全面了解一致性哈希算法及PHP代码实现
在设计一个分布式系统的架构时,为了提高系统的负载能力,需要把不同的数据分发到不同的服务节点上。因此这里就需要一种分发的机制,其实就是一种算法,来实现这种功能。这里我们就用到了Consistent Hashing算法。
在正式介绍Consistent Hashing算法之前我们先来看一个简单的hash算法,就是用取余数的方式来选择节点。具体的步骤如下:
一、根据集群服务的节点数创建一个哈希表
二、然后根据键名计算出键名的整数哈希值,用该哈希值对节点数取余。
三、最后根据余数在哈希表中取出节点。
假设在一个集群中有n个服务器节点,对这些节点编号为0,1,2,…,n-1 。然后,将一条数据(key,value)存储到服务器中。这时我们该如何来选择服务器节点呢?根据上面的步骤我们需要对key计算hash值,然后再对n(节点个数)取余数。最后得到的值就是我们所要的节点。用一个公式来表示:num = hash(key) % n。hash()是一个计算hash值的函数,这里对hash()函数还是有一定的要求的,如果我们使用的hash()函数很优化的话,那计算出的num是均匀分布在0,1,2,…,n-1之间的,从而使尽可能多的服务器节点都能被使用。而不是所有的数据都集中在一个或者几个服务器节点上面。具体的hash()实现不是本章讨论的重点。
这种单纯的取余数的方式虽然简单,但是如果将其应用到实际生产系统中会出现很大的问题。假设我们有23个服务节点。那么根据上面的方式,一个key映射到每个节点的概率都是1/23。假设增加了一个服务节点的话,之前的hash(key) % n 就会变成hash(key) % (n+1) 。也就是说对于key来说有23/24的概率会被重新分配到新的节点。相反只会有1/24的概率会被分配到原节点。同样,当你减少一个节点的时候,有22/23的概率会被重新分配到新的节点上去。
鉴于这种情况,就需要有一种方式来避免或者减少在横向扩展的时候命中率降低的情况的发生。这种方法就是我们将要介绍的Consistent Hashing算法,我们称其为一致性hash算法。
为了了解Consistent Hashing算法是如何工作的,我们假设单位区间 [ 0 , 1 ) 依顺时针的方向均匀的分布在圆上。
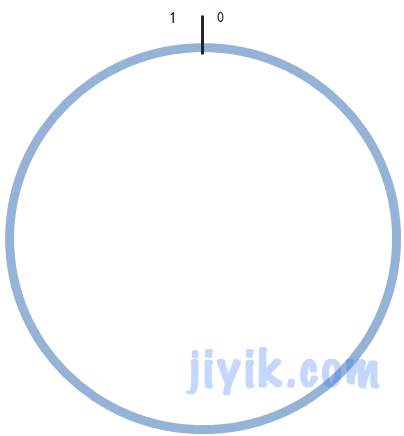
假使有n个服务节点,为每个服务节点编号为0, 1, 2, …, n-1。然后我们需要有一个hash()函数来对服务节点计算hash值。如果选用的hash()函数返回值的取值范围为[ 0, R ),那么使用公式 v = hash(n) / R。这样得到的v会分布在单位区间[ 0, 1 )内。所以,通过这个方式就可以使我们的服务节点分布在圆上面。
当然,以单位区间[ 0, 1 ) 画圆只是一种方式,还有很多其他的画圆方式,比如说:以区间[ 0, 2^32-1 ) 为圆,然后使用hash()函数对服务节点计算hash()值。选用的hash()函数产生的值当然也必须在0 – (2^32-1) 范围之内了。
这里我们还是以[ 0, 1 )为例来介绍。
我们以3个服务节点为例来进行说明
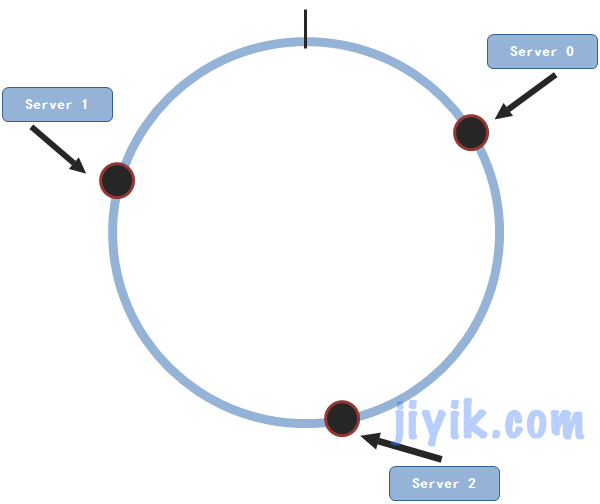
