Fast Run:提高 MegEngine 模型推理性能的神奇功能
作者:王博文 | 旷视 MegEngine 架构师
一、背景
对于深度学习框架来说,网络的训练/推理时间是用户非常看中的。在实际生产条件下,用户设计的 NN 网络是千差万别,即使是同一类数学计算,参数也各不相同。如果没有针对性的优化,框架就完全丧失竞争力。因此,在一类数学计算中,开发者们会开发多种高效的算法,分别适用于不同的参数,以保证网络的性能。接下来开发者们需要解决一个新问题,当计算参数确定以后,如何让最快的算法执行该计算。
大部分框架靠先验的经验选择算法,MegEngine 亦总结有优秀的先验经验值,实现计算时自动选择算法。但是依靠经验不能保证一定选择了最快的算法。很多实际场景中,用户希望网络有最极致的性能。为此,MegEngine 设计了专门的流程,可以为每个计算自动选择最快的算法,从而保证整个网络的运行时间最短。并且同时能够将计算的参数和其对应的算法信息以及设备信息记录到内存或文件,当用户再次运行网络时,可以直接获取性能最好的算法。这一提升性能的流程被称为 Fast Run,它能让 MegEngine 的用户运行不同的网络时都能收获最好的性能。
二、Fast Run 简述
目前,主流的框架几乎都使用了算子(Operator)的概念来抽象数学计算,如卷积算子,矩阵乘算子等。MegEngine 也使用了算子 这一概念。此外,在底层,我们开发了名为 MegDNN 的计算库,用以完成实际的数学计算。 MegDNN 仅提供数学计算能力。MegDNN 的顶层也是按照算子的概念组织的,对不同的后端,分别封装了 MegDNN 算子。一个 MegDNN 算子内部则可能有多个该算子的算法,MegEngine 将算法抽象为 Algorithm,一个 Algorithm 对象可以完成该算子的计算。
以卷积算子为例,ARM 上,MegEngine 实现了非常通用的 Im2col 算法,有特定条件下性能卓越的 Winograd 算法,有在小尺寸卷积时高性能的 Direct 直接卷积算法等。CUDA 上,有调用 cuDNN 库函数的方法等等。从 MegEngine 算子到 MegDNN 算子再到算法的关系如下图所示:
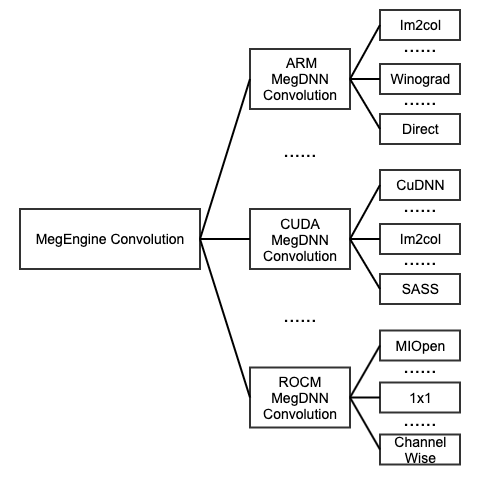
一个 MegEngine 算子可能持有一个或多个 MegDNN 算子来完成计算,一个 MegDNN 算子需要从多个算法对象中选择一个来执行计算。为了极致的计算性能,需要在开始网络计算之前,给 MegDNN 算子选好最快的算法。
Fast Run 的思路很直接,在网络计算开始之前,将每个 MegDNN 算子中所有可行的算法全部运行一次(Profiling),并将性能数据记录下来,将最快的算法设置给 MegDNN 算子。Fast Run 成立的前提条件是算法运行时间是稳定的,这样比较每个算法的 Profiling 数据才有意义。
最后是确定 Fast Run 执行的时间点。MegEngine 有统一的内存管理,各 MegEngine 算子需要在计算开始前向内存规划单元申请足够的计算时内存,这一内存包括了其内部的 MegDNN 算子计算时需要的内存,而 MegDNN 算子计算时需要的内存完全由算法决定。这就要求,MegDNN 此刻已经确定了将要使用的算法。自然地,MegEngine 选择在调用该接口之前执行 Fast Run 流程。这样,当 Fast Run 流程完成时,各 MegDNN 算子都设置了性能最好的算法。
Fast Run 执行的代价是显然的,它会显著增加第一次网络执行的时间。Fast Run 的流程如下图:
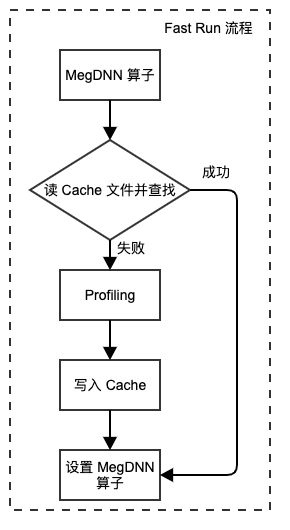
Fast Run 有下面两种使用方式,区别在于上图中写入的 Cache 文件不同:
- 离线 Fast Run,离线 Fast Run 分两步,分别在不同的进程中完成。第一步先将整个网络计算执行一遍,这一过程中,Fast Run 会将各个算法的性能数据写到一个专门的数据结构中,最后数据被统一写入一个 Cache 文件,随后进程退出,这个过程称之为“搜参”。第二步,加载同样的网络,通过 MegEngine 的接口将 Cache 文件读入。可以看出,离线 Fast Run甚至可以在不同的设备上进行。
- 在线 Fast Run,在线 Fast Run 在同一个进程完成的。前半段与离线 Fast Run 的流程相同,Fast Run 后,各算法的性能数据保存在内存中的一个数据结构之中。此时,进程不会退出。后续可以给网络加载不同的输入数据,此时各 MegDNN 算子中已设置好性能最好的算法。并且,也可以初始化另外的网络,亦可以像离线 Fast Run 的后半部分一样,从当前的数据结构中读取算法。
总的来说,Fast Run 提供搜参和记录的功能。它的作用是给网络中的各个 MegDNN 算子选择当前参数下性能最好的算法。由于 Fast Run 对每个 MegDNN 算子执行同样的操作,因此它在前向推理和反向传播时都能使用。目前,MegEngine 支持 CUDA、CPU、ROCM 三个后端的 Fast Run ,MegEngine 的用户们在训练和部署时,均广泛使用 Fast Run。
三、Fast Run 原理
Fast Run 中,Profiling 一个 MegDNN 算子并设置算法,会经历 4 个步骤,其流程如下图示:
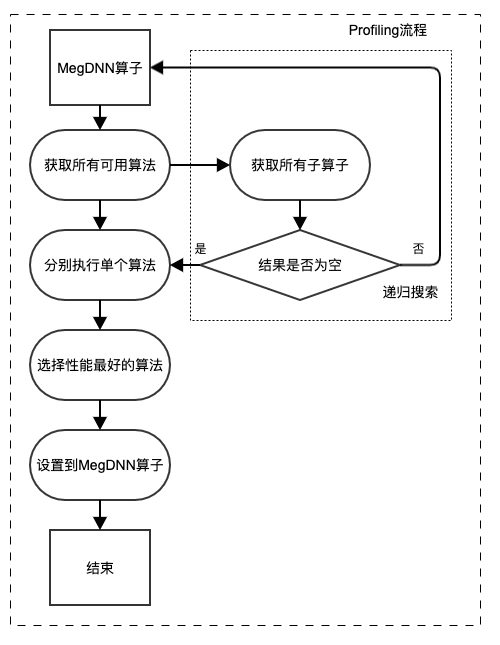
这一流程中,需要注意一些细节:
1、递归搜参:MegDNN 中普遍存在算子嵌套的情况。例如,Convolution 算子中,Im2col 算法会使用 MegDNN 的 MatMul 算子执行矩阵乘计算。那么,Convolution 的性能直接受到 MatMul 性能的影响。可以看到,在 Profiling 一个 Convolution 算子之前,需要 MatMul 算子执行的性能数据已知。为了解决这个问题,Fast Run 使用了递归的方式,来解决搜参时的算子嵌套问题。如上图中虚线框所示,一个 MegDNN 算子,在获取所有可用算法之后,会调用每个算法的接口,询问该算法是否依赖子算子并保存相关结果,若最终相关结果不为空,则会先对子算子进行一次 Profiling,此后,再 Profiling 顶层的算子时,其使用的子算子会有最优的算法保存在 Cache 中。
2、Fast Run 性能数据保存:Fast Run 性能数据存取离不开 Cache。MegEngine 提供了两种 PersistentCache,两种 Cache 区别于数据保存的位置(内存或是文件)。Cache 的结构如下图所示:

MegEngine 中,PersistentCache 对象是单例的,两种 Cache 都保证线程安全。Cache 维护一个从 category 信息到一个集合的映射的集合,此处 category 是一个后端的记录信息。Category 是一个字符串,由后端信息和算子类型拼接获得,后端信息 由设备区分,例如 CUDA 的后端信息由设备名称、NVIDIA 驱动版本和 CUDA 运行时库版本信息组成;CPU 作为后端时,则只记录设备名称。MegEngine 中只有 CUDA、CPU、ROCM 三种类型有对应的 categoty 生成,这也是 MegEngine 目前仅支持在 CUDA、CPU、ROCM 三个后端支持 Fast Run 的原因。算子类型 由算子名称、Cache 版本信息两部分组成。
