【CPU微架构设计】分布式多端口(4写2读)寄存器堆设计
寄存器堆(Register File)是微处理的关键部件之一。寄存器堆往往具有多个读写端口,其中写端口往往与多个处理单元相对应。传统的方法是使用集中式寄存器堆,即一个集中式寄存器堆匹配N个处理单元。随着端口数量的增加,集中式寄存器堆的功耗、面积、时序均会呈幂增长,进而可能降低处理器总体性能。
下图所示为传统的集中式寄存器堆结构:

本文讨论一种基于分布存储和面积与时序互换原则的多端口寄存器堆设计,我们暂时称之为“分布式寄存器堆”。该种寄存器从端口使用上,仍与集中式寄存器堆完全兼容,但该寄存器堆使用多个寄存器簇和块分布式地存储操作数。当并行写入时,各寄存器簇分布式地存储写入结果;当读出时,由相应的仲裁算法在多个寄存器簇的结果中选取确定的一个簇作为最终输出。图二显示了这种分布式寄存器堆的逻辑结构。
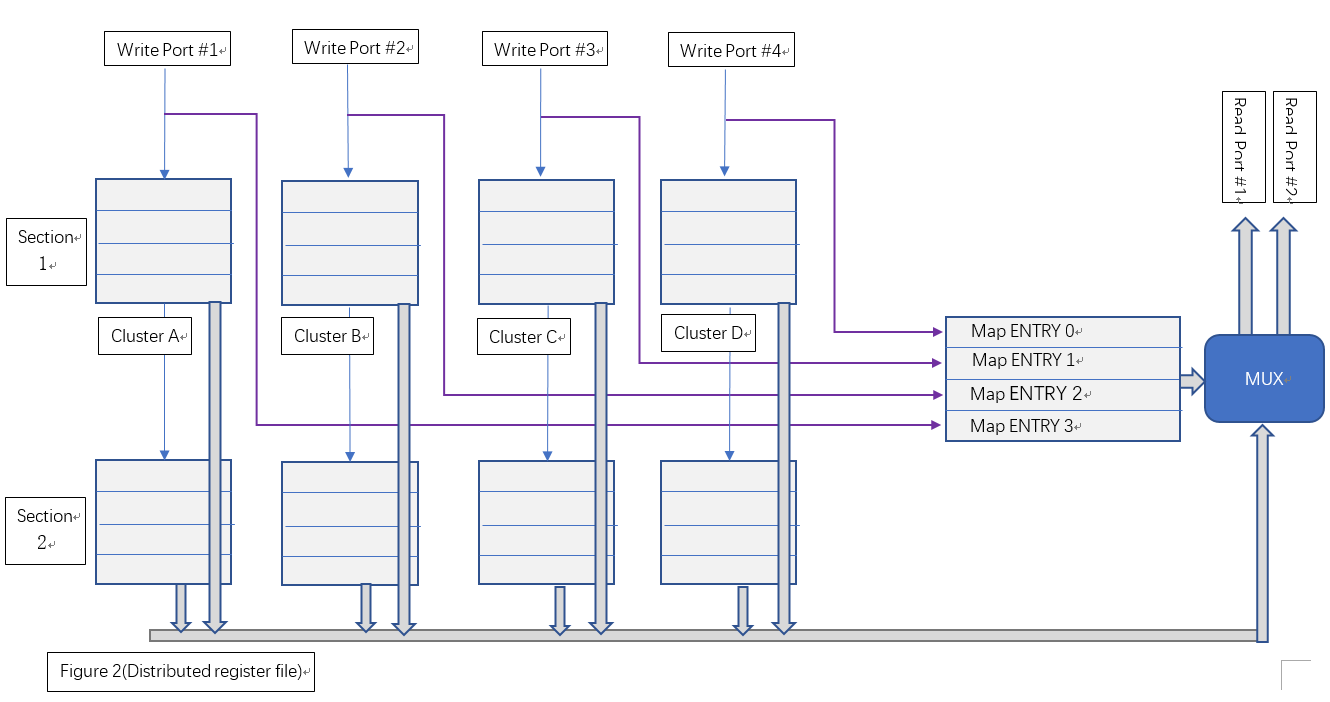
该结构主要由区块(Section)和簇(Cluster)两个维度组织寄存器:
(1)、从Section层面看,Section 1和Section 2是两个完全相同的组成结构(相当于逻辑的复制),同时两个Section中寄存器所持有的操作数也完全相同。一个Section只能处理一个读端口的操作。Section1负责处理读端口#1,而Section2负责处理读端口#2。
(2)、从Cluster层面看,Cluster A、B、C、D是几个分别独立的集中式寄存器堆,其具体结构可等价为一个双口RAM。写入时,Clusters分别独立地写入各自要求的地址。读出时,各Cluster从相同的读出地址读出各自的数据,最后将4个数据送到MUX进行最后的仲裁。
综上,单个Section负责单个读端口操作,单个Cluster负责单个写端口操作。
分布式寄存器堆的设计关键在于仲裁调度算法。由于一个Section只负责处理一个读端口的操作,我们首先从单个Section维度考虑。虽然单个周期内需要同时处理4个写端口,但读端口是唯一的。事先记录每个写端口的地址所对应的Cluster编号,在读出时,通过读出地址反向获取对应的Cluster,进而从该Cluster取出最终结果。
其次再考虑多个读端口并行操作。考虑复制两个相同的Section逻辑,并将所有写端口并联起来,则可以保证两个Section所持有的操作数完全相同。对两个Section同时进行读操作,这样便实现了并行地读出两个不同地址的数据。
接下来设计两个关键部件:Cluster寄存器堆和数据仲裁器。
一、Cluster寄存器的设计
上文已经提到过,Cluster寄存器可等价为双端口RAM。关于DPRAM的具体结构可参考相关资料,本文不再赘述。DPRAM容量根据最为通用的配置,采用32x32bit设计,可通过例化参数设置地址总线和数据总线的宽度。利用Verilog描述一个同步时钟DPRAM的源码如下:
module dpram_sclk
#(
,
,
, // Whether to rest the RAM while initialization (for simulation only)
// Whether enable data bypass
)
(/*AUTOARG*/
// Outputs
dout,
// Inputs
clk, rst, raddr, re, waddr, we, din
);
// Port List
input clk;
input rst;
:] raddr;
input re;
:] waddr;
input we;
:] din;
:] dout;
:] mem[(<<ADDR_WIDTH)-:];
:] rdata;
reg re_r;
:] dout_w;
generate
if(CLEAR_ON_INIT) begin :clear_on_init
