final域的内存语义
一、final的基本语义
final关键字可以用来修饰类、方法和变量(包括成员变量和局部变量)
- 当用final修饰一个类时,表明这个类不能被继承。
- 当用final修饰一个方法时,表明这个方法不能被重写。
- 当用final修饰一个变量时,表明这个变量初始化后就不能再被修改。
对于final类,从设计的角度来讲,将类设计为final是不希望这个类被继承,从而对这个类进行修改。比如String类。
对于final方法,将方法设计为final除了可以防止方法被重写外,还能提升效率。final方法涉及到内联(inline)机制,内联是编译器的一种很重要优化手段,内联行为看起来就像把final方法中的内容复制到了调用final方法的方法中,这样会避免了方法调用时的额外的开销。
在并发编程中,final也起到了很重要的作用。下面重点来讲解final域的内存语义
二、final域的内存语义
旧的final模型中,final的值看起来是可变的。参考:How can final fields appear to change their values?
新的JMM中已经对上面的情况进行了修复。参考:How do final fields work under the new JMM?
1.final域的重排序规则
对于final域,编译器和处理器要遵守两个重排序规则。
- 写final域的重排序规则:在构造函数内对一个final域的写入,与随后把这个被构造对象的引用赋值给一个引用变量,这两个操作之间不能重排序。(禁止把final域的写操作重排序到构造函数之外)
- 读final域的重排序规则:初次读一个包含final域的对象的引用,与随后初次读这个final域,这两个操作之间不能重排序。
下面用一个例子来说明以上两条规则。
public class FinalExample {
int i;//普通域
final int j;//final域
static FinalExample obj;
public FinalExample () {
i = 1;//写普通域。对普通域的写操作【可能会】被重排序到构造函数之外
j = 2;//写final域。对final域的写操作【不会】被重排序到构造函数之外
}
// 写线程A执行
public static void writer () {
obj = new FinalExample ();
}
// 读线程B执行
public static void reader () {
FinalExample object = obj;//读对象引用
int a = object.i;//读普通域。可能会看到结果为0(由于i=1可能被重排序到构造函数外,此时y还没有被初始化)
int b = object.j;//读final域。保证能够看到结果为2
}
}
①写final域的重排序规则。
写final域的重排序规则禁止把final域的写重排序到构造函数之外。这个规则的实现包含下面2个方面。
