Hive语法及其进阶(一)
1、Hive完整建表
1 CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name(
2 [(col_name data_type [COMMENT col_comment], ...)]
3 )
4 [COMMENT table_comment]
5 [PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)]
6 [CLUSTERED BY (col_name, col_name, ...)
7 [SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS]
8 [
9 [ROW FORMAT row_format]
10 [STORED AS file_format]
11 | STORED BY 'storage.handler.class.name' [ WITH SERDEPROPERTIES (...) ] (Note: only available starting with 0.6.0)
12 ]
13 [LOCATION hdfs_path]
14 [TBLPROPERTIES (property_name=property_value, ...)] (Note: only available starting with 0.6.0)
15 [AS select_statement] (Note: this feature is only available starting with 0.5.0.)
注意:
[]:表示可选
EXTERNAL:外部表
(col_name data_type [COMMENT col_comment],...:定义字段名,字段类型
COMMENT col_comment:给字段加上注释
COMMENT table_comment:给表加上注释
PARTITIONED BY (col_name data_type [COMMENT col_comment],...):分区 分区字段注释
CLUSTERED BY (col_name, col_name,...):分桶
SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS:设置排序字段 升序、降序
ROW FORMAT row_format:指定设置行、列分隔符(默认行分隔符为\n)
STORED AS file_format:指定Hive储存格式:textFile、rcFile、SequenceFile 默认为:textFile
LOCATION hdfs_path:指定储存位置(默认位置在hive.warehouse目录下)
TBLPROPERTIES (property_name=property_value, ...):跟外部表配合使用,比如:映射HBase表,然后可以使用HQL对hbase数据进行查询,当然速度比较慢
AS select_statement:从别的表中加载数据 select_statement=sql语句
2、使用默认方式建表
1 create table students01
2 (
3 id bigint,
4 name string,
5 age int,
6 gender string,
7 clazz string
8 )
9 ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';
注意:
分割符不指定,默认不分割
通常指定列分隔符,如果字段只有一列可以不指定分割符:
ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';
3、建表2:指定location
1 create table students02
2 (
3 id bigint,
4 name string,
5 age int,
6 gender string,
7 clazz string
8 )
9 ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
10 LOCATION 'data';

4、建表3:指定存储格式
1 create table student_rc
2 (
3 id bigint,
4 name string,
5 age int,
6 gender string,
7 clazz string
8 )
9 ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
10 STORED AS rcfile;
注意:
指定储存格式为rcfile,inputFormat:RCFileInputFormat,outputFormat:RCFileOutputFormat,如果不指定,默认为textfile
注意:
除textfile以外,其他的存储格式的数据都不能直接加载,需要使用从表加载的方式。



5、建表4:从其他表中加载数据
格式:
create table xxxx as select_statement(SQL语句) (这种方式比较常用)
例子:
create table students4 as select * from students2;

6、建表5:从其他表中获取表结构
格式:
create table xxxx like table_name 只想建表,不需要加载数据
例子:
create table student04 like students;

7.Hive加载数据
1、使用```hadoop dfs -put '本地数据' 'hive表对应的HDFS目录下

2、使用 load data inpath(是对hdfs的文件移动,移动,移动,不是复制)
3、使用load data local inpath(经常使用,从本地文件中上传)

// overwrite 覆盖加载
// 实际上就是hadoop执行了rmr然后put操作
例如:load data local inpath'/usr/local/data/students.txt' overwrite into table student01;

方式1和方式2的区别:
1.上传数据到hdfs目录和hive表没有任何关系(不需要数据格式进行匹配,hive读取数据还是需要数据格式的匹配)
2.上传数据到hive表和hive表有关系(需要数据格式进行匹配)
8. 清空表
truncate table student01;
注意: 清空代表清空数据,不是删除表

