使用SimHash进行海量文本去重[转]
阅读目录
在之前的两篇博文分别介绍了常用的hash方法([Data Structure & Algorithm] Hash那点事儿)以及局部敏感hash算法([Algorithm] 局部敏感哈希算法(Locality Sensitive Hashing)),本文介绍的SimHash是一种局部敏感hash,它也是Google公司进行海量网页去重使用的主要算法。
1. SimHash与传统hash函数的区别
传统的Hash算法只负责将原始内容尽量均匀随机地映射为一个签名值,原理上仅相当于伪随机数产生算法。传统的hash算法产生的两个签名,如果原始内容在一定概率下是相等的;如果不相等,除了说明原始内容不相等外,不再提供任何信息,因为即使原始内容只相差一个字节,所产生的签名也很可能差别很大。所以传统的Hash是无法在签名的维度上来衡量原内容的相似度,而SimHash本身属于一种局部敏感哈希算法,它产生的hash签名在一定程度上可以表征原内容的相似度。
我们主要解决的是文本相似度计算,要比较的是两个文章是否相识,当然我们降维生成了hash签名也是用于这个目的。看到这里估计大家就明白了,我们使用的simhash就算把文章中的字符串变成 01 串也还是可以用于计算相似度的,而传统的hash却不行。我们可以来做个测试,两个相差只有一个字符的文本串,“你妈妈喊你回家吃饭哦,回家罗回家罗” 和 “你妈妈叫你回家吃饭啦,回家罗回家罗”。
通过simhash计算结果为:
1000010010101101111111100000101011010001001111100001001011001011
1000010010101101011111100000101011010001001111100001101010001011
通过传统hash计算为:
0001000001100110100111011011110
1010010001111111110010110011101
大家可以看得出来,相似的文本只有部分 01 串变化了,而普通的hash却不能做到,这个就是局部敏感哈希的魅力。
2. SimHash算法思想
假设我们有海量的文本数据,我们需要根据文本内容将它们进行去重。对于文本去重而言,目前有很多NLP相关的算法可以在很高精度上来解决,但是我们现在处理的是大数据维度上的文本去重,这就对算法的效率有着很高的要求。而局部敏感hash算法可以将原始的文本内容映射为数字(hash签名),而且较为相近的文本内容对应的hash签名也比较相近。SimHash算法是Google公司进行海量网页去重的高效算法,它通过将原始的文本映射为64位的二进制数字串,然后通过比较二进制数字串的差异进而来表示原始文本内容的差异。
3. SimHash流程实现
simhash是由 Charikar 在2002年提出来的,本文为了便于理解尽量不使用数学公式,分为这几步:
(注:具体的事例摘自Lanceyan的博客《海量数据相似度计算之simhash和海明距离》)
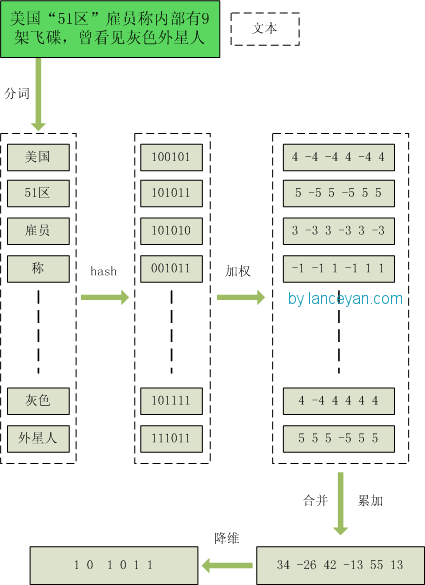
