数据特征分析:3.统计分析 & 帕累托分析
1.统计分析
统计指标对定量数据进行统计描述,常从集中趋势和离中趋势两个方面进行分析
集中趋势度量 / 离中趋势度量
One.集中趋势度量
指一组数据向某一中心靠拢的倾向,核心在于寻找数据的代表值或中心值 —— 统计平均数
算数平均数、位置平均数(加权平均值) (1)算术平均数 、加权算术平均数
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
% matplotlib inline
# 1、集中趋势度量 (1)算数平均数
data = pd.DataFrame({'value':np.random.randint(100,120,100),
'f':np.random.rand(100)})
data['f'] = data['f'] / data['f'].sum() # f为权重,这里将f列设置成总和为1的权重占比
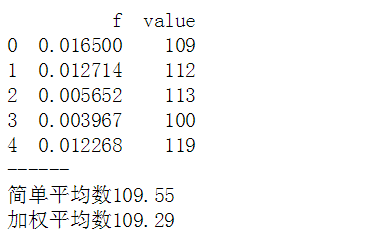
print(data.head())
print('------')
# 创建数据 mean = data['value'].mean()
print('简单平均数%.2f'% mean) # 简单算数平均值 = 总和 / 样本数量 (不涉及权重)
mean_w = (data['value'] * data['f']).sum() / data['f'].sum()
print('加权平均数%.2f'% mean_w)
# 加权算数平均值 = (x1f1 + x2f2 + ... + xnfn) / (f1 + f2 + ... + fn)
(2)位置平均数
data['value'].plot(kind = 'kde',style = '--k',grid = True) 密度曲线; plt.axvline()
# 1、集中趋势度量 (2)位置平均数 m = data['value'].mode().tolist() #变成一个列表,可能不止一个
print('众数为',m) # 众数是一组数据中出现次数最多的数,这里可能返回多个值 med = data['value'].median()
print('中位数为%i'% med) # 中位数指将总体各单位标志按照大小顺序排列后,中间位置的数字
mean = data['value'].mean()
print('简单平均数%.2f'% mean) #中位数和平均数差不多 data['value'].plot(kind = 'kde',style = '--k',grid = True)
# 密度曲线 plt.axvline(mean,hold=None,color='r',linestyle="--",alpha=0.8)
plt.text(mean + 5,0.005,'简单算数平均值为:%.2f' % mean, color = 'r')
# 简单算数平均值 plt.axvline(mean_w,hold=None,color='b',linestyle="--",alpha=0.8)
plt.text(mean + 5,0.01,'加权算数平均值:%.2f' % mean_w, color = 'b')
# 加权算数平均值 plt.axvline(med,hold=None,color='g',linestyle="--",alpha=0.8)
plt.text(mean + 5,0.015,'中位数:%i' % med, color = 'g')
# 中位数
# **这里三个数text显示的横坐标一致,目的是图示效果不拥挤

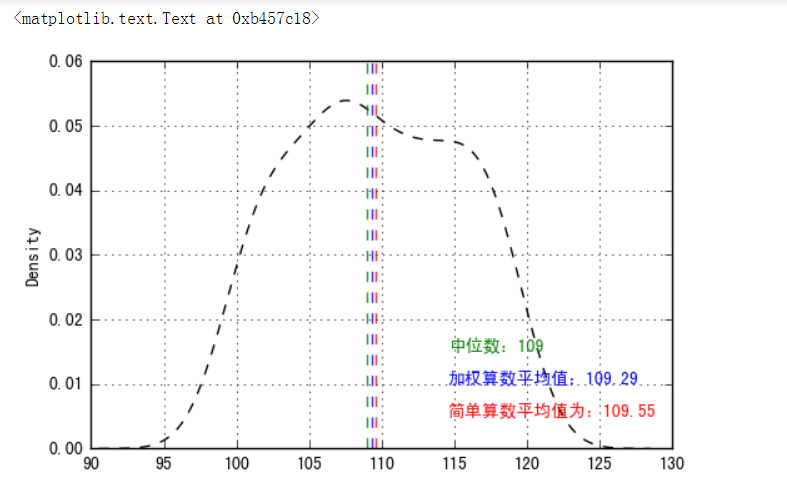
密度曲线,100-150的密度分布,绿色的为中位数,红色的为简单的算术平均值,蓝色的为加权平均值。
Two.离中趋势度量
指一组数据中各数据以不同程度的距离偏离中心的趋势
极差与分位差、方差与标准差、离散系数
(1)极差、分位差
data.plot.box(vert=False, grid=True, color=color, figsize=(10, 3)) #箱型图
# 2、离中趋势度量
data = pd.DataFrame({'A_sale':np.random.rand(30)*1000,
'B_sale':np.random.rand(30)*1000},
