Pandas高级教程之:Dataframe的合并
简介
Pandas提供了很多合并Series和Dataframe的强大的功能,通过这些功能可以方便的进行数据分析。本文将会详细讲解如何使用Pandas来合并Series和Dataframe。
使用concat
concat是最常用的合并DF的方法,先看下concat的定义:
pd.concat(objs, axis=0, join='outer', ignore_index=False, keys=None,
levels=None, names=None, verify_integrity=False, copy=True)
看一下我们经常会用到的几个参数:
objs是Series或者Series的序列或者映射。
axis指定连接的轴。
join : {‘inner’, ‘outer’}, 连接方式,怎么处理其他轴的index,outer表示合并,inner表示交集。
ignore_index: 忽略原本的index值,使用0,1,… n-1来代替。
copy:是否进行拷贝。
keys:指定最外层的多层次结构的index。
我们先定义几个DF,然后看一下怎么使用concat把这几个DF连接起来:
In [1]: df1 = pd.DataFrame({'A': ['A0', 'A1', 'A2', 'A3'],
...: 'B': ['B0', 'B1', 'B2', 'B3'],
...: 'C': ['C0', 'C1', 'C2', 'C3'],
...: 'D': ['D0', 'D1', 'D2', 'D3']},
...: index=[0, 1, 2, 3])
...:
In [2]: df2 = pd.DataFrame({'A': ['A4', 'A5', 'A6', 'A7'],
...: 'B': ['B4', 'B5', 'B6', 'B7'],
...: 'C': ['C4', 'C5', 'C6', 'C7'],
...: 'D': ['D4', 'D5', 'D6', 'D7']},
...: index=[4, 5, 6, 7])
...:
In [3]: df3 = pd.DataFrame({'A': ['A8', 'A9', 'A10', 'A11'],
...: 'B': ['B8', 'B9', 'B10', 'B11'],
...: 'C': ['C8', 'C9', 'C10', 'C11'],
...: 'D': ['D8', 'D9', 'D10', 'D11']},
...: index=[8, 9, 10, 11])
...:
In [4]: frames = [df1, df2, df3]
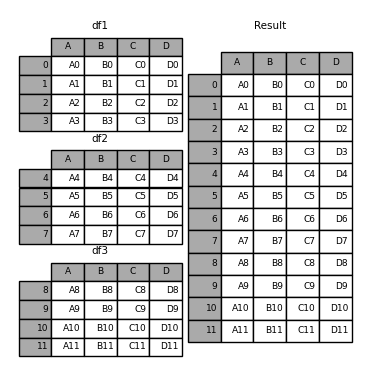
In [5]: result = pd.concat(frames)
df1,df2,df3定义了同样的列名和不同的index,然后将他们放在frames中构成了一个DF的list,将其作为参数传入concat就可以进行DF的合并。
举个多层级的例子:
In [6]: result = pd.concat(frames, keys=['x', 'y', 'z'])
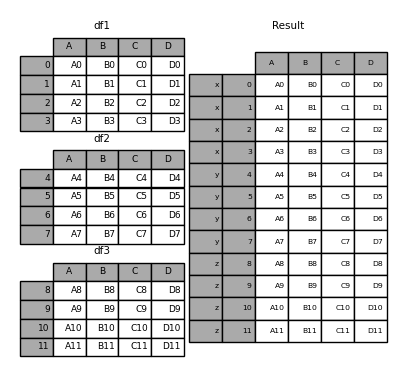
使用keys可以指定frames中不同frames的key。
使用的时候,我们可以通过选择外部的key来返回特定的frame:
In [7]: result.loc['y']
Out[7]:
A B C D
4 A4 B4 C4 D4
5 A5 B5 C5 D5
6 A6 B6 C6 D6
7 A7 B7 C7 D7
上面的例子连接的轴默认是0,也就是按行来进行连接,下面我们来看一个例子按列来进行连接,如果要按列来连接,可以指定axis=1:
In [8]: df4 = pd.DataFrame({'B': ['B2', 'B3', 'B6', 'B7'],
...: 'D': ['D2', 'D3', 'D6', 'D7'],
...: 'F': ['F2', 'F3', 'F6', 'F7']},
...: index=[2, 3, 6, 7])
...:
In [9]: result = pd.concat([df1, df4], axis=1, sort=False)
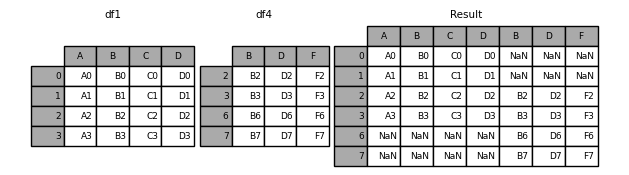
默认的 join='outer',合并之后index不存在的地方会补全为NaN。
