alertmanager的使用
一、Alertanager的安装
1、下载
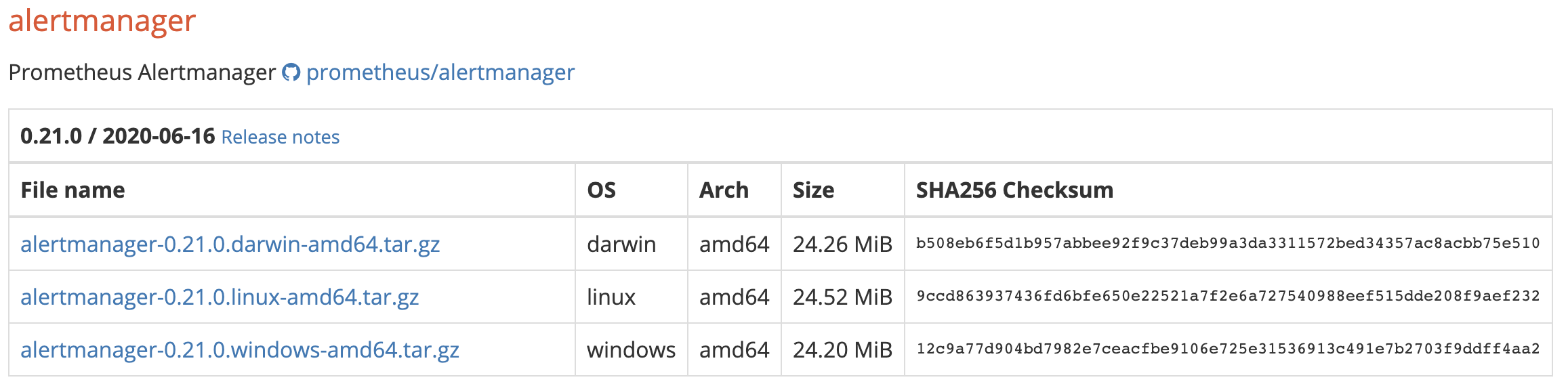
2、安装
# 不同的平台下载不同的安装包wget https://github.com/prometheus/alertmanager/releases/download/v0.21.0/alertmanager-0.21.0.darwin-amd64.tar.gz# 解压tar zxvf alertmanager-0.21.0.darwin-amd64.tar.gz# 重命名mv alertmanager-0.21.0.darwin-amd64.tar.gz alertmanager
3、启动
# 启动的时候指定配置文件的路径和启动端口./alertmanager --config.file=alertmanager.yml --web.listen-address=":9093"# 显示帮助信息./alertmanager --help
4、alertmanager和prometheus的整合
修改prometheus.yml配置文件
alerting:alertmanagers:- static_configs:- targets:- 127.0.0.1:9082 # 告警管理器的地址