index = pd.period_range('',''))
print(data.head())
print('------')
# 创建数据
# A/B销售额量级在同一水平 # (1)极差、分位差
a_r = data['A_sale'].max() - data['A_sale'].min()
b_r = data['B_sale'].max() - data['B_sale'].min()
print('A销售额的极差为:%.2f, B销售额的极差为:%.2f' % (a_r,b_r))
print('------')
# 极差
# 没有考虑中间变量的变动,测定离中趋势不稳定 sta = data['A_sale'].describe()
stb = data['B_sale'].describe()
print(sta)
print('---------')
a_iqr = sta.loc['75%'] - sta.loc['25%']
b_iqr = stb.loc['75%'] - stb.loc['25%']
print('A销售额的分位差为:%.2f, B销售额的分位差为:%.2f' % (a_iqr,b_iqr))
print('------')
# 分位差 color = dict(boxes='DarkGreen', whiskers='DarkOrange', medians='DarkBlue', caps='Gray')
data.plot.box(vert=False, grid=True, color=color, figsize=(10, 3)) #箱型图
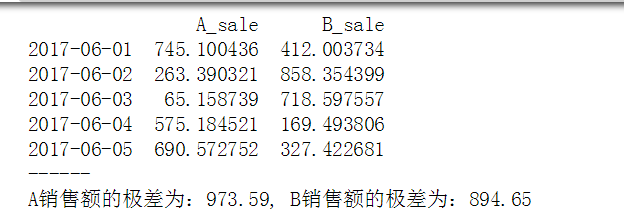

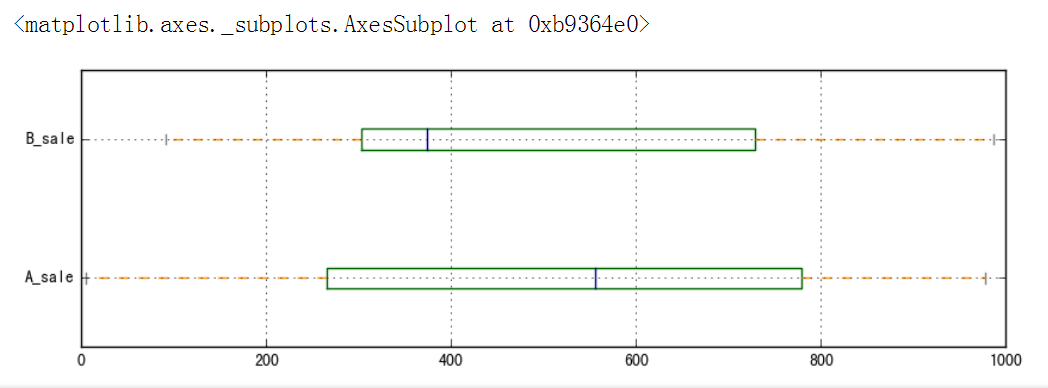
极差只能反映值的区间,不能反映里边内部的波动情况,极差越小离中趋势越小。
(2)方差与标准差
# 2、离中趋势度量
# (2)方差与标准差 a_std = sta.loc['std'] #标准差直接做个平方
b_std = stb.loc['std']
a_var = data['A_sale'].var() #方差就用到了.var() 标准差.describe()
b_var = data['B_sale'].var()
print('A销售额的标准差为:%.2f, B销售额的标准差为:%.2f' % (a_std,b_std))
print('A销售额的方差为:%.2f, B销售额的方差为:%.2f' % (a_var,b_var))
# 方差 → 各组中数值与算数平均数离差平方的算术平均数
# 标准差 → 方差的平方根
# 标准差是最常用的离中趋势指标 → 标准差越大,离中趋势越明显

data['A_sale'].plot(kind = 'kde',style = 'k--',grid = True,title = 'A密度曲线')
中位数-标准差 、 中文书+标准差
fig = plt.figure(figsize = (12,4))
ax1 = fig.add_subplot(1,2,1)
data['A_sale'].plot(kind = 'kde',style = 'k--',grid = True,title = 'A密度曲线')
plt.axvline(sta.loc['50%'],hold=None,color='r',linestyle="--",alpha=0.8)
plt.axvline(sta.loc['50%'] - a_std,hold=None,color='b',linestyle="--",alpha=0.8) #一个中位数-标准差
plt.axvline(sta.loc['50%'] + a_std,hold=None,color='b',linestyle="--",alpha=0.8) #一个中位数+标准差
# A密度曲线,1个标准差 ax2 = fig.add_subplot(1,2,2)
data['B_sale'].plot(kind = 'kde',style = 'k--',grid = True,title = 'B密度曲线')
plt.axvline(stb.loc['50%'],hold=None,color='r',linestyle="--",alpha=0.8)