- JMM禁止编译器把final域的写重排序到构造函数之外。
- 编译器会在final域的写之后,构造函数return之前,插入一个StoreStore屏障。这个屏障禁止处理器把final域的写重排序到构造函数之外。
对于前面的程序,下面是一种可能的执行序列
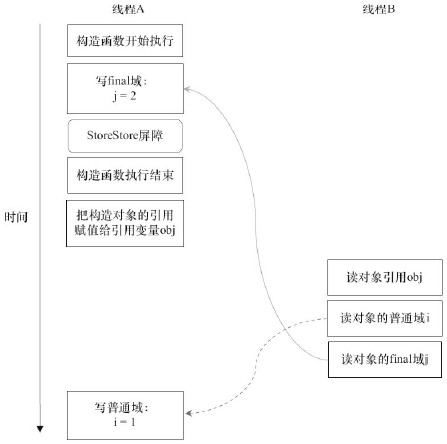
在上图的执行序列中,写普通域的操作(i=1)被编译器重排序到了构造器之外,导致读线程B错误的读取变量i的初始化的值。而由于写final域重排序规则的限定,写final域的操作(j=2)被限定在了构造函数之内,读线程B必然能够正确读到正确的值。
②读final域的重排序规则。
对读final域的重排序规则的实现,包括以下2个方面
- JMM禁止处理器重排序这两个操作(注意,这个规则仅仅针对处理器)。
- 编译器会在读final域操作的前面插入一个LoadLoad屏障。
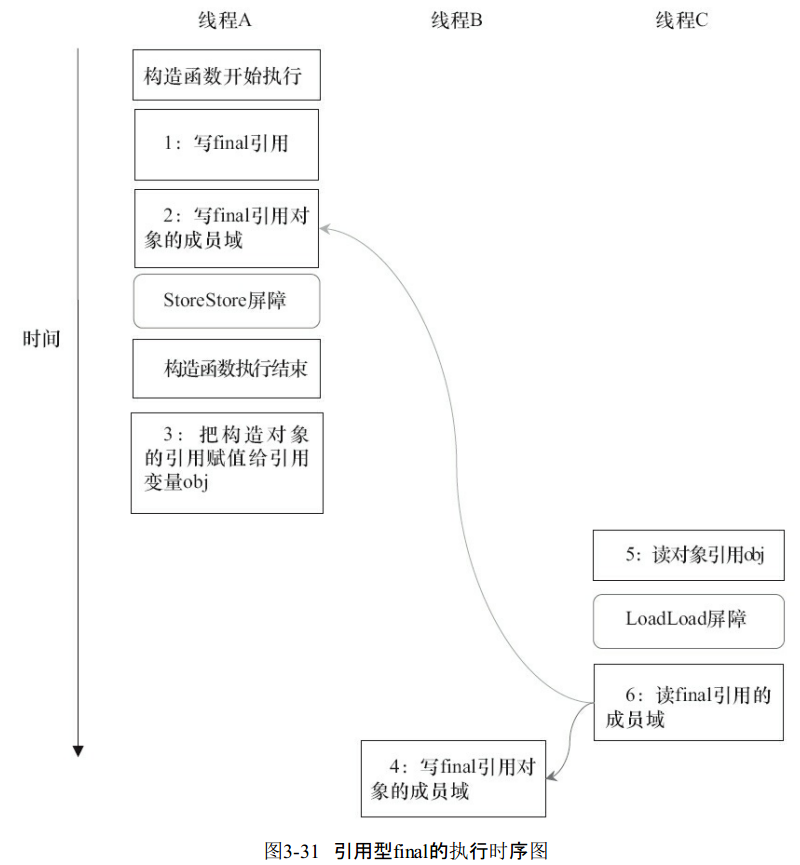
下面是前面程序的另外一种执行序列(假设写线程A没有发生任何重排序,同时程序在不遵守间接依赖的处理器上执行)
在上图的执行序列中,读对象的普通域的操作被处理器重排序到读对象引用之前。读普通域时,由于该域还没有被写线程A写入,因此这是一个错误的读取操作。而由于读final域的重排序规则的限定,会把读对象final域的操作限定在读对象引用之后,由于此时final域已经被A线程初始化过了,所以这是一个正确的读取操作。
2.final域为引用类型
上面例子中final域是基本数据类型。而对于final域是引用类型,写final域的重排序规则对编译器和处理器增加了如下约束:
- 在构造函数内对一个final引用的对象的成员域的写入,与随后在构造函数外把这个被构造对象的引用赋值给一个引用变量,这两个操作之间不能重排序。
请看下面的例子。
public class FinalReferenceExample {
final int[] intArray;// final是引用类型
static FinalReferenceExample obj;
public FinalReferenceExample () {
intArray = new int[1];// ①对final域的写入
intArray[0] = 1;// ②对这个final域引用的对象的成员域的写入
}
// 写线程A执行
public static void writerOne () {
obj = new FinalReferenceExample (); // ③把被构造的对象的引用赋值给某个引用变量
}
// 写线程B执行
public static void writerTwo () {
obj.intArray[0] = 2;// ④
}
// 读线程C执行
public static void reader () {
if (obj != null) {// ⑤
int temp1 = obj.intArray[0];// ⑥