一个 category 映射到一个集合,该集合维护单个 MegDNN 算子的信息到其所有可用算法的 Profiling 结果的映射。该集合的 key值 由 MegDNN 算子的所有输入 Tensor 的尺寸和算子的全部参数组成(这些参数能够完全决定一个算法是否可用)。value值 是一个数组,保存每个 Profiling 过的算法的时间、所需额外的空间等信息,并排序。排序时,以运行时间进行升序排列,并且保证了序列中每个算法使用的内存必须小于其前一个算法使用的内存 – 这样序列中不存在一个算法既慢于另一个算法,又使用更多的内存。一个 Cache 中可以存在不同后端的 Fast Run 结果,只要它们的 category 不同。
在一些常见的模型上,推理时关闭和开启 Fast Run,性能表现如下:
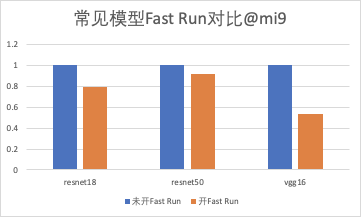
从工程落地中 Fast Run 的使用情况来看,绝大部分场景下,能显著降低网络运行时间。
四、Fast Run 使用
MegEngine 可配置的参数众多,很多都是工程落地的解决方法,在工业上经过大量的实践。其中一些参数与 Fast Run 的使用有密切的关系,这里详细阐述它们的使用。
4.1 开启 Fast Run
源代码级别使用 Fast Run 可以参照 MegEngine 自带的可执行程序 load_and_run,如果仅关注利用 load_and_run 测试模型,有下面两个参数需要使用:
- --full-run/--fast-run,搜参的两种模式,需用户选择其中一种模式,两者的区别在于 Profiling 时,生成的 MegDNN 算子的可用算法集大小不同。--full-run 时,会 Profiling MegDNN 算子内所有的可用算法,包括最朴素的算法(MegDNN 算子至少有一个算法,保证任何参数下均可用,运行慢)。--fast-run 则会排除朴素算法。如果想要减少 Profiling 的时间开销,可以选择使用 --fast-run 模式,此时需要注意的是,如果网络中有参数过于特殊的算子,则该算子可能面临没有可用算法的情况(优化过的算法不可用、朴素的算法被排除),此时 MegEngine 会报出“没有可用算法”的错误并退出。
- --fast-run-algo-policy,指定 Cache 文件的路径,文件中的性能数据会被读入内存,被全局唯一的 PersistentCache 对象持有。进程退出前,PersistentCache 中的性能数据会全部写入该文件。
两个参数可以单独使用,也可以一起使用:
- 单独使用 --full-run/--fast-run,Profiling 数据保存在内存中。
- 两者一起使用,文件中的性能数据首先会被读入内存。如果文件为空,所有 MegDNN 算子完成搜参后,性能数据写回文件。如果文件不为空,且某个 MegDNN 算子能从 Cache 中查询到性能数据,则不会进行搜参,余下不能查到性能数据的,则会搜参。这样实现了断点搜参的功能,MegEngine 称之为“续搜“。如果 Fast Run 时程序因为某些原因异常退出,”续搜“能使 Fast Run 在下一次能够连上。“续搜”也能让多个模型的性能数据可以合并在一个 Cache 文件中。如果所有 MegDNN 算子都能从 Cache 中查到性能数据,则搜参不会发生,网络具有最好的性能。
- 单独使用 --fast-run-algo-policy,文件中的性能数据首先会被读入内存,如果 Cache 中没有记录,不“续搜”,以经验值设置 MegDNN 算子的算法,性能可能不是最优。
在使用 Fast Run 时,可以配合 --verbose 一起使用,程序将详细打印 Fast Run 时的调试信息,包括 MegDNN 算子的名称,输入输出的尺寸信息,设置的算法名称等。如果发现性能不符合预期,比如当加载的模型和 Cache 文件不匹配时,通常会发生“续搜”,造成网络执行时间很长的假象。因此,我们强烈推荐在此时使用 --verbose 参数来观察程序工作是否符合预期。