这三个节点随机的分布在这个圆上面。现在假设我们有一条数据(key,value)需要存储,接下来要做的就是将这条数据通过同样的方法映射到圆上面。
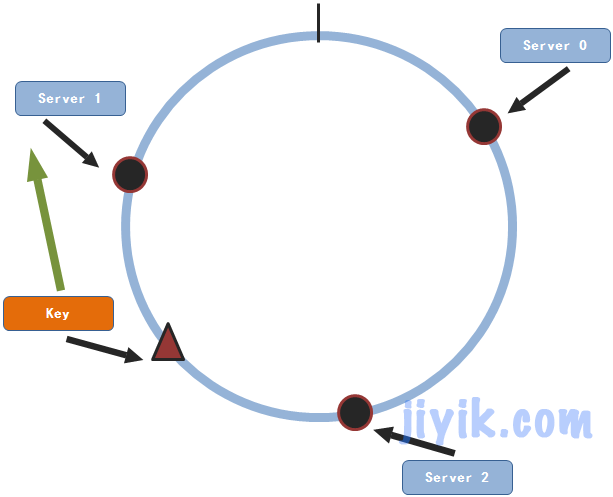
然后从key所坐落在圆上的位置开始顺时针查找服务节点所在的位置,找到的第一个服务节点即是要存储的节点。所以说这条数据将要存储在服务节点1上。
同理,当有其它的(key,value)对需要存储的时候,也是按照上面的方式进行服务节点的选择。
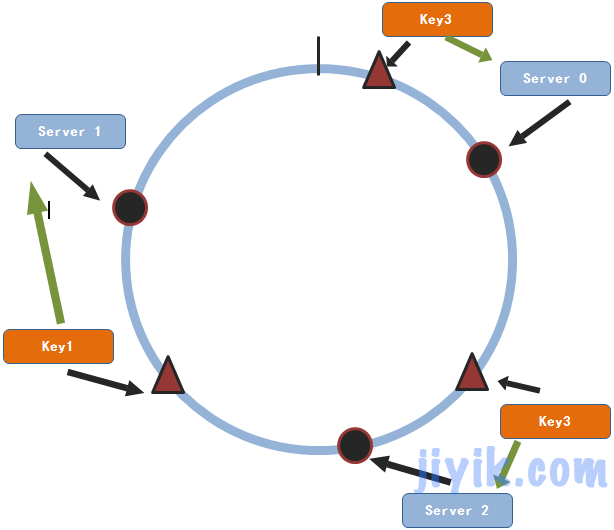
现在我们来看该方法对于我们刚开始提到的横向扩展的问题是否能够很好的解决呢?
假设我们需要增加一个服务节点3
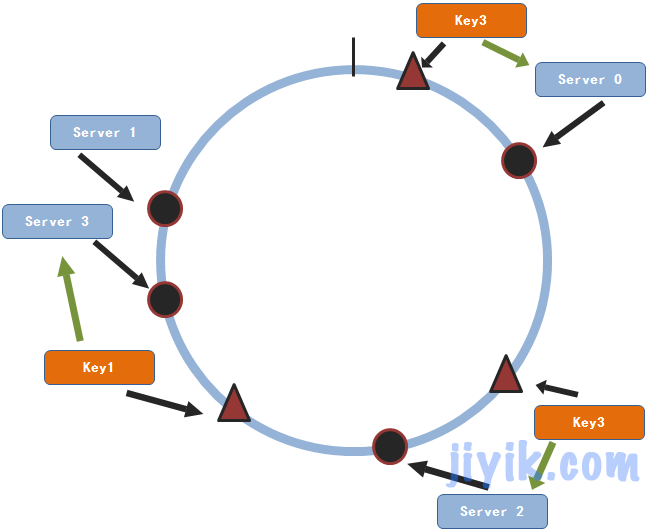
通过上图,我们可以看出,只有key1会改变其存储服务节点。对于大部分的数据来说依然会找到原先的节点。因此,对于n个服务节点的集群来说,当有服务节点增加的时候一条数据只有1/(n+1)的概率会改变其存储的服务节点。这个概率远比取余数法所得的概率要小的多。同样,减少一个服务节点和增加服务节点的原理是相同的,其每条数据重新选择服务节点的概率为1/(n-1)。同样这个概率也是很小的。
下面就用一段php代码来简单的实现这个过程
- $nodes = array('192.168.5.201','192.168.5.102','192.168.5.111');
- $keys = array('onmpw', 'jiyi', 'onmpw_key', 'jiyi_key', 'www','www_key','key1');
- $buckets = array(); //节点的hash字典
- $maps = array(); //存储key和节点之间的映射关系
- /**
- * 生成节点字典 —— 使节点分布在单位区间[0,1)的圆上
- */
- foreach( $nodes as $key) {
- $crc = crc32($key)/pow(2,32); // CRC値
- $buckets[] = array('index'=>$crc,'node'=>$key);
- }
- /*
- * 根据索引进行排序
- */
- sort($buckets);
- /*
- * 对每个key进行hash计算,找到其在圆上的位置
- * 然后在该位置开始依顺时针方向找到第一个服务节点
- */
- foreach($keys as $key){
- $flag = false; //表示是否有找到服务节点
- $crc = crc32($key)/pow(2,32);//计算key的hash值
- for($i = 0; $i < count($buckets); $i++){
- if($buckets[$i]['index'] > $crc){
- /*
- * 因为已经对buckets进行了排序
- * 所以第一个index大于key的hash值的节点即是要找的节点
- */
- $maps[$key] = $buckets[$i]['node'];
- $flag = true;
- break;
- }
- }
- if(!$flag){
- //没有找到,则使用buckets中的第一个服务节点