plt.axvline(stb.loc['50%'] - b_std,hold=None,color='b',linestyle="--",alpha=0.8)
plt.axvline(stb.loc['50%'] + b_std,hold=None,color='b',linestyle="--",alpha=0.8)
# B密度曲线,1个标准差

它们的中位数是差不多的,A的两个标准差之间的距离是 小于 B曲线两个标准差之间的长度的,A相当于B来说更集中。
总结:
对于集中度和离中度就用到这几个指标,对于集中度看中间那个数值的(包括均值、算术平均值、位置平均数 );离中趋势看极差、标准差、方差。
2. 帕累托分析
帕累托分析(贡献度分析) → 帕累托法则:20/80定律
“原因和结果、投入和产出、努力和报酬之间本来存在着无法解释的不平衡。一般来说,投入和努力可以分为两种不同的类型:
多数,它们只能造成少许的影响;少数,它们造成主要的、重大的影响。”
→ 一个公司,80%利润来自于20%的畅销产品,而其他80%的产品只产生了20%的利润
例如:
** 世界上大约80%的资源是由世界上15%的人口所耗尽的
** 世界财富的80%为25%的人所拥有;在一个国家的医疗体系中
** 20%的人口与20%的疾病,会消耗80%的医疗资源。
一个思路:通过二八原则,去寻找关键的那20%决定性因素!
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
% matplotlib inline
data = pd.Series(np.random.randn(10)*1200 + 3000,
index = list('ABCDEFGHIJ')) #10个产品的销售额
data.sort_values(ascending = False, inplace = True) #从大到小排序
data

plt.figure(figsize = (10, 4))
data.plot(kind = 'bar', color = 'g', alpha = 0.8, width = 0.6)#做一个柱状图
plt.ylabel('营收_元')
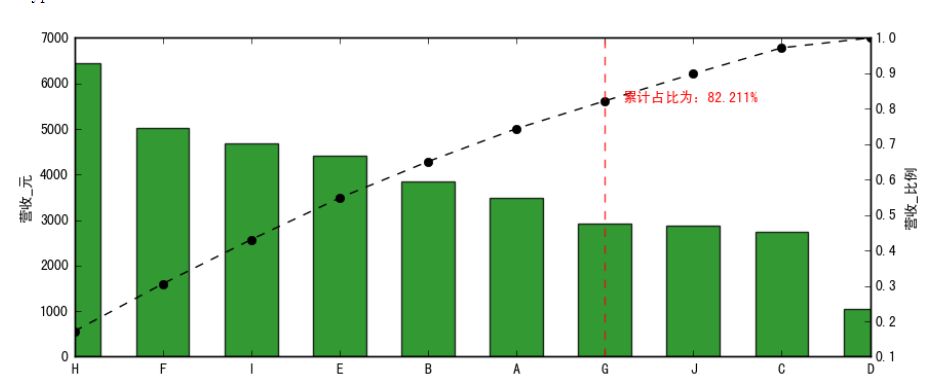
# 创建营收柱状图 p = data.cumsum()/data.sum() #累计占比,除个总和;大于0.8的在C产品
key = p[p>0.8].index[0] #p[p>0.8].index -->Index(['J', 'G', 'B'], dtype='object')
key_num = data.index.tolist().index(key) #找到对应的索引序号
print('超过80%累计占比的节点值索引为:' ,key)
print('超过80%累计占比的节点值索引位置为:' ,key_num)
print('------')
# 找到累计占比超过80%时候的index
# 找到key所对应的索引位置 p.plot(style = '--ko', secondary_y=True)#累计占比曲折线图,累计占比;# secondary_y → y副坐标轴,用次坐标轴
plt.axvline(key_num, hold = None, color = 'r', linestyle = '--', alpha = 0.8)#把80%占比那个参考线画出来,直接是key_num,因为它是X轴的索引值
plt.text(key_num+0.2,p[key],'累计占比为:%.3f%%' % (p[key]*100), color = 'r') # 累计占比超过80%的节点
plt.ylabel('营收_比例')
# 绘制营收累计占比曲线 key_product = data.loc[:key]
print('核心产品为:')
print(key_product)
# 输出决定性因素产品

数据特征分析:3.统计分析 & 帕累托分析的更多相关文章
- 数据可视化之分析篇(一)使用Power BI进行动态帕累托分析
https://zhuanlan.zhihu.com/p/57763423 通过简单的点击交互,就能进行动态分析发现见解,才是我们需要的,恰好这也是 PowerBI 所擅长的. 就帕累托分析来说,能从 ...
