IRT模型的参数估计方法(EM算法和MCMC算法)
1、IRT模型概述
IRT(item response theory 项目反映理论)模型。IRT模型用来描述被试者能力和项目特性之间的关系。在现实生活中,由于被试者的能力不能通过可观测的数据进行描述,所以IRT模型用一个潜变量 $ \theta $ 来表示,并考虑与项目相关的一组参数来分析正确回答测试项目的概率。目前常见的IRT模型有2-PL模型和3-PL模型。其具体表达式如下:
2-PL模型的表达式如下:
$ p_{i,j}(\theta_i) = \frac {1} {1 + \exp\,[-D\,a_j\,(\theta_i - b_j)]} $
其种 $ \theta_i $ 是被试者能力的参数,$ a_j $ 和 $ b_j $ 分别代表的是题目的区分度参数和难度参数,D是为1.7的常数。
3-PL模型是在模型中引入了预测参数 $ c_j $ ,该参数的含义是描述被试者在没有任何先验知识的情况下,回答正确某项目的概率。常见的例子有学生在做选择题时,即使对该问题没有任何相关知识的获取,也有一定的概率答对该题目。
3-PL模型的表达式如下:
$ p_{i,j}(\theta_i) = c_j + \frac {1 - c_j} {1 + \exp\,[-D\,a_j\,(\theta_i - b_j)]} $
$ c_j $ 表示的是预测参数,其余的参数含义和2-PL模型中的一致。
IRT模型满足三条基本假设:
1)潜在单调性,IRT模型是连续严格单调的函数。
2)条件独立性,IRT模型认为给定 $ \theta_i $,对于第 $ i $ 个被试者,$ Y_{i,j} $ 是独立的;而对于不同的被试者,其各自的答案 $ Y_i $ 也是相互独立的。
3)单维性假设,IRT模型认为某个测试的所有项目都是测量同一个潜在特质。
IRT模型的曲线又称为项目相应曲线或者项目特征曲线(ICC),曲线图如下:
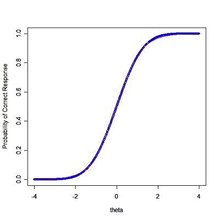
区分度参数 $ a $ 的值是ICC曲线拐点处的斜率,即斜率的最大值。项目难度参数 $ b $ 一般表示在ICC曲线最陡的那一点所对应的 $ \theta $ 的值。改变 $ b $ 的值不会改线曲线的形状,只会导致曲线左右移动。预测参数 $ c $ 代表了ICC曲线的下限,如上图 $ c $ 的值为0.
在这里为了方便讨论,我们用2-PL模型来作为示例。而实际情况中为了简化模型,也可以将预测参数设置为一个常数,例如对于主观题设置为0,对于选择题设置为0.25.
2、EM算法求解IRT模型
EM算法的具体讲解见这一篇。EM算法是一种迭代算法,用于含有隐变量的概率模型的极大似然估计,或者说是极大后验概率估计。EM算法分为 E步和 M步
E步:计算联合分布的条件概率期望。
M步:极大化对数似然函数的条件期望求解参数。
首先来分析我们的观测数据和隐变量。
观测数据:我们把被试者 $ i $ 对项目 $ j $ 的作答反映记为 $ y_{i, j} $ ,又记向量 $ y_i = (y_{i1}, y_{i2}, ....., y_{im}) $ ,称为观测数据,其中 $ i = 1, 2, ..., N, j = 1, 2, ..., m $。对于两级计分模型(在这里我们只考虑两级计分模型,即模型输出的结果只有二分类),$ y_{ij} $ 的取值有0 和 1,分别表示被试者答错和答对题目。除了两级计分模型,还会有多级计分模型(即输出的结果为多分类)。
