Fllin(七)【Flink CDC实践】
FlinkCDC
1.简介
CDC是Change Data Capture(变更数据获取)的简称。核心思想是,监测并捕获数据库的变动(包括数据或数据表的插入、更新以及删除等),将这些变更按发生的顺序完整记录下来,写入到消息中间件中以供其他服务进行订阅及消费。
CDC种类
CDC主要分为基于查询和基于Binlog两种方式,我们主要了解一下这两种之间的区别:
| 基于查询的CDC | 基于Binlog的CDC | |
|---|---|---|
| 开源产品 | Sqoop、Kafka JDBC Source | Canal、Maxwell、Debezium |
| 执行模式 | Batch | Streaming |
| 是否可以捕获所有数据变化 | 否 | 是 |
| 延迟性 | 高延迟 | 低延迟 |
| 是否增加数据库压力 | 是 | 否 |
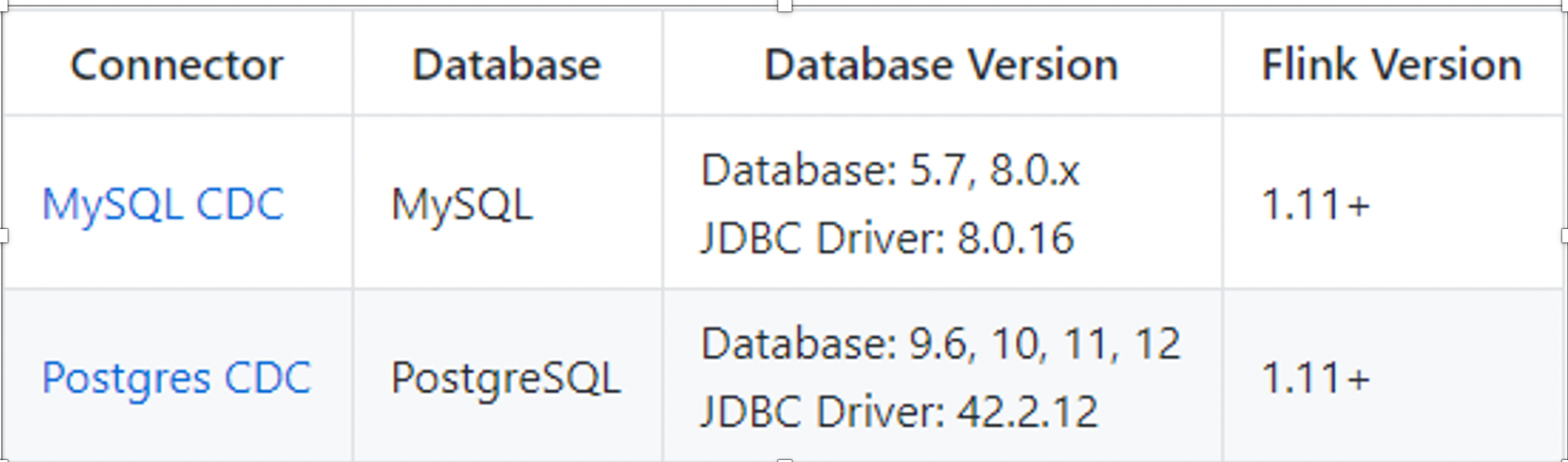
支持的数据库
Flink社区开发了 flink-cdc-connectors 组件,这是一个可以直接从 MySQL、PostgreSQL
等数据库直接读取全量数据和增量变更数据的 source 组件。目前也已开源,开源地址:https://github.com/ververica/flink-cdc-connectors。
2.依赖
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>1.12.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.12</artifactId>
<version>1.12.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_2.12</artifactId>
<version>1.12.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.1.3</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.49</version>
</dependency>
<dependency>
<groupId>com.alibaba.ververica</groupId>
<artifactId>flink-connector-mysql-cdc</artifactId>
<version>1.1.1</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.75</version>
</dependency>
</dependencies>
3.flink stream api
package com.flink.day07_flink_cdc;
import com.alibaba.ververica.cdc.connectors.mysql.MySQLSource;
import com.alibaba.ververica.cdc.debezium.DebeziumSourceFunction;
import com.alibaba.ververica.cdc.debezium.StringDebeziumDeserializationSchema;
import org.apache.flink.api.common.restartstrategy.RestartStrategies;
import org.apache.flink.runtime.state.filesystem.FsStateBackend;
import org.apache.flink.streaming.api.CheckpointingMode;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.CheckpointConfig;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import java.util.Properties;
/**
* @description: TODO Flink CDC stream api
* @author: HaoWu
* @create: 2021年05月21日
*/
public class Flink01_Flink_CDC_Streaming {
public static void main(String[] args) throws Exception {
//1.TODO 创建执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
//2.TODO Flink-CDC将读取binlog的位置信息以状态的方式保存在CK,如果想要做到断点续传,需要从Checkpoint或者Savepoint启动程序
//2.1 开启Checkpoint,每隔5秒钟做一次CK
env.enableCheckpointing(5000L);
//2.2 指定CK的一致性语义
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
//2.3 设置任务关闭的时候保留最后一次CK数据
env.getCheckpointConfig().enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
//2.4 指定从CK自动重启策略
env.setRestartStrategy(RestartStrategies.fixedDelayRestart(3, 2000L));
//2.5 设置状态后端
env.setStateBackend(new FsStateBackend("hdfs://hadoop102:9000/flinkCDC"));
//2.6 设置访问HDFS的用户名
System.setProperty("HADOOP_USER_NAME", "atguigu");
//3.创建Flink-MySQL-CDC的Source
Properties properties = new Properties();
//initial (default): Performs an initial snapshot on the monitored database tables upon first startup, and continue to read the latest binlog.
//latest-offset: Never to perform snapshot on the monitored database tables upon first startup, just read from the end of the binlog which means only have the changes since the connector was started.
