不懂数据库索引的底层原理?那是因为你心里没点b树
本文在个人技术博客不同步发布,详情可用力戳
亦可扫描屏幕右侧二维码关注个人公众号,公众号内有个人联系方式,等你来撩...
前几天下班回到家后正在处理一个白天没解决的bug,厕所突然传来对象的声音:
对象:xx,你有《时间简史》吗?
我:我去!妹子,你这啥癖好啊,我有时间也不会去捡屎啊!
对象:...人家说的是霍金的科普著作《时间简史》,是一本书啦!
我:哦,那我没有...
对象:人家想看诶,你明天帮我去图书馆借一本吧...
我:我明天还要改...
对象:你是不是不爱我了,分手!
我:我一大早就去~
第二天一大早我就到了图书馆,刚进门就看到一个索引牌,标识着不同楼层的功能,这样我很快能定位到我要找的目标所在的楼层了。

我到楼上后又看到每排的书架上又对书的分类进行了细分,这样我能更快的定位到我要找的书具体在哪个书架!
并且每个楼层都有一台查询终端,输入书名就能查到对应的唯一标识“索书号”,类似于P159-49/164这样的一个编码,书架上的书都是按照这个编码进行排序的!有了这个编码再去对应的书架上,很快就能找到对应的书在书架的具体位置了。

不到十分钟,我就从图书馆借好书出来了。
这么大的图书馆,我为什么能在这么短的时间内找到我要的书?如果这些书是杂乱无章的堆放,或者没有任何标识的放在书架,我还能这么快的找到吗?
这不禁让我想到了我们开发中用到的数据库,图书馆的书就类似我们数据表中的数据,楼层索引牌、书架分类标识、索书号就类似我们查找数据的索引。
那我们常用的数据库的索引底层的一个数据结构是什么样的呢?想到这里我又回到图书馆借了一本《数据库从入门到放弃》!
要了解数据库索引的底层原理,我们就得先了解一种叫树的数据结构,而树中很经典的一种数据结构就是二叉树!所以下面我们就从二叉树到平衡二叉树,再到B-树,最后到B+树来一步一步了解数据库索引底层的原理!
二叉树(Binary Search Trees)
二叉树是每个结点最多有两个子树的树结构。通常子树被称作“左子树”(left subtree)和“右子树”(right subtree)。二叉树常被用于实现二叉查找树和二叉堆。二叉树有如下特性:
1、每个结点都包含一个元素以及n个子树,这里0≤n≤2。
2、左子树和右子树是有顺序的,次序不能任意颠倒。左子树的值要小于父结点,右子树的值要大于父结点。
光看概念有点枯燥,假设我们现在有这样一组数[35 27 48 12 29 38 55],顺序的插入到一个数的结构中,步骤如下

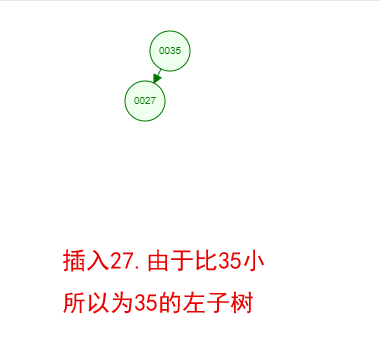
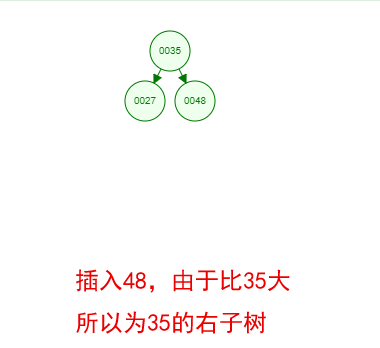
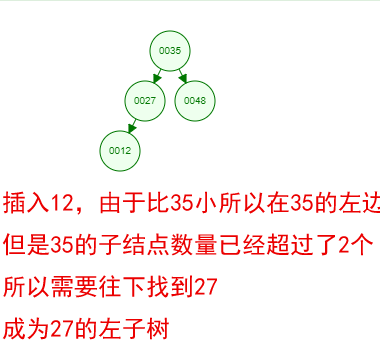
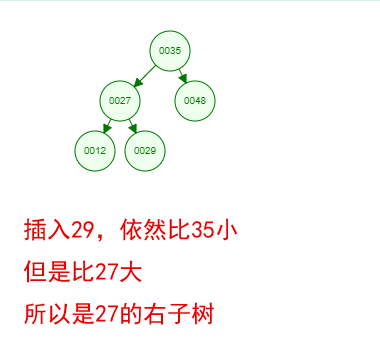
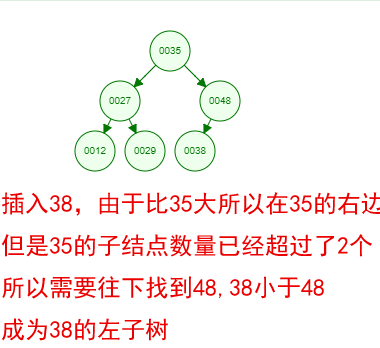
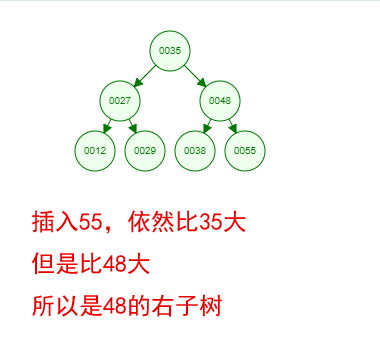
好了,这就是一棵二叉树啦!我们能看到,经通过一系列的插入操作之后,原本无序的一组数已经变成一个有序的结构了,并且这个树满足了上面提到的两个二叉树的特性!
