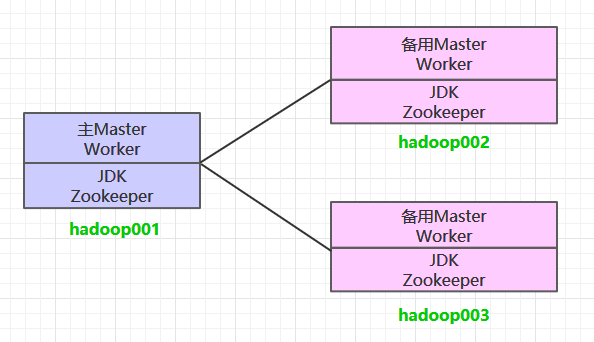
一、集群规划
这里搭建一个3节点的Spark集群,其中三台主机上均部署Worker服务。同时为了保证高可用,除了在hadoop001上部署主Master服务外,还在hadoop002和hadoop003上分别部署备用的Master服务,Master服务由Zookeeper集群进行协调管理,如果主Master不可用,则备用Master会成为新的主Master。
二、前置条件
搭建Spark集群前,需要保证JDK环境、Zookeeper集群和Hadoop集群已经搭建,相关步骤可以参阅:
三、Spark集群搭建
3.1 下载解压
下载所需版本的Spark,官网下载地址:http://spark.apache.org/downloads.html
下载后进行解压:
# tar -zxvf spark-2.2.3-bin-hadoop2.6.tgz
3.2 配置环境变量
# vim /etc/profile
添加环境变量:
export SPARK_HOME=/usr/app/spark-2.2.3-bin-hadoop2.6
export PATH=${SPARK_HOME}/bin:$PATH
使得配置的环境变量立即生效:
# source /etc/profile
3.3 集群配置
进入${SPARK_HOME}/conf目录,拷贝配置样本进行修改:
1. spark-env.sh
cp spark-env.sh.template spark-env.sh
# 配置JDK安装位置
JAVA_HOME=/usr/java/jdk1.8.0_201
# 配置hadoop配置文件的位置
HADOOP_CONF_DIR=/usr/app/hadoop-2.6.0-cdh5.15.2/etc/hadoop
# 配置zookeeper地址
SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=hadoop001:2181,hadoop002:2181,hadoop003:2181 -Dspark.deploy.zookeeper.dir=/spark"
2. slaves
cp slaves.template slaves
配置所有Woker节点的位置:
hadoop001
hadoop002
hadoop003
3.4 安装包分发
将Spark的安装包分发到其他服务器,分发后建议在这两台服务器上也配置一下Spark的环境变量。
scp -r /usr/app/spark-2.4.0-bin-hadoop2.6/ hadoop002:usr/app/
scp -r /usr/app/spark-2.4.0-bin-hadoop2.6/ hadoop003:usr/app/
四、启动集群
4.1 启动ZooKeeper集群
分别到三台服务器上启动ZooKeeper服务:
zkServer.sh start
4.2 启动Hadoop集群
# 启动dfs服务
start-dfs.sh
# 启动yarn服务
start-yarn.sh
4.3 启动Spark集群