整合参考链接https://prometheus.io/docs/prometheus/latest/configuration/configuration/#alertmanager_config
二、告警分组
分组机制可以将某一类型的告警信息合并成一个大的告警信息,避免发送太多的告警邮件。
**比如:**我们有3台服务器都介入了Prometheus,这3台服务器同时宕机了,那么如果不分组可能会发送3个告警信息,如果分组了,那么会合并成一个大的告警信息。
1、告警规则
监控服务器宕机的时间超过1分钟就发送告警邮件。
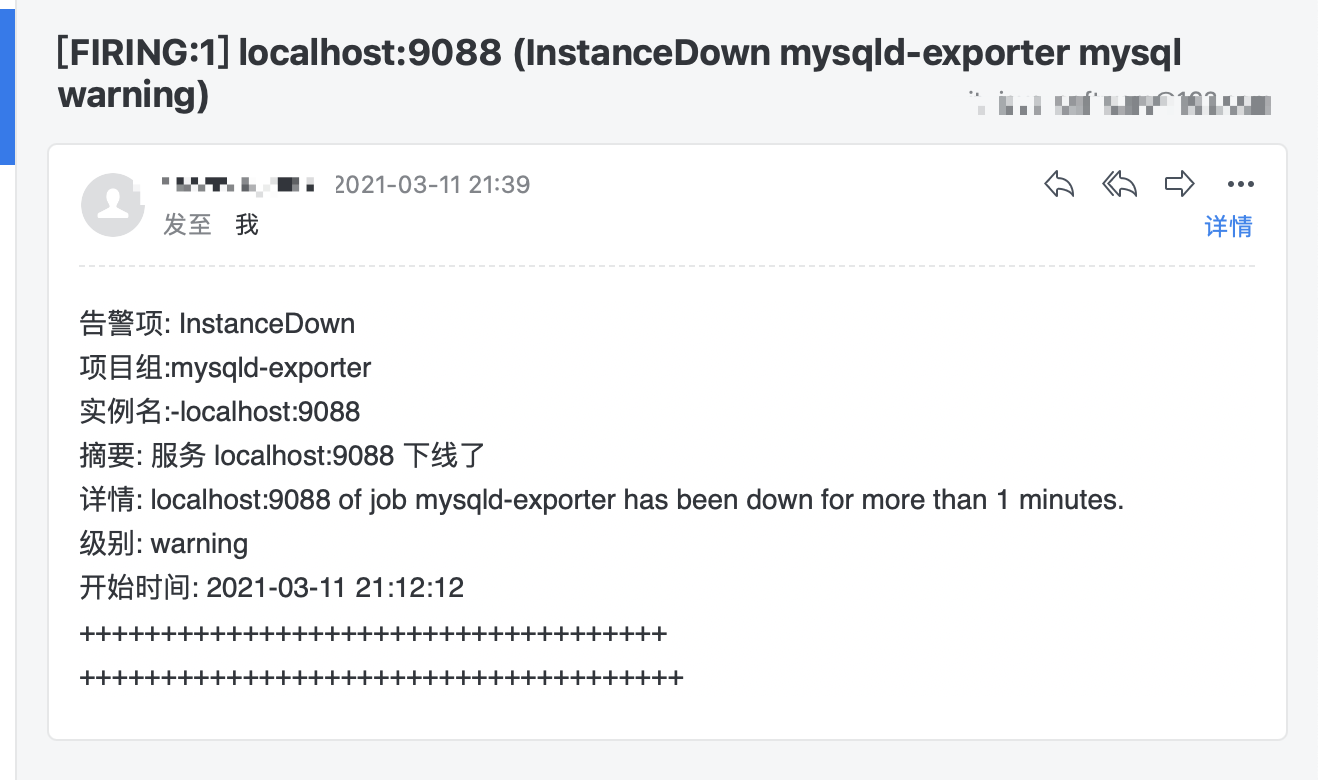
groups:- name: Test-Group-001 # 组的名字,在这个文件中必须要唯一rules:- alert: InstanceDown # 告警的名字,在组中需要唯一expr: up == 0 # 表达式, 执行结果为true: 表示需要告警for: 1m # 超过多少时间才认为需要告警(即up==0需要持续的时间)labels:severity: warning # 定义标签annotations:summary: "服务 {{ $labels.instance }} 下线了"description: "{{ $labels.instance }} of job {{ $labels.job }} has been down for more than 1 minutes."