但是如果同样是上面那一组数,我们自己升序排列后再插入,也就是说按照[12 27 29 35 38 48 55]的顺序插入,会怎么样呢?
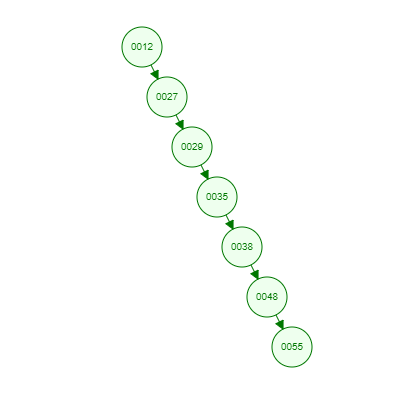
由于是升序插入,新插入的数据总是比已存在的结点数据都要大,所以每次都会往结点的右边插入,最终导致这棵树严重偏科!!!上图就是最坏的情况,也就是一棵树退化为一个线性链表了,这样查找效率自然就低了,完全没有发挥树的优势了呢!
为了较大发挥二叉树的查找效率,让二叉树不再偏科,保持各科平衡,所以有了平衡二叉树!
平衡二叉树 (AVL Trees)
平衡二叉树是一种特殊的二叉树,所以他也满足前面说到的二叉树的两个特性,同时还有一个特性:
它的左右两个子树的高度差的绝对值不超过1,并且左右两个子树都是一棵平衡二叉树。
大家也看到了前面[35 27 48 12 29 38 55]插入完成后的图,其实就已经是一颗平衡二叉树啦。
那如果按照[12 27 29 35 38 48 55]的顺序插入一颗平衡二叉树,会怎么样呢?我们看看插入以及平衡的过程:


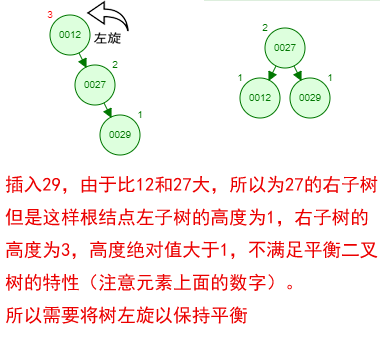
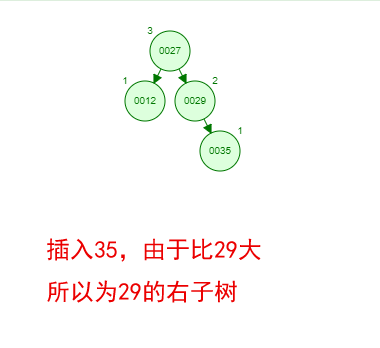
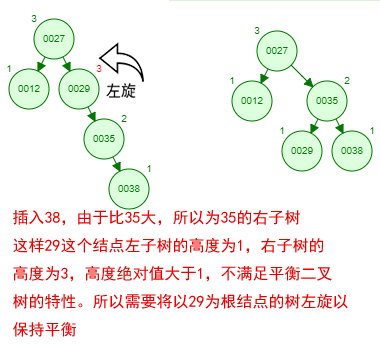
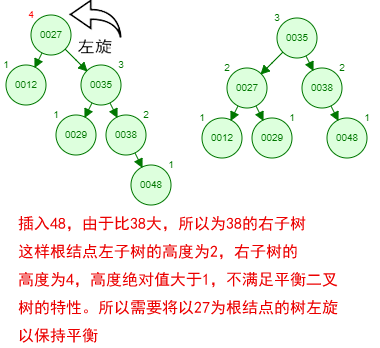
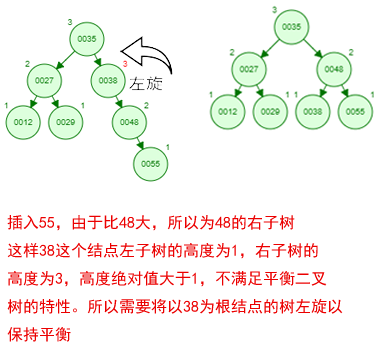
这棵树始终满足平衡二叉树的几个特性而保持平衡!这样我们的树也不会退化为线性链表了!我们需要查找一个数的时候就能沿着树根一直往下找,这样的查找效率和二分法查找是一样的呢!
一颗平衡二叉树能容纳多少的结点呢?这跟树的高度是有关系的,假设树的高度为h,那每一层最多容纳的结点数量为2^(n-1),整棵树最多容纳节点数为2^0+2^1+2^2+...+2^(h-1)。这样计算,100w数据树的高度大概在20左右,那也就是说从有着100w条数据的平衡二叉树中找一个数据,最坏的情况下需要20次查找。如果是内存操作,效率也是很高的!但是我们数据库中的数据基本都是放在磁盘中的,每读取一个二叉树的结点就是一次磁盘IO,这样我们找一条数据如果要经过20次磁盘的IO?那性能就成了一个很大的问题了!那我们是不是可以把这棵树压缩一下,让每一层能够容纳更多的节点呢?虽然我矮,但是我胖啊...
