如何利用Python计算景观指数AI
可使用工具包
- pylandstats
- 此工具包基本是根据fragstats形成的,大部分fragstats里面的景观指数,这里都可以计算。但是,还是有一小部分指数这里没有涉及。
- LS_METRICS
自定义的aggregation index(AI)计算
原理
\]
这里的\(e_{ii}\)是同类型像元公共边的个数
\(max\_e_{ii}\)是同类型像元最大公共边的个数, \(max\_e_{ii}\)的计算有公式可寻,具体计算公式如下:
\[\begin{align*}
& max\_eii = 2n(n-1), & when \quad m = 0, or\\
& max\_eii = 2n(n-1) + 2m -1, & when\quad m ≤ n, or\\
& max\_eii = 2n(n-1) + 2m -2, & when \quad m > n.\\
\end{align*}
\]n为不超过某个类型像元总面积\(A_i\)的最大整数正方形的边长
m=\(A_i-n^2\)
实例
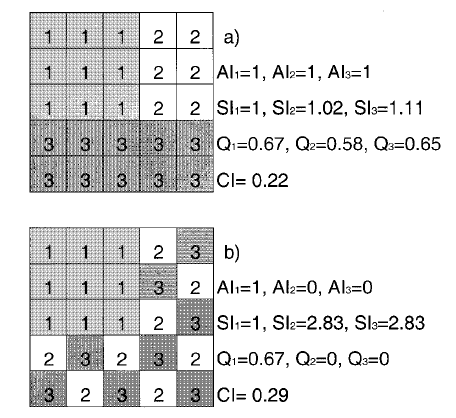
- 例如图a中类型1的聚居指数AI可为:
\[\begin{align*}
&e_{ii}=12\\
&max\_e{ii}=2n(n-1)=2\times3\times2=12\\
&AI=\frac{e_{ii}}{max\_e{ii}}\times100=100
\end{align*}
\]这里AI为100是因为这里乘了一个系数100;
Python实现
- 函数依赖关系

class AI(Landscape, ABC):
def __init__(self, landscape, **kwargs):
super().__init__(landscape, **kwargs)
# 用于计算每种类型公共边的数量
def get_share_edge(self, class_):
# 1.将数据转换为二值型
binary_data = (self.landscape_arr == class_).astype(np.int8)
# 2.设置卷积模板
cov_template = np.array([[0, 0, 0],
[0, 0, 1],
[0, 1, 0]])
# 3.填充边缘
binary_pad = np.pad(binary_data, 1, mode='constant', constant_values=0)
# 4.计算公共边总数
row_num, col_num = binary_pad.shape
count = 0
for i in range(1, row_num - 1):
for j in range(1, col_num - 1):
if binary_pad[i, j] == 1:
count += np.sum(binary_pad[i - 1:i + 2, j - 1:j + 2] * cov_template)
return count
# 计算eii
@property
def eii(self):
return pd.Series([self.get_share_edge(class_) for class_ in self.classes], index=self.classes)
# 计算最大的eii
@property
def max_eii(self):
arr = self.landscape_arr
flat_arr = arr.ravel()
# 规避nodata值
if self.nodata in flat_arr:
a_ser = pd.value_counts(flat_arr).drop(self.nodata).reindex(self.classes)
else:
a_ser = pd.value_counts(flat_arr).reindex(self.classes)
n_ser = np.floor(np.sqrt(a_ser))
m_ser = a_ser - np.square(n_ser)
max_eii = pd.Series(index=a_ser.index)
for i in a_ser.index:
if m_ser[i] == 0:
max_eii[i] = (2 * n_ser[i]) * (n_ser[i] - 1)
elif m_ser[i] <= n_ser[i]:
max_eii[i] = 2 * n_ser[i] * (n_ser[i] - 1) + 2 * m_ser[i] - 1
elif m_ser[i] >= n_ser[i]:
max_eii[i] = 2 * n_ser[i] * (n_ser[i] - 1) + 2 * m_ser[i] - 2
return max_eii
# 计算AI指数
def aggregation_index(self, class_val=None):
"""
计算斑块类型的聚集指数AI
:param class_val: 整型,需要计算AI的斑块类型代号
:return: 标量数值或者Series
"""
if len(self.classes) < 1:
warnings.warn("当前数组全是空值,没有需要计算的类型聚集指数",
RuntimeWarning,
)
return np.nan
if class_val is None:
return (self.eii / self.max_eii) * 100
else:
return ((self.eii / self.max_eii) * 100)[class_val]
参考文献
- An aggregation index (AI) to quantify spatial patterns of landscapes
- http://www.umass.edu/landeco/research/fragstats/documents/Metrics/Contagion - Interspersion Metrics/Metrics/C116 - AI.htm
如何利用Python计算景观指数AI的更多相关文章
- 利用Python计算π的值,并显示进度条
利用Python计算π的值,并显示进度条 第一步:下载tqdm 第二步;编写代码 from math import * from tqdm import tqdm from time import ...
