Python爬虫 小白[3天]入门笔记
Day-0
1.如果你还不了解Python的基础语法,可以移步|>>>Python 基础 小白 [7天] 入门笔记<<<|或自行学习。
简介
1.什么是爬虫?
网络爬虫(又称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。2.实质
模拟浏览器向服务器发送请求,把得到的数据拆分筛选后保存。3.写爬虫程序的一般步骤
准备工作->获取数据->解析内容->保存数据
2.爬虫实例
U[爬取豆瓣Top250电影信息]
A[main主函数]
A -->B[1.爬取网页函数]
A -->D[2.解析数据函数]
A -->E[3.保存数据函数]
B -->f(del askURL)
D -->g(del getdata)
E -->h(del savedata)
f -->|参数|i(跳转网址url)
g -->|参数|j(基础网址baseurl)
h -->|参数|k(datalist,savepath)
i -->|功能|o(伪装浏览器请求访问指定的url,返回得到的html原码)
j -->|功能|p(按正则表达式等匹配拆分筛选html原码,返回筛选结果)
k -->|功能|q(把解析结果datalist写入指定路径savapath的文件中)
Day-1
Url访问请求模拟
#-*- codeing = utf-8 -*-
#@Time : 2020/7/12 20:27
#@Author : HUGBOY
#@File : hello_urllib.py
#@Software: PyCharm
#Urllib
'''----------------------|简介|------------------
1.urllib原理
2.模拟浏览器请求/get/post
----------------------------------------------'''
import urllib.request
#get请求
'''
response = urllib.request.urlopen("http://www.baidu.com")
print(response.read().decode('utf-8'))
#response为一个对象/read()读取内容/decode('utf-8')中文编码
'''
#post请求(需要传入参数/hello : word)
'''
import urllib.parse
thedata = bytes(urllib.parse.urlencode({"hello":"word"}),encoding="utf-8")#转换为二进制数据包
response = urllib.request.urlopen("http://httpbin.org/post",data = thedata)
print(response.read().decode("utf-8"))
'''
#请求超时(多少秒内是否有返回)
'''
import urllib.parse
try:
response = urllib.request.urlopen("http://httpbin.org/get",timeout=0.01)
print(response.read().decode("utf-8"))
except Exception as rel:
print("呀!请求超时啦,被发现了")
print(rel)
'''
#访问状态
'''
import urllib.parse
response = urllib.request.urlopen("http://baidu.com/get",timeout=5)
#print(response.status)#返回状态码/200正常返回/418我是一个茶壶爬虫被发现了/404找不到
#print(response.getheaders())#获取请求头中的所有内容
print(response.getheader("Server"))#获得指定内容
'''
#伪装浏览器-测试(防止418)
'''
import urllib.parse
url = "http://httpbin.org/post"
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:78.0) Gecko/20100101 Firefox/78.0"}
data = bytes(urllib.parse.urlencode({'name':'hugboy'}),encoding="utf-8")
req = urllib.request.Request(url=url,data=data,headers=headers,method="POST")
response = urllib.request.urlopen(req)
print(response.read().decode("utf-8"))
'''
#伪装浏览器-实战(防止418)
import urllib.parse
url = "http://www.douban.com"
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:78.0) Gecko/20100101 Firefox/78.0"}
req = urllib.request.Request(url=url,headers=headers)
response = urllib.request.urlopen(req)
print(response.read().decode("utf-8"))
re正则表达式
#-*- codeing = utf-8 -*-
#@Time : 2020/7/13 9:41
#@Author : HUGBOY
#@File : hello_re.py
#@Software: PyCharm
'''-------------简介-----------------
正则表达式
1.re
2.sub
----------------------------------'''
#正则表达式
#re
import re
print("创建模式对象")
pat = re.compile("aa")#标准
r = pat.search("aa123aabc")#校验
print(r)
#<re.Match object; span=(0, 2), match='aa'> search查找只匹配第一个
print("无需创建对象")
r = re.search(".com","www.heihei.com")#"标准","数据"
print(r)
print("找到并输出")
print(re.findall("a","a site named www.heihei.com hahahha"))
print(re.findall("[A-Z]","HugBoy"))
print(re.findall("[a-z]+","HugBoy"))
#sub
print("找到a用A替换")
print(re.sub("a","A","I am a vactory man!"))