integer entry;
initial begin
; entry < (<<ADDR_WIDTH); entry=entry+) // reset
mem[entry] = {DATA_WIDTH{'b0}};
end
end
endgenerate
// bypass control
generate
if (ENABLE_BYPASS) begin : bypass_gen
:] din_r;
reg bypass;
assign dout_w = bypass ? din_r : rdata;
always @(posedge clk)
if (re) din_r <= din;
always @(posedge clk)
if (waddr == raddr && we && re)
bypass <= ;
else
bypass <= ;
end else begin
assign dout_w = rdata;
end
endgenerate
// R/W logic
always @(posedge clk)
re_r <= rst ? 'b0 : re;
'b0}};
always @(posedge clk) begin
if (we)
mem[waddr] <= din;
if (re)
rdata <= mem[raddr];
end
endmodule
module dpram_sclk
值得注意的是,实现中加入了数据旁通机制,保证当发生同时读写且地址相同时,写入数据能在单个操作周期内送达读端口。
二、数据仲裁器的设计
数据仲裁器的核心是维护一个写入地址→Cluster编号的映射表。假设分布式寄存器堆总共有32个寄存器(以5bit地址总线寻址),则我们需要一个表项数为32的列表,存储每个地址对应的Cluster编号。Verilog描述如下:
:] sel_map[(<<ADDR_WIDTH)-:];
对于每个写端口,在写操作周期维护映射表,记录下写入地址对应的Cluster,实现如下:
// Maintain the selection map
always @(posedge clk) begin
if (we1)
sel_map[waddr1] <= 'd0;
if (we2)
sel_map[waddr2] <= 'd1;
if (we3)
sel_map[waddr3] <= 'd2;
if (we4)
sel_map[waddr4] <= 'd3;
end
对于读端口,先从映射表获取实际存储目标操作数的Cluster,然后利用多路复用器选取其输出,作为该Section的最终读取结果。
// mux
'd0 ? dout0 :
sel_map[raddr]=='d1 ? dout1 :
sel_map[raddr]=='d2 ? dout2 :
sel_map[raddr]=='d3 ? dout3 :
{DATA_WIDTH{'b0}}; /* never got this */
由此,我们可以得出单个Section的完整设计:
module cpram_sclk_4w1r #(
,
,
, // Whether to rest the RAM while initialization (for simulation only)
// Whether enable data bypass
)
(/*AUTOARG*/
// Outputs
rdata,
// Inputs
clk, rst, we1, waddr1, wdata1, we2, waddr2, wdata2, we3, waddr3,
wdata3, we4, waddr4, wdata4, re, raddr
);
// Ports
input clk;
input rst;
