爬虫实战——Scrapy爬取伯乐在线所有文章
Scrapy简单介绍及爬取伯乐在线所有文章
一.简说安装相关环境及依赖包
1.安装Python(2或3都行,我这里用的是3)
2.虚拟环境搭建:
依赖包:virtualenv,virtualenvwrapper(为了更方便管理和使用虚拟环境)
安装:pip install virtulaenv,virtualenvwrapper或通过源码包安装
常用命令:mkvirtualenv --python=/usr/local/python3.5.3/bin/python article_spider(若有多个Python版本可以指定,然后创建虚拟环境article_spider);
workon :显示当前环境下所有虚拟环境
workon 虚拟环境名:进入相关环境:

退出虚拟环境:deactivate
删除虚拟环境:rmvirtualenv article_spider
安装相关依赖包及Scrapy框架:pip install scrapy(建议用豆瓣源镜像安装,快得多pip install https://pypi.douban.com /simple scrapy)
windows操作环境中还需安装(pip install pypiwin32)
注:若安装失败有可能是版本不同,可以到官网查看对应版本安装:https://www.lfd.uci.edu/~gohlke/pythonlibs/
3.新建Scrapy项目(可以定制模板,这里用默认的):
scrapy startproject article_spider:

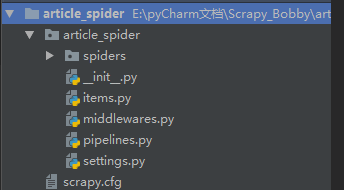
用Pycharm打开,结构如下(与Django相似),爬虫都放在spider文件夹中:
创建爬虫文件:cd article_spider:进入项目
scrapy genspider --list(查看spider提供的模板)
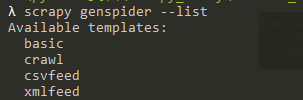
scrapy genspider -t 模板名 爬虫文件名 域名(指定模板):

scrapy genspider 爬虫文件名 所爬取的域名(默认模板为basic)


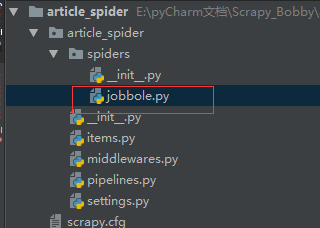
jobbole.py文件如下(start_url中的url都会通过parse函数,可以把要爬取的网址放进start_url):查看Spider源码可知,通过start_requests返回url,是一个生成器
# -*- coding: utf-8 -*-
import scrapy class JobboleSpider(scrapy.Spider):
name = 'jobbole'
allowed_domains = ['blog.jobbole.com']
start_urls = ['http://blog.jobbole.com/'] def parse(self, response):
pass
二.爬虫相关技能介绍
1.新建main函数,执行并调试爬虫:
from scrapy.cmdline import execute
import sys
import os
#将父目录添加到搜索目录中
sys.path.append(os.path.dirname(os.path.abspath(__file__)))
execute(["scrapy","crawl","jobbole"])
修改setting.py:
# Obey robots.txt rules
#默认为True会过滤掉ROBOTS协议
ROBOTSTXT_OBEY =False
调试结果如下,body中为网页所有内容:
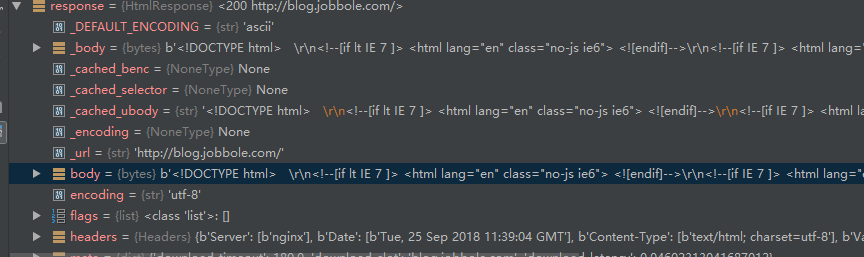
3.scrapy shell的使用(方便调试):
3.1scrapy shell "http://blog.jobbole.com/114405/"(scrapy shell 要爬取调试的url)

3.2xpath提取并获取文章名,extract()方法将Selectorlist转换为list:

3.Xpath的使用,提取所需内容(比Beautifulsoup快得多):
3.1xapth节点关系:
父节点
子节点
同胞节点(兄弟节点)
先辈节点
后代节点
3.2xpath语法简单使用:



3.3提取文章名:
# -*- coding: utf-8 -*-
import scrapy class JobboleSpider(scrapy.Spider):
name = 'jobbole'
allowed_domains = ['blog.jobbole.com']
start_urls = ['http://blog.jobbole.com/114405/']
def parse(self, response):
title=response.xpath('//*[@id="post-114405"]/div[1]/h1/text()')
pass

返回的是一个Selectorlist,便于嵌套xpath
3.4xpath获取时间:

3.5获取点赞数,xpath的contains函数,获取class包含vote-post-up的span标签下的:

3.6获取收藏数:
fav_nums=response.xpath("//span[contains(@class,'bookmark-btn')]/text()").extract()[0]
#使用正则匹配,有可能无收藏,匹配不到
match_fav=re.match(".*(\d+).*",fav_nums)
if match_fav:
fav_nums=int(match_fav.group(1))
else:
fav_nums=0
3.7获取评论数:
comments_nums = response.xpath("//a[@href='#article-comment']/span/text()").extract()[0]
math_comments=re.match(".*(\d).*",comments_nums)
if math_comments:
comments_nums=int(math_comments)
else:
comments_nums=0
3.8文章内容:

3.9标签提取:
tag_list= response.xpath('//*[@id="post-114405"]/div[2]/p/a/text()').extract()
tag_list=[element for element in tag_list if not element.strip().endswith("评论")]
tags=','.join(tag_list)
4.CSS选择器筛选提取内容:
4.1CSS常用方法:

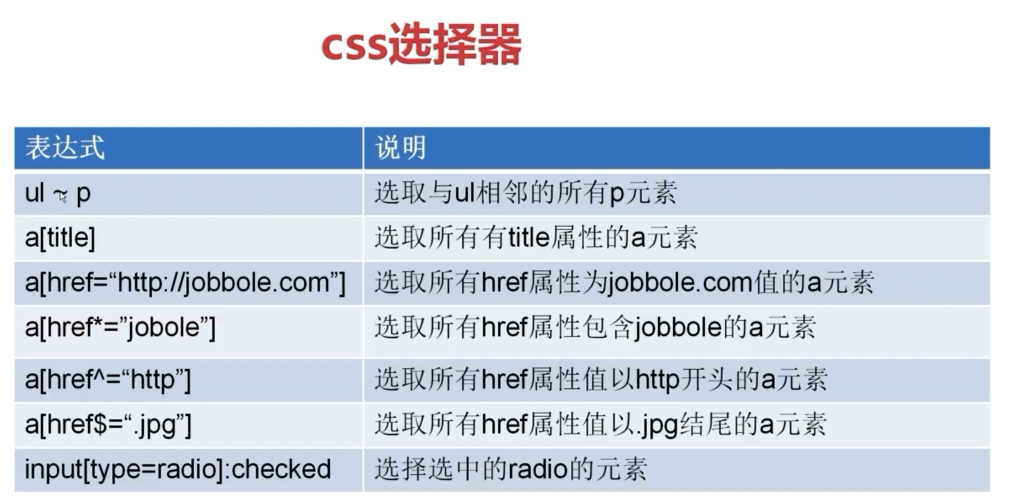

4.2获取文章名:

4.3获取时间:

4.4获取点赞数:

4.5获取收藏数:

4.6获取评论数:

4.7文章内容:

4.8标签提取:

5.Xpath和CSS提取比较,哪种方便用哪个都行,extract()[0]可以换成extract_first("")直接提取第一个,无则返回空:
# -*- coding: utf-8 -*-
import scrapy
import re class JobboleSpider(scrapy.Spider):
name = 'jobbole'
allowed_domains = ['blog.jobbole.com']
start_urls = ['http://blog.jobbole.com/114405/'] def parse(self, response):
#通过xpath提取
title=response.xpath('//div[@class="entry-header"]/h1/text()')
create_date= response.xpath('//p[@class="entry-meta-hide-on-mobile"]/text()').extract()[0].replace("·","").strip()
praise_nums=response.xpath("//span[contains(@class,'vote-post-up')]/h10/text()").extract()[0]
if praise_nums:
praise_nums=int(praise_nums)
else:
praise_nums=0
fav_nums=response.xpath("//span[contains(@class,'bookmark-btn')]/text()").extract()[0]
match_fav=re.match(".*(\d+).*",fav_nums)
if match_fav:
fav_nums=int(match_fav.group(1))
else:
fav_nums=0
comments_nums = response.xpath("//a[@href='#article-comment']/span/text()").extract()[0]
math_comments=re.match(".*(\d).*",comments_nums)
if math_comments:
comments_nums=int(math_comments.group(1))
else:
comments_nums=0
cotent=response.xpath('//div[@class="entry"]').extract()[0]
tag_list= response.xpath('//div[@class="entry-meta"]/p/a/text()').extract()
tag_list=[element for element in tag_list if not element.strip().endswith("评论")]
tags=','.join(tag_list) #通过CSS提取
title=response.css(".entry-header > h1::text").extract()[0]
create_time=response.css("p.entry-meta-hide-on-mobile::text").extract()[0].replace("·","").strip()
praise_nums=int(response.css("span.vote-post-up h10::text").extract()[0])
if praise_nums:
praise_nums = int(praise_nums)
else:
praise_nums = 0
fav_nums=response.css(".bookmark-btn::text").extract()[0]
match_fav = re.match(".*(\d+).*", fav_nums)
if match_fav:
fav_nums = int(match_fav.group(1))
else:
fav_nums = 0
comments_nums=response.css("a[href='#article-comment'] span::text").extract()[0]
math_comments = re.match(".*(\d).*", comments_nums)
if math_comments:
comments_nums = int(math_comments.group(1))
else:
comments_nums = 0
content=response.css("div.entry").extract()[0]
tag_list = response.css("p.entry-meta-hide-on-mobile a::text").extract()
tag_list = [element for element in tag_list if not element.strip().endswith("评论")]
tags = ','.join(tag_list)
三.具体实现
1.获取所有文章url(jobbole.py):
from scrapy.http import Request
#提取域名的函数
#python3
from urllib import parse
#python2
#import urlparse class JobboleSpider(scrapy.Spider):
name = 'jobbole'
allowed_domains = ['blog.jobbole.com']
start_urls = ['http://blog.jobbole.com/all-posts/'] def parse(self, response):
'''
1.获取文章列表页中的文章url并交给scrapy下载后进行解析;
2.获取下一页url并交给scrapy下载交给parse解析字段
'''
#解析列表页中所有文章url交给scrapy下载后进行解析
post_urls=response.css("div#archive div.floated-thumb div.post-meta p a.archive-title::attr(href)").extract()
for post_url in post_urls:
#若提取的url不全,不包含域名,可以用parse拼接
#Request(url=parse.urljoin(response.url,post_url),callback=self.parse_detail)
#生成器,回调
yield Request(post_url,callback=self.parse_detail)
#提取下一页并交给scrapy下载
next_url=response.css(".next.page-numbers::attr(href)").extract_first()
if next_url:
yield Request(next_url,callback=self.parse) def parse_detail(self,response):
# 通过xpath提取
title=response.xpath('//div[@class="entry-header"]/h1/text()')
create_date= response.xpath('//p[@class="entry-meta-hide-on-mobile"]/text()').extract()[0].replace("·","").strip()
praise_nums=response.xpath("//span[contains(@class,'vote-post-up')]/h10/text()").extract()[0]
if praise_nums:
praise_nums=int(praise_nums)
else:
praise_nums=0
fav_nums=response.xpath("//span[contains(@class,'bookmark-btn')]/text()").extract()[0]
match_fav=re.match(".*(\d+).*",fav_nums)
if match_fav:
fav_nums=int(match_fav.group(1))
else:
fav_nums=0
comments_nums = response.xpath("//a[@href='#article-comment']/span/text()").extract()[0]
math_comments=re.match(".*(\d).*",comments_nums)
if math_comments:
comments_nums=int(math_comments.group(1))
else:
comments_nums=0
cotent=response.xpath('//div[@class="entry"]').extract()[0]
tag_list= response.xpath('//div[@class="entry-meta"]/p/a/text()').extract()
tag_list=[element for element in tag_list if not element.strip().endswith("评论")]
tags=','.join(tag_list)
2.获取文章封面图:
class JobboleSpider(scrapy.Spider):
name = 'jobbole'
allowed_domains = ['blog.jobbole.com']
start_urls = ['http://blog.jobbole.com/all-posts/'] def parse(self, response):
'''
1.获取文章列表页中的文章url并交给scrapy下载后进行解析;
2.获取下一页url并交给scrapy下载交给parse解析字段
'''
#解析列表页中所有文章url交给scrapy下载后进行解析
#获取url及image的节点
post_nodes=response.css("div#archive div.floated-thumb div.post-thumb a")