下面看一个join='inner'的情况:
In [10]: result = pd.concat([df1, df4], axis=1, join='inner')

join='inner' 只会选择index相同的进行展示。
如果合并之后,我们只想保存原来frame的index相关的数据,那么可以使用reindex:
In [11]: result = pd.concat([df1, df4], axis=1).reindex(df1.index)
或者这样:
In [12]: pd.concat([df1, df4.reindex(df1.index)], axis=1)
Out[12]:
A B C D B D F
0 A0 B0 C0 D0 NaN NaN NaN
1 A1 B1 C1 D1 NaN NaN NaN
2 A2 B2 C2 D2 B2 D2 F2
3 A3 B3 C3 D3 B3 D3 F3
看下结果:

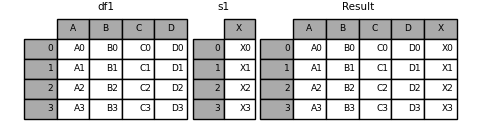
可以合并DF和Series:
In [18]: s1 = pd.Series(['X0', 'X1', 'X2', 'X3'], name='X')
In [19]: result = pd.concat([df1, s1], axis=1)
如果是多个Series,使用concat可以指定列名:
In [23]: s3 = pd.Series([0, 1, 2, 3], name='foo')
In [24]: s4 = pd.Series([0, 1, 2, 3])
In [25]: s5 = pd.Series([0, 1, 4, 5])
In [27]: pd.concat([s3, s4, s5], axis=1, keys=['red', 'blue', 'yellow'])
Out[27]:
red blue yellow
0 0 0 0
1 1 1 1
2 2 2 4
3 3 3 5
使用append
append可以看做是concat的简化版本,它沿着axis=0 进行concat:
In [13]: result = df1.append(df2)
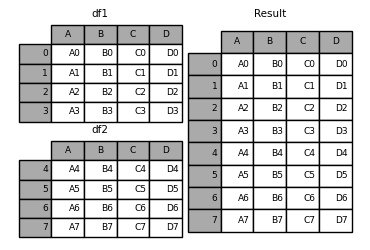
如果append的两个 DF的列是不一样的会自动补全NaN:
In [14]: result = df1.append(df4, sort=False)
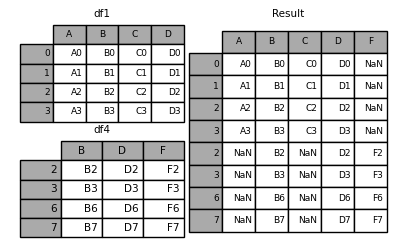
如果设置ignore_index=True,可以忽略原来的index,并重写分配index:
In [17]: result = df1.append(df4, ignore_index=True, sort=False)
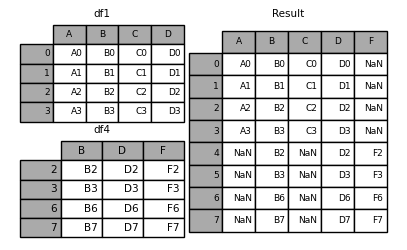
向DF append一个Series:
In [35]: s2 = pd.Series(['X0', 'X1', 'X2', 'X3'], index=['A', 'B', 'C', 'D'])
In [36]: result = df1.append(s2, ignore_index=True)
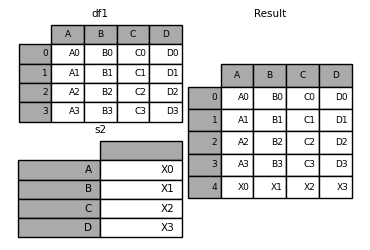
使用merge
和DF最类似的就是数据库的表格,可以使用merge来进行类似数据库操作的DF合并操作。
先看下merge的定义:
pd.merge(left, right, how='inner', on=None, left_on=None, right_on=None,
left_index=False, right_index=False, sort=True,
suffixes=('_x', '_y'), copy=True, indicator=False,
validate=None)
Left, right是要合并的两个DF 或者 Series。
on代表的是join的列或者index名。
left_on:左连接
right_on:右连接
left_index: 连接之后,选择使用左边的index或者column。
right_index:连接之后,选择使用右边的index或者column。
how:连接的方式,'left', 'right', 'outer', 'inner'. 默认 inner.
