数据结构与算法(python版)
案例程序:
- def sumOfN(n):
"""累计求和"""- theSum = 0
- for i in range(1,n+1):
- theSum = theSum+i
- return theSum
二、计算资源指标
三、Python中有一个time模块,可以获取计算机系统当前时间

- # 使用timeit模块对函数计时
- # 创建一个timer对象,指定需要反复运行的语句
- from timeit import Timer
- t1 = Timer("test1()", "from __main__ import test1")
- print("concat %f seconds\n" % (t1.timeit(number=1000)))
- t2 = Timer("test2()", "from __main__ import test2")
- print("append %f seconds\n" % (t2.timeit(number=1000)))
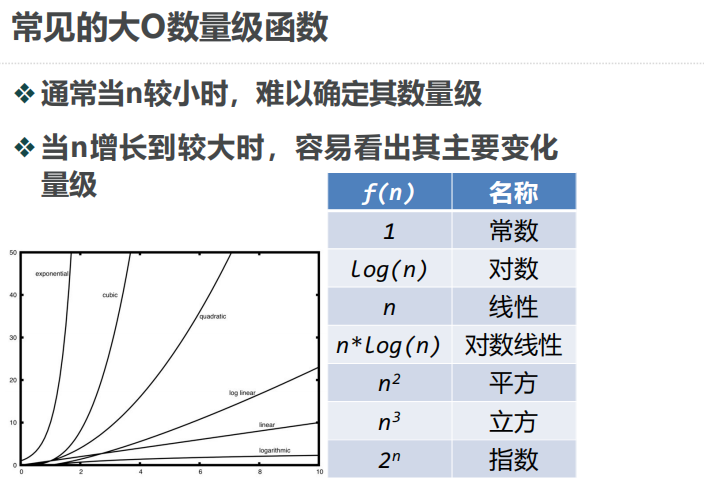
四、数量级函数 Order of Magnitude,大O表示法
1、基本操作数量函数T(n)的精确值并不是特别重要,重要的是T(n)中起决定性因素的主导部分用动态的眼光看,就是当问题规模增大的时候,
T(n)中的一些部分会盖过其它部分的贡献;

算法案例:“变位词”判断问题
- 所谓“变位词”是指两个词之间存在组成字母的
- 重新排列关系
- 如:heart和earth,python和typhon
- 为了简单起见,假设参与判断的两个词仅由小写
- 字母构成,而且长度相等
- def anagramSolution2(s1, s2):
"""将字符串变成列表并排序,然后逐一对比"""- alist1 = list(s1)
- alist2 = list(s2)
- alist1.sort()
- alist2.sort()
- pos = 0
- matches = True
- while pos < len(s1) and matches:
- if alist1[pos] == alist2[pos]:
- pos = pos + 1
- else:
- matches = False
- return matches
- # 使用timeit模块对函数计时
- # 创建一个timer对象,指定需要反复运行的语句
- from timeit import Timer
- t1 = Timer("test1()", "from __main__ import test1")
- print("concat %f seconds\n" % (t1.timeit(number=1000)))
- t2 = Timer("test2()", "from __main__ import test2")
- print("append %f seconds\n" % (t2.timeit(number=1000)))
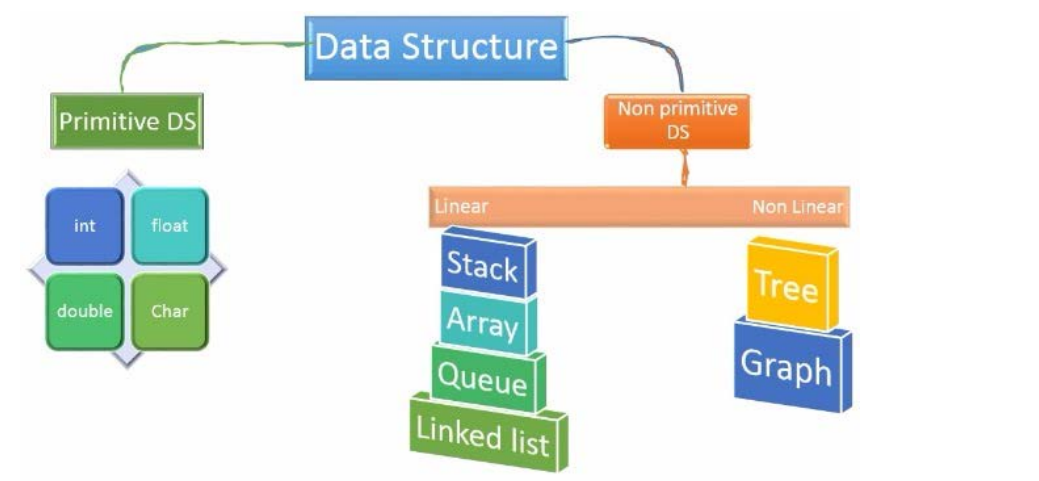
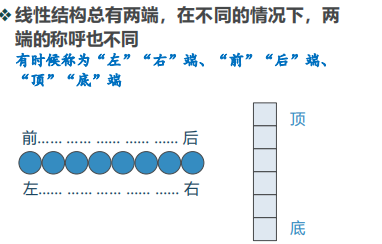
五、python数据类型-线性结构:list、dict、stack、queue、Deque、UnorderedList、OrderedList、

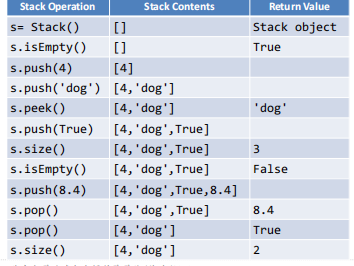
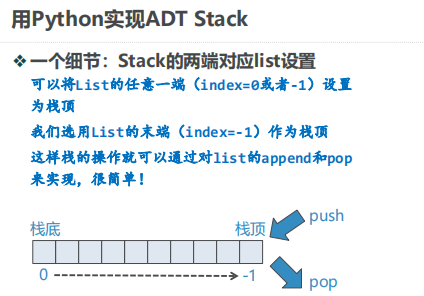
stack的实现:
- class Stack:
- """简单实现的一个栈"""
- def __init__(self):
- self.items = []
- def isEmpty(self):
- return self.items == []
- def push(self, item):
- self.items.append(item)
- def pop(self):