2、alertmanager.yml配置
global:resolve_timeout: 5m# 整合qq邮件smtp_smarthost: 'smtp.qq.com:465'smtp_from: '1451578387@qq.com'smtp_auth_username: '1451578387@qq.com'smtp_auth_identity: 'xxxxxx'smtp_auth_password: 'xxxxxx'smtp_require_tls: false# 路由route:group_by: ['alertname'] # 根据什么分组,此处配置的是根据告警的名字分组,没有指定 group_by 貌似是根据规则文件的 groups[n].name 来分组的。group_wait: 10s # 当产生一个新分组时,告警信息需要等到 group_wait 才可以发送出去。group_interval: 10s # 如果上次告警信息发送成功,此时又来了一个新的告警数据,则需要等待 group_interval 才可以发送出去repeat_interval: 120s # 如果上次告警信息发送成功,且问题没有解决,则等待 repeat_interval 再次发送告警数据receiver: 'email' # 告警的接收者,需要和 receivers[n].name 的值一致。receivers:- name: 'email'email_configs:- to: '1451578387@qq.com'
3、分组相关的alertmanager的配置
route:group_by: ['alertname']group_wait: 10sgroup_interval: 10srepeat_interval: 120s
group_wait、group_interval和repeat_interval的解释参考上方的注释。和此链接https://www.robustperception.io/whats-the-difference-between-group_interval-group_wait-and-repeat_interval
4、邮件发送结果

三、告警抑制
指的是当某类告警产生的时候,于此相关的别的告警就不用发送告警信息了。
**比如:**我们对某台机器的CPU的使用率进行了监控,比如 使用到 80% 和 90% 都进行了监控,那么我们可能想如果CPU使用率达到了90%就不要发送80%的邮件了。
1、告警规则
如果 cpu 在5分钟的使用率超过 80% 则产生告警信息。
如果 cpu 在5分钟的使用率超过 90% 则产生告警信息。