- $maps[$key] = $buckets[0]['node'];
- }
- }
- foreach($maps as $key=>$val){
- echo $key.'=>'.$val,"<br />";
- }
这段代码运行的结果如下
- onmpw=>192.168.5.102
- jiyi=>192.168.5.201
- onmpw_key=>192.168.5.201
- jiyi_key=>192.168.5.102
- www=>192.168.5.201
- www_key=>192.168.5.201
- key1=>192.168.5.111
然后我们添加一个服务节点,修改代码如下
- $nodes = array('192.168.5.201','192.168.5.102','192.168.5.111','192.168.5.11');
其它代码不变,继续运行结果如下
- onmpw=>192.168.5.102
- jiyi=>192.168.5.201
- onmpw_key=>192.168.5.11
- jiyi_key=>192.168.5.102
- www=>192.168.5.201
- www_key=>192.168.5.201
- key1=>192.168.5.111
我们看到,只有onmpw_key重新选择了服务节点。其它的都是原先的节点。
到这里我们看到,较之于取余数法命中的概率提高了相当多了。那这里是不是就解决了我们前面遇到的问题了呢?
其实,还没有。因为这些值的分布毕竟不是那么的均匀。在系统中有可能这些服务节点分布非常的集中,这可能导致的情况就是所有的key都映射到其中的一个或者几个节点上面,剩下的服务节点都没有被用到。虽然这并不是什么很严重的问题,那为什么我们要浪费哪怕只是一台服务器呢。
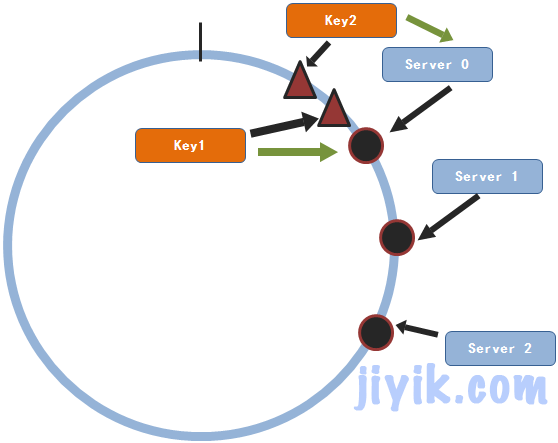
我们看,这种情况就造成了数据集中在一个服务节点上面,造成了其它服务节点的浪费。那如何解决这个问题呢?人们就又想出了一种新的方式:就是为每个节点建立虚拟的节点。什么意思呢?就是说对于节点j,为其建立m个复制品。这m个复制出来的节点都通过hash()函数得出不同的hash值,但是每个虚拟节点保存的节点信息都是节点j的。然后这些虚拟节点都会随机的分布在圆上面。举例子来说,我们有两个服务节点。并且为每个节点都复制出三个虚拟节点。这些节点(包括虚拟节点都随机的分布在圆上面)
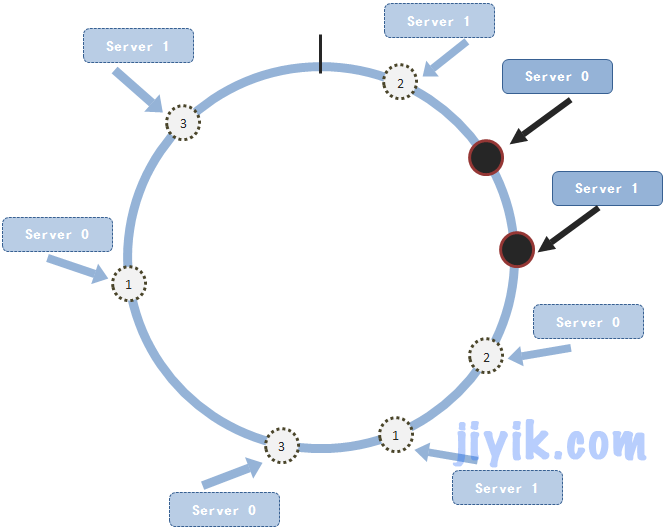
这样看起来服务节点在圆上分布还是比较均匀的了。其实,总结起来就是在上面的那种方式上稍微做了一下改进——给每个节点复制一些虚拟节点。
因此,我们的代码也不需要做过多的修改。为了看代码比较直观,我在这里还是将整段代码罗列在这。
- $nodes = array('192.168.5.201','192.168.5.102','192.168.5.111');
- $keys = array('onmpw', 'jiyi', 'onmpw_key', 'jiyi_key', 'www','www_key','key1');
- //添加的变量 修改的地方
- $replicas = 160; //每个节点的复制的个数