隐变量(缺失数据):我们把每个被试者的潜在的不可观测的能力值称为缺失数据,记为 $ \theta = (\theta_1, \theta_2, ......, \theta_N) $ ,其中 $ \theta_i $ 是被试者 $ i $ 的潜在能力值。
完全数据:完全数据对每一个被试者来说就是观察数据加缺失数据,记作 $ [(y_1, \theta_1), (y_2, \theta_2), ..., (y_N, \theta_N)] $ 。
将EM算法应用到IRT模型中来,则E步和M步可以描述为:
E步:即在给定缺失数据的分布,观察数据和参数初值时,求完全数据的对数似然函数的条件期望。
M步:即使用E步计算出的完全数据充分统计量的条件期望值,极大化完全数据的对数似然函数的条件期望求解参数的值。
不断的循环迭代E步和M步,直到参数估计收敛。
在IRT模型当中,我们通常认为能力参数 $ \theta $ 是连续随机变量,故可以取任意值。在EM算法估计参数的过程中,我们是能力参数 $ \theta $ 为离散分布。能力值只能取 $ q_1, q_2, ......, q_K $, K个值中的一个,且 $ P(\theta = q_k) = \pi_k $ 。
在给定了反应矩阵 $ Y $ 的情况下,假设项目参数 $ \Delta = [\delta_1, ......, \delta_J] $ ,能力分布参数 $ \pi = (\Pi_1, ......, \Pi_K) $ 。则E步中计算的条件期望推到如下:
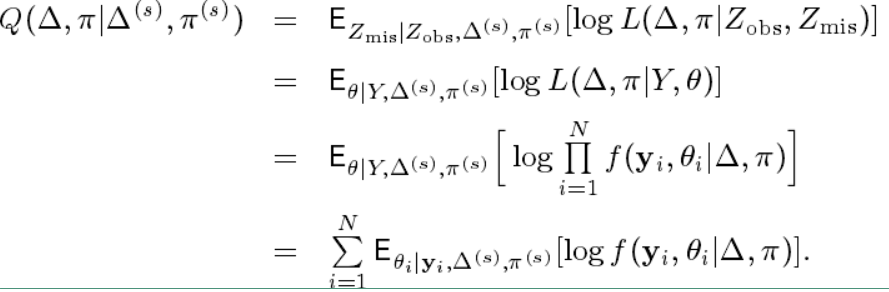
对上面的公式做一些转换表示为:
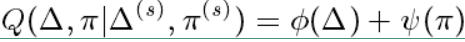
其中 $ \phi(\Delta) $ 和 $ \psi(\pi) $ 的表达式如下:
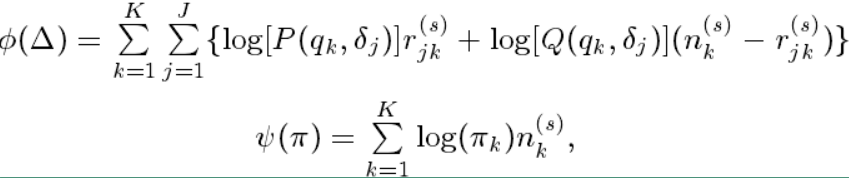
其中:
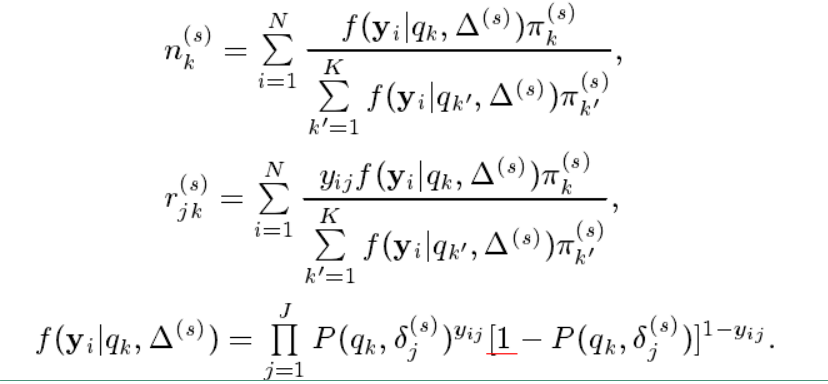
在上面式子中的 $ n_k^{(s)} $ 可以理解为在 $ N $ 个被试者中能力水平为 $ q_k $ 的被试数目的期望(即能力为 $ q_k $ 的被试者的个数),$ r_{jk}^{(s)} $ 可以理解为在 $ N $ 个被试者中具有能力水平 $ q_k $ 的被试者答对第 $ j $ 个项目的个数。 $ n_k^{(s)} $ 和 $ r_{jk}^{(s)} $ 都是人工数据。
应用EM算法的第 $ s $ 步迭代中
E步:利用第 $ s-1 $ 步得到的参数估计值 $ \Delta^{(s)} $ 和 $ \pi_k^{(s)} $ 计算 $ n_k^{(s)} $ 和 $ r_{jk}^{(s)} $ (首次迭代时初始化 $ \Delta^{(0)} $ 和 $ \pi_k^{(0)} $ 的值)。
M步:将E步计算出的 $ n_k^{(s)} $ 和 $ r_{jk}^{(s)} $ 代入到 $ \phi(\Delta) $ 和 $ \psi(\pi) $ 中,对两项分别极大化可得参数 $ \Delta $ 和 $ \pi $ 的估计值 $ \Delta^{(s+1)} $ 和 $ \pi_k^{(s+1)} $ .具体的求解如下:
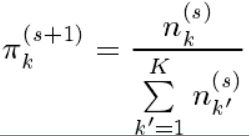