groups:- name: Cpurules:- alert: Cpu01expr: "(1 - avg(irate(node_cpu_seconds_total{mode='idle'}[5m])) by (instance,job)) * 100 > 80"for: 1mlabels:severity: info # 自定一个一个标签 info 级别annotations:summary: "服务 {{ $labels.instance }} cpu 使用率过高"description: "{{ $labels.instance }} of job {{ $labels.job }} 的 cpu 在过去5分钟内使用过高,cpu 使用率 {{humanize $value}}."- alert: Cpu02expr: "(1 - avg(irate(node_cpu_seconds_total{mode='idle'}[5m])) by (instance,job)) * 100 > 90"for: 1mlabels:severity: warning # 自定一个一个标签 warning 级别annotations:summary: "服务 {{ $labels.instance }} cpu 使用率过高"description: "{{ $labels.instance }} of job {{ $labels.job }} 的 cpu 在过去5分钟内使用过高,cpu 使用率 {{humanize $value}}."
2、alertmanager.yml 配置抑制规则
抑制规则:
如果 告警的名称 alertname = Cpu02 并且 告警级别 severity = warning ,那么抑制住 新的告警信息中 标签为 severity = info 的告警数据。并且源告警和目标告警数据的 instance 标签的值必须相等。
# 抑制规则,减少告警数据inhibit_rules:- source_match: # 匹配当前告警规则后,抑制住target_match的告警规则alertname: Cpu02 # 标签的告警名称是 Cpu02severity: warning # 自定义的告警级别是 warningtarget_match: # 被抑制的告警规则severity: info # 抑制住的告警级别equal:- instance # source 和 target 告警数据中,instance的标签对应的值需要相等。
3、邮件发送结果
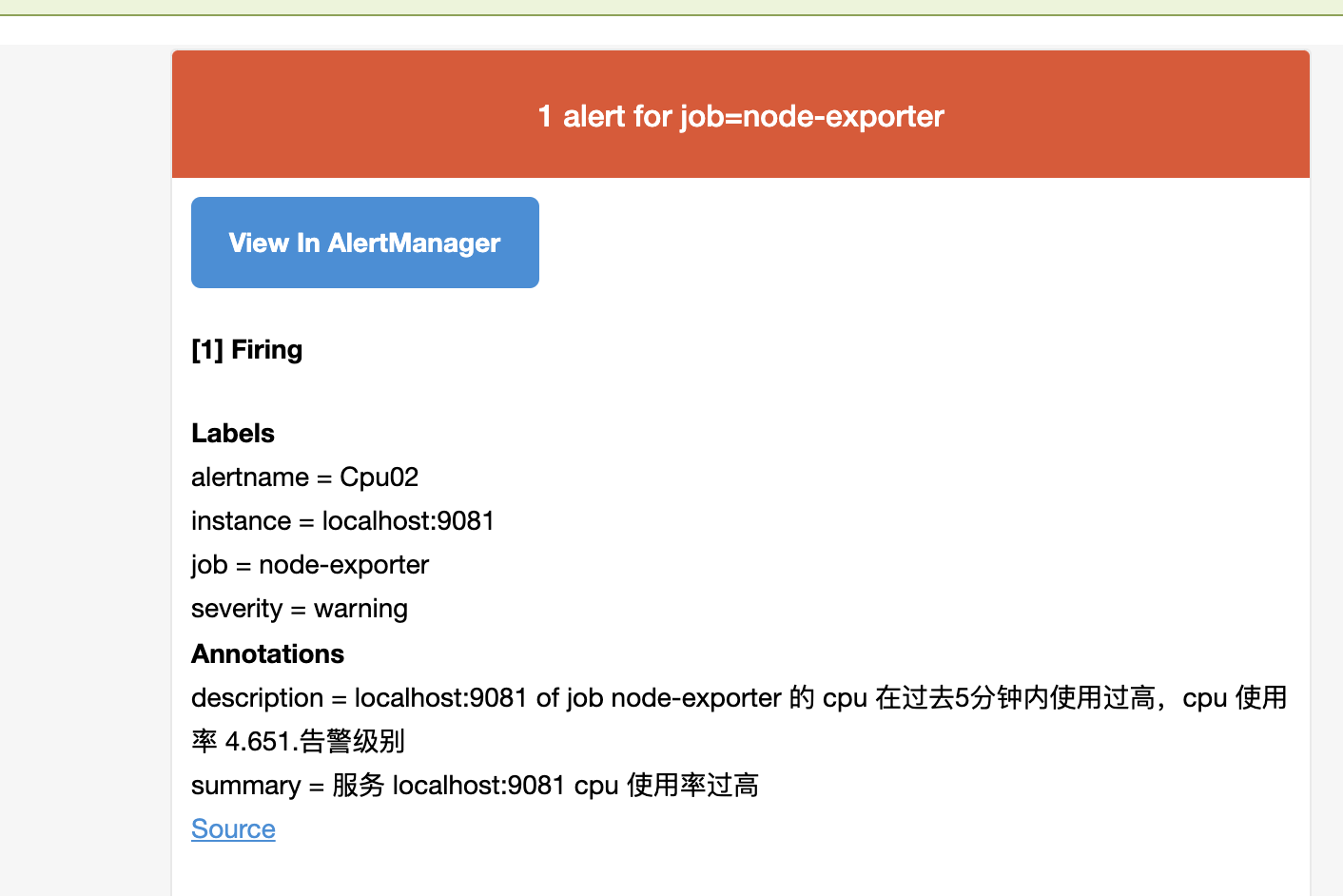
可以看到 只发送了 warning级别的告警,没有发送info级别的告警。
四、告警静默
指的是处于静默期,不发送告警信息。
**比如:**我们系统某段时间进行停机维护,由此可能会产生一堆的告警信息,但是这个时候的告警信息是没有意义的,就可以配置静默规则过滤掉。
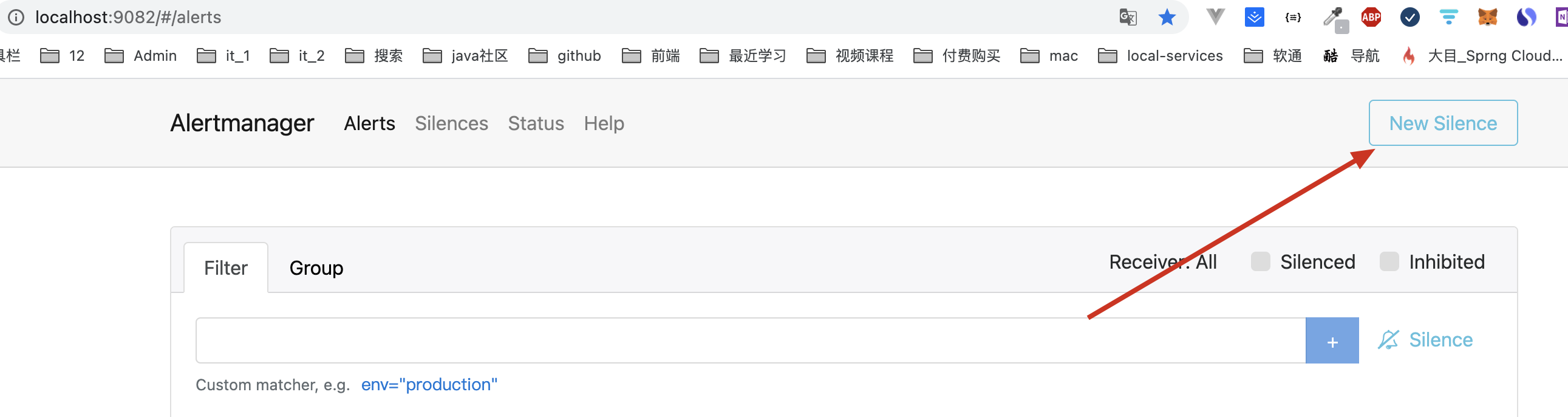
1、配置静默规则
需要在 alertmanager 的控制台,或通过 amtool 来操作。
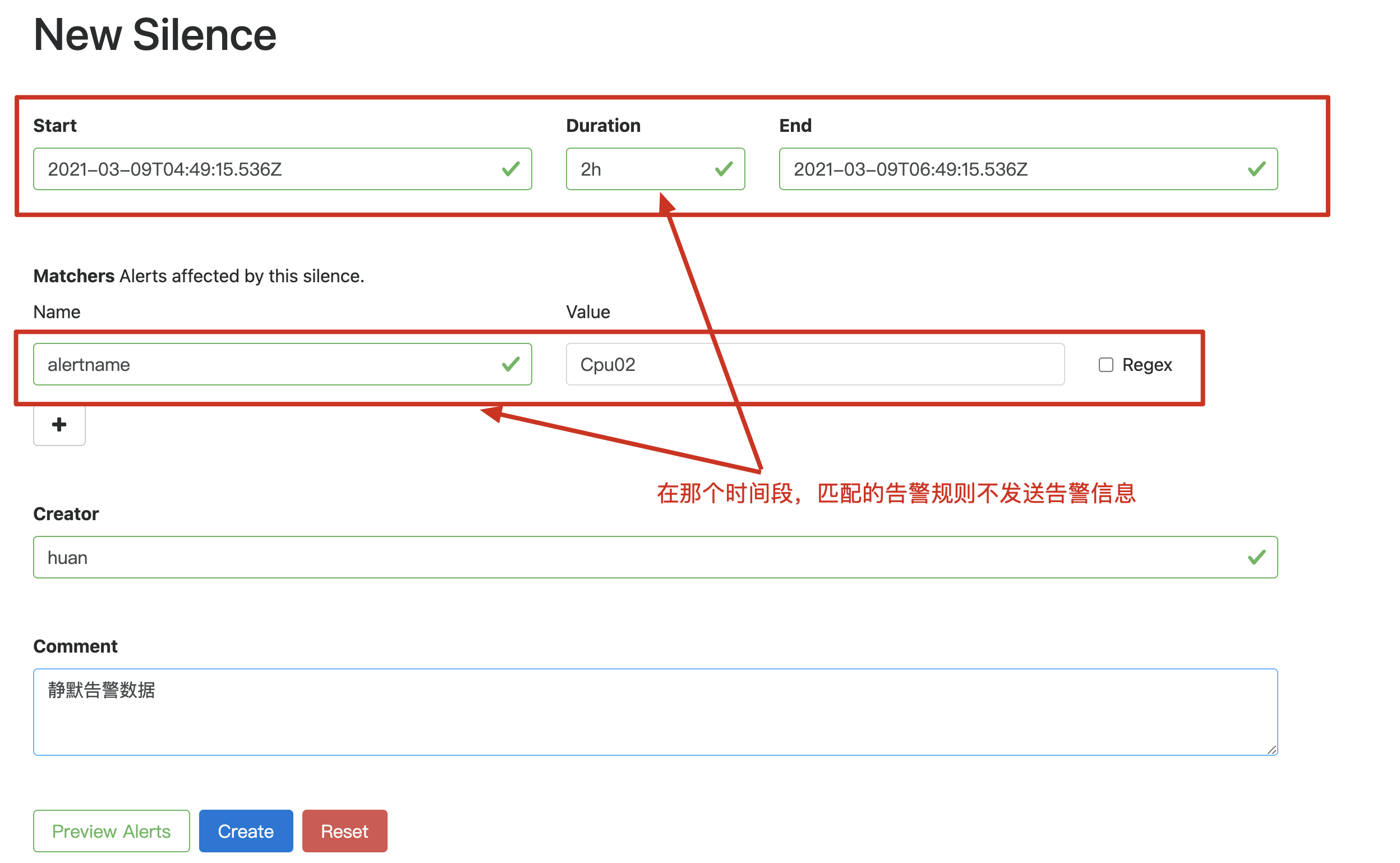
经过上述的配置,就收不到告警信息了。
五、告警路由
1、altermanager.yml配置文件的编写
