【网络爬虫入门03】爬虫解析利器beautifulSoup模块的基本应用
【网络爬虫入门03】爬虫解析利器beautifulSoup模块的基本应用
1、引言
网络爬虫最终的目的就是过滤选取网络信息,因此最重要的就是解析器了,其性能的优劣直接决定这网络爬虫的速度和效率。BeautifulSoup可以通过定位HTML件中的标签来格式化和组织复杂的网络信息,尝试化平淡为神奇,用简单易用的Python对象为我们展现XML的信息结构,它会帮你节省数小时甚至数天的工作时间。
2、什么是BeautifulSoup模块?
BeautifulSoup是一个非常优秀的Python扩展库,它可以从HTML或XML文件中提取我们感兴趣的数据。它不但可以标签进行查找,还可以通过标签属性来查找。 BeautifulSoup除了支持Python标准库中的HTML解析器之外,还支持一些第三方的解析器,可以有针对性地向网页进行解析。 BeautifulSoup官方推荐使用lxml作为解析器,据说因为lxml解析器的效率更高。
学习BeautifulSoup的最完整和最好资料是官方文档,常用的内容熟练掌握,不常用的需要的时候查阅就好。在本文中,只总结爬虫开发中常用知识,更多内容要看官方文档:
http://beautifulsoup.readthedocs.io/zh_CN/latest/#id18
3、对象的种类
BeautifulSoup对象是一个复杂的树形结构,它的每一个节点都是一个Python对象,获取网页内容就是一个提取对象内容的过程,其提取对象的方法可以分为:遍历文档树、搜索文档树、CSS选择器。
所有的对象可以分为4种:
<1> Tag:Tag对象与XML或HTML原生文档中的tag相同。它有很多方法和属性,其中最重要的是:name和attributes。BeautifulSoup对象通过find()和find_all()方法,或者直接调用子标签获取一列对象或单个对象。
<2> NavigableString:用来表示标签里的文字,不是标签。
<3> Comment:这是一个特殊类型的NavigableString对象,用来查找HTML文档中的注释。
<4> BeautifulSoup:这个对象表示文档的全部内容。大部分时候可以把它当作Tag对象,它支持遍历文档树和搜索文档树的大部分方法。
4、官方测试样例

5、遍历文档树
文档树的遍历方法就好像爬树一样,需要首先爬到树干上,然后慢慢爬到小树干,最后到树枝上,就可以得到需要的数据了。
例1:获取文档树中的‘body标签中的‘p’标签中的’‘b’标签。

在遍历文档树中,搞清各个标签之间的关系是非常重要的。子标签就是一个父标签的下一级;而后代标签是指一个父标签下面所有级别的标签。所有子标签都是后代标签,但不是所有的后代标签都是子标签。一般情况下,BeautifulSoup的方法总是处理当前标签的后代标签。
可以通过 .parent 属性来获取某个元素的父节点.
例2:获取文档树中‘p’标签的父标签。
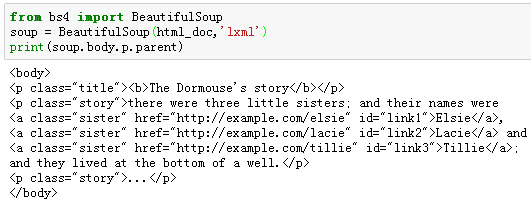
tag的.contents 属性可以将tag的子节点以列表的方式输出;通过tag的.children 生成器,也可以对tag的子节点进行循环。
例3:获取文档树中‘p’标签的子标签。
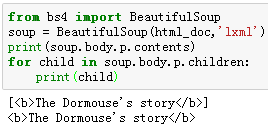
6、搜索文档树
相对于遍历文档树来说,搜索文档树最常用。在搜索文档树时,最常用的是find_all()和find()方法。在这里,主要通过例子讲述find_all()的常见使用,关于find_all()的具体描述参见官方文档。
find_all (name, attrs, recursive, string, limit, keyword)
该方法搜索当前tag的所有tag子节点,并判断是否符合过滤器的条件。
[1] name参数:可以查找所有名字为name的tag,字符串对象会自动忽略掉。该参数的值可以接受:字符串、正则表达式、列表和True。
例4:搜索文档树中的‘title’标签。
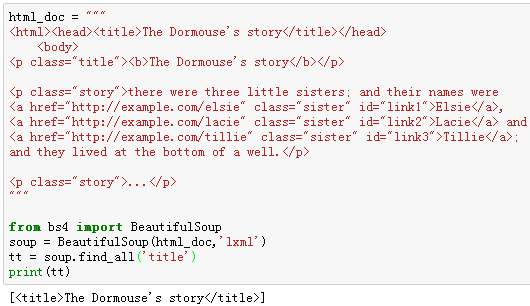
例5:搜索文档树中的‘a’标签,逐条打印出来。