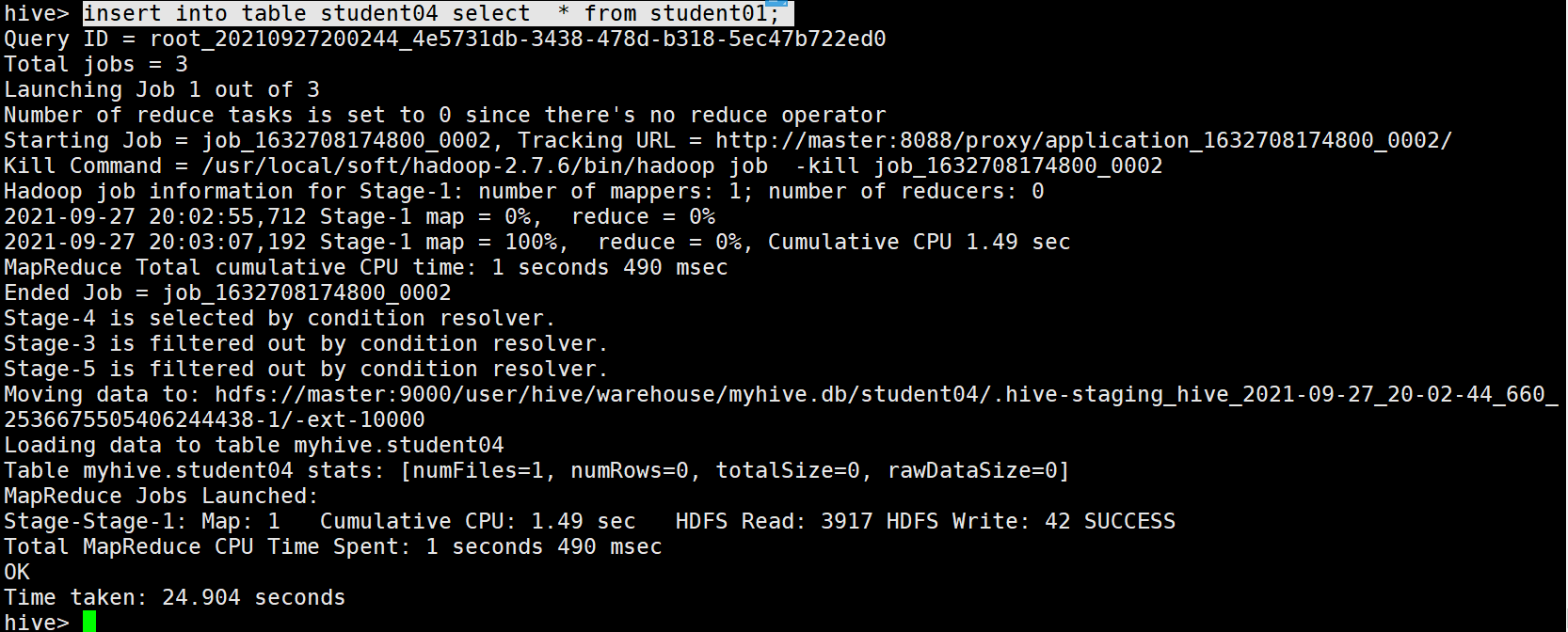
11. insert into table xxxx SQL语句 (没有as) 传输给别的格式的hive table
例如:
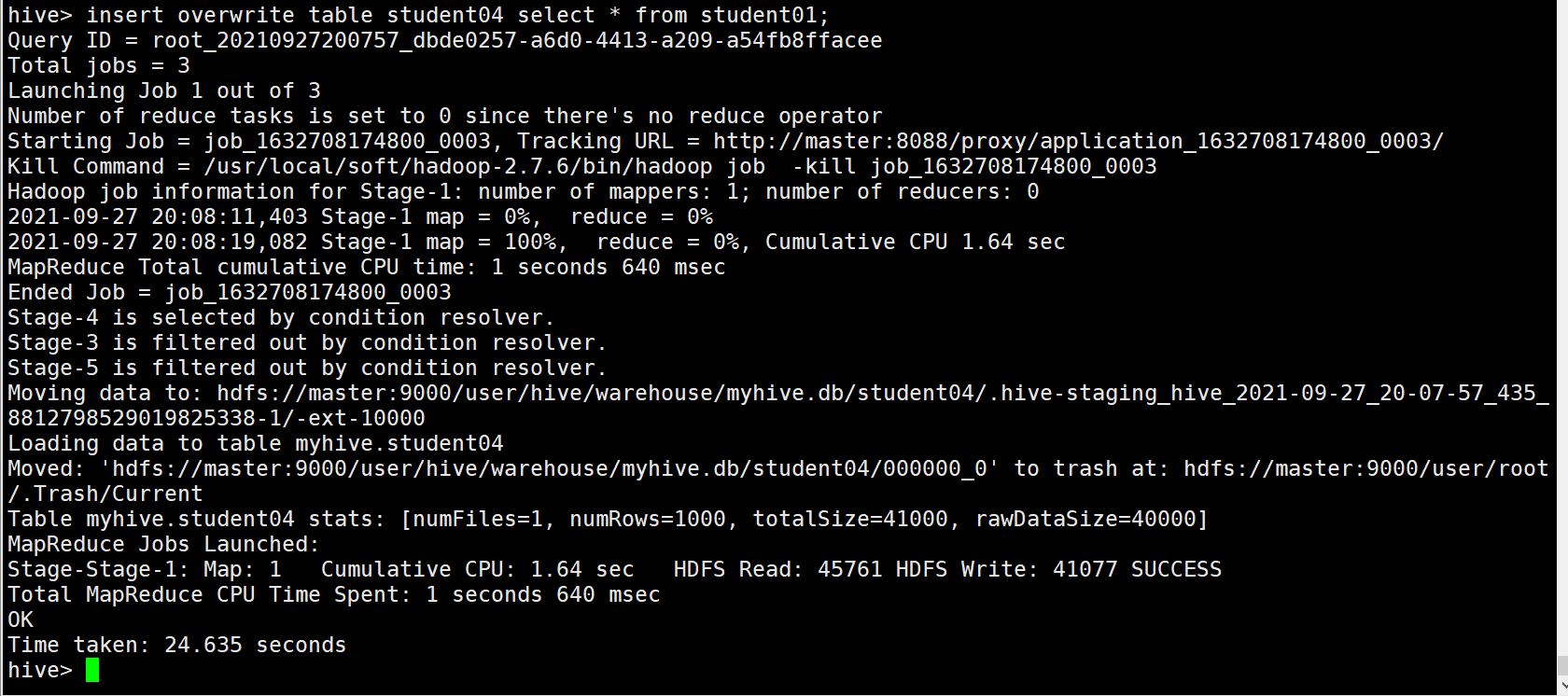
insert into table student04 select * from student01;
覆盖插入 把into 换成 overwrite
例如:
insert overwrite table student04 select * from student01;
9、Hive 内部表(Managed tables)vs 外部表(External tables)
区别:
内部表删除数据跟着删除
外部表只会删除表结构,数据依然存在
注意:
公司中实际应用场景为外部表,为了避免表意外删除数据也丢失
不能通过路径来判断是目录还是hive表(是内部表还是外部表)
建表:
1 内部表
2 create table students_managed01
3 (
4 id bigint,
5 name string,
6 age int,
7 gender string,
8 clazz string
9 )
10 ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';