print("抵消转译")
a = r"\n 'abc\'"
print(a)
Day-2
bs4树形结构查询
#-*- codeing = utf-8 -*-
#@Time : 2020/7/12 22:25
#@Author : HUGBOY
#@File : hello_bs4.py
#@Software: PyCharm
'''----------------------|简介|------------------
1.将复杂的HTML文档转换成一个复杂的树形结构,
每个节点都是Python对象,所有对象都可以归纳为4中
BeautifulSoup4
- Tag
- NavigableString
- BeautifulSoup
- Comment
2.遍历,搜索,css选择器
----------------------------------------------'''
from bs4 import BeautifulSoup
f = open("./baidu.html","rb")#文件内容见 [附:day-2|baidu.html]
html = f.read()
rel = BeautifulSoup(html,"html.parser")#把html解析为树形结构
print("- Tag 标签及其内容(只拿到匹配到的第一个标签)")
#网页中的title <title>百度一下,你就知道 </title>
print(rel.title)
#网页中的超链接a <a class="mnav" href="http://news.baidu.com" name="tj_trnews"><!--新闻--></a>
print(rel.a)
print(type(rel.a))#<class 'bs4.element.Tag'>
print("- NavigableString 标签里的内容(字符串)")
print(rel.title.string)
print(rel.a.string)
print(rel.a.attrs)#字典形式-一个标签内所有属性
print("- BeautifulSoup 整个为文档")
print(type(rel))#运行结果 <class 'bs4.BeautifulSoup'>
print(rel)
print("- Comment 注释符号里的内容")
#<a class="mnav" href="http://news.baidu.com" name="tj_trnews"><!--新闻--></a>
print(rel.a.string)
print(type(rel.a.string))#运行结果 <class 'bs4.element.Comment'>
#遍历文档
print("标签里的内容,按列表格式取出")
print(rel.head.contents)
print("列表元素")
print(rel.head.contents[1])
#*搜索文档
#1
print(" find_all()字符串过滤:查找与字符串完全匹配的内容")
t_list = rel.find_all("a")
print(t_list)
print("search() 正则表达式")
import re
t_list = rel.find_all(re.compile("a"))#所有标签中含'a'字母的标签及其字内容
print(t_list)
print("根据传入的函数要求搜索/搜索有name属性的标签")
def name_is(tag):
return tag.has_attr("name")
t_list = rel.find_all(name_is)
print(t_list)
print("优雅的打印下,哈哈哈")
for one in t_list:
print(one)
#2
print("含参数")
t_list = rel.find_all(id = "head")
for one in t_list:
print(one)
print("有class")
t_list = rel.find_all(class_ = True)