进入hadoop001的${SPARK_HOME}/sbin目录下,执行下面命令启动集群。执行命令后,会在hadoop001上启动Maser服务,会在slaves配置文件中配置的所有节点上启动Worker服务。
start-all.sh
分别在hadoop002和hadoop003上执行下面的命令,启动备用的Master服务:
# ${SPARK_HOME}/sbin 下执行
start-master.sh
4.4 查看服务
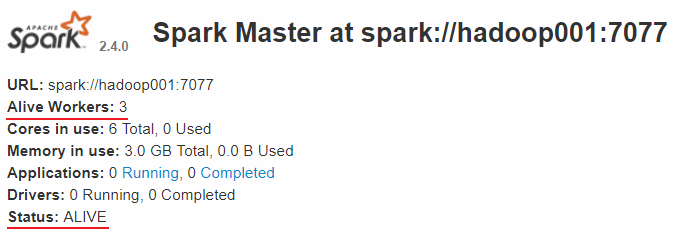
查看Spark的Web-UI页面,端口为8080。此时可以看到hadoop001上的Master节点处于ALIVE状态,并有3个可用的Worker节点。
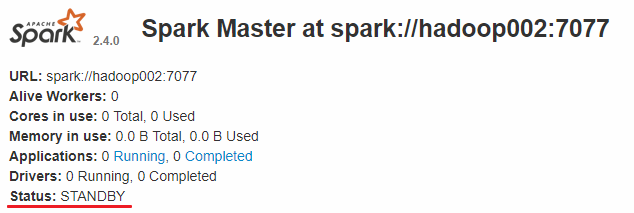
而hadoop002和hadoop003上的Master节点均处于STANDBY状态,没有可用的Worker节点。
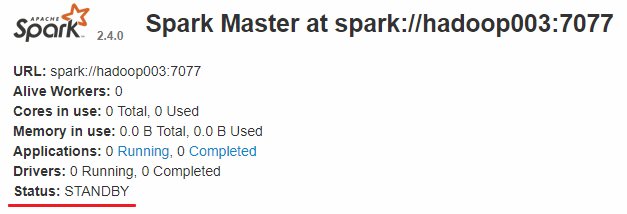
五、验证集群高可用
此时可以使用kill命令杀死hadoop001上的Master进程,此时备用Master会中会有一个再次成为主Master,我这里是hadoop002,可以看到hadoop2上的Master经过RECOVERING后成为了新的主Master,并且获得了全部可以用的Workers。
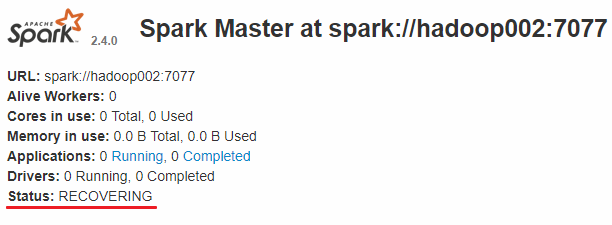
Hadoop002上的Master成为主Master,并获得了全部可以用的Workers。
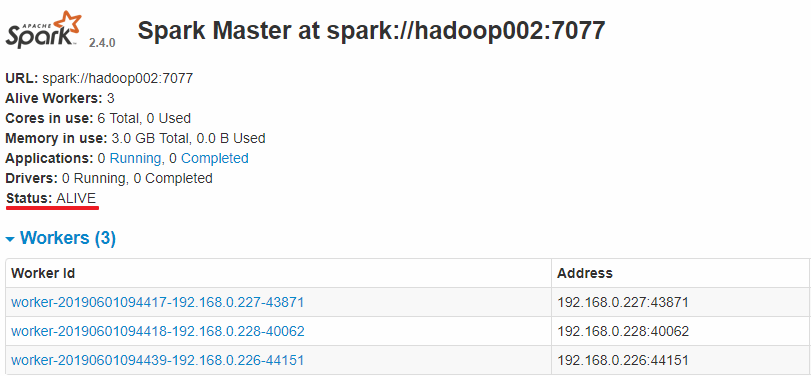
此时如果你再在hadoop001上使用start-master.sh启动Master服务,那么其会作为备用Master存在。
六、提交作业
和单机环境下的提交到Yarn上的命令完全一致,这里以Spark内置的计算Pi的样例程序为例,提交命令如下:
spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode client \
--executor-memory 1G \
--num-executors 10 \
/usr/app/spark-2.4.0-bin-hadoop2.6/examples/jars/spark-examples_2.11-2.4.0.jar \
100
更多大数据系列文章可以参见个人 GitHub 开源项目: 程序员大数据入门指南
Spark学习之路(七)—— 基于ZooKeeper搭建Spark高可用集群的更多相关文章
- Hadoop 学习之路(八)—— 基于ZooKeeper搭建Hadoop高可用集群
一.高可用简介 Hadoop 高可用 (High Availability) 分为 HDFS 高可用和 YARN 高可用,两者的实现基本类似,但 HDFS NameNode 对数据存储及其一致性的要求 ...
- Kafka 学习之路(二)—— 基于ZooKeeper搭建Kafka高可用集群
一.Zookeeper集群搭建 为保证集群高可用,Zookeeper集群的节点数最好是奇数,最少有三个节点,所以这里搭建一个三个节点的集群. 1.1 下载 & 解压 下载对应版本Zookeep ...