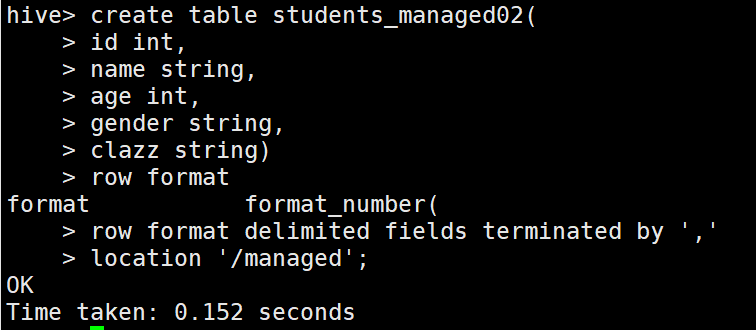
1 //内部表指定location
2 create table students_managed02
3 (
4 id bigint,
5 name string,
6 age int,
7 gender string,
8 clazz string
9 )
10 ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
11 LOCATION '/managed';
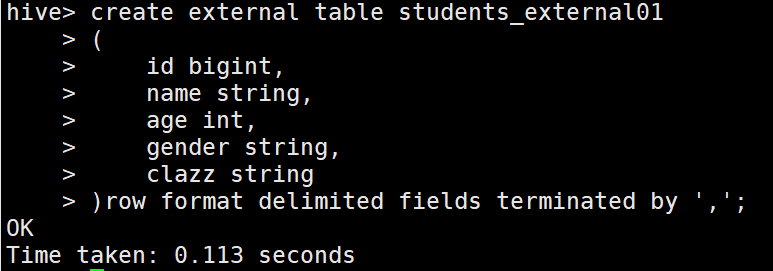
1 // 外部表
2 create external table students_external01
3 (
4 id bigint,
5 name string,
6 age int,
7 gender string,
8 clazz string
9 )
10 ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';
1 // 外部表指定location
2 create external table students_external02
3 (
4 id bigint,
5 name string,
6 age int,
7 gender string,
8 clazz string
9 )
10 ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';
11 LOCATION '/external';