global:resolve_timeout: 5msmtp_smarthost: 'smtp.qq.com:465'smtp_from: '145xxx8387@qq.com'smtp_auth_username: '1451578387@qq.com'smtp_auth_identity: 'xxxxx'smtp_auth_password: 'xxxxx'smtp_require_tls: false# 根路由,不能存在 match和match_re,任何告警数据没有匹配到路由时,将会由此根路由进行处理。route:group_by: ['job']group_wait: 10sgroup_interval: 10srepeat_interval: 120sreceiver: 'default-receiver'routes:- match_re:alertname: 'Cpu.*' # 如果告警的名字是以 Cpu 开头的发给 receiver-01receiver: 'receiver-01'- match:alertname: 'InstanceDown' # 如果告警的名字是 InstanceDown 则发送给 receiver-02receiver: 'receiver-02'group_by: ['instance'] # 根据 instance 标签分组continue: true # 为true则还需要去匹配子路由。routes:- match:alertname: 'InstanceDown' # 如果告警的名字是 InstanceDown 则还是需要发送给 receiver-03receiver: 'receiver-03'# 定义4个接收人(接收组等等)receivers:- name: 'default-receiver'email_configs:- to: '145xxx8387@qq.com'send_resolved: true- name: 'receiver-01'email_configs:- to: '2469xxx193@qq.com'send_resolved: true- name: 'receiver-02'email_configs:- to: 'weixin145xxx8387@163.com'send_resolved: true- name: 'receiver-03'email_configs:- to: 'it_xxx_software@163.com'send_resolved: trueinhibit_rules:- source_match:alertname: Cpu02severity: warningtarget_match:severity: infoequal:- instance
告警结果:
1、告警名称中存在 Cpu 的发送给 receiver-01(2469xxx193@qq.com)