for one in t_list:
print(one)
print("指定某个")
t_list = rel.find_all(href="http://map.baidu.com")
for one in t_list:
print(one)
#3
print("text参数")
#t_list = rel.find_all(text = "hao123")
t_list = rel.find_all(text = ["hao123","地图","贴吧","有吗"])
for one in t_list:
print(one)
print("正则表达式查包含特定文本内容(标签里的字符串)/如查所有含数字的")
t_list = rel.find_all(text = re.compile("\d"))
for one in t_list:
print(one)
print("limit限定个数")
t_list = rel.find_all("a",limit=3)
for one in t_list:
print(one)
#css选择器
print("通过标签查照")
t_list = rel.select('title')
for one in t_list:
print(one)
print("通过类名照")
t_list = rel.select(".mnav")
for one in t_list:
print(one)
print("通过id查找")
t_list = rel.select("#u1")
for one in t_list:
print(one)
print("通过属性值查找")
t_list = rel.select("a[class='bri']")
for one in t_list:
print(one)
print("查找head里的title(通过子标签)")
t_list = rel.select("head>title")
for one in t_list:
print(one)
print("查找兄弟标签(与某标签同级标签)")
t_list = rel.select(".mnav ~ .bri")
for one in t_list:
print(one)
print("获得其中的文本")
print(t_list[0].get_text())
[附:day-2|baidu.html]
<!DOCTYPE html>
<html>
<head>
<meta content="text/html;charset=utf-8" http-equiv="content-type" />
<meta content="IE=Edge" http-equiv="X-UA-Compatible" />
<meta content="always" name="referrer" />
<link href="https://ss1.bdstatic.com/5eN1bjq8AAUYm2zgoY3K/r/www/cache/bdorz/baidu.min.css" rel="stylesheet" type="text/css" />
<title>百度一下,你就知道 </title>
</head>
<body link="#0000cc">
<div id="wrapper">
<div id="head">
<div class="head_wrapper">
<div id="u1">
<a class="mnav" href="http://news.baidu.com" name="tj_trnews"><!--新闻123--></a>
<a class="mnav" href="http://news.baidu.com" name="tj_trnews">新闻1</a>
<a class="mnav" href="https://www.hao123.com" name="tj_trhao123">hao123</a>
<a class="mnav" href="http://map.bai521314du.com" name="tj_trmap">地图</a>