- return self.items.pop()
- #这里的:不同的方法,有不同的操作
- # def push(self, item):
- # self.items.insert(0,item)
- # def pop(self):
- # return self.items.pop(0)
- def peek(self):
- return self.items[len(self.items) - 1]
- def size(self):
- return len(self.items)
- class Stack:
- """简单实现的一个栈"""
- def __init__(self):
- self.items = []
- def isEmpty(self):
- return self.items == []
- def push(self, item):
- self.items.append(item)
- def pop(self):
- return self.items.pop()
- #这里的
- # def push(self, item):
- # self.items.insert(0,item)
- # def pop(self):
- # return self.items.pop(0)
- def peek(self):
- return self.items[len(self.items) - 1]
- def size(self):
- return len(self.items)
- def parChecker(symbolString):
- s = Stack()
- balanced = True
- index = 0
- while index < len(symbolString) and balanced:
- symbol = symbolString[index]
- if symbol == "(":
- s.push(symbol)
- else:
- if s.isEmpty():
- balanced = False
- else:
- s.pop()
- index = index + 1
- if balanced and s.isEmpty():
- return True
- else:
- return False
print (parChecker('((((()))))'))
通用的写发 包含[{(
- def parChecker(symbolString):
- s = Stack()
- balanced = True
- index = 0
- while index < len(symbolString) and balanced:
- symbol = symbolString[index]if symbol in "({[":
- s.push(symbol)
- else:
- if s.isEmpty():
- balanced = False
- else:
- top=s.pop()
- if not matches(top,symbol):
- balanced = False
- index = index + 1
- print('s', s)
- if balanced and s.isEmpty():
- return True
- else:
- return False
- def matches(open, close):
- opens = "[({"
- closers = "]})"
return opens.index(open) == closers.index(close)
实用场景
栈的应用二:进制之间的转化
基本概念:二进制:二进制是计算机原理中最基本的概念,作为组成计算机最基本部件的逻辑门电路,其输入和输出
均仅为两种状态:0和1;
十进制:人类传统文化中最基本的数值概念,如果没有进制之间的转换,人们跟计算机的交互
会相当的困难;
所谓的“进制”,就是用多少个字符来表示整数:十进制是0~9这十个数字字符,二进制是0、1两