B-Tree
这颗矮胖的树就是B-Tree,注意中间是杠精的杠而不是减,所以也不要读成B减Tree了~
那B-Tree有哪些特性呢?一棵m阶的B-Tree有如下特性:
1、每个结点最多m个子结点。
2、除了根结点和叶子结点外,每个结点最少有m/2(向上取整)个子结点。
3、如果根结点不是叶子结点,那根结点至少包含两个子结点。
4、所有的叶子结点都位于同一层。
5、每个结点都包含k个元素(关键字),这里m/2≤k<m,这里m/2向下取整。
6、每个节点中的元素(关键字)从小到大排列。
7、每个元素(关键字)字左结点的值,都小于或等于该元素(关键字)。右结点的值都大于或等于该元素(关键字)。
是不是感觉跟丈母娘张口问你要彩礼一样,列一堆的条件,而且每一条都让你很懵逼!下面我们以一个[0,1,2,3,4,5,6,7]的数组插入一颗3阶的B-Tree为例,将所有的条件都串起来,你就明白了!


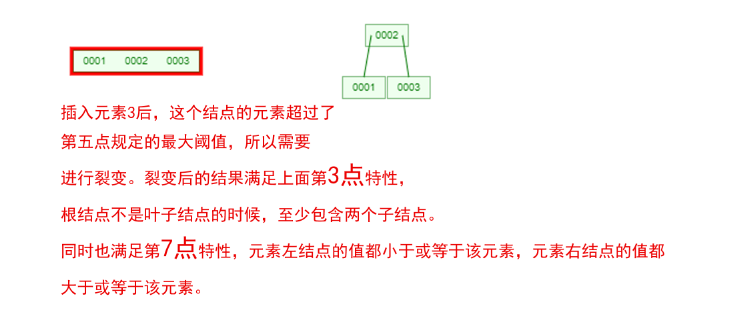
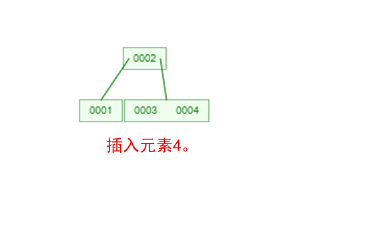
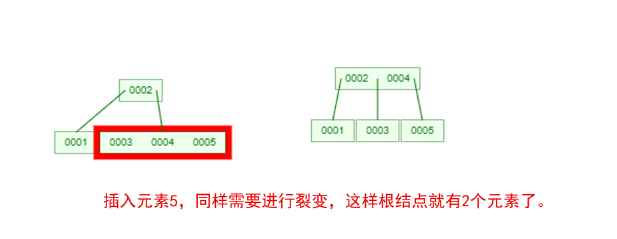
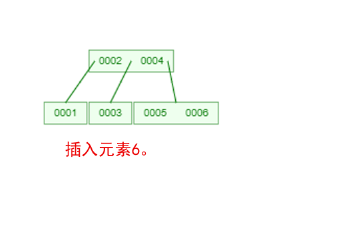
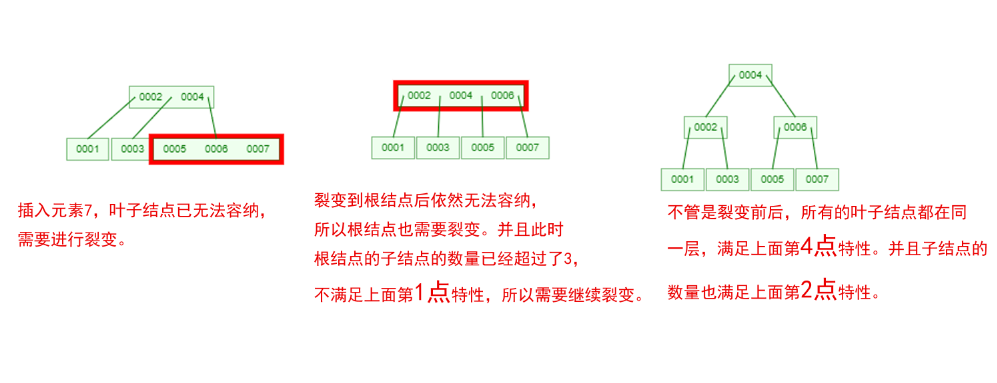
那么,你是否对B-Tree的几点特性都清晰了呢?在二叉树中,每个结点只有一个元素。但是在B-Tree中,每个结点都可能包含多个元素,并且非叶子结点在元素的左右都有指向子结点的指针。
如果需要查找一个元素,那流程是怎么样的呢?我们看下图,如果我们要在下面的B-Tree中找到关键字24,那流程如下
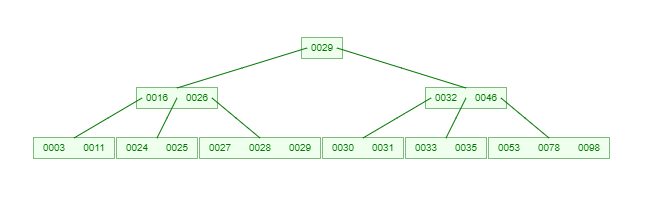