<a class="mnav" href="http://v.baidu.com" name="tj_trvideo">视频</a>
<a class="mnav" href="http://tieba.baidu.com" name="tj_trtieba">贴吧</a>
<a class="bri" href="//www.baidu.com/more/" name="tj_briicon" style="display: block;">更多产品 </a>
</div>
</div>
</div>
</div>
</body>
</html>
Day-3
爬取豆瓣电影Top250数据
爬取效果
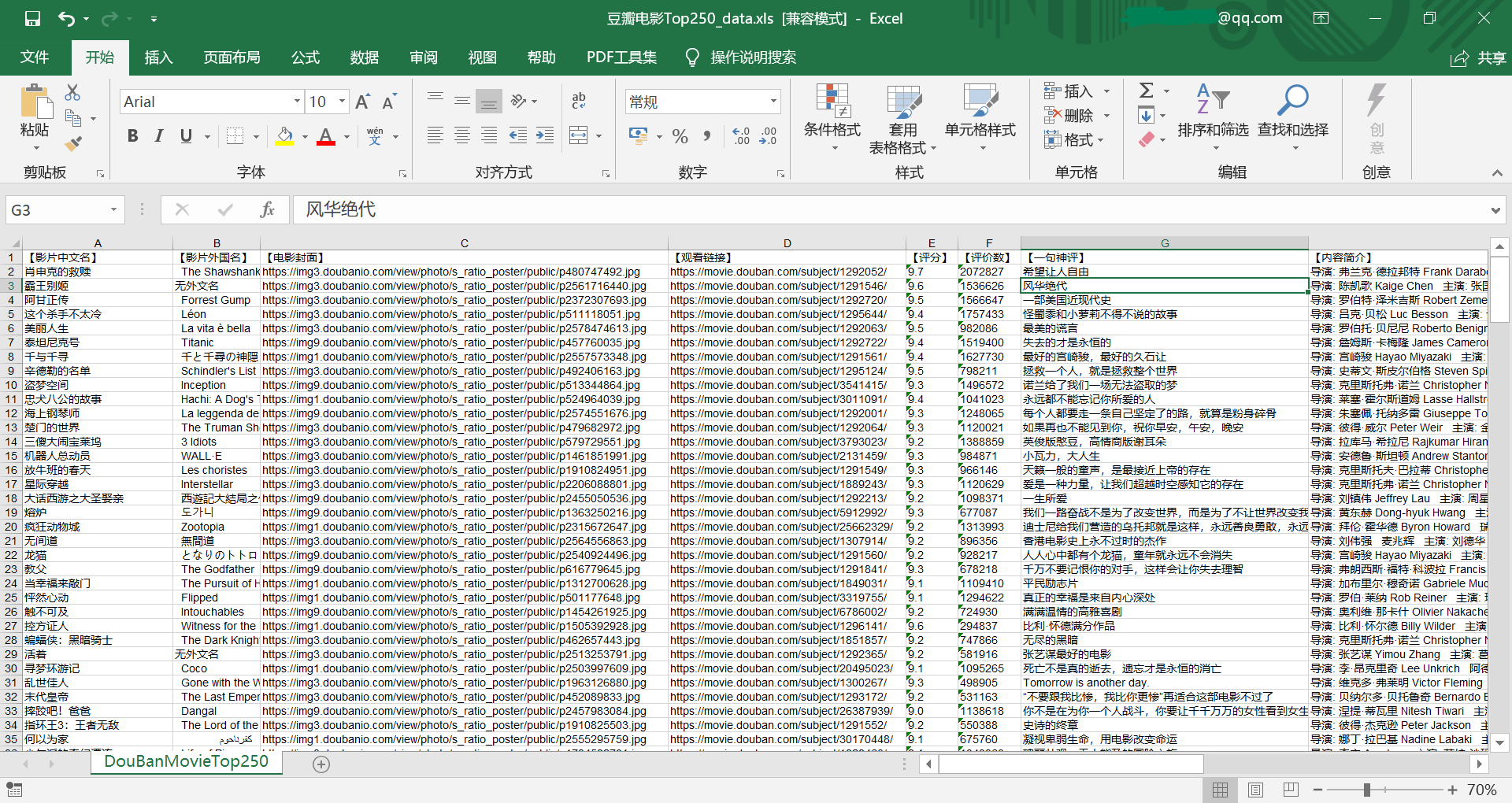
[源代码]
本例在Excel保存数据,另|>>>附:Python 爬虫 数据库保存数据<<<|
# -*- codeing = utf-8 -*-
# @Time : 2020/7/12 19:11
# @Author : HUGBOY
# @File : sp_douban.py
# @Software: PyCharm
'''----------------------|简介|------------------
#爬虫
#爬取豆瓣TOP250电影数据
#1.爬取网页
#2.逐一解析数据
#3.保存数据(xlwt|sqlite)
----------------------------------------------'''
from bs4 import BeautifulSoup # 网页解析、获取数据
import re # 正则表达式
import urllib.request, urllib.error # 指定URL、获取网页数据
import random
import xlwt # 存到excel的操作 详见[附:day-3|xlwt]
import sqlite3 # 存到数据库操作
def main():
baseurl = "https://movie.douban.com/top250/?start="
datalist = getdata(baseurl)
savepath = ".\\豆瓣电影Top250_data.xls"
savedata(datalist,savepath)
# 正则表达式匹配规则
findTitle = re.compile(r'<span class="title">(.*)</span>') # 影片片名
findR = re.compile(r'<span class="inq">(.*)</span>') # 一句话评
findRating = re.compile(r'<span class="rating_num" property="v:average">(.*)</span>') # 影片评分
findPeople = re.compile(r'<span>(\d*)人评价</span>') # 影评人数-/d 代表数字
findLink = re.compile(r'<a href="(.*?)">') # 影片链接
findImg = re.compile(r'<img.*src="(.*?)"', re.S) # 影片图片-re.S 允许.中含换行符
findBd = re.compile(r'<p class="">(.*?)</p>', re.S) # 影片简介
def getdata(baseurl):
datalist = []
for i in range(0, 10): # 调用获取页面信息的函数*10次
url = baseurl + str(i * 25)
html = askURL(url) # 保存获取到的网页原码
# 解析网页
soup = BeautifulSoup(html, "html.parser")
for item in soup.find_all('div', class_="item"):
# print(item) #一部电影的所有信息
data = []
item = str(item)