for post_node in post_nodes:
image_url=post_node.css("img::attr(src)")
post_url=post_node.css("::attr(href)")
#若提取的url不全,不包含域名,可以用parse拼接
#Request(url=parse.urljoin(response.url,post_url),callback=self.parse_detail)
#生成器,回调
yield Request(parse.urljoin(response.url,post_url),meta={"front-image-url":image_url},callback=self.parse_detail)
#提取下一页并交给scrapy下载
next_url=response.css(".next.page-numbers::attr(href)").extract_first()
if next_url:
yield Request(next_url,callback=self.parse)
def parse_detail(self,response):
# 通过xpath提取
front_image_url=response.meta.get("front-image-url","")#文章封面图
2.items.py(通过item实例化,类似于字典,但功能更全,可以集中管理,去重等):
2.1源码如下:
# -*- coding: utf-8 -*- # Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html import scrapy class ArticleSpiderItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
pass
2.2添加文章类,用来实例化提取的文章格式(类似于Django的Model)【items.py中】:
......
class JobboleArticleSpider(scrapy.Item):
#字段中有Field类型,可以接受任何类型
title=scrapy.Field()
create_date=scrapy.Field()
url=scrapy.Field()
#对url做MD5,固定url的长度
url_object_id=scrapy.Field()
front_image_url=scrapy.Field()
front_image_path=scrapy.Field()
praise_nums=scrapy.Field()
fav_nums=scrapy.Field()
comment_nums=scrapy.Field()
tags=scrapy.Field()
content=scrapy.Field()
2.3填充数据(jobbole.py中):
...... def parse_detail(self,response):
#实例化item中JobboleArtilce对象
article_item=JobboleArticleSpider()
# 通过xpath提取
front_image_url=response.meta.get("front-image-url","")#文章封面图
title=response.xpath('//div[@class="entry-header"]/h1/text()').extract_first()
create_date= response.xpath('//p[@class="entry-meta-hide-on-mobile"]/text()').extract()[0].replace("·","").strip()
praise_nums=response.xpath("//span[contains(@class,'vote-post-up')]/h10/text()").extract()[0]
if praise_nums:
praise_nums=int(praise_nums)
else:
praise_nums=0
fav_nums=response.xpath("//span[contains(@class,'bookmark-btn')]/text()").extract()[0]
match_fav=re.match(".*(\d+).*",fav_nums)
if match_fav:
fav_nums=int(match_fav.group(1))
else:
fav_nums=0
comments_nums = response.xpath("//a[@href='#article-comment']/span/text()").extract()[0]
math_comments=re.match(".*(\d).*",comments_nums)
if math_comments:
comments_nums=int(math_comments.group(1))
else:
comments_nums=0
content=response.xpath('//div[@class="entry"]').extract()[0]
tag_list= response.xpath('//div[@class="entry-meta"]/p/a/text()').extract()
tag_list=[element for element in tag_list if not element.strip().endswith("评论")]
tags=','.join(tag_list) #填充item数据
article_item["title"]=title
article_item["url"]=response.url
article_item["create_date"]=create_date
article_item["front_image_url"]=front_image_url
article_item["praise_nums"]=praise_nums
article_item["fav_nums"]=fav_nums
article_item["comment_nums"]=comments_nums
article_item["tags"]=tags
article_item["content"]=content
#传递到item中
yield article_item
2.4把setting.py中ITEM_PIPELINES注释取消,让其生效:
ITEM_PIPELINES = {
'article_spider.pipelines.ArticleSpiderPipeline': 300,
}
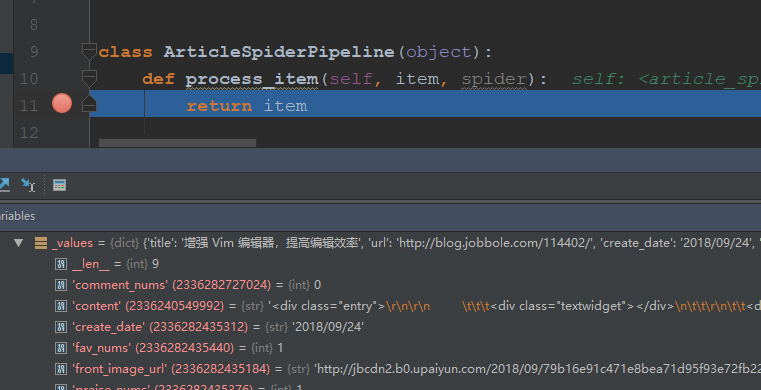
调试发现,数据会传送到pipelines中,可以在这儿做一系列操作
2.5在setting.py中添加ImagesPipelines实现图片自动下载(virtualenvs\article_spider\Lib\site-packages\scrapy\pipelines\images.py),下载图片需要依赖PIL这个库(pip install pillow):
ITEM_PIPELINES = {
'article_spider.pipelines.ArticleSpiderPipeline': 300,
#后面的数字大小表示pipeline先后流经的顺序,先1,后300
'scrapy.pipelines.images.ImagesPipeline':1
}
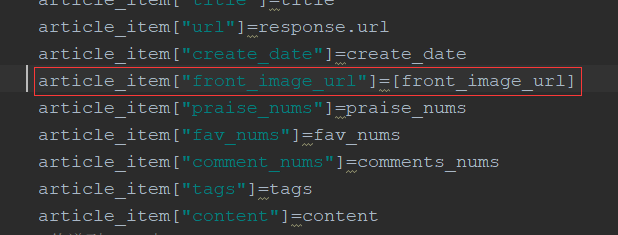
#配置图片在item中下载的字段,front-image-url会被当成数组处理,因此jobole中该字段应改成列表
IMAGES_URLS_FIELD="front_image_url"
#配置图片保存路径
import os
#获取setting.py的父目录
project_dir=os.path.dirname(os.path.abspath(__file__))
IMAGES_STORE=os.path.join(project_dir,"images")
#设置图片最小宽度,高度,即必须大于这么多才下载,还有很多属性可以坎源码
IMAGES_MIN_HEIGHT=100
IMAGES_MIN_WIDTH=100
front_image_url需转换为列表格式才能被下载
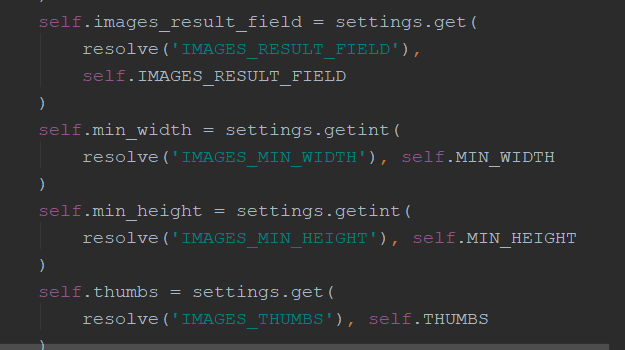
部分image.py源码
2.6定制pipeline处理封面图,获取图片地址(pipelines.py中):
class ArticleImagePipeline(ImagesPipeline):
'''
定制图片的pipepline
'''
#重写ImagesPipeline中的item_completed()函数
def item_completed(self, results, item, info):
for ok, value in results:
image_path = value['path']
item['front_image_path'] = image_path
#记得返回item
return item
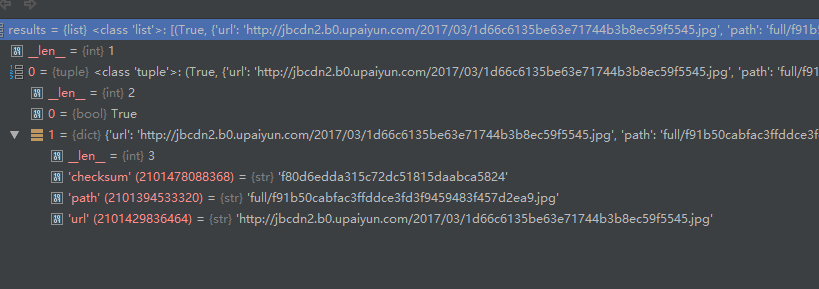
通过item_completed()获取的results结构如上图
item_completed()该方法源码如上图
2.7使用md5固定url长度(Python3默认所有字符为unicode,而unicode不能被hash),可以单独写在一个py文件;里,新建utils下common.py:
import hashlib def get_md5(url):
# 判断url如果为unicode编码,则转换为utf-8
if isinstance(url, str):
url = url.encode('utf-8')
m = hashlib.md5()
m.update(url)
return m.hexdigest() if __name__ == "__main__":
print(get_md5("https://jobbole.com".encode('utf-8')))

