大数据 | 分布式文件系统 HDFS
HDFS 的特点与应用场景
适合存储大文件
容错性高
适用于流式的数据访问
适用于读多写少场景
HDFS的相关概念
数据块(Block)
NameNode和DataNode
Secondary NameNode
块缓存
HDFS 架构
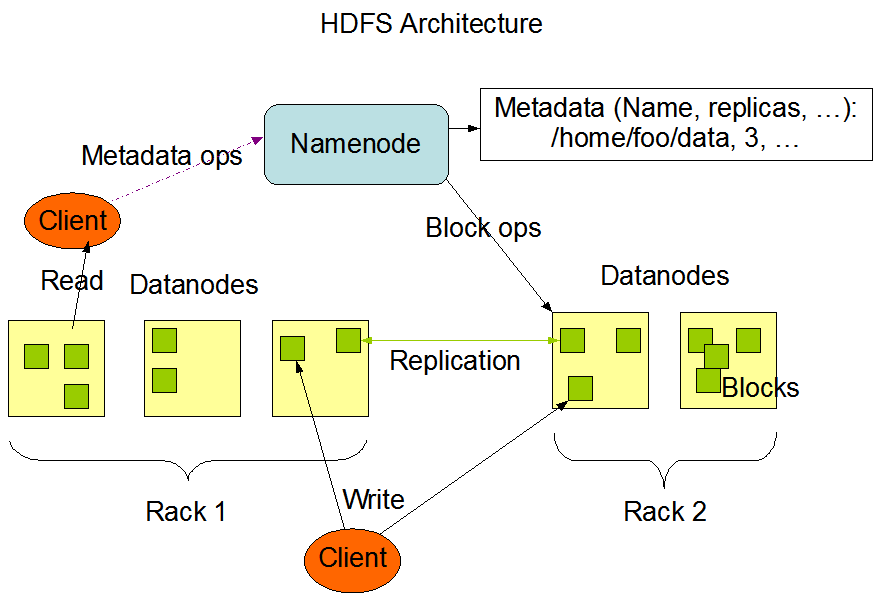
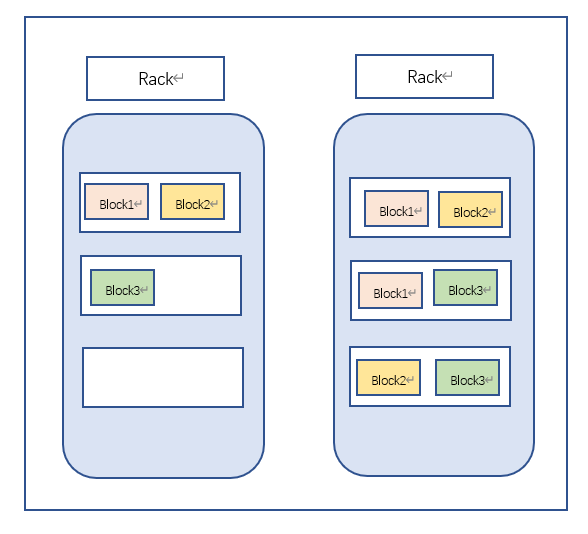
机架感知和副本机制
读写流程
读操作
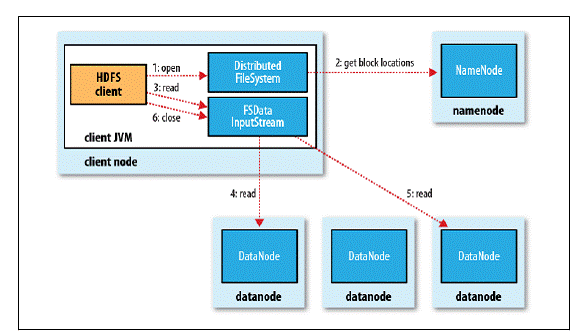
- 客户端通过调用 FileSystem 对象的 open() 方法来打开希望读取的文件,对于 HDFS 来说,这个对象是分布式文件系统的一个实例;
- DistributedFileSystem 通过RPC 调用 NameNode 以确定文件起始块的位置,由于存在多个副本,因此Namenode会返回同一个Block的多个文件的位置,然后根据集群拓扑结构排序,就近取;
- 前两步会返回一个 FSDataInputStream 对象,该对象会被封装成 DFSInputStream 对象,DFSInputStream 可以方便的管理 datanode 和 namenode 数据流,客户端对这个输入流调用 read() 方法;
- 存储着文件起始块的 DataNode 地址的 DFSInputStream 随即连接距离最近的 DataNode,通过对数据流反复调用 read() 方法,可以将数据从 DataNode 传输到客户端;
- 到达块的末端时,DFSInputStream 会关闭与该 DataNode 的连接,然后寻找下一个块的最佳 DataNode,这些操作对客户端来说是透明的,从客户端的角度来看只是读一个持续不断的流;
- 一旦客户端完成读取,就对 FSDataInputStream 调用 close() 方法关闭文件读取。
写操作
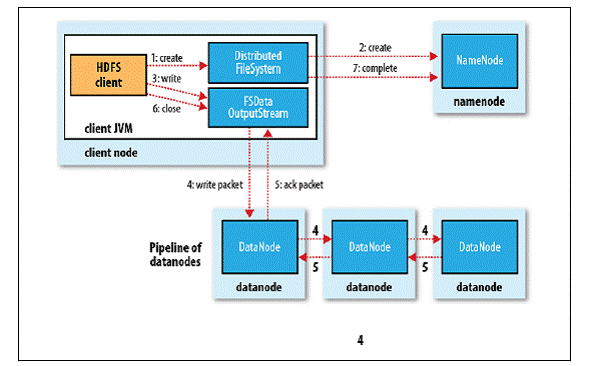
- 客户端通过调用 DistributedFileSystem 的 create() 方法创建新文件;
- DistributedFileSystem 通过 RPC 调用 NameNode 去创建一个没有 Blocks 关联的新文件,创建前 NameNode 会做各种校验,比如文件是否存在、客户端有无权限去创建等。如果校验通过,NameNode 会为创建新文件记录一条记录,否则就会抛出 IO 异常;
