Reinforcement Learning: An Introduction读书笔记(4)--动态规划
> 目 录 <
- Dynamic programming
- Policy Evaluation (Prediction)
- Policy Improvement
- Policy Iteration
- Value Iteration
- Asynchronous Dynamic Programming
- Generalized Policy Iteration
> 笔 记 <
Dynamic programming(DP)
定义:a collection of algorithms that can be used to compute optimal policies given a perfect model of the environment as a Markov decision process (MDP).
经典的DP算法处理RL problem的能力有限的原因:(1) 假设a perfect model with complete knowledge;(2) 巨大的计算开销
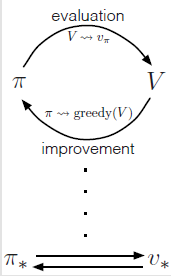
Policy Evaluation (Prediction)
policy evaluation: the iterative computation of the state-value function $v_{\pi}$ for a given policy $\pi$.

用迭代=的方法实现评估: 旧的value = expected immediate rewards + 从后继states获得的values
这种更新操作叫做expected update,因为它基于所有可能的后继states的期望,而非单个next state sample。
存储方式:有two-array version(同时存储old和new value) 和 in-place algorithm(只存储new value)两种,通常采用后者,收敛的更快。

Policy Improvement
我们计算policy的价值函数的目的是希望能够帮助我们找到更好的policy。
Policy improvement theorem:
两个确定的策略$\pi$和$\pi'$,如果满足:
那么策略$\pi'$一定比$\pi$好or跟它一样好。因此,策略$\pi'$可以在所有state上得到更多or相等的expected return:
证明如下:
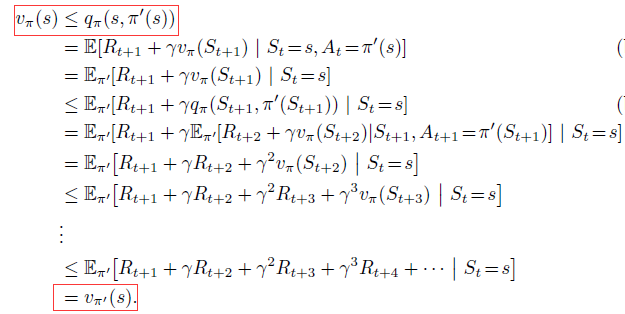
Policy improvement:
定义: Policy improvement refers to the computation of an improved policy given the value function for that policy.
相比原始策略$\pi$,如果我们在所有states上采用贪心算法来选择action,那么得到的新策略如下:
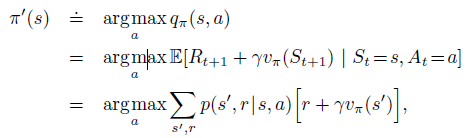
因为其满足policy improvement theorem的条件,所以新的greedy policy $\pi'$要比old policy更好。我们可以根据这一性质,不断地对policy进行改进,直到new policy和old policy一样好,即$v_{\pi}=v_{\pi'}$,此时对所有的states满足:
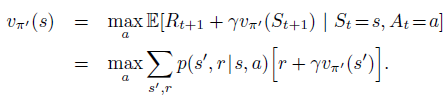
该式子正是Bellman optimality equation,因此$v_{\pi'}$一定是$\v_{*}$, 策略$\pi$和$\pi‘’$一定是最优策略。
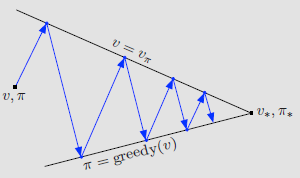
Policy Iteration
定义: 一种把policy evaluation和policy improvement结合在一起的常见的DP方法。
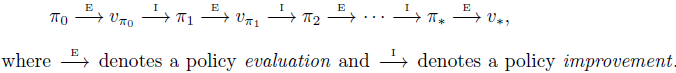
因为finite MDP只有有限数量的策略,因此最终总会在有限步数内收敛到一个optimal policy和optimal value function。

Value Iteration
policy iteration的缺点:每一轮迭代都需要执行policy evaluation,而policy evaluation需要对state set扫描多次并且$\v_{\pi}$最终很久才能收敛。
改进方法:可否让policy evaluation早一些停止?value iteration不再等policy evaluation收敛,而是只对所有state扫描一次就停止。将policy evaluation和policy improvement的步骤同时进行:

Asynchronous Dynamic Programming
之前讨论的DP方法的缺点在于:需要对MDP中所有states进行扫描、操作,导致效率低下。
Asynchronous DP algorithms: 是in-place iterative DP algorithms,这类算法可以按照任意顺序更新state的value,并且不管其他states当前的value是何时更新的。
需要注意的是,avoiding state sweeps并不意味着我们可以减少计算量,其好处是(1) 可以让我们尽快利用更新后的value来提升policy,并且减少更新那些无用的states。(2)可以实时计算,所以可以实现iterative DP algorithm at the same time that agent is actually experiencing the MDP。agent经历可以用于决定更新那些states。
Generalized Policy Iteration
generalized policy iteration (GPI):policy-evaluation and policy-improvement processes interaction
Reinforcement Learning: An Introduction读书笔记(4)--动态规划的更多相关文章
- Reinforcement Learning: An Introduction读书笔记(3)--finite MDPs
> 目 录 < Agent–Environment Interface Goals and Rewards Returns and Episodes Policies and Val ...
- Reinforcement Learning: An Introduction读书笔记(1)--Introduction
> 目 录 < learning & intelligence 的基本思想 RL的定义.特点.四要素 与其他learning methods.evolutionary m ...
- Reinforcement Learning: An Introduction读书笔记(2)--多臂机
> 目 录 < k-armed bandit problem Incremental Implementation Tracking a Nonstationary Problem ...
- 《Machine Learning Yearing》读书笔记
——深度学习的建模.调参思路整合. 写在前面 最近偶尔从师兄那里获取到了吴恩达教授的新书<Machine Learning Yearing>(手稿),该书主要分享了神经网络建模.训练.调节 ...
- Machine Learning for hackers读书笔记(六)正则化:文本回归
data<-'F:\\learning\\ML_for_Hackers\\ML_for_Hackers-master\\06-Regularization\\data\\' ranks < ...
- 《算法导论》读书笔记之动态规划—最长公共子序列 & 最长公共子串(LCS)
From:http://my.oschina.net/leejun2005/blog/117167 1.先科普下最长公共子序列 & 最长公共子串的区别: 找两个字符串的最长公共子串,这个子串要 ...
- Machine Learning for hackers读书笔记(三)分类:垃圾邮件过滤
#定义函数,打开每一个文件,找到空行,将空行后的文本返回为一个字符串向量,该向量只有一个元素,就是空行之后的所有文本拼接之后的字符串 #很多邮件都包含了非ASCII字符,因此设为latin1就可以读取 ...
- Machine Learning for hackers读书笔记_一句很重要的话
为了培养一个机器学习领域专家那样的直觉,最好的办法就是,对你遇到的每一个机器学习问题,把所有的算法试个遍,直到有一天,你凭直觉就知道某些算法行不通.
- Machine Learning for hackers读书笔记(十二)模型比较
library('ggplot2')df <- read.csv('G:\\dataguru\\ML_for_Hackers\\ML_for_Hackers-master\\12-Model_C ...
随机推荐
- 脑残式网络编程入门(二):我们在读写Socket时,究竟在读写什么?
1.引言 本文接上篇<脑残式网络编程入门(一):跟着动画来学TCP三次握手和四次挥手>,继续脑残式的网络编程知识学习 ^_^. 套接字socket是大多数程序员都非常熟悉的概念,它是计算机 ...
- 每天学点SpringCloud(八):使用Apollo做配置中心
由于Apollo支持的图形化界面相对于我们更加的友好,所以此次我们使用Apollo来做配置中心 本篇文章实现了使用Apollo配置了dev和fat两个环境下的属性配置.Apollo官方文档https: ...
- C++ Opencv Mat类型使用的几个注意事项及自写函数实现Laplace图像锐化
为了提升自己对Opencv中Mat数据类型的熟悉和掌握程度,自己尝试着写了一下Laplace图像锐化函数,一路坎坷,踩坑不断.现将代码分享如下: #include <opencv2/opencv ...
- 微信小程序web-view实例
微信小程序web-view实例 index.js //index.js //获取应用实例 const app = getApp() Page({ /** * 页面的初始数据 */ data: { }, ...
- 初识vw和vh
最近在项目里突然看到了一行css代码,height:100vh; 一时间有点蒙蔽 因为之前有听过这个css3新增单位,但没有去了解过. 那这个单位又跟px,rem,em,%有什么不同呢? 简述: ...
- WHERE 子句用于规定选择的标准
WHERE 子句 如需有条件地从表中选取数据,可将 WHERE 子句添加到 SELECT 语句. (也称条件查询语句) 语法SELECT 列名称 FROM 表名称 WHERE 列 运算符 值 下面的& ...
- iOS学习——(转)NSObject详解
本文主要转载自:ios开发 之 NSObject详解 NSObject是大部分Objective-C类继承体系的根类.这个类遵循NSObject协议,提供了一些通用的方法,对象通过继承NSObject ...
- Kubernetes集群搭建之Etcd集群配置篇
介绍 etcd 是一个分布式一致性k-v存储系统,可用于服务注册发现与共享配置,具有以下优点. 简单 : 相比于晦涩难懂的paxos算法,etcd基于相对简单且易实现的raft算法实现一致性,并通过g ...
- Git+Hexo搭建个人博客详细过程
通过Git+Hexo搭建的个人博客地址:https://liangh.top/ 1.安装Node.js.配置好Node.js环境.安装Git和配置好Git环境,打开cmd命令行,成功界面如下 2.安装 ...
- State状态模式
1.简介 在日常开发中,某些对象的状态如果发生改变,对应的行为也将发生改变,那么如何在运行时根据对象的状态动态的改变对象的行为,同时不产生紧耦合关系(即使用if else或者swith所带来的紧耦合关 ...