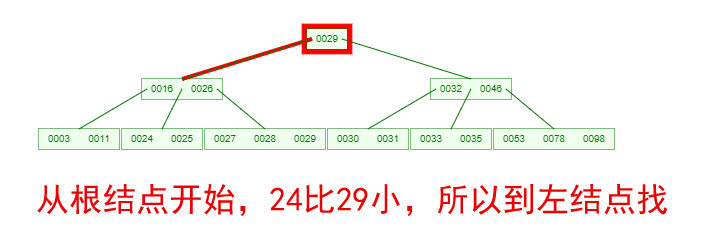
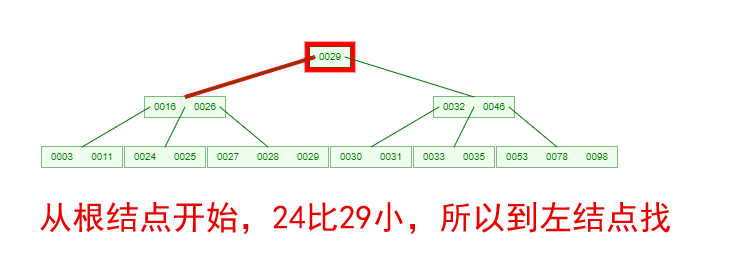
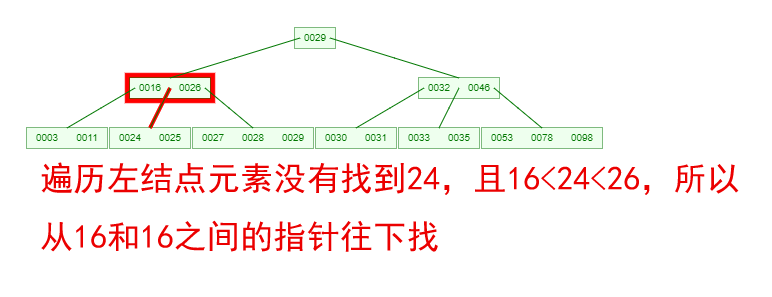
从这个流程我们能看出,B-Tree的查询效率好像也并不比平衡二叉树高。但是查询所经过的结点数量要少很多,也就意味着要少很多次的磁盘IO,这对
性能的提升是很大的。
前面对B-Tree操作的图我们能看出来,元素就是类似1、2、3这样的数值,但是数据库的数据都是一条条的数据,如果某个数据库以B-Tree的数据结构存储数据,那数据怎么存放的呢?我们看下一张图
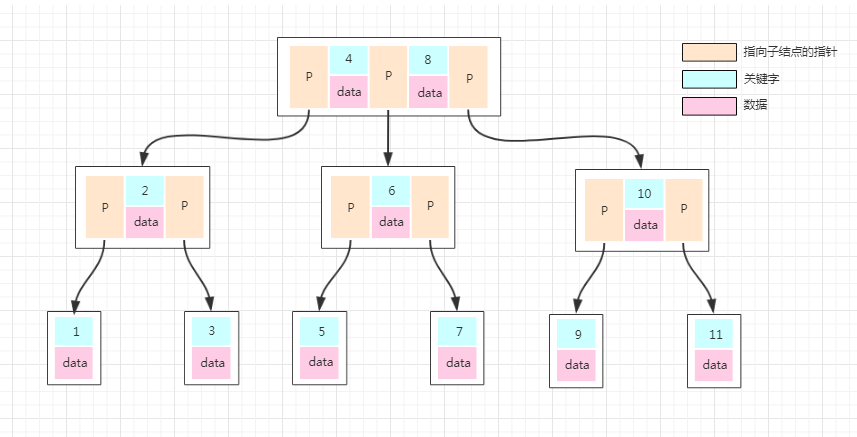
普通的B-Tree的结点中,元素就是一个个的数字。但是上图中,我们把元素部分拆分成了key-data的形式,key就是数据的主键,data就是具体的数据。这样我们在找一条数的时候,就沿着根结点往下找就ok了,效率是比较高的。
B+Tree
B+Tree是在B-Tree基础上的一种优化,使其更适合实现外存储索引结构。B+Tree与B-Tree的结构很像,但是也有几个自己的特性:
1、所有的非叶子节点只存储关键字信息。
2、所有卫星数据(具体数据)都存在叶子结点中。
3、所有的叶子结点中包含了全部元素的信息。
4、所有叶子节点之间都有一个链指针。
如果上面B-Tree的图变成B+Tree,那应该如下:
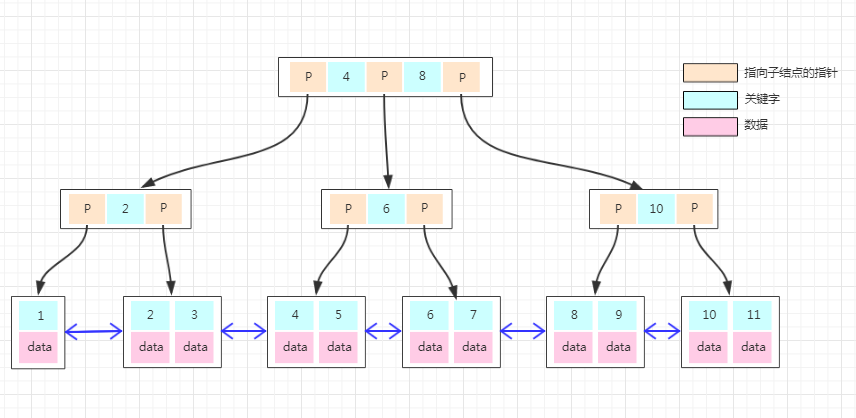
大家仔细对比于B-Tree的图能发现什么不同?
1、非叶子结点上已经只有key信息了,满足上面第1点特性!
2、所有叶子结点下面都有一个data区域,满足上面第2点特性!
3、非叶子结点的数据在叶子结点上都能找到,如根结点的元素4、8在最底层的叶子结点上也能找到,满足上面第3点特性!