[2] attrs参数:是用一个Python字典封装一个标签的若干属性和对应的属性值。
例6:搜索‘a’标签中,id属性的值为“link2”的标签。

因为表示CSS类名的关键字class在Python中是保留字,所以,在按照CSS类名搜索tag的时候,如果使用class作为参数会导致语法的错误,不过,可以通过class_搜索指定CSS类名的tag,或者通过字典的方式指定参数。
例7:搜索‘a’标签中,class属性的值为“sister1”的标签。

例8:搜索‘a’标签中,class属性的值为“sister1”和属性值为“sister3”的标签。

[3] recursive参数:是一个布尔变量。该参数为True,find_all()就会根据你的要求去查找标签参数的所有子标签,以及子标签的子标签。如果该参数为False,find_all()就只查找文档一级标签。该参数默认是True的,一般情况下不需要修改,除非你真正了解自己需要那些信息,而且抓去的速度非常重要,那么你可以设置该参数。
[4] string参数:通过该参数可以搜索文档中的字符串内容,与name参数相似,其可选值一样,接受:字符串、正则表达式、列表和True,例如:
soup.find_all(string = "Elsie")
soup.find_all(string = ["Elsie", "Tillie", "Lacie"])
soup.find_all(string = re.compile("Dormouse"))
该参数还可以与其他参数混合使用来过滤:
soup.find_all("a", string = "Elsie")
例9:搜索文档树中符合列表中参数的字符串内容。

[5] limit参数:find_all()方法返回的是全部的搜索结果,如果我们不需要全部结果,可以使用limit参数来限制返回结果的数量。当搜索到的结果数量达到limit的限制时,就停止搜索返回结果。find()方法实际上等价于find_all()的limit参数为1的情形。
例10:搜索'a'标签并返回一个结果。

[6]keyword参数:如果一个指定名字的参数不是搜索内置的参数名,搜索时会把该参数当作指定名字tag的属性来搜索。
通过标签参数name把标签列表传到find_all()里获取一系列标签,其实就是一个“或”关系的过滤器;而关键字参数keyword可以让你增加一个“与”关系的过滤器来简化工作。
如果传入一个名字为id的参数,BeautifulSoup会搜索每一个tag的id属性,如果传入href参数,则会搜索每一个tag的href属性。在搜索指定名字的属性时,可以使用的参数值包括:字符串、正则表达式、列表和True。
例11:在文档树中查找所有包含id属性的tag,无论id属性的值是什么。

例12:查找id属性值为link2的标签。

除了上面的基础应用之外,关于find_all()使用可以相当灵活,需要通过在实践中不断的体会和积累,我们在看几个例子:
例13:使用多个指定名字的参数,同时过滤tag的多个属性。
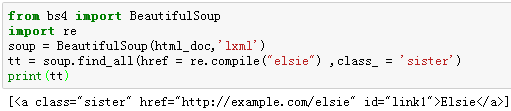
例14:将‘a’标签中的网络链接抓取出来。

