Pytorch多卡训练
前一篇博客利用Pytorch手动实现了LeNet-5,因为在训练的时候,机器上的两张卡只用到了一张,所以就想怎么同时利用起两张显卡来训练我们的网络,当然LeNet这种层数比较低而且用到的数据集比较少的神经网络是没有必要两张卡来训练的,这里只是研究怎么调用两张卡。
现有方法
在网络上查找了多卡训练的方法,总结起来就是三种:
- nn.DataParallel
- pytorch-encoding
- distributedDataparallel
第一种方法是pytorch自带的多卡训练的方法,但是从方法的名字也可以看出,它并不是完全的并行计算,只是数据在两张卡上并行计算,模型的保存和Loss的计算都是集中在几张卡中的一张上面,这也导致了用这种方法两张卡的显存占用会不一致。
第二种方法是别人开发的第三方包,它解决了Loss的计算不并行的问题,除此之外还包含了很多其他好用的方法,这里放出它的GitHub链接有兴趣的同学可以去看看。
第三种方法是这几种方法最复杂的一种,对于该方法来说,每个GPU都会对自己分配到的数据进行求导计算,然后将结果传递给下一个GPU,这与DataParallel将所有数据汇聚到一个GPU求导,计算Loss和更新参数不同。
这里我先选择了第一个方法进行并行的计算
并行计算相关代码
首先需要检测机器上是否有多张显卡
USE_MULTI_GPU = True
# 检测机器是否有多张显卡
if USE_MULTI_GPU and torch.cuda.device_count() > 1:
MULTI_GPU = True
os.environ["CUDA_DEVICE_ORDER"] = "PCI_BUS_ID"
os.environ["CUDA_VISIBLE_DEVICES"] = "0, 1"
device_ids = [0, 1]
else:
MULTI_GPU = False
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
其中os.environ["CUDA_VISIBLE_DEVICES"] = "0, 1"是将机器中的GPU进行编号
接下来就是读取模型了
net = LeNet()
if MULTI_GPU:
net = nn.DataParallel(net,device_ids=device_ids)
net.to(device)
这里与单卡的区别就是多了nn.DataParallel这一步操作
接下来是optimizer和scheduler的定义
optimizer=optim.Adam(net.parameters(), lr=1e-3)
scheduler = StepLR(optimizer, step_size=100, gamma=0.1)
if MULTI_GPU:
optimizer = nn.DataParallel(optimizer, device_ids=device_ids)
scheduler = nn.DataParallel(scheduler, device_ids=device_ids)
因为optimizer和scheduler的定义发送了变化,所以在后期调用的时候也有所不同
比如读取learning rate的一段代码:
optimizer.state_dict()['param_groups'][0]['lr']
现在就变成了
optimizer.module.state_dict()['param_groups'][0]['lr']
详细的代码可以在我的GitHub仓库看到
开始训练
训练过程与单卡一样,这里就展示两张卡的占用情况
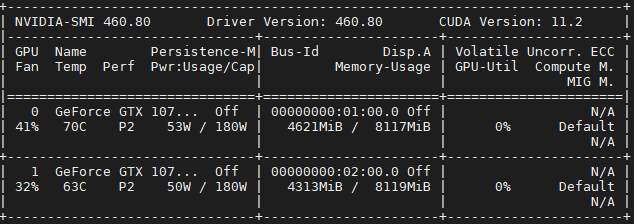
可以看到两张卡都有占用,这说明我们的代码起了作用,但是也可以看到,两张卡的占用有明显的区别,这就是前面说到的DataParallel只是在数据上并行了,在loss计算等操作上并没有并行
最后
如果文章那里有错误和建议,都可以向往指出
Pytorch多卡训练的更多相关文章
- Pytorch使用分布式训练,单机多卡
pytorch的并行分为模型并行.数据并行 左侧模型并行:是网络太大,一张卡存不了,那么拆分,然后进行模型并行训练. 右侧数据并行:多个显卡同时采用数据训练网络的副本. 一.模型并行 二.数据并行 数 ...
- 使用Pytorch进行多卡训练
当一块GPU不够用时,我们就需要使用多卡进行并行训练.其中多卡并行可分为数据并行和模型并行.具体区别如下图所示: 由于模型并行比较少用,这里只对数据并行进行记录.对于pytorch,有两种方式可以进行 ...
- Pytorch多GPU训练
Pytorch多GPU训练 临近放假, 服务器上的GPU好多空闲, 博主顺便研究了一下如何用多卡同时训练 原理 多卡训练的基本过程 首先把模型加载到一个主设备 把模型只读复制到多个设备 把大的batc ...