2、告警名称是 InstanceDown 的需要发送给 receiver-02 和 receiver-03(weixin145xxx8387@163.com和it_xxx_software@163.com)
3、需要注意一下路由中的 continue参数,为 true,则需要在继续匹配子路由,为false:不在匹配它下方的子路由了。
当告警信息没有匹配到任务路由时,则由根路由(route)进行处理。
访问url https://www.prometheus.io/webtools/alerting/routing-tree-editor/ 查看告警树。
2、路由匹配
告警数据 从最顶级的route进入路由树,根路由需要匹配所有的告警数据,不可以设置match和match_re
每个路由下,有自己的子路由。**比如:**某个告警,如果级别普通,则通知给用户A,如果过段时间还未恢复,变y严重了,则需要通知给张三和李四,那么可以通过子路由实现。
默认情况下,告警从 根路由 进入之后,会遍历它下方的所有的子路由,
如果 route 中的 continue = false,那么在匹配到第一个符合的路由之后就停止匹配了。
如果 continue = true那么会继续进行匹配。
如果所有的都没有匹配到,那么走 根路由。
六、自定义邮件模板
1、定义告警模板
cat email.template.tmpl
{{ define "email.template.tmpl" }}{{- if gt (len .Alerts.Firing) 0 -}}{{ range.Alerts }}告警名称: {{ .Labels.alertname }} <br>实例名: {{ .Labels.instance }} <br>摘要: {{ .Annotations.summary }} <br>详情: {{ .Annotations.description }} <br>级别: {{ .Labels.severity }} <br>开始时间: {{ (.StartsAt.Add 28800e9).Format "2006-01-02 15:04:05" }}<br>++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++<br>{{ end }}{{ end -}}{{- if gt (len .Alerts.Resolved) 0 -}}{{ range.Alerts }}Resolved-告警恢复了。<br>告警名称: {{ .Labels.alertname }} <br>实例名: {{ .Labels.instance }} <br>摘要: {{ .Annotations.summary }} <br>详情: {{ .Annotations.description }} <br>级别: {{ .Labels.severity }} <br>开始时间: {{ (.StartsAt.Add 28800e9).Format "2006-01-02 15:04:05" }}<br>恢复时间: {{ (.EndsAt.Add 28800e9).Format "2006-01-02 15:04:05" }}<br>++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++<br>{{ end }}{{ end -}}{{- end }}