- 前两步结束后会返回 FSDataOutputStream 的对象,和读文件的时候相似,FSDataOutputStream 被封装成 DFSOutputStream,DFSOutputStream 可以协调 NameNode 和 Datanode。客户端开始写数据到 DFSOutputStream,DFSOutputStream 会把数据切成一个个小的数据包,并写入内部队列称为“数据队列”(Data Queue);
- DataStreamer 会去处理接受 Data Queue,它先问询 NameNode 这个新的 Block 最适合存储在哪几个 DataNode 里,比如重复数是 3,那么就找到 3 个最适合的 DataNode,把他们排成一个 pipeline。DataStreamer 把 Packet 按队列输出到管道的第一个 Datanode 中,第一个 DataNode 又把 Packet 输出到第二个 DataNode 中,以此类推;
- DFSOutputStream 还有一个队列叫 Ack Quene,也是由 Packet 组成,等待 DataNode 的收到响应,当 Pipeline 中的所有 DataNode 都表示已经收到的时候,这时 Akc Quene 才会把对应的 Packet 包移除掉;
- 客户端完成写数据后调用 close() 方法关闭写入流;
- DataStreamer 把剩余的包都刷到 Pipeline 里然后等待 Ack 信息,收到最后一个 Ack 后,通知 NameNode 把文件标示为已完成。
总结

大数据 | 分布式文件系统 HDFS的更多相关文章
- 大数据 --> 分布式文件系统HDFS的工作原理
分布式文件系统HDFS的工作原理 Hadoop分布式文件系统(HDFS)是一种被设计成适合运行在通用硬件上的分布式文件系统.HDFS是一个高度容错性的系统,适合部署在廉价的机器上.它能提供高吞吐量的数 ...
- 大数据 | 分布式文件系统HDFS 练习
本次作业来自于:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3292 利用Shell命令与HDFS进行交互 以”./bin/dfs ...
- 大数据技术原理与应用——分布式文件系统HDFS
分布式文件系统概述 相对于传统的本地文件系统而言,分布式文件系统(Distribute File System)是一种通过网络实现文件在多台主机上进行分布式存储的文件系统.分布式文件系统的设计一般采用 ...