- 数据可视化之PowerQuery篇(十一)使用Power BI进行动态帕累托分析
https://zhuanlan.zhihu.com/p/57763423 上篇文章介绍了帕累托图的用处以及如何制作一个简单的帕累托图,在 PowerBI 中可以很方便的生成,但若仅止于此,并不足以体 ...
- 帕累托分析法(Pareto Analysis)(柏拉图分析)
帕累托分析法(Pareto Analysis)(柏拉图分析) ABC分类法是由意大利经济学家帕雷托首创的.1879年,帕累托研究个人收入的分布状态图是地,发现少数人收入占全部人口收入的大部分,而多数人 ...
- 数据特征分析:1.基础分析概述& 分布分析
基础分析概述 几个基础分析思路: 分布分析 对比分析 统计分析 帕累托分析 正态性检测 相关性分析 分布分析 分布分析是研究数据的分布特征和分布类型,分定量数据.定性数据区分基本统计量. import ...
- 数据可视化之powerBI技巧(四)使用Power BI制作帕累托图
各种复杂现象的背后,其实都是受关键的少数因素和普通的大多数因素所影响,把主要精力放在关键的少数因素上,就能达到事半功倍的效果. 这就是大家常说的二八原则,也称为帕累托原则,最早是由意大利经济学家 V. ...
- 帕累托分布(Pareto distributions)、马太效应
什么是帕累托分布 帕累托分布是以意大利经济学家维弗雷多·帕雷托命名的. 是从大量真实世界的现象中发现的幂次定律分布.这个分布在经济学以外,也被称为布拉德福分布. 帕累托因对意大利20%的人口拥有80% ...
- tableau-创建帕累托图
参考文献:https://onlinehelp.tableau.com/current/pro/desktop/zh-cn/pareto.html 帕累托图是一种按发生频率排序的特殊直方图.在质量管理 ...
- Tableau绘图一热图、日历图、人口金字塔、标靶图、凹凸图、帕累托图
Tableau绘图一热图.日历图.人口金字塔.标靶图.凹凸图.帕累托图 本文首发于博客冰山一树Sankey,去博客浏览效果更好.直接右上角搜索该标题即可 一.热图 例子:示例超市 可以通过更改颜色来改 ...
- FusionCharts 2D帕累托图
1.了解帕累托图的特性以及和其他图的共性 2.设计帕累托图页面中引入图的类型以及怎么引入到页面 Pareto2D.html: <!DOCTYPE HTML PUBLIC "-//W3C ...
随机推荐
- django.db.utils.OperationalError: (1049, "Unknown database 'djangodb'")
DATABASES = { 'default': { 'ENGINE':'django.db.backends.mysql', 'NAME': 'mysql', 'USER':'root', 'PAS ...
- 连接mysql(建表和删表)
from sqlalchemy.ext.declarative import declarative_base##拿到父类from sqlalchemy import Column##拿到字段from ...
- Dnsmasq加速本地DNS请求
文章目录 Dnsmasq安装 Dnsmasq配置 Dnsmasq启动 Dnsmasq使用 Dnsmasq小结 默认的情况下,我们平时上网用的本地DNS服务器都是使用电信或者联通的,但是这样也导致了 ...
- WPF窗体的生命周期
和所有类一样,窗口也有生存期,在第一次实例化窗口时生存期开始,然后就可以显示.激活和停用窗口,直到最终关闭窗口. 1.显示窗体 构造函数 Show().ShowDialog()方法:Show()方法显 ...
- vmware 下找不到ifcfg-eth0的问题
找不大 eth0网卡,也就连不上网络,症状是ifconfig以后只现实lo,不显示eth0 ifconfig,显示的ip是ifcfg-lo的ip 解决办法 . 拷贝cp ifcfg-lo ifcfg- ...
- kernel_size
kernel_size=(1,3)[flag] if flag==True:kernel_size=3 else: kernel_size=1
- Spark启动时的master参数以及Spark的部署方式
我们在初始化SparkConf时,或者提交Spark任务时,都会有master参数需要设置,如下: conf = SparkConf().setAppName(appName).setMaster(m ...
- 放一点百度来的,常见的windowserror
0操作成功完成.1功能错误.2系统找不到指定的文件.3系统找不到指定的路径.4系统无法打开文件.5拒绝访问.6句柄无效.7存储控制块被损坏.8存储空间不足,无法处理此命令.9存储控制块地址无效.10环 ...
- redis-4.0.8 配置文件解读
# Redis configuration file example.## Note that in order to read the configuration file, Redis must ...
- python函数之各种器
一: 装饰器 1:装饰器模板 def wrapper(func): def inner(*args,**kwargs): ret =func(*args,**kwargs) return ret re ...