个字符
十进制转换为二进制,采用的是“除以2求余数”的算法

- 十进制转化为2进制 案例
def divideBy2(decNumber):- remstack =Stack()
- while decNumber>0:
- rem=decNumber%2 #求余数
- remstack.push(rem)
- decNumber = decNumber//2 # 整数部分
- binString = ""
- while not remstack.isEmpty():
- binString=binString+str(remstack.pop())
- return binString
- print (divideBy2(256))
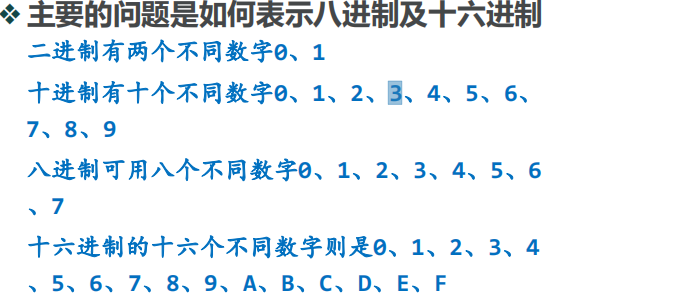
- 十进制转换为十六以下任意进制
- def baseConverter(decNumber,base):
- digits="0123456789ABCDEF"
- remstack =Stack()
- while decNumber>0:
- rem=decNumber%base #余数
- remstack.push(rem)
- decNumber = decNumber//base # 整数部分
- newString = ""
- while not remstack.isEmpty():
- newString=newString+digits[remstack.pop()]
- return newString
- print (baseConverter(256,2))
栈的应用三:表达式应用
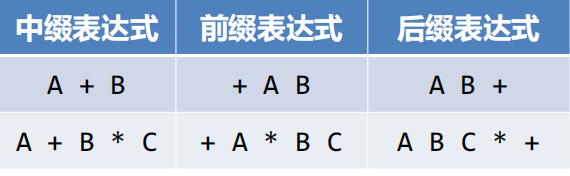
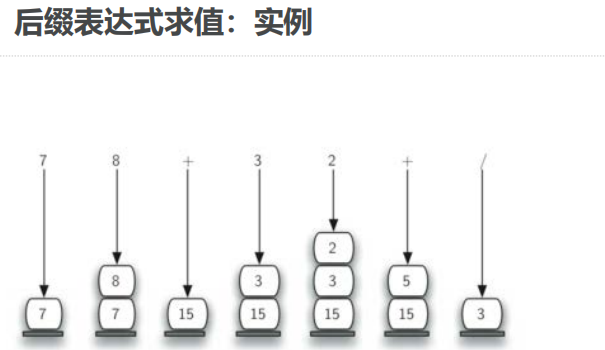
- def infixToPostfix(infixexpr):
- prec = {}
- prec["*"] = 3 # 记录操作符优先级
- prec["/"] = 3
- prec["+"] = 2
- prec["-"] = 2
- prec["("] = 1
- opStack = Stack()
- postfixList = []
- tokenList = infixexpr.split() # 解析表达式到单词列表
- for token in tokenList:
- if token in "ABCDEFGHIJKLMNOPQRSTUVWXYZ" or token in "0123456789":
- postfixList.append(token)
- elif token == "(":
- opStack.push(token)
- elif token == ")":
- topToken = opStack.pop()
- while topToken != '(':
- postfixList.append(topToken)
- topToken = opStack.pop()
- else: # 操作符
- while (not opStack.isEmpty()) and (prec[opStack.peek()] >= prec[token]):
- postfixList.append((opStack.pop()))
- opStack.push(token)
- while not opStack.isEmpty():
- postfixList.append(opStack.pop()) # 操作符
- return " ".join(postfixList) # 合成后缀表达式字符串
七:队列Queue:新加入的数据项必须在数据集末尾等待,而等待时间最长的数据项则是队首;(FIFO:First-in-first-out)先进先出
应用场景:计算机科学中队列的例子:键盘缓冲❖键盘敲击并不马上显示在屏幕上需要有个队列性质的缓冲区,将尚未显示的敲击
字符暂存其中,