上传数据:
hive> load data local inpath '/usr/local/data/students.txt'into table students_managed01;hive> load data local inpath '/usr/local/data/students.txt'into table students_managed02;
hive> load data local inpath '/usr/local/data/students.txt'into table students_external01;hive> load data local inpath '/usr/local/data/students.txt'into table students_external02;

删除数据:
hive> drop table students_managed01;
hive> drop table students_managed02;
hive> drop table students_external01;
hive> drop table students_external02;
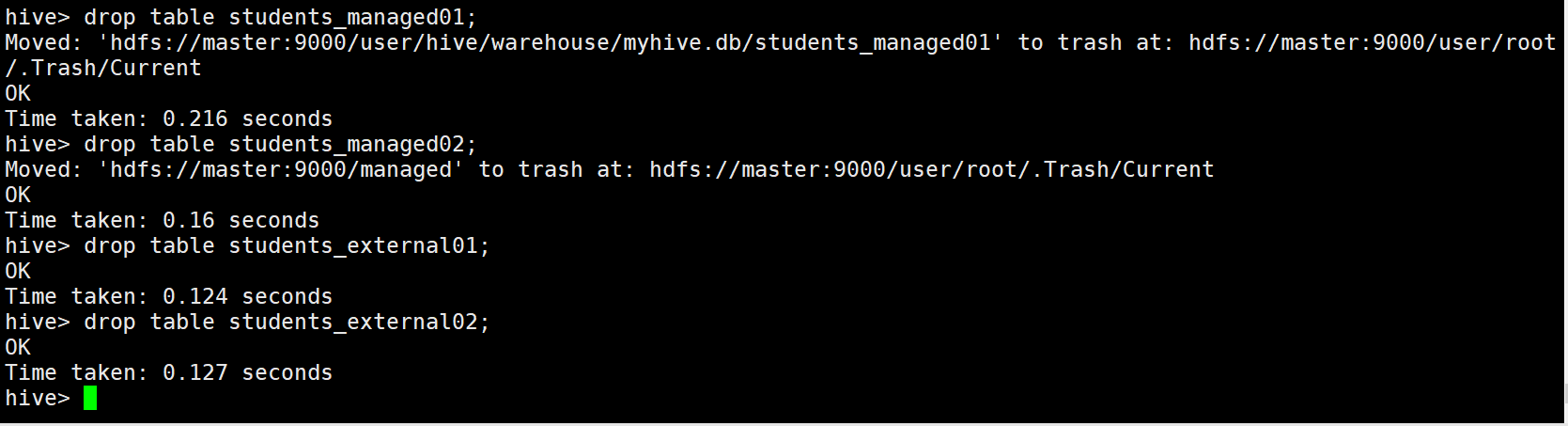
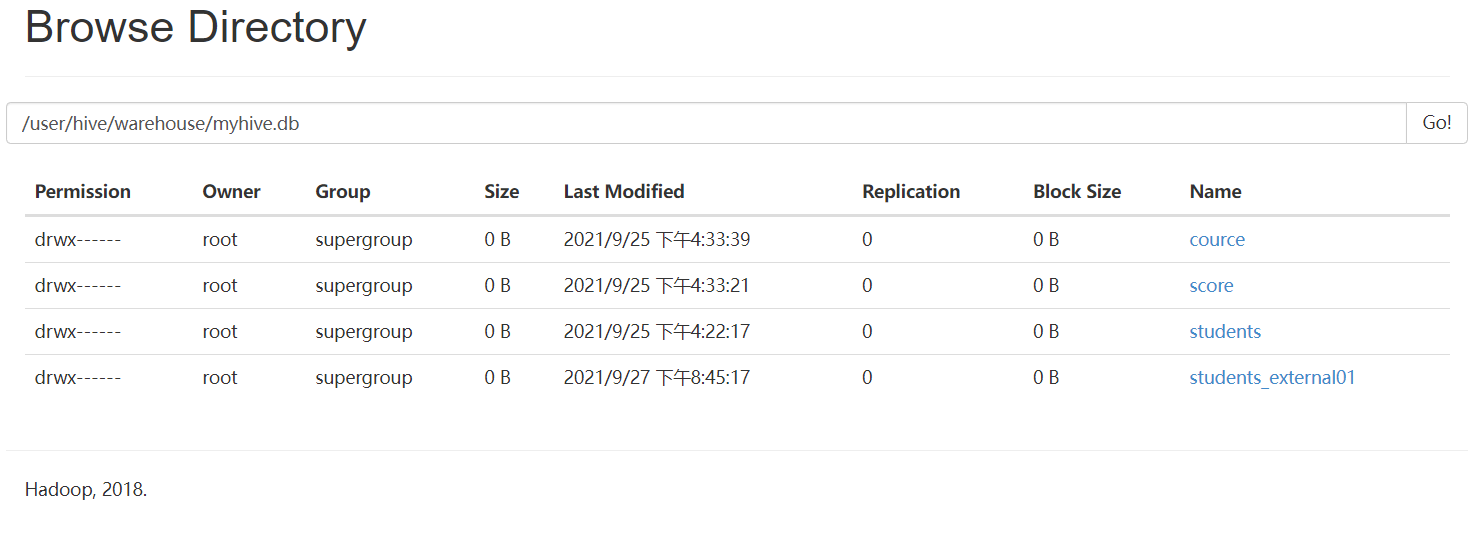
外部表与内部表总结:
可以看出,删除内部表的时候,表中的数据(HDFS上的文件)会被同表的元数据一起删除
删除外部表的时候,只会删除表的元数据,不会删除表中的数据(HDFS上的文件)
一般在公司中,使用外部表多一点,因为数据可以需要被多个程序使用,避免误删,通常外部表会结合location一起使用
外部表还可以将其他数据源中的数据 映射到 hive中,比如说:hbase,ElasticSearch......
设计外部表的初衷就是 让 表的元数据 与 数据 解耦
10、Hive建立分区表
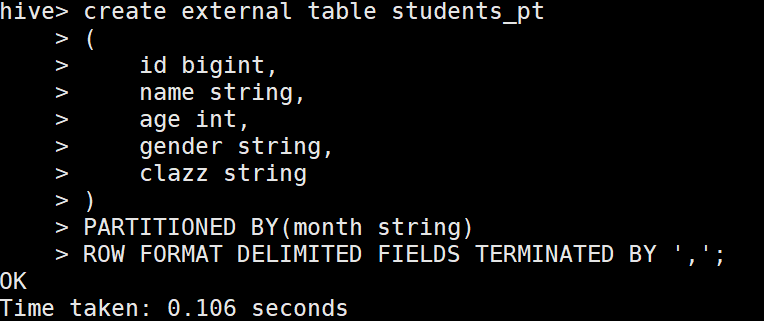
1.创建单级分区
1 create table students_pt
2 (
3 id bigint,
4 name string,
5 age int,
6 gender string,
7 clazz string
8 )
9 PARTITIONED BY(month string)
10 ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';
2.加载数据
load data local inpath '/usr/local/data/students.txt' into table students_pt partition(month='2021-09-26');