}
}
}
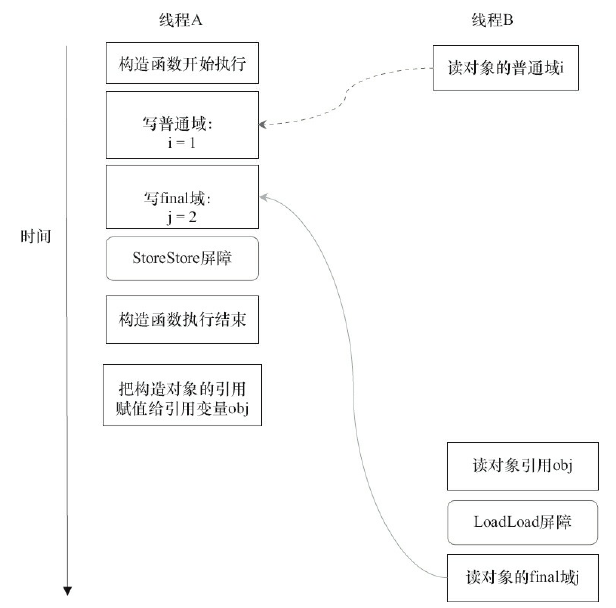
对上面的示例程序,假设首先线程A执行writerOne()方法,执行完后线程B执行writerTwo()方法,执行完后线程C执行reader()方法。下面是一种可能的线程执行时序。
这里除了前面提到的①不能和③重排序外,写引用类型的final域的重排序增加的约束规定了②和③也不能重排序。
JMM可以确保读线程C至少能看到写线程A在构造函数中对final引用对象的成员域的写入。即C至少能看到数组下标0的值为1,而写线程B对数组元素的写入,读线程C可能看得到也可能看不到。JMM不保证线程B的写入对读线程C可见,因为写线程B和读线程C之间存在数据竞争,此时的执行结果不可预知。
如果想要确保读线程C看到写线程B对数组元素的写入,写线程B和读线程C之间需要使用同步(锁或volatile)来确保内存可见性。
3.为什么final引用不能从构造函数中逸出
前面我们提到过,写final域的重排序规则可以确保:在引用变量为任意线程可见之前,该引用变量指向的对象的final域已经在构造函数中被正确初始化过了。其实,要得到这个效果,还需要一个保证:在构造函数内部,不能让这个被构造对象的引用为其他线程所见,也就是对象引用不能在构造函数中“逸出”。
为了说明问题,让我们来看下面的示例代码。
public class FinalReferenceEscapeExample {
final int i;
static FinalReferenceEscapeExample obj;
public FinalReferenceEscapeExample () {
i = 1; // ①写final域
obj = this; // ②this引用在此"逸出"
}
//写线程A执行
public static void writer() {
new FinalReferenceEscapeExample ();
}
//读线程B执行
public static void reader() {
if (obj != null) { // ③
int temp = obj.i; // ④
}
}
}
假设线程A执行writer()方法,线程B执行reader()方法。这里的操作②使得对象还未完成构造前就为线程B可见。即使这里的操作②是构造函数的最后一步,且在程序中操作②排在操作①后面,执行read()方法的线程仍然可能无法看到final域被初始化后的值,因为这里的操作①和操作②之间可能被重排序。实际的执行时序可能如下:
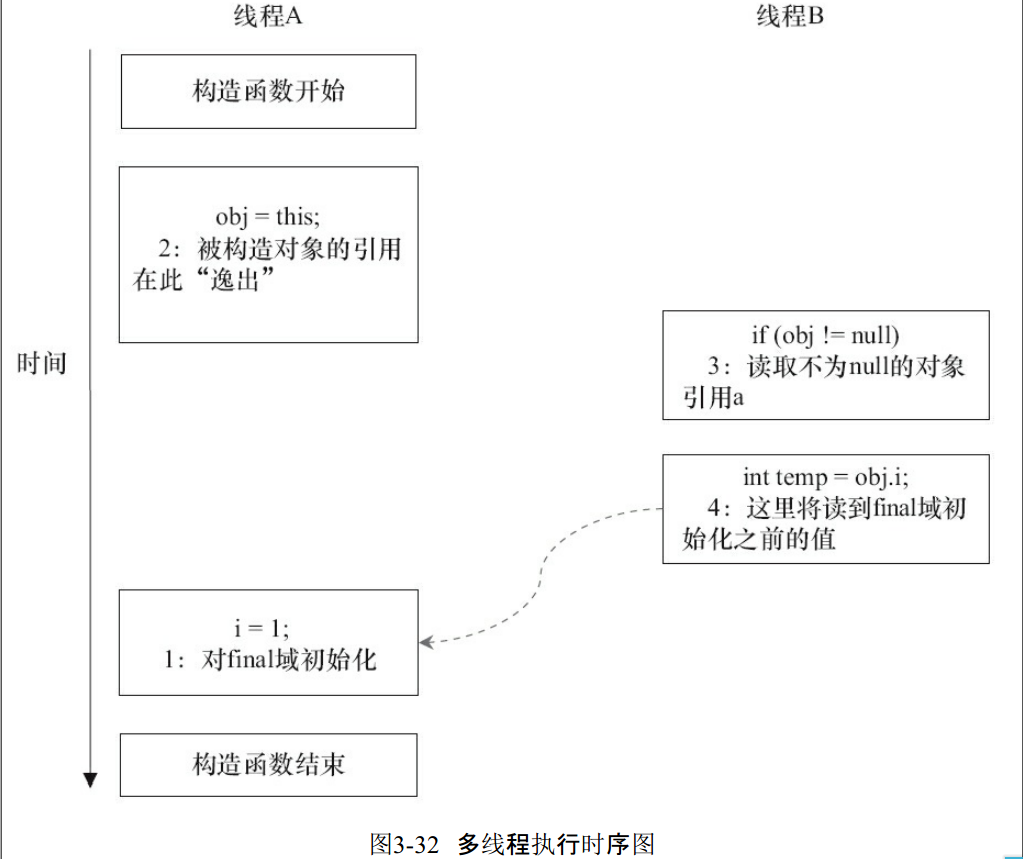
从上图可以看出:在构造函数返回前,被构造对象的引用不能为其他线程可见。因为此时final域可能还没有初始化。在构造函数返回后,任意线程都将保证能看到final域正确初始化之后的值。
4.final语义在处理器中的实现
现在我们以X86处理器为例,说明final语义在处理器中的具体实现。