sort: 是否排序。
suffixes: 处理重复的列。
copy: 是否拷贝数据
先看一个简单merge的例子:
In [39]: left = pd.DataFrame({'key': ['K0', 'K1', 'K2', 'K3'],
....: 'A': ['A0', 'A1', 'A2', 'A3'],
....: 'B': ['B0', 'B1', 'B2', 'B3']})
....:
In [40]: right = pd.DataFrame({'key': ['K0', 'K1', 'K2', 'K3'],
....: 'C': ['C0', 'C1', 'C2', 'C3'],
....: 'D': ['D0', 'D1', 'D2', 'D3']})
....:
In [41]: result = pd.merge(left, right, on='key')
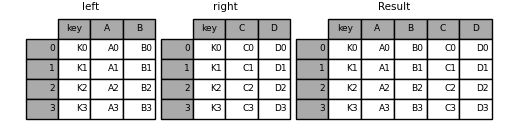
上面两个DF通过key来进行连接。
再看一个多个key连接的例子:
In [42]: left = pd.DataFrame({'key1': ['K0', 'K0', 'K1', 'K2'],
....: 'key2': ['K0', 'K1', 'K0', 'K1'],
....: 'A': ['A0', 'A1', 'A2', 'A3'],
....: 'B': ['B0', 'B1', 'B2', 'B3']})
....:
In [43]: right = pd.DataFrame({'key1': ['K0', 'K1', 'K1', 'K2'],
....: 'key2': ['K0', 'K0', 'K0', 'K0'],
....: 'C': ['C0', 'C1', 'C2', 'C3'],
....: 'D': ['D0', 'D1', 'D2', 'D3']})
....:
In [44]: result = pd.merge(left, right, on=['key1', 'key2'])

How 可以指定merge方式,和数据库一样,可以指定是内连接,外连接等:
| 合并方法 | SQL 方法 |
|---|---|
left |
LEFT OUTER JOIN |
right |
RIGHT OUTER JOIN |
outer |
FULL OUTER JOIN |
inner |
INNER JOIN |
In [45]: result = pd.merge(left, right, how='left', on=['key1', 'key2'])
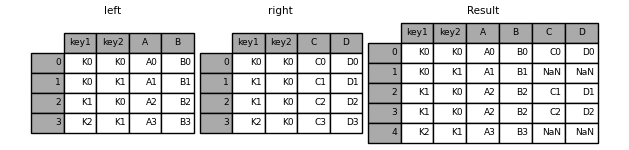
指定indicator=True ,可以表示具体行的连接方式:
In [60]: df1 = pd.DataFrame({'col1': [0, 1], 'col_left': ['a', 'b']})
In [61]: df2 = pd.DataFrame({'col1': [1, 2, 2], 'col_right': [2, 2, 2]})
In [62]: pd.merge(df1, df2, on='col1', how='outer', indicator=True)
Out[62]:
col1 col_left col_right _merge
0 0 a NaN left_only
1 1 b 2.0 both
2 2 NaN 2.0 right_only
3 2 NaN 2.0 right_only
如果传入字符串给indicator,会重命名indicator这一列的名字:
In [63]: pd.merge(df1, df2, on='col1', how='outer', indicator='indicator_column')
Out[63]:
col1 col_left col_right indicator_column
0 0 a NaN left_only
1 1 b 2.0 both
2 2 NaN 2.0 right_only
3 2 NaN 2.0 right_only
多个index进行合并:
In [112]: leftindex = pd.MultiIndex.from_tuples([('K0', 'X0'), ('K0', 'X1'),
.....: ('K1', 'X2')],
.....: names=['key', 'X'])
.....:
In [113]: left = pd.DataFrame({'A': ['A0', 'A1', 'A2'],