- 基于 ZooKeeper 搭建 Hadoop 高可用集群
一.高可用简介 二.集群规划 三.前置条件 四.集群配置 五.启动集群 六.查看集群 七.集群的二次启动 一.高可用简介 Hadoop 高可用 (High Availability) 分为 HDFS ...
- Hadoop 系列(八)—— 基于 ZooKeeper 搭建 Hadoop 高可用集群
一.高可用简介 Hadoop 高可用 (High Availability) 分为 HDFS 高可用和 YARN 高可用,两者的实现基本类似,但 HDFS NameNode 对数据存储及其一致性的要求 ...
- Kafka —— 基于 ZooKeeper 搭建 Kafka 高可用集群
一.Zookeeper集群搭建 为保证集群高可用,Zookeeper集群的节点数最好是奇数,最少有三个节点,所以这里搭建一个三个节点的集群. 1.1 下载 & 解压 下载对应版本Zookeep ...
- Kafka 系列(二)—— 基于 ZooKeeper 搭建 Kafka 高可用集群
一.Zookeeper集群搭建 为保证集群高可用,Zookeeper 集群的节点数最好是奇数,最少有三个节点,所以这里搭建一个三个节点的集群. 1.1 下载 & 解压 下载对应版本 Zooke ...
- 入门大数据---基于Zookeeper搭建Kafka高可用集群
一.Zookeeper集群搭建 为保证集群高可用,Zookeeper 集群的节点数最好是奇数,最少有三个节点,所以这里搭建一个三个节点的集群. 1.1 下载 & 解压 下载对应版本 Zooke ...
- 基于keepalived搭建MySQL高可用集群
MySQL的高可用方案一般有如下几种: keepalived+双主,MHA,MMM,Heartbeat+DRBD,PXC,Galera Cluster 比较常用的是keepalived+双主,MHA和 ...
- 基于Docker-compose搭建Redis高可用集群-哨兵模式(Redis-Sentinel)
原文转载自「刘悦的技术博客」https://v3u.cn/a_id_110 我们知道,Redis的集群方案大致有三种:1)redis cluster集群方案:2)master/slave主从方案:3) ...
- 基于docker实现redis高可用集群
基于docker实现redis高可用集群 yls 2019-9-20 简介 基于docker和docker-compose 使用redis集群和sentinel集群,达到redis高可用,为缓存做铺垫 ...
随机推荐
- Scala & IntelliJ IDEA:环境搭建、helloworld
--------------------- 前言 --------------------- 项目关系,希望用Spark GraphX做数据分析及图像展示,但前提是得回spark:spark是基于 ...
- IOC学习1
学习蒋金楠的 ASP.NET Core中的依赖注入(1):控制反转(IoC) 而来,这篇文章经典异常.一定要多读.反复读. 这篇文章举了一个例子,就是所谓的mvc框架,一开始介绍mvc的思想,由一个d ...
- 王立平--android这四个组成部分
Android中称为四大组件的为别为:Activity/Service/BroadCast Recevicer/Content provider Activity:activity是用户和应用程序交 ...
- if-then和if-then-else声明
1.使用if-then声明 结构化命令,主要类型为if-then声明.if-then例如,下面的语句格式: if command then commands fi 假设你在使用其它编程语言的if-th ...
- python_简单的DB统计
import numpy as npimport pylab as pldates=['20170314','20170315','20170316','20170317','20170318','2 ...
- Java Swing编程接口(30)---列表框:JList
列表框同时可以在信息呈现给用户的列表多个选项,使用JList能够建立一个列表框. package com.beyole.util; import java.awt.Container; import ...
- 【值转换器】 WPF中Image数据绑定Icon对象
原文:[值转换器] WPF中Image数据绑定Icon对象 这是原来的代码: <Image Source="{Binding MenuIcon}" ...
- WCF SOAP用法
基本思路 1.新建一个WCF服务库2.在客户端引用处右键,添加服务引用 点击发现,选择目标服务设置好命名空间 可以在高级一栏里面,设置详细信息 点击确认,添加服务引用 3.在客户端自动生成 ...
- github中README.md文件写法解析,git指令速查表
http://blog.csdn.net/u012234115/article/details/41778701 http://blog.csdn.net/u012234115/article/det ...
- 基于IOCP的高速文件传输代码
//服务端: const //transmit用的参数 TF_USE_KERNEL_APC = $20; //命令类型 CMD_CapScreen = ...