- $buckets = array(); //节点的hash字典
- $maps = array(); //存储key和节点之间的映射关系
- /**
- * 生成节点字典 —— 使节点分布在单位区间[0,1)的圆上
- */
- foreach( $nodes as $key) {
- //修改的地方
- for($i=1;$i<=$replicas;$i++){
- $crc = crc32($key.'.'.$i)/pow(2,32); // CRC値
- $buckets[] = array('index'=>$crc,'node'=>$key);
- }
- }
- /*
- * 根据索引进行排序
- */
- sort($buckets);
- /*
- * 对每个key进行hash计算,找到其在圆上的位置
- * 然后在该位置开始依顺时针方向找到第一个服务节点
- */
- foreach($keys as $key){
- $flag = false; //表示是否有找到服务节点
- $crc = crc32($key)/pow(2,32);//计算key的hash值
- for($i = 0; $i < count($buckets); $i++){
- if($buckets[$i]['index'] > $crc){
- /*
- * 因为已经对buckets进行了排序
- * 所以第一个index大于key的hash值的节点即是要找的节点
- */
- $maps[$key] = $buckets[$i]['node'];
- $flag = true;
- break;
- }
- }
- if(!$flag){
- //没有找到,则使用buckets中的第一个服务节点
- $maps[$key] = $buckets[0]['node'];
- }
- }
- foreach($maps as $key=>$val){
- echo $key.'=>'.$val,"<br />";
- }
有改动的地方在代码里已经标注出来了。可以看到,修改的地方还是比较少的。
至此,相信大家对Consistent Hashing应该有了一个比较清晰的认识。hash算法的用处还是很广泛的,比如在memcache集群,nginx负载等方面都有用到。
我们在 带你深入了解Memcached中的分布式思想 这篇文章中用实际的案例介绍了一致性hash算法在Memcache中的应用。这里我们所有的代码都是用PHP实现的,如果对PHP不熟悉的有兴趣的可以参考以下教程,PHP教程。
所以,了解hash算法对于我们是有很大的帮助的。
上述算法过程的表述有不清楚或者不合适的地方,欢迎大家不吝赐教。
全面了解一致性哈希算法及PHP代码实现的更多相关文章
- 一致性哈希算法——PHP实现代码
<?php /** * Flexihash - A simple consistent hashing implementation for PHP. * * The MIT License * ...
- 一致性哈希算法与Java实现
原文:http://blog.csdn.net/wuhuan_wp/article/details/7010071 一致性哈希算法是分布式系统中常用的算法.比如,一个分布式的存储系统,要将数据存储到具 ...