4、注意图中叶子结点之间的箭头,满足满足上面第4点特性!
B-Tree or B+Tree?
在讲这两种数据结构在数据库中的选择之前,我们还需要了解的一个知识点是操作系统从磁盘读取数据到内存是以磁盘块(block)为基本单位的,位于同一个磁盘块中的数据会被一次性读取出来,而不是需要什么取什么。即使只需要一个字节,磁盘也会从这个位置开始,顺序向后读取一定长度的数据放入内存。这样做的理论依据是计算机科学中著名的局部性原理: 当一个数据被用到时,其附近的数据也通常会马上被使用。
预读的长度一般为页(page)的整倍数。页是计算机管理存储器的逻辑块,硬件及操作系统往往将主存和磁盘存储区分割为连续的大小相等的块,每个存储块称为一页(在许多操作系统中,页得大小通常为4k)。
B-Tree和B+Tree该如何选择呢?都有哪些优劣呢?
1、B-Tree因为非叶子结点也保存具体数据,所以在查找某个关键字的时候找到即可返回。而B+Tree所有的数据都在叶子结点,每次查找都得到叶子结点。所以在同样高度的B-Tree和B+Tree中,B-Tree查找某个关键字的效率更高。
2、由于B+Tree所有的数据都在叶子结点,并且结点之间有指针连接,在找大于某个关键字或者小于某个关键字的数据的时候,B+Tree只需要找到该关键字然后沿着链表遍历就可以了,而B-Tree还需要遍历该关键字结点的根结点去搜索。
3、由于B-Tree的每个结点(这里的结点可以理解为一个数据页)都存储主键+实际数据,而B+Tree非叶子结点只存储关键字信息,而每个页的大小有限是有限的,所以同一页能存储的B-Tree的数据会比B+Tree存储的更少。这样同样总量的数据,B-Tree的深度会更大,增大查询时的磁盘I/O次数,进而影响查询效率。
鉴于以上的比较,所以在常用的关系型数据库中,都是选择B+Tree的数据结构来存储数据!下面我们以mysql的innodb存储引擎为例讲解,其他类似sqlserver、oracle的原理类似!
innodb引擎数据存储
在InnoDB存储引擎中,也有页的概念,默认每个页的大小为16K,也就是每次读取数据时都是读取4*4k的大小!假设我们现在有一个用户表,我们往里面写数据
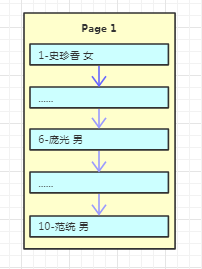
这里需要注意的一点是,在某个页内插入新行时,为了不减少数据的移动,通常是插入到当前行的后面或者是已删除行留下来的空间,所以在某一个页内的数据并不是完全有序的(后面页结构部分有细讲),但是为了为了数据访问顺序性,在每个记录中都有一个指向下一条记录的指针,以此构成了一条单向有序链表,不过在这里为了方便演示我是按顺序排列的!
由于数据还比较少,一个页就能容下,所以只有一个根结点,主键和数据也都是保存在根结点(左边的数字代表主键,右边名字、性别代表具体的数据)。假设我们写入10条数据之后,Page1满了,再写入新的数据会怎么存放呢?我们继续看下图
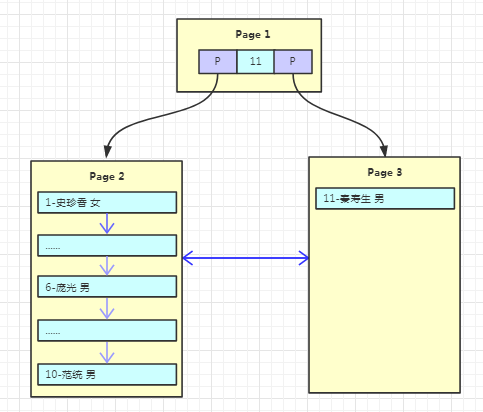
有个叫“秦寿生”的朋友来了,但是Page1已经放不下数据了,这时候就需要进行页分裂,产生一个新的Page。在innodb中的流程是怎么样的呢?
1、产生新的Page2,然后将Page1的内容复制到Page2。
2、产生新的Page3,“秦寿生”的数据放入Page3。
3、原来的Page1依然作为根结点,但是变成了一个不存放数据只存放索引的页,并且有两个子结点Page2、Page3。
这里有两个问题需要注意的是
1、为什么要复制Page1为Page2而不是创建一个新的页作为根结点,这样就少了一步复制的开销了?
如果是重新创建根结点,那根结点存储的物理地址可能经常会变,不利于查找。并且在innodb中根结点是会预读到内存中的,所以结点的物理地址固定会比较好!
2、原来Page1有10条数据,在插入第11条数据的时候进行裂变,根据前面对B-Tree、B+Tree特性的了解,那这至少是一颗11阶的树,裂变之后每个结点的元素至少为11/2=5个,那是不是应该页裂变之后主键1-5的数据还是在原来的页,主键6-11的数据会放到新的页,根结点存放主键6?