- 利用python计算windows全盘文件md5值的脚本
import hashlib import os import time import configparser import uuid def test_file_md5(file_path): t ...
- 利用python计算多边形面积
最近业务上有一个需求,给出多边形面积. Google了一下,发现国内论坛给的算法都是你抄我我抄你,也不验证一下是否正确, 从 博客园到csdncsdn 然后传播到国内各个角落...真是无力吐槽了. 直 ...
- 利用Python进行数据分析——Numpy基础:数组和矢量计算
利用Python进行数据分析--Numpy基础:数组和矢量计算 ndarry,一个具有矢量运算和复杂广播能力快速节省空间的多维数组 对整组数据进行快速运算的标准数学函数,无需for-loop 用于读写 ...
- 《利用Python进行数据分析·第2版》第四章 Numpy基础:数组和矢量计算
<利用Python进行数据分析·第2版>第四章 Numpy基础:数组和矢量计算 numpy高效处理大数组的数据原因: numpy是在一个连续的内存块中存储数据,独立于其他python内置对 ...
- 利用 Python 尝试采用面向对象的设计方法计算图形面积及周长
利用 Python 尝试采用面向对象的设计方法.(1)设计一个基类 Shape:包含两个成员函数:def cal_area(): 计算并返回该图形的面积,保留两位小数:def cal_perimete ...
- 利用Python进行数据分析_Pandas_汇总和计算描述统计
申明:本系列文章是自己在学习<利用Python进行数据分析>这本书的过程中,为了方便后期自己巩固知识而整理. In [1]: import numpy as np In [2]: impo ...
- 利用Python科学计算处理物理问题(和物理告个别)
背景: 2019年初由于尚未学习量子力学相关知识,所以处于自学阶段.浅显的学习了曾谨言的量子力学一卷和格里菲斯编写的量子力学教材.注重将量子力学的一些基本概念了解并理解.同时老师向我们推荐了Quant ...
- 利用Python进行数据分析(9) pandas基础: 汇总统计和计算
pandas 对象拥有一些常用的数学和统计方法. 例如,sum() 方法,进行列小计: sum() 方法传入 axis=1 指定为横向汇总,即行小计: idxmax() 获取最大值对应的索 ...
随机推荐
- [Linux] Linux命令行与Shell脚本编程大全 Part.2
进程 Linux是多用户系统,多个用户可以在不同地方通过网络连接到一个Linux系统上进行操作 w:显示登录人员信息 date:显示当前日期.时间和时区 up:从开机登录到现在经过的时间 load a ...
- [Qt] 事件机制(二)
在samp4_1中加一个小功能,点击右上角关闭按钮时,弹出"确认是否关闭"的消息框.如果点"yes"则关闭,如果点"No"则不关闭 在wid ...
- wps中新罗马字体如何设置Times New Roman
word wps中新罗马字体如何设置Times New Roman ### WPS字体自带 Times New Roman ###
- 保存 yum 下载的软件包并制作成本地 yum 源
保存 yum 下载的软件包并制作成本地 yum 源 实验对象 CentOS 7 yum 安装 nginx (nginx必须使用第三源才能安装:redhat8版本的则不需要,官网源自带nginx软件包) ...
- cent7 配 yum源
今天笔记配置CentOS 7本地镜像为yum源,废话不多说,上去就是干! 1:挂镜像: ? 1 2 3 4 #创建目标挂载目录 mkdir /media/CentOS7 #将镜像挂载到目标目录 mou ...
- 附: Python爬虫 数据库保存数据
原文 1.笔记 #-*- codeing = utf-8 -*- #@Time : 2020/7/15 22:49 #@Author : HUGBOY #@File : hello_sqlite3.p ...
- 基于多端口的Web服务
[Centos7.4版本] !!!测试环境我们首关闭防火墙和selinux [root@localhost ~]# systemctl stop firewalld [root@localhost ~ ...
- CentOS 7网络配置
修改配置文件 CentOS 7下的网络配置文件路径为:/etc/sysconfig/network-scripts/ifcfg-interfacename 配置文件ifcfg-interface-na ...
- selenium常用代码
from selenium import webdriver # 1. 添加浏览器设置参数对象 options = webdriver.ChromeOptions() # 2. 设置中文,与下载无弹窗 ...
- unity给子物体添加Shader
分享两个自制Shader:http://pan.baidu.com/s/1nuRcF2L Shader存放路径:\Assets\Resources\Shader\ 定义Shader类型: public ...