- 五分钟理解一致性哈希算法(consistent hashing)
转载请说明出处:http://blog.csdn.net/cywosp/article/details/23397179 一致性哈希算法在1997年由麻省理工学院提出的一种分布式哈希(DHT)实现算法 ...
- 每天进步一点点——五分钟理解一致性哈希算法(consistent hashing)
转载请说明出处:http://blog.csdn.net/cywosp/article/details/23397179 一致性哈希算法在1997年由麻省理工学院提出的一种分布式哈希(DHT) ...
- 一致性哈希算法以及其PHP实现
在做服务器负载均衡时候可供选择的负载均衡的算法有很多,包括: 轮循算法(Round Robin).哈希算法(HASH).最少连接算法(Least Connection).响应速度算法(Respons ...
- Java_一致性哈希算法与Java实现
摘自:http://blog.csdn.net/wuhuan_wp/article/details/7010071 一致性哈希算法是分布式系统中常用的算法.比如,一个分布式的存储系统,要将数据存储到具 ...
- 一致性哈希算法(consistent hashing)【转】
一致性哈希算法 来自:http://blog.csdn.net/cywosp/article/details/23397179 一致性哈希算法在1997年由麻省理工学院提出的一种分布式哈希 ...
- 一致性哈希算法学习及JAVA代码实现分析
1,对于待存储的海量数据,如何将它们分配到各个机器中去?---数据分片与路由 当数据量很大时,通过改善单机硬件资源的纵向扩充方式来存储数据变得越来越不适用,而通过增加机器数目来获得水平横向扩展的方式则 ...
- 一致性哈希算法——算法解决的核心问题是当slot数发生变化时,能够尽量少的移动数据
一致性哈希算法 摘自:http://blog.codinglabs.org/articles/consistent-hashing.html 算法简述 一致性哈希算法(Consistent Hashi ...
随机推荐
- spring boot log4j2 最佳实践
为什么选择 log4j2 Log4j2 使用了 LMAX Disruptor 库.在多线程场景中,异步 Logger 的吞吐量比 Log4j 1.x 和 Logback 高 18 倍,延迟低几个数量级 ...
- C 字符串相关的库函数
字符串操作函数 size_t strlen( char *string ); 返回字符串长度 char* strcpy( char *dst, char const *src ); 将src复制到ds ...
- 初学python写个自娱自乐的小游戏
一.摘要 当编写完后的代码执行第一次后达到了目标的预期效果,内心有些许满足,但是当突发情况产生后,程序便不能正常运行,于是准备从简单的版本开始出发,综合考虑使用者的需求,和使用过程中会遇到的问题,一步 ...
- 关于java socket中的read方法阻塞问题
客户端: public class TCPClient { public static void main(String[] args) throws IOException { FileInputS ...
- 2021.9.21考试总结[NOIP模拟58]
T1 lesson5! 开始以为是个无向图,直接不懂,跳去T2了. 之后有看了一眼发现可暴力,于是有了\(80pts\). 发现这个图是有拓扑序的,于是可以用拓扑排序找最长路径.先找原图内在最长路径上 ...
- 用STM32内置的高速ADC实现简易示波器
做一个数字采样示波器一直是我长久以来的愿望,不过毕竟这个目标难度比较大,涉及的方面实在太多,模拟前端电路.高速ADC.单片机.CPLD/FPGA.通讯.上位机程序.数据处理等等,不是一下子就能成的,慢 ...
- 用Python画如此漂亮的专业插图 ?简直So easy!
本文整理自知乎问答,仅用于学术分享,著作权归作者所有.如有侵权,请联系我删文处理.多多转发,多多学习! 方法一 强烈推荐 Python 的绘图模块 matplotlib: python plottin ...
- Python课程笔记(十一)
一.线程与多线程 1.线程与进程 线程指的是 进程(运行中的程序)中单一顺序的执行流. 多个独立执行的线程相加 = 一个进程 多线程程序是指一个程序中包含有多个执行流,多线程是实现并发机制的一种有效手 ...
- Python pylint requires Python '>=3.4.*' but the running Python is 2.7.12
用pylint 1.9.x 安装 pip install pylint==1.9.3. 或者换源 pip install -i https://pypi.tuna.tsinghua.edu.cn/si ...
- Spring Cloud Alibaba环境搭建
前言:Spring Cloud Alibaba是目前主流的分布式微服务架构,本文主要讲解了在IDEA中如何搭建Spring Cloud Alibaba环境,以及介绍Spring Cloud Aliba ...