$ \pi_k^{(s+1)} $ 的值可以直接用上述表达式求出
而对于 $ \Delta^{(s+1)} $ 在这里要用牛顿-拉弗逊方法求解。
EM算法估计IRT模型的步骤如下:
1)E步:
首先确定 $ q_k $ 和 $ \pi_k $ ;用前一次迭代参数 $ \Delta^{(s)} $ 和 $ \pi_k^{(s)} $ 求出 $ n_k^{(s)} $ 和 $ r_{jk}^{(s)} $ 。
2)M步:
计算 $ \delta_j^{(s+1)} $ 和 $ \pi^{(s+1)} $ .
3) 重复E步和M步直到项目参数收敛为止。
3、MCMC算法求解IRT模型
MCMC算法的具体详解见这一篇,MCMC算法全称是马尔科夫-蒙特卡洛算法。MCMC的基础理论为马尔可夫过程,在MCMC算法中,为了在一个指定的分布上采样,根据马尔可夫过程,首先从任一状态出发,模拟马尔可夫过程,不断进行状态转移,最终收敛到平稳分布。用MCMC算法在这里估计参数,事实上就是建立一条参数的马尔科夫链,根据参数的状态转移矩阵来输出马尔科夫链上的样本,当马尔科夫链到一定长度时就会开始收敛于某一值。
首先来看看MCMC算法在2-PL模型上的参数估计步骤:
1)取模型参数的先验分布:$ \theta~N(0, 1),\log(a)~N(0, 1),b~N(0, 1) $ ,则初始化被试能力参数,项目参数的初始值 $ \theta_0 = 0,a_0 = 1,b_0 = 0 $ 。
2)根据项目参数初值 $ a_0,b_0 $ ,估计被试者的能力参数 $ \theta_1 $ 。
各被试的能力参数 $ \theta_* $ 独立地从建议性分布 $ q_\theta $ 中选取,我们去被试能力参数的建议分布为 $ \theta_*~N(\theta_0, c_\theta^2) $ 。其中 一般$ c_\theta = 1.1 $ 。
计算从状态 $ \theta_0 $ 转移到状态 $ \theta_1 $ 的接受概率 $ a(\theta_0, \theta_*) = min(1, R_\theta^0) $,由它来决定是否发生状态的转移。
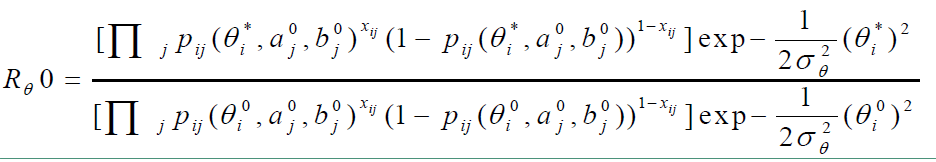
其中
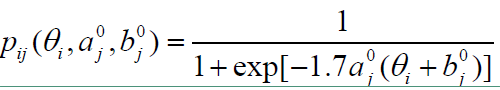
生成随机数 $ r_1~U(0, 1) $ ,比较 $ r_1 $ 与接受概率 $ a(\theta_0, \theta_*) $ 的大小,进行状态转移判断:
若 $ a(\theta_0, \theta_*) \ge r_1 $ ,则有 $ \theta_1 = \theta_* $ ;否则 $ \theta_1 = \theta_* $ 。
3)根据步骤(2)计算出来的被试能力参数 $\theta_1 $ ,估计项目参数 $ a_1, b_1 $ 。
各项目的区分度参数和难度参数 $ a_*, b_* $ 分别独立地从建议分布 $ q_a, q_b $ 中选取,我们取区分度参数和难度参数的建议分布为 $ \log(a_*)~N(a_0, c_a^2), b*~N(b_0, c_b^2) $ ,其中 $ c_a = 0.3, c_b = 0.3 $ 。
计算从状态 $ (a_0, b_0) $ 转移至状态 $ (a_*, b_*) $ 的接收概率 $ \alpha(a_0, b_0, a_*, b_*) = min(1, R_{a,b}^0) $ ,由它来决定是否发生状态的转移。