如果是这样的话新的页空间利用率只有50%,并且会导致更为频繁的页分裂。所以innodb对这一点做了优化,新的数据放入新创建的页,不移动原有页面的任何记录。
随着数据的不断写入,这棵树也逐渐枝繁叶茂,如下图
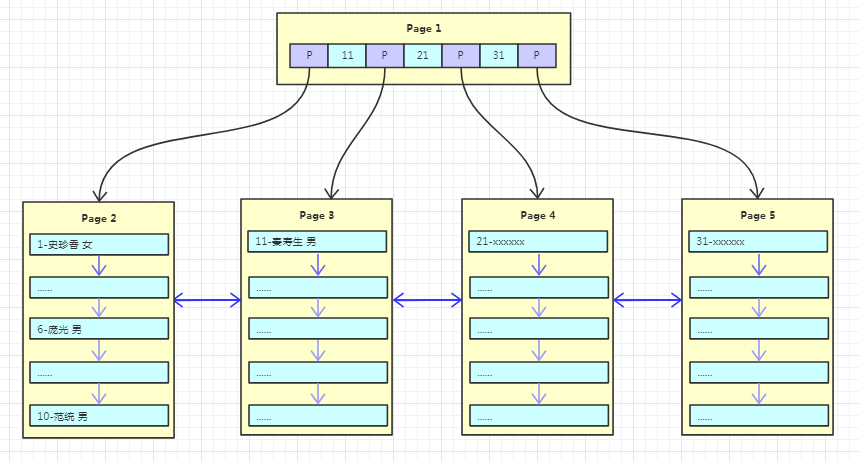
每次新增数据,都是将一个页写满,然后新创建一个页继续写,这里其实是有个隐含条件的,那就是主键自增!主键自增写入时新插入的数据不会影响到原有页,插入效率高!且页的利用率高!但是如果主键是无序的或者随机的,那每次的插入可能会导致原有页频繁的分裂,影响插入效率!降低页的利用率!这也是为什么在innodb中建议设置主键自增的原因!
这棵树的非叶子结点上存的都是主键,那如果一个表没有主键会怎么样?在innodb中,如果一个表没有主键,那默认会找建了唯一索引的列,如果也没有,则会生成一个隐形的字段作为主键!
有数据插入那就有删除,如果这个用户表频繁的插入和删除,那会导致数据页产生碎片,页的空间利用率低,还会导致树变的“虚高”,降低查询效率!这可以通过索引重建来消除碎片提高查询效率!
innodb引擎数据查找
数据插入了怎么查找呢?
1、找到数据所在的页。这个查找过程就跟前面说到的B+Tree的搜索过程是一样的,从根结点开始查找一直到叶子结点。
2、在页内找具体的数据。读取第1步找到的叶子结点数据到内存中,然后通过分块查找的方法找到具体的数据。
这跟我们在新华字典中找某个汉字是一样的,先通过字典的索引定位到该汉字拼音所在的页,然后到指定的页找到具体的汉字。innodb中定位到页后用了哪种策略快速查找某个主键呢?这我们就需要从页结构开始了解。
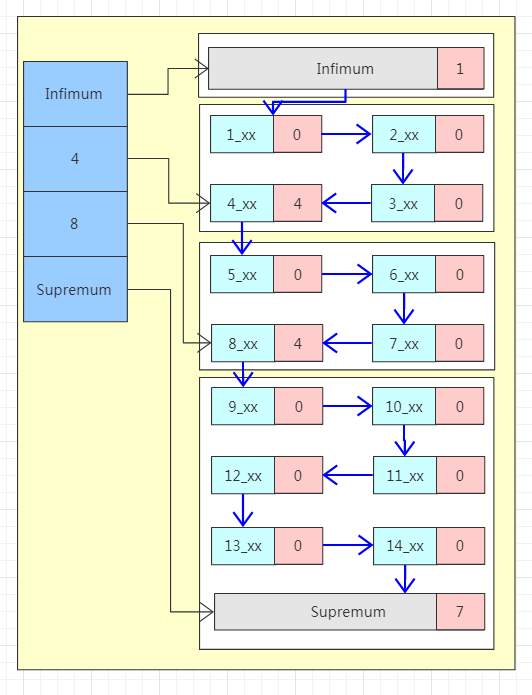
左边蓝色区域称为Page Directory,这块区域由多个slot组成,是一个稀疏索引结构,即一个槽中可能属于多个记录,最少属于4条记录,最多属于8条记录。槽内的数据是有序存放的,所以当我们寻找一条数据的时候可以先在槽中通过二分法查找到一个大致的位置。
右边区域为数据区域,每一个数据页中都包含多条行数据。注意看图中最上面和最下面的两条特殊的行记录Infimum和Supremum,这是两个虚拟的行记录。在没有其他用户数据的时候Infimum的下一条记录的指针指向Supremum,当有用户数据的时候,Infimum的下一条记录的指针指向当前页中最小的用户记录,当前页中最大的用户记录的下一条记录的指针指向Supremum,至此整个页内的所有行记录形成一个单向链表。
行记录被Page Directory逻辑的分成了多个块,块与块之间是有序的,也就是说“4”这个槽指向的数据块内最大的行记录的主键都要比“8”这个槽指向的数据块内最小的行记录的主键要小。但是块内部的行记录不一定有序。