导入模块并调用get_md5()填充数据(jobbole.py)
3.数据的保存:
3.1通过json格式保存到文件(PIpelines.py,记得配置到setting中):
class JsonEncodingPipeline(object):
#自定义json文件的导出
def __init__(self):
self.file=codecs.open("article.json","w",encoding='utf-8') def process_item(self, item, spider):
#调用pipeline生成的函数,ensure_ascii=False防止中文等编码错误
lines=json.dumps(dict(item),ensure_ascii=False)+"\n"
self.file.write(lines)
return item def spider_closed(self,spider):
'''
调用spider_closed(信号)关闭文件
'''
self.file.close()
ITEM_PIPELINES = {
'article_spider.pipelines.ArticleSpiderPipeline': 300,
#后面的数字大小表示pipeline先后流经的顺序
# 'scrapy.pipelines.images.ImagesPipeline':1
'article_spider.pipelines.JsonEncodingPipeline':2,
'article_spider.pipelines.ArticleImagePipeline':1
}
3.2还可以用scrapy自带的库保存json格式(还有很多其他格式)(from scrapy.exporters import JsonItemExporter):

exporters中的文件格式种类
class JsonExporterPipeline(object):
#调用scrapy提供的exporter导出json文件
def __init__(self):
self.file=open("articlexporter.json","wb")
self.exporter=JsonItemExporter(self.file,encoding="utf-8",ensure_ascii=False)
#写入"[\n"
self.exporter.start_exporting()
def close_spider(self,spider):
#写入"]\n"
self.exporter.finish_exporting()
self.file.close() def process_item(self, item, spider):
self.exporter.export_item(item)
return item