.....: 'B': ['B0', 'B1', 'B2']},
.....: index=leftindex)
.....:
In [114]: rightindex = pd.MultiIndex.from_tuples([('K0', 'Y0'), ('K1', 'Y1'),
.....: ('K2', 'Y2'), ('K2', 'Y3')],
.....: names=['key', 'Y'])
.....:
In [115]: right = pd.DataFrame({'C': ['C0', 'C1', 'C2', 'C3'],
.....: 'D': ['D0', 'D1', 'D2', 'D3']},
.....: index=rightindex)
.....:
In [116]: result = pd.merge(left.reset_index(), right.reset_index(),
.....: on=['key'], how='inner').set_index(['key', 'X', 'Y'])
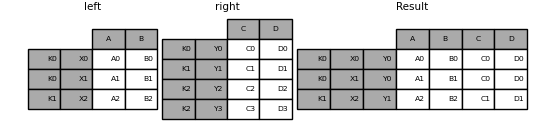
支持多个列的合并:
In [117]: left_index = pd.Index(['K0', 'K0', 'K1', 'K2'], name='key1')
In [118]: left = pd.DataFrame({'A': ['A0', 'A1', 'A2', 'A3'],
.....: 'B': ['B0', 'B1', 'B2', 'B3'],
.....: 'key2': ['K0', 'K1', 'K0', 'K1']},
.....: index=left_index)
.....:
In [119]: right_index = pd.Index(['K0', 'K1', 'K2', 'K2'], name='key1')
In [120]: right = pd.DataFrame({'C': ['C0', 'C1', 'C2', 'C3'],
.....: 'D': ['D0', 'D1', 'D2', 'D3'],
.....: 'key2': ['K0', 'K0', 'K0', 'K1']},
.....: index=right_index)
.....:
In [121]: result = left.merge(right, on=['key1', 'key2'])
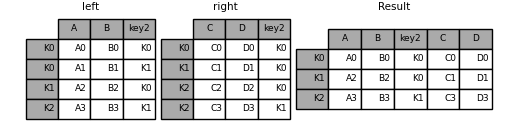
使用join
join将两个不同index的DF合并成一个。可以看做是merge的简写。
In [84]: left = pd.DataFrame({'A': ['A0', 'A1', 'A2'],
....: 'B': ['B0', 'B1', 'B2']},
....: index=['K0', 'K1', 'K2'])
....:
In [85]: right = pd.DataFrame({'C': ['C0', 'C2', 'C3'],
....: 'D': ['D0', 'D2', 'D3']},
....: index=['K0', 'K2', 'K3'])
....:
In [86]: result = left.join(right)
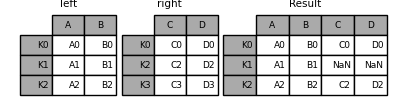
可以指定how来指定连接方式:
In [87]: result = left.join(right, how='outer')
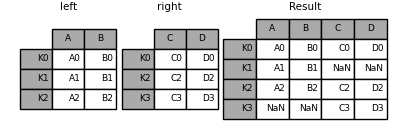
默认join是按index来进行连接。
还可以按照列来进行连接:
In [91]: left = pd.DataFrame({'A': ['A0', 'A1', 'A2', 'A3'],
....: 'B': ['B0', 'B1', 'B2', 'B3'],
....: 'key': ['K0', 'K1', 'K0', 'K1']})
....:
In [92]: right = pd.DataFrame({'C': ['C0', 'C1'],
....: 'D': ['D0', 'D1']},
....: index=['K0', 'K1'])
....:
In [93]: result = left.join(right, on='key')
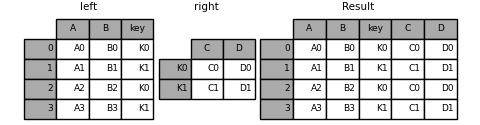