- 计图(Jittor) 1.1版本:新增骨干网络、JIT功能升级、支持多卡训练
计图(Jittor) 1.1版本:新增骨干网络.JIT功能升级.支持多卡训练 深度学习框架-计图(Jittor),Jittor的新版本V1.1上线了.主要变化包括: 增加了大量骨干网络的支持,增强了辅 ...
- pytorch 多GPU训练总结(DataParallel的使用)
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明.本文链接:https://blog.csdn.net/weixin_40087578/artic ...
- pytorch: 准备、训练和测试自己的图片数据
大部分的pytorch入门教程,都是使用torchvision里面的数据进行训练和测试.如果我们是自己的图片数据,又该怎么做呢? 一.我的数据 我在学习的时候,使用的是fashion-mnist.这个 ...
- AMD cpu 下 Pytorch 多卡并行卡死问题解决
dataparallel not working on nvidia gpus and amd cpus https://github.com/pytorch/pytorch/issues/130 ...
- pytorch版yolov3训练自己数据集
目录 1. 环境搭建 2. 数据集构建 3. 训练模型 4. 测试模型 5. 评估模型 6. 可视化 7. 高级进阶-网络结构更改 1. 环境搭建 将github库download下来. git cl ...
- PyTorch Tutorials 4 训练一个分类器
%matplotlib inline 训练一个分类器 上一讲中已经看到如何去定义一个神经网络,计算损失值和更新网络的权重. 你现在可能在想下一步. 关于数据? 一般情况下处理图像.文本.音频和视频数据 ...
随机推荐
- 仅仅使用Google就完成了人生第一次破解
2021年2月6日21:17:09 begin 起因 在异乡的打工人,不善言谈,幸有一老同学,周末常邀吃饭,感恩之心铭记于心.她结婚时,为表心意欲做视频,视频需要制作字幕,搜索之,偶遇一字幕软件,但是 ...
- GitlabCI/CD&Kubernetes项目交付流水线实践
GitlabCI实践 GitLabCI/CD基础概念 为什么要做CI/CD? GitLab CI/CD简介 GitLabCI VS Jenkins 安装部署GitLab服务 GitLabRunner实 ...
- Kubernetes工作流程--<1>
Kubernetes工作流程 客户端创建pod 流程: 用户管理员创建 Pod 的请求默认是通过kubectl 客户端管理命令 api server 组件进行交互的,默认会将请求发送给 API Ser ...
- Mokito 单元测试与 Spring-Boot 集成测试
Mokito 单元测试与 Spring-Boot 集成测试 版本说明 Java:1.8 JUnit:5.x Mokito:3.x H2:1.4.200 spring-boot-starter-test ...
- Unity 背包系统的完整实现(基于MVC框架思想)
前言: 项目源码上传GitHub:Unity-knapsack 背包系统: 背包系统是游戏中非常重要的元素,几乎每一款游戏都有背包系统,我们使用背包系统可以完成装备栏的数据管理,商店物体的数据管理等等 ...
- 2-fabric网络搭建流程
目录 一.示例网络 下面开始一步步的搭建和叙述上述过程 二.创建网络 三.添加网络管理员 四.定义联盟 五.为联盟创建通道 六.节点和账本 七.应用程序和智能合约链码 八.完成网络 简化视觉词汇表 九 ...
- leetcode 刷题(数组篇)4题 寻找两个正序数组的中位数(二分查找)
题目描述 给定两个大小分别为 m 和 n 的正序(从小到大)数组 nums1 和 nums2.请你找出并返回这两个正序数组的 中位数 . 示例 1: 输入:nums1 = [1,3], nums2 = ...
- 【CTF】图片隐写术 · 盲水印
前言 盲水印同样是CTF Misc中极小的一个知识点,刚刚做到一题涉及到这个考点的题目. 感觉还挺有意思的,就顺便去了解了下盲水印技术. 数字水印 数字水印(Digital Watermark)一种应 ...
- No_leak(ret2ROP + 低字节改写到syscall)
No_leak 有这种题,题目很短小,只有一个read函数,没有输出函数,这样的题怎么解呢?当然首先想到的是ret2dl,但是那个有点儿复杂.下面我来介绍一种简单的解法. 代码如下: //gcc 1. ...
- 数据结构☞二叉搜索树BST
二叉查找树(Binary Search Tree),(又:二叉搜索树,二叉排序树)它可以是一棵空树,也可以是具有下列性质的二叉树: 若它的左子树不空,则左子树上所有结点的值均小于它的根结点的值: 若它 ...