3.3数据导入mysql:
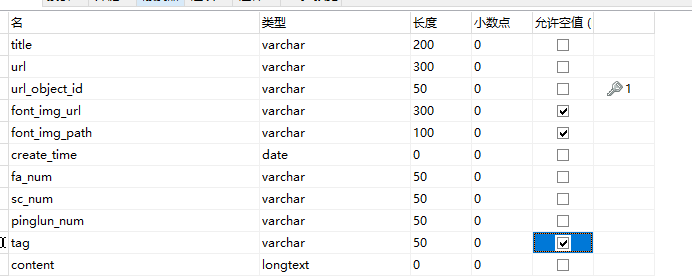
表的设计,这里只有一张表,可以直接设计:
时间格式的转换:
try:
create_date=datetime.datetime.strptime(create_date,"%Y/%m/%d").date()
except Exception as e:
create_date=datetime.datetime.now().date()
article_item["create_date"]=create_date
mysql驱动安装:pip install mysqlclient,利用Mysqldb连接数据库时的参数:
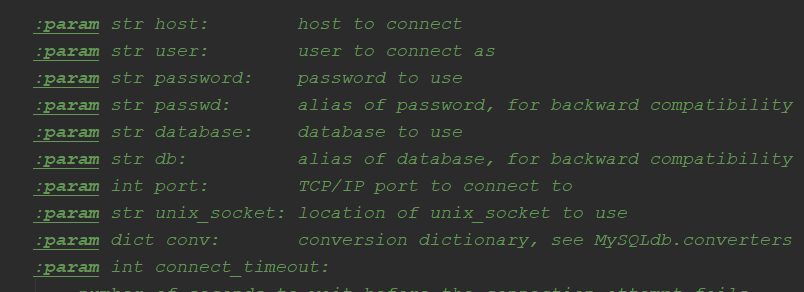
mysqlpipeline的实现,第一种插入mysql的方法(记得setting中配置pipeline),解析速度大于数据插入mysql速度,有可能导致阻塞:
......
import Mysqldb
class MysqlPipeline(object):
#数据导入数据库,爬取速度有可能远大于插入速度,造成阻塞
def __init__(self):
self.conn=MySQLdb.connect("localhost","root","","bole_articles",charset="utf8",use_unicode=True)
self.cursor=self.conn.cursor() def process_item(self,item,spider):
inser_sql="""
insert into articles(title,url,url_object_id,font_img_url,font_img_path,create_time,fa_num,sc_num,pinglun_num,tag,content)
VALUES(%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)
"""
self.cursor.execute(inser_sql,(item["title"],item["url"],item["url_object_id"],
item["front_image_url"],item["front_image_path"],item["create_date"],
item["praise_nums"],item["fav_nums"],item["comment_nums"],item["tags"],item["content"]))
self.conn.commit()
mysqltwistedpipeline异步插入(基于Twisted异步框架):
#setting中配置mysql相关信息
MYSQL_HOST="localhost"
MYSQL_DBNAME="bole_articles"
MYSQL_USER="root"
MYSQL_PASSWORD=""
......
from twisted.enterprise import adbapi
import MySQLdb
import MySQLdb.cursors
class MysqlTwistedPipeline(object):
def __init__(self, dbpool,dbpool2):
self.dbpool = dbpool # 导入setting中的配置(固定函数),注:是from_settings而不是from_setting
@classmethod
def from_settings(cls, setting):
# 将dbtool传入
dbparms = dict(
host=setting["MYSQL_HOST"],
db=setting["MYSQL_DBNAME"],
user=setting["MYSQL_USER"],
password=setting["MYSQL_PASSWORD"],
charset="utf8",
cursorclass=MySQLdb.cursors.DictCursor,
use_unicode=True,
)
# twisted异步容器,使用MySQldb模块连接
dbpool = adbapi.ConnectionPool("MySQLdb", **dbparms) return cls(dbpool) def process_item(self, item, spider):
# 使用Twisted将mysql插入变成异步执行
query = self.dbpool.runInteraction(self.do_insert, item)
# 处理异常
query.addErrback(self.handle_error,item,spider) def handle_error(self, failure, item, spider):
print(failure) def do_insert(self, cursor, item):
# 执行具体的插入
inser_sql = """
insert into articles(title,url,url_object_id,font_img_url,font_img_path,create_time,fa_num,sc_num,pinglun_num,tag,content)
VALUES(%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)
"""
cursor.execute(inser_sql, (item["title"], item["url"], item["url_object_id"],
item["front_image_url"], item["front_image_path"], item["create_date"],
item["praise_nums"], item["fav_nums"], item["comment_nums"], item["tags"],
item["content"]))
4.item_loader的使用(jobbole.py):代码更加简洁,但值全为list,定制需要修改item中函数
from scrapy.loader import ItemLoader
......
def parse_detail(self,response):
#通过item_loader加载item
item_loader=ItemLoader(item=JobboleArticleSpider(),response=response)
#三个重要方法item_loader.add_xpath();item_loader.add_css();item_loader.add_css()
item_loader.add_css("title",".entry-header > h1::text")
item_loader.add_value("url",response.url)
item_loader.add_value("url_ooject_id",get_md5(front_image_url))
item_loader.add_css("create_date","p.entry-meta-hide-on-mobile::text")
item_loader.add_value("front_image_url",[front_image_url])