特性:队列的先进先出性质则保证了字符的输入和显示次序一致性。
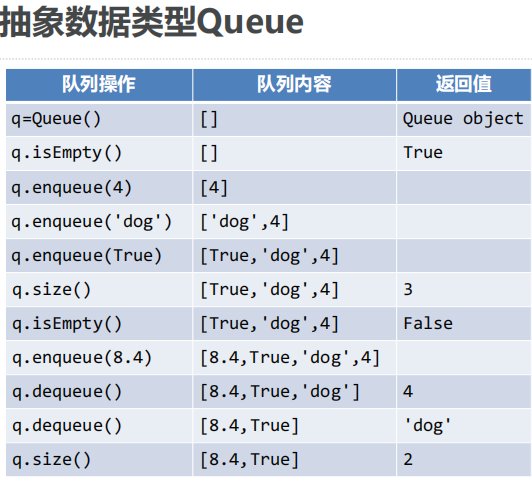
Queue():创建一个空队列对象,返回值为Queue对象;
enqueue(item):将数据项item添加到队尾,无返回值;
dequeue():从队首移除数据项,返回值为队首数据项,队列被修改;
isEmpty():测试是否空队列,返回值为布尔值
size():返回队列中数据项的个数。
- class Queue:
- def __init__(self):
- self.items = []
- def isEmpty(self):
- return self.items == []
- def enqueue(self, item):
- # 队列首段加选项
- self.items.insert(0, item)
- def dequeue(self):
- # 队列尾端出
- return self.items.pop()
- def size(self):
- return len(self.items)
- def hotPotato(namelist, num):
- simqueue = Queue()
- for name in namelist:
- simqueue.enqueue(name)
- while simqueue.size() > 1:
- for i in range(num):
- simqueue.enqueue(simqueue.dequeue())
- simqueue.dequeue()
- return simqueue.dequeue()
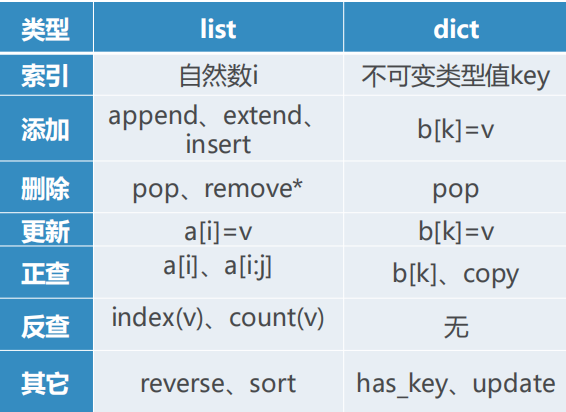
五、list:最常用的是:按索引取值和赋值(v =a[i], a[i]= v)、线性结构:【】
- 四种生成向list里面加数据的方式
def test1():- l = []
- for i in range(1000):
- l = l + [i]
- def test2():
- l = []
- for i in range(1000):
- l.append(i)
- def test3():
'列表推导式'
- l = [i for i in range(1000)]
- def test4():
- l = list(range(1000))
数据结构与算法(python版)的更多相关文章
- 北京大学公开课《数据结构与算法Python版》
之前我分享过一个数据结构与算法的课程,很多小伙伴私信我问有没有Python版. 看了一些公开课后,今天特向大家推荐北京大学的这门课程:<数据结构与算法Python版>. 课程概述 很多同学 ...
- 【数据结构与算法Python版学习笔记】引言
学习来源 北京大学-数据结构与算法Python版 目标 了解计算机科学.程序设计和问题解决的基本概念 计算机科学是对问题本身.问题的解决.以及问题求解过程中得出的解决方案的研究.面对一 个特定问题,计 ...
- 学习笔记:[算法分析]数据结构与算法Python版[基本的数据结构-上]
线性结构Linear Structure ❖线性结构是一种有序数据项的集合,其中 每个数据项都有唯一的前驱和后继 除了第一个没有前驱,最后一个没有后继 新的数据项加入到数据集中时,只会加入到原有 某个 ...
- 【数据结构与算法Python版学习笔记】查找与排序——散列、散列函数、区块链
散列 Hasing 前言 如果数据项之间是按照大小排好序的话,就可以利用二分查找来降低算法复杂度. 现在我们进一步来构造一个新的数据结构, 能使得查找算法的复杂度降到O(1), 这种概念称为" ...
- 数据结构与算法Python版 熟悉哈希表,了解Python字典底层实现
Hash Table 散列表(hash table)也被称为哈希表,它是一种根据键(key)来存储值(value)的特殊线性结构. 常用于迅速的无序单点查找,其查找速度可达到常数级别的O(1). 散列 ...