4.2 算法属性
MegDNN 中某些算法具有独特的属性,会影响向 MegDNN 算子设置算法,当前使用的 属性 有:
- REPRODUCIBLE:具有 REPRODUCIBLE 属性的算法,可保证计算结果比特对齐。Fast Run 中,在从 Cache 中读算法信息时提供了对 REPRODUCIBLE 属性的支持。设置 --reproducible,Fast Run 会从 Cache 中选择性能最好的且具有 REPRODUCIBLE 属性的算法。在 Profiling 阶段,并不区分算法是否 REPRODUCIBLE,这样 Cache 中的算法既有 REPRODUCIBLE 属性的,也有非 REPRODUCIBLE 属性的,具备一定的泛用性。
- NAIVE:只有 MegDNN 中最朴素的算法具有 NAIVE 属性。--full-run 和 --fast-run 的区别就在于 --fast-run 通过该属性筛除了运行最慢的朴素算法。
4.3 weight 前处理
有些算法,在计算时需要对数据进行辅助转换。其中,对权重 weight 的转换可以是一次性的,这样可以节省运行时间。例如 Winograd 算法,其权重可以在进行卷积计算之前转好,节约相当一部分运行时的性能开销。MegEngine 在 GraphCommonOptimizeOptions 中提供了 weight_preprocess 选项来支持部署时权重的提前转换功能。一旦设置 weight_preprocess,对于那些 weight 能够提前转换的算法,其性能数据将不会包含权重转换的时间。简单的说,在搜参阶段设置 weight_preprocess,会影响算法的性能数据,从而 Cache 中算法的性能数据排序可能不同。如果 Cache 是在开启 weight 前处理的情况下搜参得到,部署时务必要开启 weight 前处理以获得更好的性能,否则有性能下降的风险。Fast Run 与 weight 前处理不是必需的关系,两者可以分开使用。不过通常情况下,两者结合使用可以获得更好的性能.
4.4 Fast Run 版本
Fast Run 的版本信息以字符串的形式表示在 Cache 的 category 中。Cache 具有兼容性,可以允许不同的版本的 MegEngine 下的搜参结果集合在同一个 Cache 中,Cache 中看到的是不同的 category。但是用户在使用过程,依然需要注意 Fast Run 的版本。一般地,如果 MegDNN 的算法发生了删除或者是属性的变动,Fast Run 的版本信息会发生变化。Fast Run 版本信息变化后,需要重新搜参。
附:
GitHub:MegEngine 天元
欢迎加入 MegEngine 技术交流 QQ 群:1029741705
Fast Run:提高 MegEngine 模型推理性能的神奇功能的更多相关文章
- 移动端 CPU 的深度学习模型推理性能优化——NCHW44 和 Record 原理方法详解
用户实践系列,将收录 MegEngine 用户在框架实践过程中的心得体会文章,希望能够帮助有同样使用场景的小伙伴,更好地了解和使用 MegEngine ~ 作者:王雷 | 旷视科技 研发工程师 背景 ...
- MegEngine推理性能优化
MegEngine推理性能优化 MegEngine「训练推理一体化」的独特范式,通过静态图优化保证模型精度与训练时一致,无缝导入推理侧,再借助工业验证的高效卷积优化技术,打造深度学习推理侧极致加速方案 ...
- 深度学习框架如何自动选择最快的算法?Fast Run 让你收获最好的性能!
作者:王博文 | 旷视 MegEngine 架构师 一.背景 对于深度学习框架来说,网络的训练/推理时间是用户非常看中的.在实际生产条件下,用户设计的 NN 网络是千差万别,即使是同一类数学计算,参数 ...