# 提取影片详细信息
title = re.findall(findTitle, item)
if (len(title) == 2):
ctitle = title[0] # 中文名
data.append(ctitle)
otitle = title[1].replace("/", "") # 外文名-去掉'/'和""
data.append(otitle)
else:
data.append(title[0])
data.append("无外文名")
img = re.findall(findImg, item)[0]
data.append(img)
link = re.findall(findLink, item)[0] # re库:正则表达式找指定字符串
data.append(link)
rating = re.findall(findRating, item)[0]
data.append(rating)
people = re.findall(findPeople, item)[0]
data.append(people)
r = re.findall(findR, item)
if len(r) != 0:
r = r[0].replace("。", "")
data.append(r)
else:
data.append("无一句评")
bd = re.findall(findBd, item)[0]
bd = re.sub('<br(\s+)?/>(\s+)?', " ", bd) # 替换</br>
bd = re.sub('/', " ", bd) # 替换/
data.append(bd.strip()) # 去掉空格
datalist.append(data) # 把一部电影信息存储
print(datalist)
return datalist
# 得到指定Url网页内容
def askURL(url):
head = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:78.0) Gecko/20100101 Firefox/78.0"}
request = urllib.request.Request(url, headers=head)
html = ""
try:
response = urllib.request.urlopen(request)
html = response.read().decode("utf-8")
#print(html) 测试
except Exception as rel:
if hasattr(rel, "code"):
print(rel.code)
if hasattr(rel, "reason"):
print(rel.reason)
return html
def savedata(datalist,savepath):
book = xlwt.Workbook(encoding="utf-8",style_compression=0)#样式压缩效果
sheet = book.add_sheet('DouBanMovieTop250',cell_overwrite_ok=True)#覆盖写
col = ("【影片中文名】","【影片外国名】","【电影封面】","【观看链接】","【评分】","【评价数】","【一句神评】","【内容简介】")
for i in range(0,8):
sheet.write(0,i,col[i])#表头名
for i in range(0,250):
print("正在写入第%d条..."%(i+1))
data = datalist[i]
for k in range(0,8):
sheet.write(i+1,k,data[k])
print("正在保存...")
book.save(savepath)
if __name__ == "__main__":
main()
print("爬取完成,奥利给!")
[附:day-3|xlwt]保存在Excel
运行效果
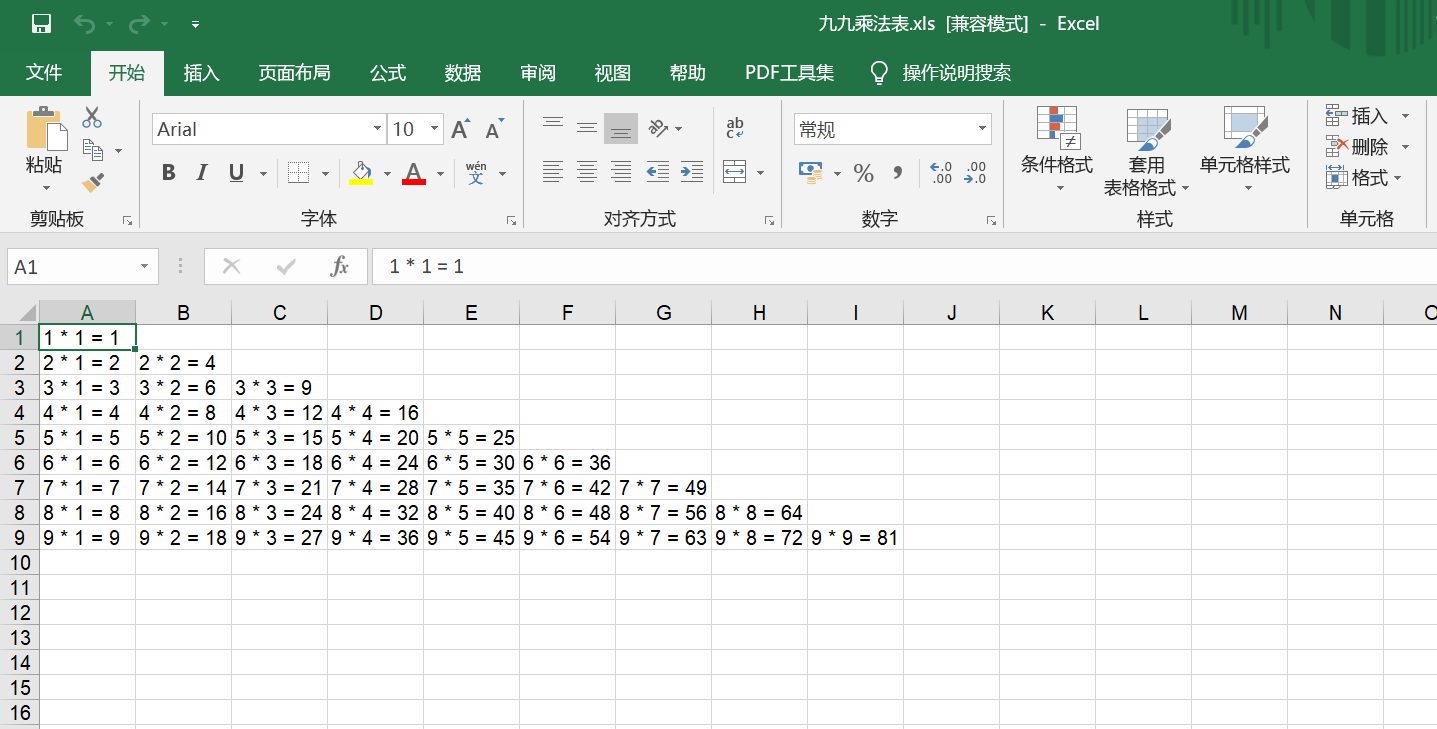