单个index和多个index进行join:
In [100]: left = pd.DataFrame({'A': ['A0', 'A1', 'A2'],
.....: 'B': ['B0', 'B1', 'B2']},
.....: index=pd.Index(['K0', 'K1', 'K2'], name='key'))
.....:
In [101]: index = pd.MultiIndex.from_tuples([('K0', 'Y0'), ('K1', 'Y1'),
.....: ('K2', 'Y2'), ('K2', 'Y3')],
.....: names=['key', 'Y'])
.....:
In [102]: right = pd.DataFrame({'C': ['C0', 'C1', 'C2', 'C3'],
.....: 'D': ['D0', 'D1', 'D2', 'D3']},
.....: index=index)
.....:
In [103]: result = left.join(right, how='inner')
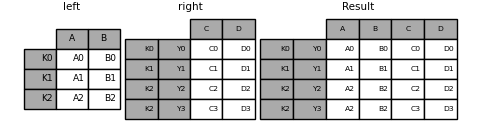
列名重复的情况:
In [122]: left = pd.DataFrame({'k': ['K0', 'K1', 'K2'], 'v': [1, 2, 3]})
In [123]: right = pd.DataFrame({'k': ['K0', 'K0', 'K3'], 'v': [4, 5, 6]})
In [124]: result = pd.merge(left, right, on='k')
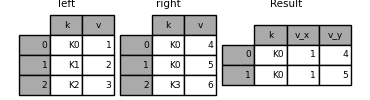
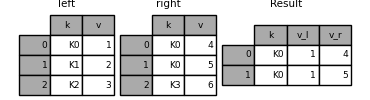
可以自定义重复列名的命名规则:
In [125]: result = pd.merge(left, right, on='k', suffixes=('_l', '_r'))
覆盖数据
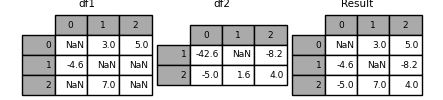
有时候我们需要使用DF2的数据来填充DF1的数据,这时候可以使用combine_first:
In [131]: df1 = pd.DataFrame([[np.nan, 3., 5.], [-4.6, np.nan, np.nan],
.....: [np.nan, 7., np.nan]])
.....:
In [132]: df2 = pd.DataFrame([[-42.6, np.nan, -8.2], [-5., 1.6, 4]],
.....: index=[1, 2])
.....:
In [133]: result = df1.combine_first(df2)
或者使用update:
In [134]: df1.update(df2)
本文已收录于 http://www.flydean.com/04-python-pandas-merge/
最通俗的解读,最深刻的干货,最简洁的教程,众多你不知道的小技巧等你来发现!
欢迎关注我的公众号:「程序那些事」,懂技术,更懂你!
Pandas高级教程之:Dataframe的合并的更多相关文章
- Pandas高级教程之:GroupBy用法
Pandas高级教程之:GroupBy用法 目录 简介 分割数据 多index get_group dropna groups属性 index的层级 group的遍历 聚合操作 通用聚合方法 同时使用 ...
- Pandas高级教程之:处理text数据
目录 简介 创建text的DF String 的方法 columns的String操作 分割和替换String String的连接 使用 .str来index extract extractall c ...
- Pandas高级教程之:处理缺失数据
目录 简介 NaN的例子 整数类型的缺失值 Datetimes 类型的缺失值 None 和 np.nan 的转换 缺失值的计算 使用fillna填充NaN数据 使用dropna删除包含NA的数据 插值 ...
- Pandas高级教程之:category数据类型
目录 简介 创建category 使用Series创建 使用DF创建 创建控制 转换为原始类型 categories的操作 获取category的属性 重命名categories 使用add_cate ...