每个行记录的都有一个n_owned的区域(图中粉红色区域),n_owned标识这个这个块有多少条数据,伪记录Infimum的n_owned值总是1,记录Supremum的n_owned的取值范围为[1,8],其他用户记录n_owned的取值范围[4,8],并且只有每个块中最大的那条记录的n_owned才会有值,其他的用户记录的n_owned为0。
所以当我们要找主键为6的记录时,先通过二分法在稀疏索引中找到对应的槽,也就是Page Directory中“8”这个槽,“8”这个槽指向的是该数据块中最大的记录,而数据是单向链表结构所以无法逆向查找,所以需要找到上一个槽即“4”这个槽,然后通过“4”这个槽中最大的用户记录的指针沿着链表顺序查找到目标记录。
聚集索引&非聚集索引
前面关于数据存储的都是演示的聚集索引的实现,如果上面的用户表需要以“用户名字”建立一个非聚集索引,是怎么实现的呢?我们看下图:
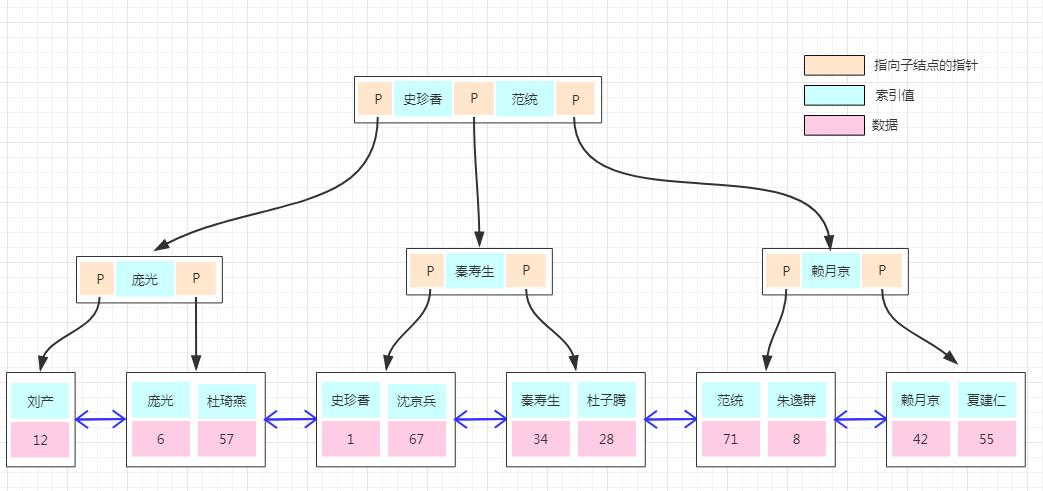
非聚集索引的存储结构与前面是一样的,不同的是在叶子结点的数据部分存的不再是具体的数据,而数据的聚集索引的key。所以通过非聚集索引查找的过程是先找到该索引key对应的聚集索引的key,然后再拿聚集索引的key到主键索引树上查找对应的数据,这个过程称为回表!
图中的这些名字均来源于网络,希望没有误伤正在看这篇文章的你~^_^
innodb与MyISAM两种存储引擎对比
上面包括存储和搜索都是拿的innodb引擎为例,那MyISAM与innodb在存储上有啥不同呢?憋缩话,看图:
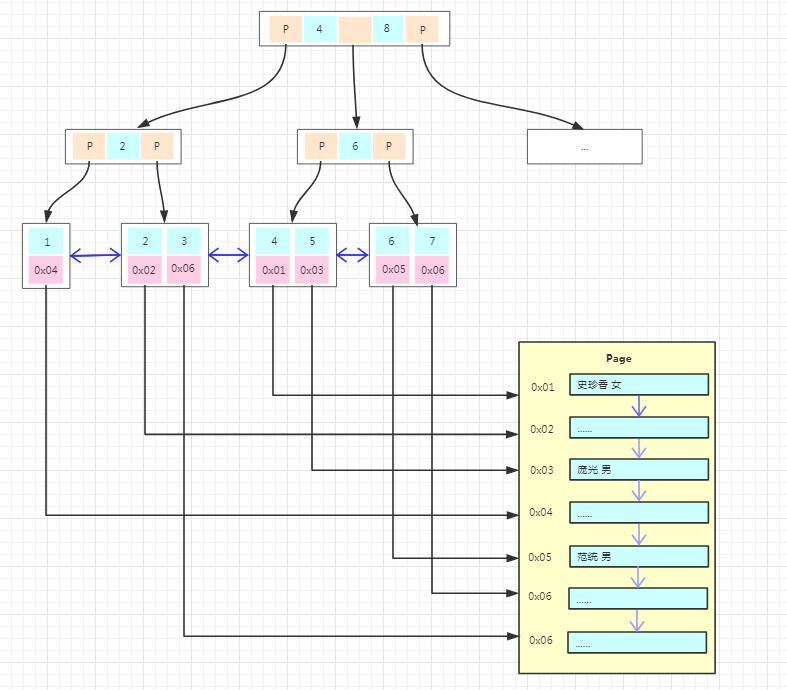
上图为MyISAM主键索引的存储结构,我们能看到的不同是
1、主键索引树的叶子结点的数据区域没有存放实际的数据,存放的是数据记录的地址。
2、数据的存储不是按主键顺序存放的,按写入的顺序存放。
也就是说innodb引擎数据在物理上是按主键顺序存放,而MyISAM引擎数据在物理上按插入的顺序存放。并且MyISAM的叶子结点不存放数据,所以非聚集索引的存储结构与聚集索引类似,在使用非聚集索引查找数据的时候通过非聚集索引树就能直接找到数据的地址了,不需要回表,这比innodb的搜索效率会更高呢!
索引优化建议?
大家经常会在很多的文章或书中能看到一些索引的使用建议,比如说
1、like的模糊查询以%开头,会导致索引失效。
2、一个表建的索引尽量不要超过5个。
3、尽量使用覆盖索引。
4、尽量不要在重复数据多的列上建索引。
5、。。。。。。。。。。。
6、。。。。。。。。。。。
很多这里就不一一列举了!那看完这篇文章,我们能否带着疑问去分析一下为什么要有这些建议?为什么like的模糊查询以%开头,会导致索引失效?为什么一个表建的索引尽量不要超过5个?为什么? 为什么??为什么???相信看到这里的你再加上自己的一些思考应该有答案了吧?