//timestamp: Never to perform snapshot on the monitored database tables upon first startup, and directly read binlog from the specified timestamp. The consumer will traverse the binlog from the beginning and ignore change events whose timestamp is smaller than the specified timestamp.
//specific-offset: Never to perform snapshot on the monitored database tables upon first startup, and directly read binlog from the specified offset.
properties.setProperty("scan.startup.mode", "initial");
DebeziumSourceFunction<String> mysqlSource = MySQLSource.<String>builder()
.hostname("hadoop102")
.port(3306)
.username("root")
.password("root")
.databaseList("gmall-flink-200821")
.tableList("gmall-flink-200821.z_user_info") //可选配置项,如果不指定该参数,则会读取上一个配置下的所有表的数据,注意:指定的时候需要使用"db.table"的方式
.debeziumProperties(properties)
.deserializer(new StringDebeziumDeserializationSchema())
.build();
//4.使用CDC Source从MySQL读取数据
DataStreamSource<String> mysqlDS = env.addSource(mysqlSource);
//5.打印数据
mysqlDS.print();
//6.执行任务
env.execute();
}
}
4.flink sql
package com.flink.day07_flink_cdc;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
/**
* @description: TODO FLink CDC SQL
* @author: HaoWu
* @create: 2021年05月24日
*/
public class Flink02_Flink_CDC_Sql {
public static void main(String[] args) throws Exception {
//1.创建flink sql执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
//2.创建FLink-Mysql-CDC 的Source
String sourceSql= "create table user_info(\n" +
" id int,\n" +
" name string,\n" +
" age int\n" +
")\n" +
"with(\n" +
" 'connector'='mysql-cdc',\n" +
" 'hostname'='hadoop102',\n" +
" 'port'='3306',\n" +
" 'username'='root',\n" +
" 'password'='root',\n" +
" 'password'='root',\n" +
" 'database-name'='gmall-flink-200821',\n" +
" 'table-name'='z_user_info'\n" +
")";
tableEnv.executeSql(sourceSql);
tableEnv.executeSql("select * from user_info").print();
//3.执行程序
env.execute();
}
}
5.自定义反序列化器
参考:https://blog.csdn.net/qq_31866793/article/details/109207663
package com.flink.day07_flink_cdc;
import com.alibaba.fastjson.JSONObject;
import com.alibaba.ververica.cdc.connectors.mysql.MySQLSource;
import com.alibaba.ververica.cdc.debezium.DebeziumDeserializationSchema;
import com.alibaba.ververica.cdc.debezium.DebeziumSourceFunction;
import io.debezium.data.Envelope;
import org.apache.flink.api.common.typeinfo.BasicTypeInfo;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
import org.apache.kafka.connect.data.Field;
import org.apache.kafka.connect.data.Struct;
import org.apache.kafka.connect.source.SourceRecord;
import java.util.List;
import java.util.Properties;
/**
* @description: TODO Flink-CDC 自定义反序列化
* @author: HaoWu
* @create: 2021年05月24日
*/
public class Flink03_Flink_CDC_CustomerSchema {
public static void main(String[] args) throws Exception {
//1.创建执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
//2.创建 Flink-Mysql-CDC 的Source
Properties properties = new Properties();
//initial (default): Performs an initial snapshot on the monitored database tables upon first startup, and continue to read the latest binlog.