2、修改alertmanager.yml配置文件
1、加载告警模板的位置
global:resolve_timeout: 5mtemplates:- '/Users/huan/soft/prometheus/alertmanager-0.21.0/templates/*.tmpl'
配置 templates选项
2、接收人使用邮件模板
receivers:- name: 'default-receiver'email_configs:- to: 'it_xxx_software@163.com'send_resolved: truehtml: '{{template "email.template.tmpl" . }}'
注意:
html: '{{template "email.template.tmpl" . }}' 中的 template 中的值为 {{ define “email.template.tmpl” }} 中的值。
七、参考链接
3、alertmanager和prometheus整合参考链接
4、分组告警中 group_wait、group_interval和repeat_interval的解释
5、抑制规则配置
7、https://aleiwu.com/post/prometheus-alert-why/
8、查看告警树
alertmanager的使用的更多相关文章
- Alertmanager 集群
Alertmanager 集群搭建 环境准备:2台主机 (centos 7) 192.168.31.151 192.168.31.144 1.安装部署 192.168.31.151 cd /usr/l ...
- prometheus + grafana + node_exporter + alertmanager 的安装部署与邮件报警 (一)
大家一定要先看详细的理论教程,再开始搭建,这样报错后才容易找到突破口 参考文档 https://www.cnblogs.com/afterdawn/p/9020129.html https://www ...
- prometheus告警插件-alertmanager
prometheus本身不支持告警功能,主要通过插件alertmanage来实现告警.AlertManager用于接收Prometheus发送的告警并对于告警进行一系列的处理后发送给指定的用户. pr ...
- Alertmanager 安装(k8s报警)
一.下载Alertmanager https://prometheus.io/download/ wget https://github.com/prometheus/alertmanager/rel ...