其中
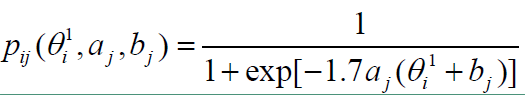
生成随机数 $ r_2~U(0, 1) $ ,比较 $ r_2 $ 与 $ \alpha(a_0, b_0, a_*, b_*) $ 的大小,进行状态转移判断:
若 $ \alpha(a_0, b_0, a_*, b_*) \ge r_2 $ ,则 $ a_1 = a_*, b_1 = b_* $ ;否则 $ a_1 = a_0, b_1 = b_0 $ 。
4)重复步骤(2)和(3)$ n $ 次,删除为首的 $ w $ 次,取剩余的 $ m = n - w $ 次迭代所得结果的均值即为参数的估计值。
5)步骤(4)会生成一条长度为 $ n $ 的 $ Markov $ 链,重复步骤(4)$ i $ 次( $ i $ 次一般小于5),即可以得到 $ i $ 条 $ Markov $ 链,将这 $ i $ 条链得到的参数估计值的均值为最终的参数估计值。
MCMC 算法在求解3-PL模型的参数时和求2-PL模型的参数的方法一致。但是在同等的数据量下,3-PL模型的参数估计精度要低于2-PL模型的参数估计的精度(参数越多,模型越复杂,在同等量的参数下就更容易过拟合)。因此一般我们会将预测参数 $ c_j $ 标为常数值。
4、4-PL模型
在3-PL模型中引入预测参数 $ c_j $ 是为了描述被试者在没有任何相关项目能力地情况下,答对项目的概率。然而现实中还会存在一种情况就是被试者在充分掌握了项目知识的情况下,可以认为理论上被试者关于此项目的能力是完全可以答对该项目的,但实际中却答错了该问题。为了解决这一问题,引入了参数 $ \gamma_j $ ,此时模型可以表示为:
$ p_{i,j}(\theta_i) = c_j + \frac {\gamma_j - c_j} {1 + \exp\,[-D\,a_j\,(\theta_i - b_j)]} $
对于4-PL模型的参数估计依然可以用估计2-PL参数的方法,此时项目参数不再只是 $ (a_j, b_j) $ ,而是 $ (a_j, b_j, c_j, \gamma_j) $ 。
IRT模型的参数估计方法(EM算法和MCMC算法)的更多相关文章
- EM算法和GMM算法的相关推导及原理
极大似然估计 我们先从极大似然估计说起,来考虑这样的一个问题,在给定的一组样本x1,x2······xn中,已知它们来自于高斯分布N(u, σ),那么我们来试试估计参数u,σ. 首先,对于参数估计的方 ...
- 用Spark学习FP Tree算法和PrefixSpan算法
在FP Tree算法原理总结和PrefixSpan算法原理总结中,我们对FP Tree和PrefixSpan这两种关联算法的原理做了总结,这里就从实践的角度介绍如何使用这两个算法.由于scikit-l ...
- 词性标注算法之CLAWS算法和VOLSUNGA算法
背景知识 词性标注:将句子中兼类词的词性根据上下文唯一地确定下来. 一.基于规则的词性标注方法 1.原理 利用事先制定好的规则对具有多个词性的词进行消歧,最后保留一个正确的词性. 2.步骤 ①对词性歧 ...
- 最小生成树---Prim算法和Kruskal算法
Prim算法 1.概览 普里姆算法(Prim算法),图论中的一种算法,可在加权连通图里搜索最小生成树.意即由此算法搜索到的边子集所构成的树中,不但包括了连通图里的所有顶点(英语:Vertex (gra ...