item_loader.add_css("praise_nums","span.vote-post-up h10::text")
item_loader.add_css("fav_nums",".bookmark-btn::text")
item_loader.add_css("comments_nums", "a[href='#article-comment'] span::text")
item_loader.add_css("content", "div.entry")
item_loader.add_css("tags", "p.entry-meta-hide-on-mobile a::text")
#调用此方法才生效
article_item=item_loader.load_item()
yield article_item
5.修改item处理得到的函数:
from scrapy.loader.processors import MapCompose,TakeFirst
...... def date_convert(value):
#定义处理时间函数,返回时间
try:
create_date = datetime.datetime.strptime(value, "%Y/%m/%d").date()
except Exception as e:
create_date = datetime.datetime.now().date()
return create_date class JobboleArticleSpider(scrapy.Item):
# 字段中有Field类型,可以接受任何类型
title = scrapy.Field(
#可以传多个函数
input_processor=MapCompose(lambda x: x + "hah")
)
create_date = scrapy.Field(
#处理时间,还是数组
input_processor=MapCompose(date_convert),
#只取数组的第一个,如果都要写麻烦,可以定制itemloader
output_processor=TakeFirst()
)
url = scrapy.Field()
# 对url做MD5,固定url的长度
url_object_id = scrapy.Field()
front_image_url = scrapy.Field()
front_image_path = scrapy.Field()
praise_nums = scrapy.Field()
fav_nums = scrapy.Field()
comment_nums = scrapy.Field()
tags = scrapy.Field()
content = scrapy.Field()
6.定制itemloader:
items,py:
from scrapy.loader import ItemLoader
......
class ArticleItemLoader(ItemLoader):
#自定义itemloader,值取数组的第一个,修改item中的loader
default_output_processor = TakeFirst()
jobbole.py:
......
item_loader=ArticleItemLoader(item=JobboleArticleSpider(),response=response)
#三个重要方法item_loader.add_xpath();item_loader.add_css();item_loader.add_css()
item_loader.add_css("title",".entry-header > h1::text")
item_loader.add_value("url",response.url)
item_loader.add_value("url_object_id",get_md5(front_image_url))
item_loader.add_css("create_date","p.entry-meta-hide-on-mobile::text")
item_loader.add_value("front_image_url",[front_image_url])
item_loader.add_css("praise_nums","span.vote-post-up h10::text")
item_loader.add_css("fav_nums",".bookmark-btn::text")
item_loader.add_css("comment_nums", "a[href='#article-comment'] span::text")
item_loader.add_css("content", "div.entry")
item_loader.add_css("tags", "p.entry-meta-hide-on-mobile a::text") article_item=item_loader.load_item()
yield article_item
用itemloader方法定制的item(items.py):
# -*- coding: utf-8 -*- # Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html
import datetime
import re import scrapy
# TakeFirst取第一个,Join连接
from scrapy.loader.processors import MapCompose, TakeFirst, Join
from scrapy.loader import ItemLoader class ArticleSpiderItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
pass def date_convert(value):
# 定义处理时间函数,返回时间
try:
create_date = datetime.datetime.strptime(value, "%Y/%m/%d").date()
except Exception as e:
create_date = datetime.datetime.now().date()
return create_date class ArticleItemLoader(ItemLoader):
# 自定义itemloader,值取数组的第一个,修改item中的loader
default_output_processor = TakeFirst() def get_nums(value):
# 定义处理点赞数,收藏数,评论数处理等
match_num = re.match(".*(\d+).*", value)
if match_num:
value = int(match_num.group(1))
else:
value = 0
return value def return_value(value):
# 什么也不做
return value def remove_comment(value):
# 去掉tag中提取的含评论的便签
if "评论" in value:
return ""
else:
return value class JobboleArticleSpider(scrapy.Item):
# 字段中有Field类型,可以接受任何类型
title = scrapy.Field()