1、分词,把需要判断文本分词形成这个文章的特征单词。最后形成去掉噪音词的单词序列并为每个词加上权重,我们假设权重分为5个级别(1~5)。比如:“ 美国“51区”雇员称内部有9架飞碟,曾看见灰色外星人 ” ==> 分词后为 “ 美国(4) 51区(5) 雇员(3) 称(1) 内部(2) 有(1) 9架(3) 飞碟(5) 曾(1) 看见(3) 灰色(4) 外星人(5)”,括号里是代表单词在整个句子里重要程度,数字越大越重要。
2、hash,通过hash算法把每个词变成hash值,比如“美国”通过hash算法计算为 100101,“51区”通过hash算法计算为 101011。这样我们的字符串就变成了一串串数字,还记得文章开头说过的吗,要把文章变为数字计算才能提高相似度计算性能,现在是降维过程进行时。
3、加权,通过 2步骤的hash生成结果,需要按照单词的权重形成加权数字串,比如“美国”的hash值为“100101”,通过加权计算为“4 -4 -4 4 -4 4”;“51区”的hash值为“101011”,通过加权计算为 “ 5 -5 5 -5 5 5”。
4、合并,把上面各个单词算出来的序列值累加,变成只有一个序列串。比如 “美国”的 “4 -4 -4 4 -4 4”,“51区”的 “ 5 -5 5 -5 5 5”, 把每一位进行累加, “4+5 -4+-5 -4+5 4+-5 -4+5 4+5” ==》 “9 -9 1 -1 1 9”。这里作为示例只算了两个单词的,真实计算需要把所有单词的序列串累加。
5、降维,把4步算出来的 “9 -9 1 -1 1 9” 变成 0 1 串,形成我们最终的simhash签名。 如果每一位大于0 记为 1,小于0 记为 0。最后算出结果为:“1 0 1 0 1 1”。
整个过程的流程图为:
4. SimHash签名距离计算
我们把库里的文本都转换为simhash签名,并转换为long类型存储,空间大大减少。现在我们虽然解决了空间,但是如何计算两个simhash的相似度呢?难道是比较两个simhash的01有多少个不同吗?对的,其实也就是这样,我们通过海明距离(Hamming distance)就可以计算出两个simhash到底相似不相似。两个simhash对应二进制(01串)取值不同的数量称为这两个simhash的海明距离。举例如下: 10101 和 00110 从第一位开始依次有第一位、第四、第五位不同,则海明距离为3。对于二进制字符串的a和b,海明距离为等于在a XOR b运算结果中1的个数(普遍算法)。
5. SimHash存储和索引
经过simhash映射以后,我们得到了每个文本内容对应的simhash签名,而且也确定了利用汉明距离来进行相似度的衡量。那剩下的工作就是两两计算我们得到的simhash签名的汉明距离了,这在理论上是完全没问题的,但是考虑到我们的数据是海量的这一特点,我们是否应该考虑使用一些更具效率的存储呢?其实SimHash算法输出的simhash签名可以为我们很好建立索引,从而大大减少索引的时间,那到底怎么实现呢?
这时候大家有没有想到hashmap呢,一种理论上具有O(1)复杂度的查找数据结构。我们要查找一个key值时,通过传入一个key就可以很快的返回一个value,这个号称查找速度最快的数据结构是如何实现的呢?看下hashmap的内部结构:
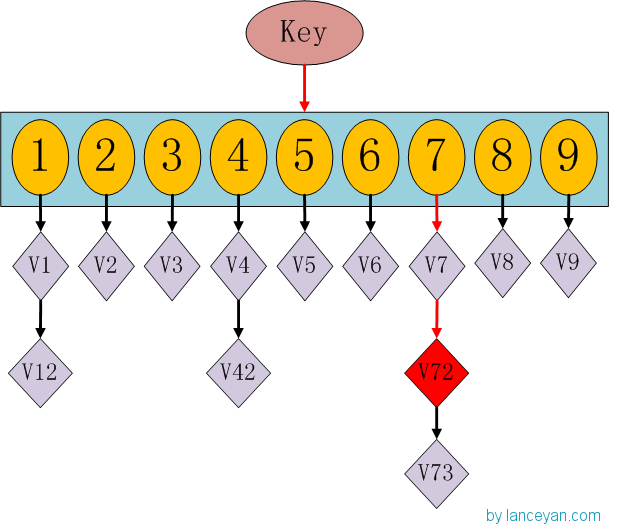