- Hadoop分布式文件系统--HDFS结构分析
转自:http://blog.csdn.net/androidlushangderen/article/details/47377543 HDFS系列:http://blog.csdn.net/And ...
- 【转载】Hadoop分布式文件系统HDFS的工作原理详述
转载请注明来自36大数据(36dsj.com):36大数据 » Hadoop分布式文件系统HDFS的工作原理详述 转注:读了这篇文章以后,觉得内容比较易懂,所以分享过来支持一下. Hadoop分布式文 ...
- 大数据篇:HDFS
HDFS HDFS是什么? Hadoop分布式文件系统(HDFS)是指被设计成适合运行在通用硬件(commodity hardware)上的分布式文件系统(Distributed File Syste ...
- 你想了解的分布式文件系统HDFS,看这一篇就够了
1.分布式文件系统 计算机集群结构 分布式文件系统把文件分布存储到多个节点(计算机)上,成千上万的计算机节点构成计算机集群. 分布式文件系统使用的计算机集群,其配置都是由普通硬件构成的,与用多个处理器 ...
- Hadoop第三天---分布式文件系统HDFS(大数据存储实战)
1.开机启动Hadoop,输入命令: 检查相关进程的启动情况: 2.对Hadoop集群做一个测试: 可以看到新建的test1.txt和test2.txt已经成功地拷贝到节点上(伪分布式只有一个节 ...
- 大数据技术 - 分布式文件系统 HDFS 的设计
本章内容介绍下 Hadoop 自带的分布式文件系统,HDFS 即 Hadoop Distributed Filesystem.HDFS 能够存储超大文件,可以部署在廉价的服务器上,适合一次写入多次读取 ...
随机推荐
- centos7 连接打印机
centos7 连接打印机 2017-08-07 15:05:33 五岳寻仙客 阅读数 2531更多 分类专栏: Liunx的日常使用 版权声明:本文为博主原创文章,遵循CC 4.0 BY-SA版 ...
- DLL重定向处理
说明 目前正在做的项目批次功能涉及第三方插件,而第三方插件需依赖4.* 版本的Newtonsoft.Json.dll,由于现有功能已经使用6.*版本的Newtonsoft.Json.dll,故采用了d ...
- 矩阵中的路径 DFS+剪枝
给定一个 m x n 二维字符网格 board 和一个字符串单词 word .如果 word 存在于网格中,返回 true :否则,返回 false . 单词必须按照字母顺序,通过相邻的单元格内的字母 ...
- Python小白的数学建模课-A1.2021年数维杯C题(运动会优化比赛模式探索)探讨
Python小白的数学建模课 A1-2021年数维杯C题(运动会优化比赛模式探索)探讨. 运动会优化比赛模式问题,是公平分配问题 『Python小白的数学建模课 @ Youcans』带你从数模小白成为 ...
- NGINX缓存使用官方指南
我们都知道,应用程序和网站一样,其性能关乎生存.但如何使你的应用程序或者网站性能更好,并没有一个明确的答案.代码质量和架构是其中的一个原因,但是在很多例子中我们看到,你可以通过关注一些十分基础的应用内 ...
- Go语言流程控制05--defer延时执行
package main import "fmt" func xingzuoZhensuo() { var birthday string fmt.Println("请输 ...
- Go基础结构与类型06---房贷计算器
package main import ( "fmt" "math" "strconv" ) /* 输入的金额.年化利息(0.05代表5%) ...
- React-setState的那些事儿
关于setState,使用过react的人应该再熟悉不过了,在hooks还不那么普及的时候,除了使用函数式组件,我们使用最多的应该就是类创建react的组件了,而在类组件中我们通常会使用state来管 ...
- 激光SLAM与视觉SLAM的特点
激光SLAM与视觉SLAM的特点 目前,SLAM技术被广泛运用于机器人.无人机.无人驾驶.AR.VR等领域,依靠传感器可实现机器的自主定位.建图.路径规划等功能.由于传感器不同,SLAM的实现方式也有 ...
- MindSpore 高阶优化器
MindSpore 高阶优化器 MindSpore自研优化器THOR(Trace-based Hardware-driven layer-ORiented Natural Gradient Desce ...