create_date = scrapy.Field(
# 处理时间,还是数组
input_processor=MapCompose(date_convert),
# 只取数组的第一个
# output_processor=TakeFirst()
)
url = scrapy.Field()
# 对url做MD5,固定url的长度
url_object_id = scrapy.Field()
front_image_url = scrapy.Field(
#覆盖定制的itemloader,这里必须为列表
outout_processor=MapCompose(return_value)
)
front_image_path = scrapy.Field()
praise_nums = scrapy.Field(
input_processor=MapCompose(get_nums)
)
fav_nums = scrapy.Field(
input_processor=MapCompose(get_nums)
)
comment_nums = scrapy.Field(
input_processor=MapCompose(get_nums)
)
tags = scrapy.Field(
# 覆盖定制的取第一个
output_processor=Join(",")
)
content = scrapy.Field()
四.总结
利用上面的方法就可以快速爬取所有文章了,scrapy是一个分布式的设计,也是多线程,写爬虫的主要部分就是在spider中定制爬虫要爬取的url及填充数据(jobbole.py),以及定制item的模板(items.py),然后就是定制pipeline对item中的数据进行一系列操作,如写入json文件,导入数据库,下载图片,获取图片路径等等。
爬虫实战——Scrapy爬取伯乐在线所有文章的更多相关文章
- python爬虫scrapy框架——爬取伯乐在线网站文章
一.前言 1. scrapy依赖包: 二.创建工程 1. 创建scrapy工程: scrapy staratproject ArticleSpider 2. 开始(创建)新的爬虫: cd Artic ...
- Scrapy爬取伯乐在线的所有文章
本篇文章将从搭建虚拟环境开始,爬取伯乐在线上的所有文章的数据. 搭建虚拟环境之前需要配置环境变量,该环境变量的变量值为虚拟环境的存放目录 1. 配置环境变量 2.创建虚拟环境 用mkvirtualen ...
- Scrapy基础(六)————Scrapy爬取伯乐在线一通过css和xpath解析文章字段
上次我们介绍了scrapy的安装和加入debug的main文件,这次重要介绍创建的爬虫的基本爬取有用信息 通过命令(这篇博文)创建了jobbole这个爬虫,并且生成了jobbole.py这个文件,又写 ...
- Scrapy爬取伯乐在线文章
首先搭建虚拟环境,创建工程 scrapy startproject ArticleSpider cd ArticleSpider scrapy genspider jobbole blog.jobbo ...
- scrapy爬取伯乐在线文章数据
创建项目 切换到ArticleSpider目录下创建爬虫文件 设置settings.py爬虫协议为False 编写启动爬虫文件main.py
- python爬虫实战(七)--------伯乐在线文章(模版)
相关代码已经修改调试成功----2017-4-21 一.说明 1.目标网址:伯乐在线 2.实现:如图字段的爬取 3.数据:存放在百度网盘,有需要的可以拿取 链接:http://pan.baidu.co ...
- 【转载】教你分分钟学会用python爬虫框架Scrapy爬取心目中的女神
原文:教你分分钟学会用python爬虫框架Scrapy爬取心目中的女神 本博文将带领你从入门到精通爬虫框架Scrapy,最终具备爬取任何网页的数据的能力.本文以校花网为例进行爬取,校花网:http:/ ...
- Python爬虫实战之爬取百度贴吧帖子
大家好,上次我们实验了爬取了糗事百科的段子,那么这次我们来尝试一下爬取百度贴吧的帖子.与上一篇不同的是,这次我们需要用到文件的相关操作. 本篇目标 对百度贴吧的任意帖子进行抓取 指定是否只抓取楼主发帖 ...
- 爬取伯乐在线文章(五)itemloader
ItemLoader 在我们执行scrapy爬取字段中,会有大量的CSS或是Xpath代码,当要爬取的网站多了,要维护起来很麻烦,为解决这类问题,我们可以根据scrapy提供的loader机制. 导入 ...
随机推荐
- BFC原理剖析
本文讲了BFC的概念是什么: BFC的约束规则:咋样才能触发生成新的BFC:BFC在布局中的应用:防止margin重叠(塌陷,以最大的为准): 清除内部浮动:自适应两(多)栏布局. 1. BFC是什么 ...
- 测试一下robotgo自动化操作,顺便解决了原来的mingw版本中只有gcc,没有g++的问题
参考:https://gitee.com/veni0/robotgo#examples 但是编译不成功 找到这个:https://gitee.com/veni0/robotgo#examples ( ...
- filter 实现登录状态控制
每天学习一点点 编程PDF电子书.视频教程免费下载:http://www.shitanlife.com/code 网站需要做用户登录鉴权控制,没有登录的话,不能访问网站,提示需要登录. 实现方式: 使 ...
- P1515 旅行(简单搜索)
非常简单的搜索. 思路:先排序,然后,搜索枚举的时候满足A < 两个旅店 < B,然后,搜索就行了. #include<iostream> #include<algori ...
- (四)JavaScript 语句
JavaScript 语句 JavaScript 语句是发给浏览器的命令. 这些命令的作用是告诉浏览器要做的事情. 下面的 JavaScript 语句向 id="demo" 的 H ...
- PHP 3 运算符 if...else...elseif 语句
<?php $x=10; $y=6; echo ($x + $y); // 输出 16 echo ($x - $y); // 输出 4 echo ($x * $y); // 输出 60 echo ...
- [ASP.NET]ScriptManager控件使用 转载
目录 概述 局部刷新 错误处理 类型系统扩展 注册定制脚本 注册 Web 服务 在客户端脚本中使用认证和个性化服务 ScriptManagerProxy 类 添加 ScriptManager 控件 客 ...
- RMQ问题--范围最小值问题
范围最小值问题(Range Minium Query,RMQ)---RMQ问题 一.一维问题 给出一个n个元素的数组A1,A2,...,An, 设计一个数据结构, 支持查询操作Query(L,R):计 ...
- Django:安装和启动
最近在学习利用python语言进行web站点开发,使用的框架是Django.这篇博客主要介绍Django的安装和简单使用. 一.Django介绍 Django是一个开源的Web应用框架,由Python ...
- Generative Adversarial Nets[Theory&MSE]
本文来自<deep multi-scale video prediction beyond mean square error>,时间线为2015年11月,LeCun等人的作品. 从一个视 ...