//latest-offset: Never to perform snapshot on the monitored database tables upon first startup, just read from the end of the binlog which means only have the changes since the connector was started.
//timestamp: Never to perform snapshot on the monitored database tables upon first startup, and directly read binlog from the specified timestamp. The consumer will traverse the binlog from the beginning and ignore change events whose timestamp is smaller than the specified timestamp.
//specific-offset: Never to perform snapshot on the monitored database tables upon first startup, and directly read binlog from the specified offset
properties.setProperty("debezium.snapshot.mode", "initial");
DebeziumSourceFunction<JSONObject> mysqlSource = MySQLSource
.<JSONObject>builder()
.hostname("hadoop102")
.port(3306)
.username("root")
.password("root")
.databaseList("gmall-flink-200821")
.tableList("gmall-flink-200821.z_user_info") //可选配置项,如果不指定该参数,则会读取上一个配置下的所有表的数据,注意:指定的时候需要使用"db.table"的方式
.debeziumProperties(properties)
.deserializer(new CdcDwdDeserializationSchema()) //自定义类解析cdc数据格式
.build();
//3.使用CDC Source从MySQL读取数据
DataStreamSource<JSONObject> mysqlDS = env.addSource(mysqlSource);
//4.打印数据
mysqlDS.print();
//5.执行任务
env.execute();
}
}
/**
* 自定义类,解析一下cdc的格式:test不支持delete
*/
class MyCustomSchema implements DebeziumDeserializationSchema<String>{//自定义数据解析器
@Override
public void deserialize(SourceRecord sourceRecord, Collector<String> collector) throws Exception {
//获取主题信息,包含着数据库和表名 mysql_binlog_source.gmall-flink-200821.z_user_info
String topic = sourceRecord.topic();
String[] arr = topic.split("\\.");
String db = arr[1];
String tableName = arr[2];
//获取操作类型 READ DELETE UPDATE CREATE ,注:导debezium.data包
Envelope.Operation operation = Envelope.operationFor(sourceRecord);
//获取值信息并转换为Struct类型,注:导kafka的包
Struct value = (Struct) sourceRecord.value();
//获取变化后的数据 ,注:导kafka的包
Struct after = value.getStruct("after");
//创建JSON对象用于存储数据信息
JSONObject data = new JSONObject();
for (Field field : after.schema().fields()) {
Object o = after.get(field);
data.put(field.name(), o);
}
//创建JSON对象用于封装最终返回值数据信息
JSONObject result = new JSONObject();
result.put("operation", operation.toString().toLowerCase());
result.put("data", data);
result.put("database", db);
result.put("table", tableName);
//发送数据至下游
collector.collect(result.toJSONString());
}
@Override
public TypeInformation<String> getProducedType() {
return TypeInformation.of(String.class);
}
}
/**
* 自定义类,解析一下cdc的格式,支持所有操作
*/
class CdcDwdDeserializationSchema implements DebeziumDeserializationSchema<JSONObject> {
private static final long serialVersionUID = -3168848963265670603L;
public CdcDwdDeserializationSchema() {
}
@Override
public void deserialize(SourceRecord record, Collector<JSONObject> out) throws Exception {
Struct dataRecord = (Struct)record.value();
Struct afterStruct = dataRecord.getStruct("after");
Struct beforeStruct = dataRecord.getStruct("before");
/*
todo 1,同时存在 beforeStruct 跟 afterStruct数据的话,就代表是update的数据
2,只存在 beforeStruct 就是delete数据
3,只存在 afterStruct数据 就是insert数据
*/
JSONObject logJson = new JSONObject();
String canal_type = "";