例15:将‘a’标签中的网络链接和字符串抓取出来,形成可视数据。

例16:将class属性值为“story”的‘p’标签的全部子标签的文本抓取出来。
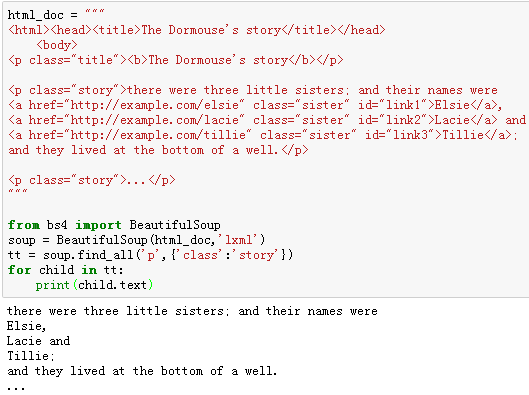
7、小结
对爬取网页的解析工作,除了 BeautifulSoup之外,还可以使用re正则表达式、lxml解析器、xpath等等来实现,熟练掌握一个工具,学习其他的会很容易。BeautifulSoup的用法远不止此,但作为网络爬虫的入门应用,上述知识基本足够。如果在学习过程中观看不练,会感觉非常抽象,无法理解;如果只知道敲代码而忽略了为什么,也只能一知半解,难以灵活应用。
【网络爬虫入门03】爬虫解析利器beautifulSoup模块的基本应用的更多相关文章
- 【爬虫入门手记03】爬虫解析利器beautifulSoup模块的基本应用
[爬虫入门手记03]爬虫解析利器beautifulSoup模块的基本应用 1.引言 网络爬虫最终的目的就是过滤选取网络信息,因此最重要的就是解析器了,其性能的优劣直接决定这网络爬虫的速度和效率.Bea ...
- 【网络爬虫入门04】彻底掌握BeautifulSoup的CSS选择器
[网络爬虫入门04]彻底掌握BeautifulSoup的CSS选择器 广东职业技术学院 欧浩源 2017-10-21 1.引言 目前,除了官方文档之外,市面上及网络详细介绍BeautifulSoup ...
- 爬虫----爬虫解析库Beautifulsoup模块
一:介绍 Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库.它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式.Beautiful Soup会帮你 ...
- 爬虫利器BeautifulSoup模块使用
一.简介 BeautifulSoup 是一个可以从HTML或XML文件中提取数据的Python库.它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式,同时应用场景也是非常丰富,你可以使用 ...
- Python爬虫入门:爬虫基础了解
有粉丝私信我想让我出更基础一些的,我就把之前平台的copy下来了,可以粗略看一下,之后都会慢慢出. 1.什么是爬虫 爬虫,即网络爬虫,大家可以理解为在网络上爬行的一直蜘蛛,互联网就比作一张大网,而爬虫 ...
- python爬虫-入门-了解爬虫
作为一个爬虫新手,我觉得首先要了解爬虫是的作用以及应用. 作用:通过爬虫获取网页内的信息.包括:标题(title)图片(image)链接(url)等等 应用:抽取所需信息,进行数据汇总及分析(从事网页 ...
- 解析库-beautifulsoup模块
# -*- coding: utf-8 -*- from bs4 import BeautifulSoup # 安装:pip install beautifulsoup4 # Beautiful So ...
- 【网络爬虫入门01】应用Requests和BeautifulSoup联手打造的第一条网络爬虫
[网络爬虫入门01]应用Requests和BeautifulSoup联手打造的第一条网络爬虫 广东职业技术学院 欧浩源 2017-10-14 1.引言 在数据量爆发式增长的大数据时代,网络与用户的沟 ...
- Python爬虫从入门到进阶(1)之Python概述及爬虫入门
一.Python 概述 1.计算机语言概述 (1).语言:交流的工具,沟通的媒介 (2).计算机语言:人跟计算机交流的工具 (3).Python是计算机语言的一种 2.Python编程语言 代码:人类 ...
随机推荐
- 洛谷P3396 哈希冲突
分块还真是应用广泛啊...... 题意:求 解:以n0.5为界. 当p小于n0.5的时候,直接用p²大小的数组储存答案. 预处理n1.5,修改n0.5. 当p大于n0.5的时候,直接按照定义计算,复杂 ...
- 网络流24题 gay题报告
洛谷上面有一整套题. 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 extra ①飞行员配对方案问题.top 裸二分图匹 ...
- P1024 一道naive的二分
好吧,这道题思路还是比较简单的.整个程序大体上很快就打出来了,然后修改了解为整数的情况. 但是交上去一直是50分,最后我很无耻的看了题解,然后抄了一个玄学if回来,瞬间AC,不知道为什么... 这句就 ...
- 使用jquery.pjax实现SPA单页面应用
前面文章介绍了前端路由简单实现和Pjax入门方面的文章,今天来分享一个单页面应用神器jquery.pjax.js. HTML 我们准备一个加载div#loading,默认隐藏,ajax请求的时候才显示 ...
- mciSendString 多线程播放多首音乐 & 注意事项
昨天晚上遇到一个问题: 使用 mciSendString 控制播放多首音乐的时候,出现最后一次播放的音乐无法通过 mciSendString ("close mp3") 关闭音乐 ...
- pytest 7 assert断言
前言:断言是自动化最终的目的,一个用例没有断言,就失去了自动化测试的意义了. 断言用到的是 assert关键字.之前的介绍,有的测试方法中其实用到了assert断言.简单的来说,就是预期的结果去和实际 ...
- java的线程
public class Test1 extends Thread{ public void run(){ // } } public class Test2 immplement Runnable{ ...
- 计算机基础:计算机网络-chapter5 运输层
一.运输层做什么事情,通过什么协议实现, 运输层做什么 为相互通信的应用提供逻辑通信 通过端口号来确定应用,提供端到端的服务: 为什么需要运输层,IP层不是就实现了传输数据吗 从IP层来说,是两台主机 ...
- appium在不同类中使用的是同一个session
要这么做的起因: 测试testng框架的时候,不同类之间可以按照顺序执行,不会互相干扰.但是换成了appium,在A类中启动了session,初始化或者一些数据我仍然要用之前的session,那就不行 ...
- 网络流n题
近日好不容易在自救之路写完暑训遗留下来的网络流8题,在此回顾一下. Going Home POJ - 2195 题意:m要去H,一个H只能容纳一个m,一步一块钱,问最小花费. 思路:最小费用最大流的板 ...