3.分区查询
单分区查询
select * from students_pt where month='2021-09-26';
多分区查询
select * from students_pt where month='2021-09-26'or month='2021-09-24';
4.增加分区
创建单个分区
alter table students_pt add partition(month='2021-09-25');

创建多个分区
alter table students_pt add partition(month='2021-09-23') partition(month='2021-09-24');(注意中间没有逗号分割)

5.删除分区
删除单个分区
alter table students_pt drop partition(month='2021-09-23');

删除多个分区
alter table students_pt drop partition(month='2021-09-24'),partition(month='2021-09-25'); (注意中间有逗号分割)

6.查看分区表分区
show partitions students_pt;

7.查看分区表结构
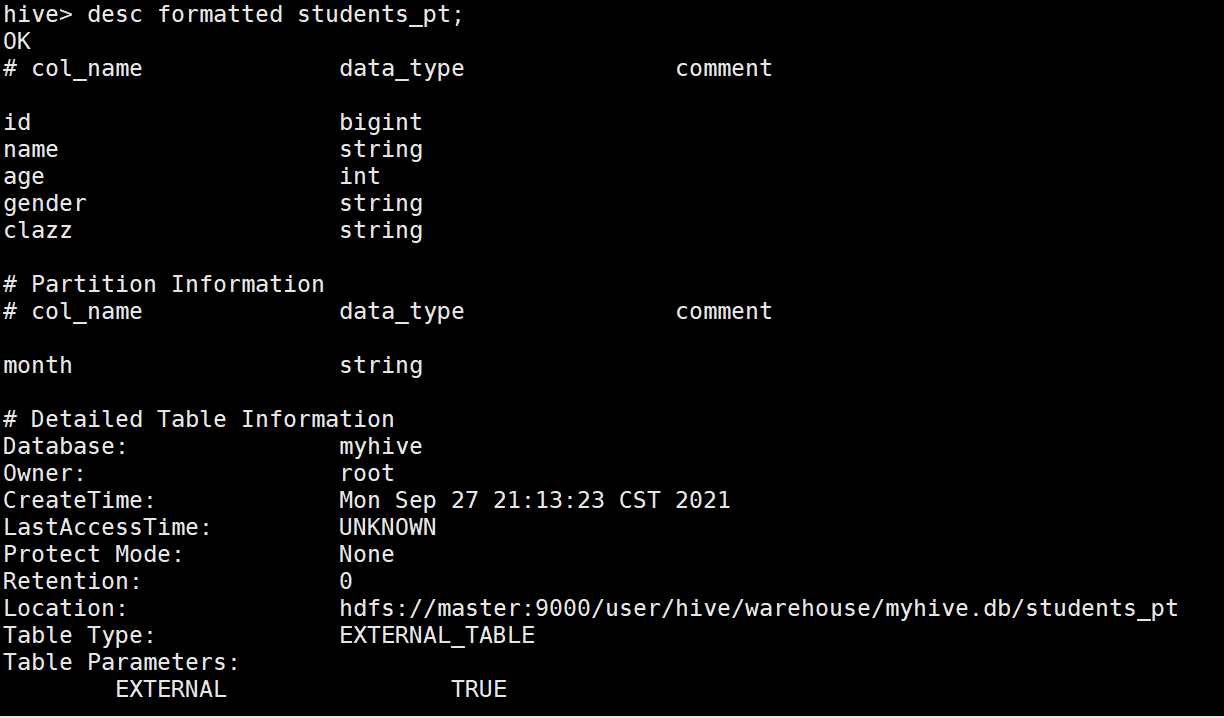
desc formatted students_pt;
Hive语法及其进阶(一)的更多相关文章
- Hive语法及其进阶(二)
1.使用JDBC连接Hive 1 import java.sql.Connection; 2 import java.sql.DriverManager; 3 import java.sql.Prep ...
- Vim技能修炼教程(3) - 语法高亮进阶
语法高亮进阶 首先我们复习一下上节学到的三个命令: * syntax match用于定义正则表达式和规则的对应 * highlight default定义配色方案 * highlight link将正 ...
- Hive语法
1.Select 语法 SELECT [ALL | DISTINCT] select_expr, select_expr, ... FROM table_reference [WHERE where_ ...
- 一脸懵逼学习Hive的使用以及常用语法(Hive语法即Hql语法)
Hive官网(HQL)语法手册(英文版):https://cwiki.apache.org/confluence/display/Hive/LanguageManual Hive的数据存储 1.Hiv ...
- 大数据学习(09)—— Hive语法
Hive官方网站上有详细的语法说明,参考LanguageManual. 这里我把最常用的几块列出来. HIVE DDL Database 建库语句 CREATE (DATABASE|SCHEMA) [ ...
- [数据库] SQL 语法之进阶篇
一.创建计算字段 下面介绍什么是计算字段,如何创建计算字段,以及如何从应用程序中使用别名引用它们. 1.1 计算字段 存储在数据库表中的数据一般不是应用程序所需要的格式,下面举几个例子. 需要显示公司 ...
- 大数据之路week07--day07 (Hive结构设计以及Hive语法)
Hive架构流程(十分重要,结合图进行记忆理解)当客户端提交请求,它先提交到Driver,Driver拿到这个请求后,先把表明,字段名拿出来,去数据库进行元数据验证,也就是Metasore,如果有,返 ...