- 【数据结构与算法Python版学习笔记】算法分析
什么是算法分析 算法是问题解决的通用的分步的指令的聚合 算法分析主要就是从计算资源的消耗的角度来评判和比较算法. 计算资源指标 存储空间或内存 执行时间 影响算法运行时间的其他因素 分为最好.最差和平 ...
- 【数据结构与算法Python版学习笔记】递归(Recursion)——定义及应用:分形树、谢尔宾斯基三角、汉诺塔、迷宫
定义 递归是一种解决问题的方法,它把一个问题分解为越来越小的子问题,直到问题的规模小到可以被很简单直接解决. 通常为了达到分解问题的效果,递归过程中要引入一个调用自身的函数. 举例 数列求和 def ...
- 【数据结构与算法Python版学习笔记】基本数据结构——列表 List,链表实现
无序表链表 定义 一种数据项按照相对位置存放的数据集 抽象数据类型无序列表 UnorderedList 方法 list() 创建一个新的空列表.它不需要参数,而返回一个空列表. add(item) 将 ...
- 【数据结构与算法Python版学习笔记】树——利用二叉堆实现优先级队列
概念 队列有一个重要的变体,叫作优先级队列. 和队列一样,优先级队列从头部移除元素,不过元素的逻辑顺序是由优先级决定的. 优先级最高的元素在最前,优先级最低的元素在最后. 实现优先级队列的经典方法是使 ...
- 【数据结构与算法Python版学习笔记】树——相关术语、定义、实现方法
概念 一种基本的"非线性"数据结构--树 根 枝 叶 广泛应用于计算机科学的多个领域 操作系统 图形学 数据库 计算机网络 特征 第一个属性是层次性,即树是按层级构建的,越笼统就越 ...
随机推荐
- 【NX二次开发】Block UI 分割线
设置控件可见 this->separator0->GetProperties()->SetLogical("Show",true);
- noip2010 总结
机器翻译 题目背景 小晨的电脑上安装了一个机器翻译软件,他经常用这个软件来翻译英语文章. 题目描述 这个翻译软件的原理很简单,它只是从头到尾,依次将每个英文单词用对应的中文含义来替换.对于每个英文单词 ...
- HTTP请求方法及响应状态码详解
HTTP请求方法和响应状态详解 HTTP请求方法 HTTP1.0/1.1支持的所有请求方法如下所示: GET 用来请求访问已被URI识别的资源.指定的资源经服务器解析后返回响应内容. POST POS ...
- top命令信息详解
top详解 [root@localhost ~]# top top - 09:36:38 up 17:59, 3 users, load average: 0.00, 0.03, 0.00 Tasks ...
- Func委托与表达式树Expression
最近在写ORM框架,其中遇到一个难点,就是作为框架调用方如何将查询条件传入框架内.其中就用到了Expression. Func委托 要Expression先要了解Func委托,Func委托的样式是: ...
- Kubernetes中予许及限制(PodSecurityPolicy)使用宿主机资源
1.在pod中使用宿主机命名空间.端口等资源 pod中的容器通常在分开的Linux命名空间中运行.这些命名空间将容器中的进程与其他容器中,或者宿主机默认命名空间中的进程隔离开来. 例如,每一个pod有 ...
- Redis的Pipeline、事务和lua
1. Pipeline 1.1 Pipeline概念 Redis客户端执行一条命令分别为如下4个过程: 1) 发送命令 2) 命令排队 3) 命令执行 4) 返回结果 其中1)+4)称为Round T ...
- 如何获取微信小程序for循环的index
在微信小程序开发中,对于wx:for,可以使用wx:for-index="index"来获取数组中的元素的索引值(下标). <view class="item&qu ...
- SpringBoot集成websocket发送后台日志到前台页面
业务需求 后台为一个采集系统,需要将采集过程中产生的日志实时发送到前台页面展示,以便了解采集过程. 技能点 SpringBoot 2.x websocket logback thymeleaf Rab ...
- CentOS-搭建MinIO集群
一.基础环境 操作系统:CentOS 7.x Minio在线演示 Minio下载 二.准备工作 2.1.机器资源 192.168.1.101 /data1 192.168.1.102 /data2 1 ...