- mahout中kmeans算法和Canopy算法实现原理
本文讲一下mahout中kmeans算法和Canopy算法实现原理. 一. Kmeans是一个很经典的聚类算法,我想大家都非常熟悉.虽然算法较为简单,在实际应用中却可以有不错的效果:其算法原理也决定了 ...
- 使用Apriori算法和FP-growth算法进行关联分析
系列文章:<机器学习实战>学习笔记 最近看了<机器学习实战>中的第11章(使用Apriori算法进行关联分析)和第12章(使用FP-growth算法来高效发现频繁项集).正如章 ...
- 0-1背包的动态规划算法,部分背包的贪心算法和DP算法------算法导论
一.问题描述 0-1背包问题,部分背包问题.分别实现0-1背包的DP算法,部分背包的贪心算法和DP算法. 二.算法原理 (1)0-1背包的DP算法 0-1背包问题:有n件物品和一个容量为W的背包.第i ...
- java实现最小生成树的prim算法和kruskal算法
在边赋权图中,权值总和最小的生成树称为最小生成树.构造最小生成树有两种算法,分别是prim算法和kruskal算法.在边赋权图中,如下图所示: 在上述赋权图中,可以看到图的顶点编号和顶点之间邻接边的权 ...
- 最短路径——Dijkstra算法和Floyd算法
Dijkstra算法概述 Dijkstra算法是由荷兰计算机科学家狄克斯特拉(Dijkstra)于1959 年提出的,因此又叫狄克斯特拉算法.是从一个顶点到其余各顶点的最短路径算法,解决的是有向图(无 ...
随机推荐
- (6)Microsoft office Word 2013版本操作入门_文件封面,页首,页尾
1插入封面: 1.1光标移动到首段,按住 Ctrl+Enter键可以插入一个新页面. 1.2 插入--->封面 可以在封面插入一个文件封面,里面的图片可以自己修改,文字标题也可以自己修改. 1. ...
- Linux服务器配置
配置ssh: 1. 查看22端口是否监听 netstat -antu | grep :22 2. 安装ssh服务 sudo apt-get install ssh 3. 再次查看22端口 安装apac ...
- JS隐藏号码中间4位
function resetPhone(phone) { var str = String(phone) var len = str.length; var prev,next; if (len &g ...
- 向后台提交数据:通过form表单提交数据需刷新网页 但通过Ajax提交数据不用刷新网页可通过原生态Ajax或jqueryAjax。Ajax代码部分
原生态Ajax提交表单:需要借助XMLHttpRequest对象的open,要收通过post发送请求还要setRequsetHeader,然后把数据发送给后端,代码如下 目录结构 index.py代码 ...
- application.properties多环境配置文件、jar包外部配置文件、配置项加密、程序中配置使用
一.简介 spring boot项目application.properties文件存放及使用介绍 二.方法一多环境配置文件 我们一般都会有多个应用环境,开发环境.测试环境.生产环境,各个环境的配置会 ...
- 【Wyn Enterprise BI知识库】 什么是商业智能 ZT
商业智能(Business Intelligence,BI),又称商务智能,指用现代数据仓库技术.在线分析处理技术.数据挖掘和数据展现技术进行数据分析以实现商业价值. 图1:商业智能(BI)系统 商业 ...
- 利用SurfaceView显示正弦曲线,仿造示波器
众所周知,view是通过刷新来重绘视图的,Android系统通过发出VSYNC信号来进行屏幕重绘,刷新的时间间隔为16ms,如果在16ms内view完成你所需要的所有操作,那么用户在视觉上就不会产生卡 ...
- IntelliJ IDEA安装、配置、测试
IntelliJ IDEA安装.配置.测试(win7_64bit) 目录 1.概述 2.本文用到的工具 3.安装.激活与配置 4.开发测试 4.1 JavaSE开发测试(确保JDK已正确安装) 4.2 ...
- IIS 配置 HTTPS
前言 HTTPS(全称:Hyper Text Transfer Protocol over Secure Socket Layer 或 Hypertext Transfer Protocol Secu ...
- CSS之精灵图(雪碧图)与字体图标
本文内容: 精灵图 字体图标 首发日期:2018-05-01 精灵图: 在以前,每个图片资源都是独立的一张张图片,浏览器访问网站中的不同网页时是重复获取这一张张图片的,这代表需要访问很多次资源. 为了 ...