如果我们需要得到key对应的value,需要经过这些计算,传入key,计算key的hashcode,得到7的位置;发现7位置对应的value还有好几个,就通过链表查找,直到找到v72。其实通过这么分析,如果我们的hashcode设置的不够好,hashmap的效率也不见得高。借鉴这个算法,来设计我们的simhash查找。通过顺序查找肯定是不行的,能否像hashmap一样先通过键值对的方式减少顺序比较的次数。看下图:
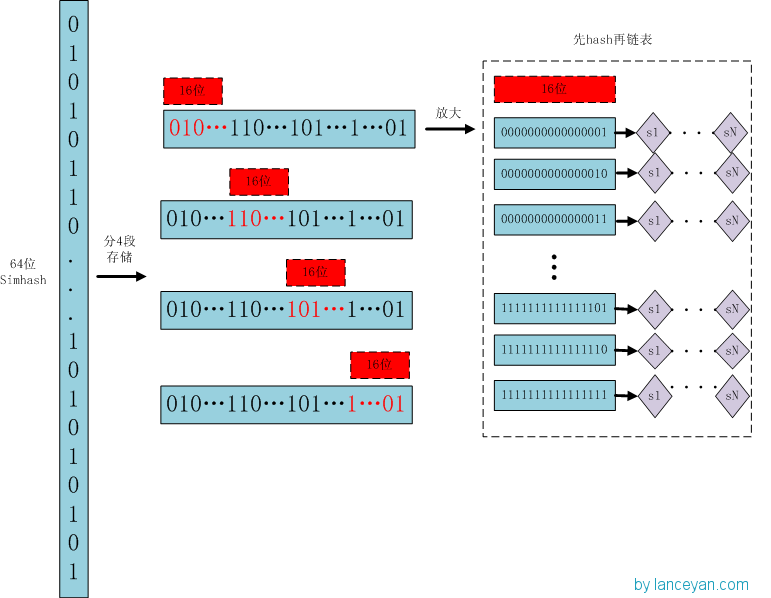
存储:
1、将一个64位的simhash签名拆分成4个16位的二进制码。(图上红色的16位)
2、分别拿着4个16位二进制码查找当前对应位置上是否有元素。(放大后的16位)
3、对应位置没有元素,直接追加到链表上;对应位置有则直接追加到链表尾端。(图上的 S1 — SN)
查找:
1、将需要比较的simhash签名拆分成4个16位的二进制码。
2、分别拿着4个16位二进制码每一个去查找simhash集合对应位置上是否有元素。
3、如果有元素,则把链表拿出来顺序查找比较,直到simhash小于一定大小的值,整个过程完成。
原理:
借鉴hashmap算法找出可以hash的key值,因为我们使用的simhash是局部敏感哈希,这个算法的特点是只要相似的字符串只有个别的位数是有差别变化。那这样我们可以推断两个相似的文本,至少有16位的simhash是一样的。具体选择16位、8位、4位,大家根据自己的数据测试选择,虽然比较的位数越小越精准,但是空间会变大。分为4个16位段的存储空间是单独simhash存储空间的4倍。之前算出5000w数据是 382 Mb,扩大4倍1.5G左右,还可以接受
6. SimHash存储和索引
1. 当文本内容较长时,使用SimHash准确率很高,SimHash处理短文本内容准确率往往不能得到保证;
2. 文本内容中每个term对应的权重如何确定要根据实际的项目需求,一般是可以使用IDF权重来进行计算。
7. 参考内容
1. 严澜的博客《海量数据相似度计算之simhash短文本查找》
2. 《Similarity estimation techniques from rounding algorithms》
3. TF-IDF原理
使用SimHash进行海量文本去重[转]的更多相关文章
- [Algorithm] 使用SimHash进行海量文本去重
在之前的两篇博文分别介绍了常用的hash方法([Data Structure & Algorithm] Hash那点事儿)以及局部敏感hash算法([Algorithm] 局部敏感哈希算法(L ...
- 使用SimHash进行海量文本去重[转载]
阅读目录 1. SimHash与传统hash函数的区别 2. SimHash算法思想 3. SimHash流程实现 4. SimHash签名距离计算 5. SimHash存储和索引 6. SimHas ...
- 使用SimHash进行海量文本去重
阅读目录 1. SimHash与传统hash函数的区别 2. SimHash算法思想 3. SimHash流程实现 4. SimHash签名距离计算 5. SimHash存储和索引 6. SimHas ...