- Pandas高级教程之:plot画图详解
目录 简介 基础画图 其他图像 bar stacked bar barh Histograms box Area Scatter Hexagonal bin Pie 在画图中处理NaN数据 其他作图工 ...
- Pandas高级教程之:统计方法
目录 简介 变动百分百 Covariance协方差 Correlation相关系数 rank等级 简介 数据分析中经常会用到很多统计类的方法,本文将会介绍Pandas中使用到的统计方法. 变动百分百 ...
- Pandas高级教程之:window操作
目录 简介 滚动窗口 Center window Weighted window 加权窗口 扩展窗口 指数加权窗口 简介 在数据统计中,经常需要进行一些范围操作,这些范围我们可以称之为一个window ...
- Pandas高级教程之:稀疏数据结构
目录 简介 Spare data的例子 SparseArray SparseDtype Sparse的属性 Sparse的计算 SparseSeries 和 SparseDataFrame 简介 如果 ...
- Pandas高级教程之:自定义选项
目录 简介 常用选项 get/set 选项 经常使用的选项 最大展示行数 超出数据展示 最大列的宽度 显示精度 零转换的门槛 列头的对齐方向 简介 pandas有一个option系统可以控制panda ...
随机推荐
- Docker镜像基本使用
使用 Docker 镜像 Docker 运行容器前需要本地存在对应的镜像,如果本地不存在该镜像,Docker 会从镜像仓库下载该镜像. 获取镜像 docker pull [选项] [Docker Re ...
- windows-CODE注入(远程线程注入)
远程线程注入(先简单说,下面会详细说)今天整理下代码注入(远程线程注入),所谓代码注入,可以简单的理解为是在指定内进程里申请一块内存,然后把我们自己的执行代码和一些变量拷贝进去(通常是以启线程的方式) ...
- SparkSQL电商用户画像(二)之如何构建画像
四. 如何构建电商用户画像 4.1 构建电商用户画像技术和流程 构建一个用户画像,包括数据源端数据收集.数据预处理.行为建模.构建用户画像 有些标签是可以直接获取到的,有些标签需要通过数据挖掘分析到! ...
- ArcGIS JS API使用PrintTask打印地图问题解决汇总
环境:来源于工作过程,使用的API是 arcgis js 3.* 3系API,4.*暂时没测试: 1.数据与打印服务跨域情况下,不能打印问题. 一般情况下,我们发布的数据服务和打印服务是在一台服务 ...
- Git 系列教程(12)- 分支的新建与合并
实际工作场景 可能会遇到的工作流 开发某个网站 为实现某个新的用户需求,创建一个分支 在这个分支上开展新工作 正在此时,你突然接到一个电话说有个很严重的问题需要紧急修补,你将按照如下方式来处理: 切换 ...
- Java集合详解(三):HashMap原理解析
概述 本文是基于jdk8_271版本进行分析的. HashMap是Map集合中使用最多的.底层是基于数组+链表实现的,jdk8开始底层是基于数组+链表/红黑树实现的.HashMap也会动态扩容,与Ar ...
- 驰骋CCFlow开源工作流程引擎如何设置PDF打印
前言 经常有驰骋CCFlow爱好者朋友提问关于打印相关问题.在这篇博文中大家介绍一下工作流引擎CCFlow的HTML打印和PDF打印,针对Java版本和.NET版本有不同的操作步骤,包括开关设置.水印 ...
- 使用alpine为基础镜像Q&A
作为go应用存在二进制文件却不能执行 明明镜像中有对应的二进制文件,但是执行时却提示 not found 或 no such file 或 standard_init_linux.go:211: ex ...
- lua编译为二进制方式
当不想使用户看到lua源码,文本文件可以通过luac,把lua文本文件"编译"成二进制的文件. lc@lc-virtual-machine:~/lua$ luac -o redis ...
- [bug] vue cli 部署在 springboot中报404
复制资源时,在static目录下新建了一个static目录,估计是引起了spring解析的混乱,改为one后即可正常访问 参考 https://www.cnblogs.com/qianjinyan/p ...