List<Field> fieldsList = null;
if(afterStruct !=null && beforeStruct !=null){
System.out.println("这是修改数据");
canal_type = "update";
fieldsList = afterStruct.schema().fields();
//todo 字段与值
for (Field field : fieldsList) {
String fieldName = field.name();
Object fieldValue = afterStruct.get(fieldName);
// System.out.println("*****fieldName=" + fieldName+",fieldValue="+fieldValue);
logJson.put(fieldName,fieldValue);
}
}else if (afterStruct !=null){
System.out.println( "这是新增数据");
canal_type = "insert";
fieldsList = afterStruct.schema().fields();
//todo 字段与值
for (Field field : fieldsList) {
String fieldName = field.name();
Object fieldValue = afterStruct.get(fieldName);
// System.out.println("*****fieldName=" + fieldName+",fieldValue="+fieldValue);
logJson.put(fieldName,fieldValue);
}
}else if (beforeStruct !=null){
System.out.println( "这是删除数据");
canal_type = "detele";
fieldsList = beforeStruct.schema().fields();
//todo 字段与值
for (Field field : fieldsList) {
String fieldName = field.name();
Object fieldValue = beforeStruct.get(fieldName);
// System.out.println("*****fieldName=" + fieldName+",fieldValue="+fieldValue);
logJson.put(fieldName,fieldValue);
}
}else {
System.out.println("一脸蒙蔽了");
}
//todo 拿到databases table信息
Struct source = dataRecord.getStruct("source");
Object db = source.get("db");
Object table = source.get("table");
Object ts_ms = source.get("ts_ms");
logJson.put("canal_database",db);
logJson.put("canal_database",table);
logJson.put("canal_ts",ts_ms);
logJson.put("canal_type",canal_type);
//todo 拿到topic
String topic = record.topic();
System.out.println("topic = " + topic);
//todo 主键字段
Struct pk = (Struct)record.key();
List<Field> pkFieldList = pk.schema().fields();
int partitionerNum = 0 ;
for (Field field : pkFieldList) {
Object pkValue= pk.get(field.name());
partitionerNum += pkValue.hashCode();
}
int hash = Math.abs(partitionerNum) % 3;
logJson.put("pk_hashcode",hash);
out.collect(logJson);
}
@Override
public TypeInformation<JSONObject> getProducedType() {
return BasicTypeInfo.of(JSONObject.class);
}
}
6.打包测试
1)打包并上传至Linux
2)开启MySQL Binlog并重启MySQL
3)启动Flink集群
bin/start-cluster.sh
4)启动HDFS集群
start-dfs.sh
5)启动程序
bin/flink run -c com.hadoop.FlinkCDC flink-200821-1.0-SNAPSHOT-jar-with-dependencies.jar
6)在MySQL的gmall-flink-200821.z_user_info表中添加、修改或者删除数据
7)给当前的Flink程序创建Savepoint
bin/flink savepoint JobId hdfs://hadoop102:8020/flink/save
8)关闭程序后,从savepoint重启程序
bin/flink run -s hdfs://hadoop102:8020/flink/save/... -c com.hadoop.FlinkCDC flink-200821-1.0-SNAPSHOT-jar-with-dependencies.jar
Fllin(七)【Flink CDC实践】的更多相关文章
- 开源大数据生态下的 Flink 应用实践
过去十年,面向整个数字时代的关键技术接踵而至,从被人们接受,到开始步入应用.大数据与计算作为时代的关键词已被广泛认知,算力的重要性日渐凸显并发展成为企业新的增长点.Apache Flink(以下简称 ...
- [.NET领域驱动设计实战系列]专题七:DDD实践案例:引入事件驱动与中间件机制来实现后台管理功能
一.引言 在当前的电子商务平台中,用户下完订单之后,然后店家会在后台看到客户下的订单,然后店家可以对客户的订单进行发货操作.此时客户会在自己的订单状态看到店家已经发货.从上面的业务逻辑可以看出,当用户 ...
- WEBGL学习笔记(七):实践练手1-飞行类小游戏之游戏控制
接上一节,游戏控制首先要解决的就是碰撞检测了 这里用到了学习笔记(三)射线检测的内容了 以鸟为射线原点,向前.上.下分别发射3个射线,射线的长度较短大概为10~30. 根据上一节场景的建设,我把y轴设 ...
- 流式处理新秀Flink原理与实践
随着大数据技术在各行各业的广泛应用,要求能对海量数据进行实时处理的需求越来越多,同时数据处理的业务逻辑也越来越复杂,传统的批处理方式和早期的流式处理框架也越来越难以在延迟性.吞吐量.容错能力以及使用便 ...