#-*- codeing = utf-8 -*-
#@Time : 2020/7/13 14:48
#@Author : HUGBOY
#@File : hello_xlwt.py
#@Software: PyCharm
'''
import xlwt
workbook = xlwt.Workbook(encoding="utf-8") #创建workbook(xlwt)对象
worksheet = workbook.add_sheet('sheet') #创建工作表
worksheet.write(0,0,'hello word,my baby sheet !') #写参数-/行/列/内容
workbook.save('九九乘法表.xls') #保存
'''
#练习 -把九九乘法表写入Excel表格中
#1while
'''
import xlwt
workbook = xlwt.Workbook(encoding="utf-8") #创建workbook(xlwt)对象
worksheet = workbook.add_sheet('sheet') #创建工作表
m = 0
while m <= 9:
m+=1
n=1
while n <= m:
#print("%d * %d = %d"%(m,n,m*n),end=' ')
worksheet.write(m-1, n-1,"%dx%d=%d"%(m,n,m*n)) # 写参数-/行/列/内容
n += 1
else:
worksheet.write(m-1, n-1," ")
continue
workbook.save('九九乘法表.xls') #保存
'''
#2for
import xlwt
workbook = xlwt.Workbook(encoding="utf-8") #创建workbook(xlwt)对象
worksheet = workbook.add_sheet('sheet') #创建工作表
for m in range(1,10):
for n in range(1,m+1):
worksheet.write(m-1,n-1,"%d * %d = %d"%(m,n,m*n))
workbook.save('九九乘法表.xls') #保存
Python爬虫 小白[3天]入门笔记的更多相关文章
- Python基础 小白[7天]入门笔记
笔记来源 Day-1 基础知识(注释.输入.输出.循环.数据类型.随机数) #-*- codeing = utf-8 -*- #@Time : 2020/7/11 11:38 #@Author : H ...
- Python爬虫小白入门(一)写在前面
一.前言 你是不是在为想收集数据而不知道如何收集而着急? 你是不是在为想学习爬虫而找不到一个专门为小白写的教程而烦恼? Bingo! 你没有看错,这就是专门面向小白学习爬虫而写的!我会采用实例的方式, ...
- Python爬虫小白入门(一)入门介绍
一.前言 你是不是在为想收集数据而不知道如何收集而着急? 你是不是在为想学习爬虫而找不到一个专门为小白写的教程而烦恼? Bingo! 你没有看错,这就是专门面向小白学习爬虫而写的!我会采用实例的方式, ...
- Python爬虫小白入门(四)PhatomJS+Selenium第一篇
一.前言 在上一篇博文中,我们的爬虫面临着一个问题,在爬取Unsplash网站的时候,由于网站是下拉刷新,并没有分页.所以不能够通过页码获取页面的url来分别发送网络请求.我也尝试了其他方式,比如下拉 ...
- Python爬虫小白入门(三)BeautifulSoup库
# 一.前言 *** 上一篇演示了如何使用requests模块向网站发送http请求,获取到网页的HTML数据.这篇来演示如何使用BeautifulSoup模块来从HTML文本中提取我们想要的数据. ...
- Python爬虫小白入门(二)requests库
一.前言 为什么要先说Requests库呢,因为这是个功能很强大的网络请求库,可以实现跟浏览器一样发送各种HTTP请求来获取网站的数据.网络上的模块.库.包指的都是同一种东西,所以后文中可能会在不同地 ...