- Hive语法小释
阅读本文你可以获取: 1.数据库的查询 2.hive表的基本操作(建表三种常用方式.删除表.修改表.加载数据.内外表转换.添加分区.复制数据) 3.SQL到HiveQL的的一些不同点 1. 基本操 ...
- hive 语法 case when 语法
' then '精选' else null end as sale_type 注意: end不能少
随机推荐
- 在npm Vue单页面的环境下,兄弟组件之间通信Bus
参考1:https://www.cnblogs.com/wangruifang/p/7772631.html 参考2:https://www.jianshu.com/p/b3d09c6c87bf 在m ...
- uwp 之吐司 toast
Toast -------------------------------------------------------------- var t = Windows.UI.Notification ...
- 【小技巧】java的List分页
今天,工作上,由于业务的一些特殊性,需要拿到数据后在java代码中进行分页. 写了一个工具类,记录如下: import java.util.ArrayList; import java.util.Li ...
- Git脑图
ps:有时我们想一台有不同的git账号对应不同的git仓库时(gitLab/gitHub)时,除了全局的用户配置定义,我们可以为不同仓库自定义不同用户名和邮件 1.查询全局的配置:git config ...
- 【Python机器学习实战】决策树与集成学习(三)——集成学习(1)
前面介绍了决策树的相关原理和实现,其实集成学习并非是由决策树演变而来,之所以从决策树引申至集成学习是因为常见的一些集成学习算法与决策树有关比如随机森林.GBDT以及GBDT的升华版Xgboost都是以 ...
- C# - 习题01_写出程序的输出结果a.Fun2(b)、b.Fun2(a)
时间:2017-08-23 整理:byzqy 题目:请写出下列程式的结果: 文件:A.cs 1 using System; 2 3 namespace InterView 4 { 5 public c ...
- Qt5中用QLCDNumber显示时间
编程中经常要用到时间的显示,因此在这总结一下在Qt中如何显示时间.废话不多说,直接上代码,简单明了,一看就懂~~ mydialog.h 文件 #ifndef MYDIALOG_H #define MY ...
- 解决->maven下载失败bug
一.前言: 经过一个下午的奋斗(谷歌,视频...重装)后终,于暂时解决了上一篇文章中的bug 传送门:https://blog.csdn.net/weixin_44092288/article/det ...
- etcd学习(8)-etcd中Lease的续期
etcd中的Lease 前言 Lease Lease 整体架构 key 如何关联 Lease Lease的续期 过期 Lease 的删除 checkpoint 机制 总结 参考 etcd中的Lease ...
- Django——Paginator分页功能练习
1.路由urls.py from django.contrib import admin from django.urls import path from app01.views import in ...