- 【翻译】借助 NeoCPU 在 CPU 上进行 CNN 模型推理优化
本文翻译自 Yizhi Liu, Yao Wang, Ruofei Yu.. 的 "Optimizing CNN Model Inference on CPUs" 原文链接: h ...
- 天猫精灵业务如何使用机器学习PAI进行模型推理优化
引言 天猫精灵(TmallGenie)是阿里巴巴人工智能实验室(Alibaba A.I.Labs)于2017年7月5日发布的AI智能语音终端设备.天猫精灵目前是全球销量第三.中国销量第一的智能音箱品牌 ...
- 【机器学习与R语言】13- 如何提高模型的性能?
目录 1.调整模型参数来提高性能 1.1 创建简单的调整模型 2.2 定制调整参数 2.使用元学习来提高性能 2.1 集成学习(元学习)概述 2.2 bagging 2.3 boosting 2.4 ...
- JVM内存模型和性能优化 转
JVM内存模型和性能优化 JVM内存模型优点 内置基于内存的并发模型: 多线程机制 同步锁Synchronization 大量线程安全型库包支持 基于内存的并发机制,粒度灵活控制,灵活度高于 ...
- 使用异步 I/O 大大提高应用程序的性能
使用异步 I/O 大大提高应用程序的性能 学习何时以及如何使用 POSIX AIO API Linux® 中最常用的输入/输出(I/O)模型是同步 I/O.在这个模型中,当请求发出之后,应用程序就会阻 ...
- NS2仿真:公交车移动周期模型及性能分析
NS2仿真实验报告3 实验名称:公交车移动周期模型及性能分析 实验日期:2015年3月16日~2015年3月21日 实验报告日期:2015年3月22日 一.实验环境(网络平台,操作系统,网络拓扑图) ...
随机推荐
- Java源码分析:Guava之不可变集合ImmutableMap的源码分析
一.案例场景 遇到过这样的场景,在定义一个static修饰的Map时,使用了大量的put()方法赋值,就类似这样-- public static final Map<String,String& ...
- Activity侧滑返回的实现原理
简介 使用侧滑Activity返回很常见,例如微信就用到了.那么它是怎么实现的呢.本文带你剖析一下实现原理.我在github上找了一个star有2.6k的开源,我们分析他是怎么实现的 //star 2 ...
- 08-ADMM算法
08-ADMM算法 目录 一.ADMM 算法动机 二.对偶问题 三.对偶上升法 四.对偶分割 五.乘子法(增广拉格朗日函数) 5.1 步长为 $\rho$ 的好处 六.ADMM算法 6.1 ADMM ...
- 仅使用JsonUtility && File类实现Json数据读写
using System.Collections; using System.Collections.Generic; using UnityEngine; using System; using S ...
- Mongo3基础操作
由于3.X的文档是在3.X当前最新版本前记录,所以这里列出一些常用的操作,比如建立库,删除库,等一些格式,然后在描述开启远程和创建用户的一些区别,以及讲解2.X和3.X配置文件区别. 1. Mongo ...
- 免费版:Xshell和Xftp下载路径
家庭版Xshell和Xftp下载地址: 下载地址:https://www.netsarang.com/zh/free-for-home-school/
- Mybatis学习(6)与Spring MVC 的集成
前面几篇文章已经讲到了mybatis与spring 的集成.但这个时候,所有的工程还不是web工程,虽然我一直是创建的web 工程.今天将直接用mybatis与Spring mvc 的方式集成起来,源 ...
- 深入理解 PHP7 中全新的 zval 容器和引用计数机制
深入理解 PHP7 中全新的 zval 容器和引用计数机制 最近在查阅 PHP7 垃圾回收的资料的时候,网上的一些代码示例在本地环境下运行时出现了不同的结果,使我一度非常迷惑. 仔细一想不难发现问题所 ...
- 在CentOS7环境下部署weblogic集群
一)环境准备 服务器操作版本系统 CentOS7 weblogic版本包 weblogic1036_generic.jar(weblogic11g) JDK jdk-8u191-linux-x64.t ...
- DHCP工作原理
DHCP:Dynamic Host Configurtion Protocol DHCP的工作原理(UDP) 1.客户端:首先会发送给一个dhcp discovery(广播)报文,报文中的2层和3层都 ...