- Python爬虫小白入门(五)PhatomJS+Selenium第二篇
一.前言 前文介绍了PhatomJS 和Selenium 的用法,工具准备完毕,我们来看看如何使用它们来改造我们之前写的小爬虫. 我们的目的是模拟页面下拉到底部,然后页面会刷出新的内容,每次会加载10 ...
- Python爬虫小白入门(六)爬取披头士乐队历年专辑封面-网易云音乐
一.前言 前文说过我的设计师小伙伴的设计需求,他想做一个披头士乐队历年专辑的瀑布图. 通过搜索,发现网易云音乐上有比较全的历年专辑信息加配图,图片质量还可以,虽然有大有小. 我的例子怎么都是爬取图片? ...
- Python爬虫小白入门(七)爬取豆瓣音乐top250
抓取目标: 豆瓣音乐top250的歌名.作者(专辑).评分和歌曲链接 使用工具: requests + lxml + xpath. 我认为这种工具组合是最适合初学者的,requests比pytho ...
随机推荐
- Spring Cloud Gateway 全局通用异常处理
为什么需要全局异常处理 在传统 Spring Boot 应用中, 我们 @ControllerAdvice 来处理全局的异常,进行统一包装返回 // 摘至 spring cloud alibaba c ...
- 【pytest官方文档】解读Skipping test functions,跳过测试用例详解
有时候,为了满足某些场景的需要,我们知道有些测试函数在这时候肯定不能执行,或者执行了也会失败.那么我们 可以选择去跳过这个测试函数,这样也就不会影响整体的测试函数运行效果,不至于在你运行的众多绿色通过 ...
- Spring Boot demo系列(六):HTTPS
2021.2.24 更新 1 概述 本文演示了如何给Spring Boot应用加上HTTPS的过程. 2 证书 虽然证书能自己生成,使用JDK自带的keytool即可,但是生产环境是不可能使用自己生成 ...
- 后端Spring Boot+前端Android交互+MySQL增删查改
2021.1.27 更新 已更新新版本博客,更新内容很多,因此新开了一篇博客,戳这里. 1 概述 使用spring boot作为后端框架与Android端配合mysql进行基本的交互,包含了最基本的增 ...
- VirtualBox CentOS8 调整分辨率
1 概述 VirtualBox安装完CentOS8后无法调节分辨率,需要安装额外的工具. 2 安装依赖包 首先确保虚拟机能正常连接网络,然后安装:kernel.kernel-core.kernel-m ...
- 【ShardingSphere】ShardingSphere学习(三)-数据分片-分片
分片键 分片算法 分片策略 SQL Hint 分片键 用于分片的数据库字段,是将数据库(表)水平拆分的关键字段.例:将订单表中的订单主键的尾数取模分片,则订单主键为分片字段. SQL中如果无分片字段, ...
- 给HTML5 Video 设置多语言字幕文件
现在各种支持HTML5的浏览器都能够播放html5视频了,但是对于字幕的支持却很少,我们期待像DVD那样强大的字幕. 往往我们还不得不通过js来做,着实是一件痛苦的事情. 现在IE10率先对HTML5 ...
- C实现十进制与十六进制转换
include <stdio.h> include <stdlib.h> include <string.h> include <locale.h> i ...
- POJ3080方法很多(暴力,KMP,后缀数组,DP)
题意: 给n个串(n>=2&&n<=10),每个串长度都是60,然后问所有串的最长公共子串,如果答案不唯一输出字典序最小的. 思路:直接暴力,枚举+KMP,后缀 ...
- POJ1324贪吃蛇(状态压缩广搜)
题意: 给你一个地图,有的地方能走,有的地方不能走,然后给你一条蛇,问你这条蛇的头部走到1,1的位置的最少步数,注意,和贪吃蛇不太一样,就是蛇咬到自己身体的那个地方,具体怎么不一样自己模拟 ...