上面我们提到,写final域的重排序规则会要求编译器在final域的写之后,构造函数return之前插入一个StoreStore障屏。读final域的重排序规则要求编译器在读final域的操作前面插入一个LoadLoad屏障。
由于X86处理器不会对写-写操作做重排序,所以在X86处理器中,写final域需要的StoreStore障屏会被省略掉。同样,由于X86处理器不会对存在间接依赖关系的操作做重排序,所以在X86处理器中,读final域需要的LoadLoad屏障也会被省略掉。也就是说,在X86处理器中,final域的读/写不会插入任何内存屏障!
5.JSR-133为什么要增强final语义
在旧的Java内存模型中,一个最严重的缺陷就是线程可能看到final域的值会改变。比如,一个线程当前看到一个整型final域的值为0(还未初始化之前的默认值),过一段时间之后这个线程再去读这个final域的值时,却发现值变为1(被某个线程初始化之后的值)。最常见的例子就是在旧的Java内存模型中,String的值可能会改变。
为了修补这个漏洞,JSR-133专家组增强了final的语义。通过为final域增加写和读重排序规则,可以为Java程序员提供初始化安全保证:只要对象是正确构造的(被构造对象的引用在构造函数中没有“逸出”),那么不需要使用同步(指lock和volatile的使用)就可以保证任意线程都能看到这个final域在构造函数中被初始化之后的值。
static
static关键字在多线程环境下有特殊含义,它能保证一个线程即使在未使用其它同步机制的情况下也总是可以读取到一个类的静态变量的初始值(不是默认值)。但这种可见性保障仅限于线程初次读取该变量。如果这个静态变量在相应类初始化完毕之后被其它线程更新,那么一个线程要读取该变量的新值仍然需要借助同步机制(锁,volatile等)。
(from 《java多线程编程实战指南-核心篇》3.1.11.1章节 P137)
参考:《java并发编程的艺术》3.6章节
总结
1.final的作用
2.static的作用
final域的内存语义的更多相关文章
- Java内存模型-final域的内存语义
一 引言 说到final你肯定知道它是Java中的关键字,那么它所在Java中的作用你知道吗?不知道的话,请前往这篇了解下https://www.cnblogs.com/yuanfy008/p/802 ...
- Java并发编程之final域的内存语义
一.final域的重排序规则 对于final域,编译器和处理器要遵循两个重拍序规则: 1.在构造函数内对一个final域的写入,与随后把这个被构造对象的引用赋值给一个引用变量,这两个操作之间不能重排序 ...
- Java并发编程原理与实战四十四:final域的内存语义
一.final域的重排序规则 对于final域,编译器和处理器要遵循两个重拍序规则: 1.在构造函数内对一个final域的写入,与随后把这个被构造对象的引用赋值给一个引用变量,这两个操作之间不能重排序 ...