不懂数据库索引的底层原理?那是因为你心里没点b树的更多相关文章
- (转)数据库_不懂数据库索引的底层原理?那是因为你心里没点BTree
原文地址:https://www.cnblogs.com/sujing/p/11110292.html 要了解数据库索引的底层原理,我们就得先了解一种叫树的数据结构,而树中很经典的一种数据结构就是二叉 ...
- MySQL数据库索引的底层原理(二叉树、平衡二叉树、B-Tree、B+Tree)
1.MySQL数据库索引的底层原理 https://mp.weixin.qq.com/s/zA9KvCkkte2mTWTcDv7hUg
- Neo4j图数据库简介和底层原理
现实中很多数据都是用图来表达的,比如社交网络中人与人的关系.地图数据.或是基因信息等等.RDBMS并不适合表达这类数据,而且由于海量数据的存在,让其显得捉襟见肘.NoSQL数据库的兴起,很好地解决了海 ...
- mysql数据库索引类型和原理
索引初识: 最普通的情况,是为出现在where子句的字段建一个索引.为方便讲述,我们先建立一个如下的表. CREATE TABLE mytable ( id serial primary key, c ...
- Activiti工作流学习笔记(三)——自动生成28张数据库表的底层原理分析
原创/朱季谦 我接触工作流引擎Activiti已有两年之久,但一直都只限于熟悉其各类API的使用,对底层的实现,则存在较大的盲区. Activiti这个开源框架在设计上,其实存在不少值得学习和思考的地 ...
- 数据库索引的实现原理(笔记)详细http://www.linezing.com/blog/?p=798#nav-1
数据库索引,是数据库管理系统中一个排序的数据结构,以协助快速查询.更新数据库表中数据.索引的实现通常使用B树及其变种B+树. 在数据之外,数据库系统还维护着满足特定查找算法的数据结构,这些数据结构以某 ...
- Python操作MySQL以及数据库索引
目录 python操作MySQL 安装 使用 SQL注入问题 MySQL的索引 为什么使用索引 索引的种类 主键索引 唯一索引 普通索引 索引优缺点 不会命中索引的情况 explain 索引覆盖 My ...
- 深入理解数据库索引采用B树和B+树的原因
前面几篇关于数据库底层磁盘文件读取,数据库索引实现细节进行了深入的研究,但是没有串联起来的讲解为什么数据库索引会采用B树和B+树而不是其他的数据结构,例如平衡二叉树.链表等,因此,本文打算从数据库文件 ...
- 数据库索引(Index)【未完待续】
数据库索引是啥?有什么用?原理是什么?最佳实践什么? 索引是啥 一个索引是这样的数据结构:从数据上来说,不仅包含了从表中某一列或多列的数据拷贝,同时,还包含了指向这列数据行的链接: 从结构上来说,索引 ...
随机推荐
- C# 比较不错的通用验证码
1 using System; using System.Collections.Generic; using System.Drawing; using System.Drawing.Imaging ...
- VS2015中的快捷键
1.回到上一个光标位置/前进到下一个光标位置 1)回到上一个光标位置:使用组合键“Ctrl + -”; 2)前进到下一个光标位置:“Ctrl + Shift + - ”. 2.复制/剪切/删除整行代码 ...
- WPF 窗体显示最前端
原文:WPF 窗体显示最前端 版权声明:本文为博主原创文章,未经博主允许不得转载. https://blog.csdn.net/jjx0224/article/details/8782845 如何做一 ...
- SharePoint创建内容类型
SharePoint创建内容类型 内容类型的用途是多种多样的.创建内容类型也非常简单. 1. 点击网站操作--网站设置. 2. 点击网站内容类型,点击创建. 3. 命名Beginning_ShareP ...
- MEF 插件式开发 - 小试牛刀
原文:MEF 插件式开发 - 小试牛刀 目录 MEF 简介 实践出真知 面向接口编程 控制反转(IOC) 构建入门级 MEF 相关参考 MEF 简介 Managed Extensibility Fra ...
- MS SQL SERVER搜索某个表的主键所在的列名
原文:MS SQL SERVER搜索某个表的主键所在的列名 SELECT SYSCOLUMNS.name FROM SYSCOLUMNS,SYSOBJECTS,SYSINDEXES,SYSINDEX ...
- 使用Advanced Installer 13.1打包发布 Windows Service服务程序
原文: 使用Advanced Installer 13.1打包发布 Windows Service服务程序 项目中需要用到一个定时推送案件状态的需求,本人小菜一只,在同事建议下要写成一个windows ...
- js基础知识总结:函数
函数内部的属性: arguments 和this是函数内部的两个特殊对象 arguments: function recursion(num){ if(num<=1){ return 1; }e ...
- .NET错误提示之:无法更新EntitySet“TableName”因为它有一个DefiningQuery
使用LINQ 进行提交数据时发生的错误提示 原因:提交的对象表 没有设主键.
- zynqmp(zcu102rev1.0)系列---1---安装 xsdk
Xilinx 的zynq7020在设备上面已经使用上,并量产,关于zynq7020使用总结将在近期同步进行. 该系列主要记录Xilinx zynqmp系列 的使用以及在遇到的问题.目前手上有一块dem ...