- 趣头条基于 Flink 的实时平台建设实践
本文由趣头条实时平台负责人席建刚分享趣头条实时平台的建设,整理者叶里君.文章将从平台的架构.Flink 现状,Flink 应用以及未来计划四部分分享. 一.平台架构 1.Flink 应用时间线 首先是 ...
- 企业实践 | 如何更好地使用 Apache Flink 解决数据计算问题?
业务数据的指数级扩张,数据处理的速度可不能跟不上业务发展的步伐.基于 Flink 的数据平台构建.运用 Flink 解决业务场景中的具体问题等随着 Flink 被更广泛的应用于广告.金融风控.实时 B ...
- [源码分析] 从源码入手看 Flink Watermark 之传播过程
[源码分析] 从源码入手看 Flink Watermark 之传播过程 0x00 摘要 本文将通过源码分析,带领大家熟悉Flink Watermark 之传播过程,顺便也可以对Flink整体逻辑有一个 ...
- 基于Apache Hudi 的CDC数据入湖
作者:李少锋 文章目录: 一.CDC背景介绍 二.CDC数据入湖 三.Hudi核心设计 四.Hudi未来规划 1. CDC背景介绍 首先我们介绍什么是CDC?CDC的全称是Change data Ca ...
- Apache Flink Quickstart
Apache Flink 是新一代的基于 Kappa 架构的流处理框架,近期底层部署结构基于 FLIP-6 做了大规模的调整,我们来看一下在新的版本(1.6-SNAPSHOT)下怎样从源码快速编译执行 ...
随机推荐
- 平分的直线 牛客网 程序员面试金典 C++ Python
平分的直线 牛客网 程序员面试金典 C++ Python 题目描述 在二维平面上,有两个正方形,请找出一条直线,能够将这两个正方形对半分.假定正方形的上下两条边与x轴平行. 给定两个vecotrA和B ...
- C#笔记2__Char类、String类、StringBuilder类 / 正则表达式 /
Char类 String类 字符串的格式化:String类的Format方法 StringBuilder类 以上:百度 or 查手册.....
- 面试题系列:用了这么多年的 Java 泛型,我竟然只知道它的皮毛
面试题:说说你对泛型的理解? 面试考察点 考察目的:了解求职者对于Java基础知识的掌握程度. 考察范围:工作1-3年的Java程序员. 背景知识 Java中的泛型,是JDK5引入的一个新特性. 它主 ...
- laravel路由导出和参数加密
路由导出 代码位置:\vendor\laravel\framework\src\Illuminate\Foundation\Console\RouteListCommand.php protected ...
- 使用Netty和动态代理实现一个简单的RPC
RPC(remote procedure call)远程过程调用 RPC是为了在分布式应用中,两台主机的Java进程进行通信,当A主机调用B主机的方法时,过程简洁,就像是调用自己进程里的方法一样.RP ...
- 【java+selenium3】多窗口window切换及句柄handle获取(四)
一 .页面准备 1.html <html> <head> <title>主页面 1</title> </head> <body> ...
- 攻防世界 WEB 高手进阶区 tinyctf-2014 NaNNaNNaNNaN-Batman Writeup
攻防世界 WEB 高手进阶区 tinyctf-2014 NaNNaNNaNNaN-Batman Writeup 题目介绍 题目考点 了解js代码(eval函数.splice函数) 了解正则 Write ...
- 什么?还在用delete删除数据《死磕MySQL系列 九》
系列文章 五.如何选择普通索引和唯一索引<死磕MySQL系列 五> 六.五分钟,让你明白MySQL是怎么选择索引<死磕MySQL系列 六> 七.字符串可以这样加索引,你知吗?& ...
- R数据分析:二分类因变量的混合效应,多水平logistics模型介绍
今天给大家写广义混合效应模型Generalised Linear Random Intercept Model的第一部分 ,混合效应logistics回归模型,这个和线性混合效应模型一样也有好几个叫法 ...
- Linux(kali)基础设置
本笔记的友情链接 常用目录介绍 boot 存放启动文件 dev 存放设备文件 etc 存放配置文件 home 普通用户家目录,以/home/$username的方式存放 media 移动存储自动挂载目 ...