- Java内存模型-final域的内存语义--没明白,预留以后继续理解
https://www.cnblogs.com/yuanfy008/p/9349275.html 来自 Java并发编程(1)-Java内存模型
- java并发学习--第十章 java内存模型的内存语义
一.锁的内存语义 所为的java内存模型的内存语义指的就是在JVM中的实现原则. 锁的内存语义:锁除了让临界区互斥执行外,还可以让释放锁的线程向获取同一个锁的线程发送消息. 我们把上面这句话再整理下: ...
- Java内存模型(MESI、内存屏障、volatile和锁及final内存语义)
JMM (Java内存模型) Java线程的实现 实现线程主要有三种方式,Java线程从JDK1.3后采用第一种方式实现: 使用内核线程实现(1:1实现) 使用用户线程实现(1:N实现) 使用用户线程 ...
- Java-内存模型 final 和 volatile 的内存语义
前提:内存屏障 内存屏障(Memory Barrier)与内存栅栏(Memory Fence)是同一个概念. 用于阻止指令重排序.保证了特定操作的执行顺序和某些变量的内存可见性. JMM 内存屏障分为 ...
- java多线程03-----------------volatile内存语义
java多线程02-----------------volatile内存语义 volatile关键字是java虚拟机提供的最轻量级额的同步机制.由于volatile关键字与java内存模型相关,因此, ...
- 基础篇:深入JMM内存模型解析volatile、synchronized的内存语义
目录 1 java内存模型,JMM(JAVA Memory Model) 2 CPU高速缓存.MESI协议 3 指令重排序和内存屏障指令 4 happen-before原则 5 synchronize ...
随机推荐
- 浏览器本地数据存储解决方案以及cookie的坑
本地数据存储解决方案以及cookie的坑 问题: cookie过长导致页面打开失败 背景: 在公司的项目中有一个需求是打开多个工单即在同一个页面中打开了多个tab(iframe),但是需要在刷新时只刷 ...
- (转)Eclipse中快速输入System.out.println()的快捷键
https://blog.csdn.net/ShiMengRan107/article/details/73614417 善用 Eclipse 组合键,可以提高输入效率. Step1: Eclipse ...
- linux 查看命令 ls-list
1. ls 基础常用 显示指定目录下的文件列表 list ls -lthr /floder l 长的列表格式 lang 能查看到常用大部分信息 t 按时间先后排序 (sort排序) tim ...
- Linux-centos7超过2TB使用parted命令分区
介绍说明: parted的操作都是实时的,也就是说你执行了一个分区的命令,他就实实在在地分区了, 而不是像fdisk那样,需要执行w命令写入所做的修改, 所以进行parted的测试千万注意不能在生产环 ...
- 数据结构【查找】—B树
/*********************讲解后期补充*****************/ 先上代码 #include "000库函数.h" #define MAXSIZE 10 ...
- 动态记忆网络(DMN)
论文:Ask Me Anything: Dynamic Memory Networks for Natural Language Processing 1.概述 Question answering( ...
- 第10章 RDB持久化
Redis是一种内存数据库,掉电即失,为了解决这个问题Redis提供了RDB持久化功能,该功能可以把Redis中的内容以RDB文件的形式存储在硬盘上,并且每次RedisServer启动的时候都会尝试从 ...
- Linux—日志查看(测试人员)
备注:在筛选语句后面加“--col”可以高亮显示查询结果中的关键字 cd /home/admin/logs/服务器名 #进入日志目录(错误日志文件:common-error.log),路径因公司而定 ...
- 【mongoDB查询进阶】聚合管道(一) -- 初识
https://segmentfault.com/a/1190000010618355 前言:一般查询可以通过find方法,但如果是比较复杂的查询或者数据统计的话,find可能就无能为力了,这时也许你 ...
- [MicroPython]TPYBoardv102播放音乐实例
0x00前言 前段时间看到TPYBoard的技术交流群(群号:157816561,)里有人问关于TPYBoard播放音乐的问题.最近抽空看了一下文档介绍,着手做了个实验.更多MicroPython的教 ...