- Prometheus+AlertManager实现邮件报警
AlertManager下载 https://prometheus.io/download/ 解压 添加配置文件test.yml,配置收发邮件邮箱 参考配置: global: smtp_smartho ...
- istio prometheus预警Prometheus AlertManager
1.安装alertmanager kubectl create -f 以下文件 alertmanager-templates.yaml.configmap.yaml.deployment.yaml.s ...
- 容器监控告警方案(cAdvisor + nodeExporter + alertmanager + prometheus +grafana)
一.prometheus基本架构 Prometheus 是一套开源的系统监控报警框架.它启发于 Google 的 borgmon 监控系统,由工作在 SoundCloud 的 google 前员工在 ...
- [k8s]prometheus+alertmanager二进制安装实现简单邮件告警
本次任务是用alertmanaer发一个报警邮件 本次环境采用二进制普罗组件 本次准备监控一个节点的内存,当使用率大于2%时候(测试),发邮件报警. k8s集群使用普罗官方文档 环境准备 下载二进制h ...
- prometheus,alertmanager 报警配置详解
vim prometheus.yml global: scrape_interval: 15s external_labels: monitor: 'codelab-monitor' scrape_c ...
- 【阿圆实验】Alertmanager HA 高可用配置
注意:没有使用supervisor进程管理器的,只参考配置,忽略和supervisor相关命令.并且alertmanager的版本不得低于0.15.2,低版本alert不支持集群配置. 一.alert ...
随机推荐
- Jsoup快速查询
一.selector选择器 二.Xpath查询
- linux 命令进阶篇之二
一.预备知识 选取init的进程. cat :由第一行开始显示文件内容 tac:由最后一行开始显示,有没有发现和cat是反过来写的 more:一页一页的显示内容 less:与more相似,但是可以往前 ...
- Tomcat部署与优化
目录: 一.Tomcat概述 二.Tomcat 服务部署 三.Tomcat 虚拟主机配置 四.Tomcat 优化 一.Tomcat概述 Tomcat是Java语言开发的,Tomcat服务器是-个免费的 ...
- 常见shell脚本测试题 if/case语句
1.检查用户家目录中的 test.sh 文件是否存在,并且检查是否有执行权限2.提示用户输入100米赛跑的秒数,要求判断秒数大于0且小于等于10秒的进入选拔赛,大于10秒的都淘汰,如果输入其它字符则提 ...
- Vue项目-初始化之 vue-cli
1.初始化项目 a.Vue CLI 是一个基于 Vue.js 进行快速开发的完整系统,提供: 通过 @vue/cli 搭建交互式的项目脚手架. 通过 @vue/cli + @vue/cli-servi ...
- 【第六篇】- Maven 仓库之Spring Cloud直播商城 b2b2c电子商务技术总结
Maven 仓库 在 Maven 的术语中,仓库是一个位置(place). Maven 仓库是项目中依赖的第三方库,这个库所在的位置叫做仓库. 在 Maven 中,任何一个依赖.插件或者项目构建的输出 ...
- 剑指offer计划19( 搜索与回溯算法中等)---java
1.1.题目1 剑指 Offer 64. 求1+2+-+n 1.2.解法 这题看评论区真的绝了,都是人才,各个说话都好听,我看到个还有用异常来结束的就离谱. 这题用了&&当左边为fal ...
- C++ windows 函数讲解(二)鼠标坐标
获得鼠标坐标: #include<bits/stdc++.h> #include<windows.h> using namespace std; int main() { PO ...
- 一文让你彻底搞懂 vue-Router
路由是网络工程里面的专业术语,就是通过互联把信息从源地址传输到目的地址的活动.本质上就是一种对应关系.分为前端路由和后端路由. 后端路由: URL 的请求地址与服务器上的资源对应,根据不同的请求地址返 ...
- jenkins的目录介绍
jenkins的目录介绍: /etc/init.d/jenkins #jenkins的启动文件 /etc/logrotate.d/jenkins /etc/sysconf ...