- 文本去重之SimHash算法
文本去重之SimHash算法 - pathenon的个人页面 - 开源中国社区 文本去重之SimHash算法
- 从海量文本中统计出前k个频率最高的词语
现有如下题目:有一个海量文本,存储的是汉语词语,要求从中找出前K个出现频率最高的词语,写出最优算法,兼顾时间和空间复杂度. 思路分析:熟悉搜索引擎的程序员,应该不是难题.用传统的HashMap是无法解 ...
- 初识【Windows API】--文本去重
最近学习操作系统中,老师布置了一个作业,运用系统调用函数删除文件夹下两个重复文本类文件,Linux玩不动,于是就只能在Windows下进行了. 看了一下介绍Windows API的博客: 点击打开 基 ...
- 能用Shell就别编程-海量文本型数据的处理
对于txt文本类数据,优先采用shell脚本,实在不行才用Python,Java,MySQL 1) Shell命令行或脚本的处理速度极快,比Java快得多. 2) Shell代码量少,几个命令就能完成 ...
- 文本去重之MinHash算法
1.概述 跟SimHash一样,MinHash也是LSH的一种,可以用来快速估算两个集合的相似度.MinHash由Andrei Broder提出,最初用于在搜索引擎中检测重复网页.它也可以应用 ...
- VB6 Collection实现百万文本去重
上一篇数组的去重说到,对于千次计算以上的去重基本上特别的吃力,这里就介绍一种方法,通过Collection集合对象来过滤重复. Option Explicit '//By: InkHin '// 参考 ...
随机推荐
- nexys4ddr数码管动态扫描Verilog例程
题目:实现数码管动态扫描功能,将十六个开关的值以十六进制的方式在4个数码管上同时显示出来. `timescale 1ns / 1ps module top( clk, sw, seg, an ); / ...
- QWidget-控件层级关系
lower() 将控件降低到最底层 raise_() 将控件提升到最上层 label.raise_() a.stackUnder(b) 让a放在b下面 注意:以上操作专指同级控件 ...
- ue4 蓝图方法备份
normalized 标准化 向量标准化 +- 1,1,1 内的值 角度标准化 +-180内的值 delta A-B (输出时roll在后面) 角度相减 interp 插值运算 (做平滑移动常用) ...
- luogu P5234 [JSOI2012]越狱老虎桥
传送门 题目要求割掉一条边后使得图不连通,那么可以使用tarjan算法求出所有的割边,然后把边双缩成点,就能得到一棵树,现在问题是在加入一条边的情况下,割掉最小的一条边使得图不连通,割掉的这条边权值最 ...
- webpack学习笔记——解决多次输出的问题&自动编译之启用观察者模式,热重载
[解决多次输出的问题] 昨天学会了用命令打包,如下 webpack entry.js bundle.js 但是会出现多次输出要表现的内容的问题,如下,执行几次上述命令,显示几次,原因是并没有清除之前输 ...
- Spark思维导图之性能优化
- Socket与TCP,UDP
什么是socket 简单来说是IP地址与端口的结合协议(RFC 793) 一种地址与端口的结合描述协议 TCP/IP协议的 相关API的总称:是网络api的集合实现 涵盖了:Stream Socket ...
- python小练习---TCP客户端
这是python黑帽子上的起始练习,我对其中的用到的函数做了注释,以便日后便于理解. 该程序可以访问百度,返回响应信息. 另外,我注释还有一部分UDP客户端的语句,TCP和UDP对比便于记忆. # - ...
- 假设result 是一个float型变量,value是一个int型变量。执行以下赋值语句以后,变量value将是什么类型?为什么?
假设result 是一个float型变量,value是一个int型变量.执行以下赋值语句以后,变量value将是什么类型?为什么? 在执行这条语句的过程中,保存在vulue变量中的值被读取出来并转化为 ...
- Fragment和FragmentActivity的使用方法
认识:首先我们知道Fragment是我们在单个Activity上要切换多个UI界面,显示不同内容.模块化这些UI面板以便提供给其他Acitivity使用便利.同时我们显示的Fragment也会受到当前 ...