input we1;
:] waddr1;
:] wdata1;
input we2;
:] waddr2;
:] wdata2;
input we3;
:] waddr3;
:] wdata3;
input we4;
:] waddr4;
:] wdata4;
input re;
:] raddr;
:] rdata;
// Internals
:] dout;
:] dout0;
:] dout1;
:] dout2;
:] dout3;
:] sel_map[(<<ADDR_WIDTH)-:];
// instance of sync dpram #1 for Cluster A
dpram_sclk
#(
.ADDR_WIDTH (ADDR_WIDTH),
.DATA_WIDTH (DATA_WIDTH),
.CLEAR_ON_INIT (CLEAR_ON_INIT),
.ENABLE_BYPASS (ENABLE_BYPASS)
)
mem0
(
.clk (clk),
.rst (rst),
.dout (dout0),
.raddr (raddr),
.re (re),
.waddr (waddr1),
.we (we1),
.din (wdata1)
);
// instance of sync dpram #2 for Cluster B
dpram_sclk
#(
.ADDR_WIDTH (ADDR_WIDTH),
.DATA_WIDTH (DATA_WIDTH),
.CLEAR_ON_INIT (CLEAR_ON_INIT),
.ENABLE_BYPASS (ENABLE_BYPASS)
)
mem1
(
.clk (clk),
.rst (rst),
.dout (dout2),
.raddr (raddr),
.re (re),
.waddr (waddr2),
.we (we2),
.din (wdata2)
);
// instance of sync dpram #3 for Cluster C
dpram_sclk
#(
.ADDR_WIDTH (ADDR_WIDTH),
.DATA_WIDTH (DATA_WIDTH),
.CLEAR_ON_INIT (CLEAR_ON_INIT),
.ENABLE_BYPASS (ENABLE_BYPASS)
)
mem2
(
.clk (clk),
.rst (rst),
.dout (dout3),
.raddr (raddr),
.re (re),
.waddr (waddr3),
.we (we3),
.din (wdata3)
);
// instance of sync dpram #4 for Cluster D
dpram_sclk
#(
.ADDR_WIDTH (ADDR_WIDTH),
.DATA_WIDTH (DATA_WIDTH),
.CLEAR_ON_INIT (CLEAR_ON_INIT),
.ENABLE_BYPASS (ENABLE_BYPASS)
)
mem3
(
.clk (clk),
.rst (rst),
.dout (dout3),
.raddr (raddr),
.re (re),
.waddr (waddr4),
.we (we4),
.din (wdata4)
);
// mux
'd0 ? dout0 :
sel_map[raddr]=='d1 ? dout1 :
sel_map[raddr]=='d2 ? dout2 :
sel_map[raddr]=='d3 ? dout3 :
{DATA_WIDTH{'b0}}; /* never got this */
// Read output with/without bypass controlling
generate
if (ENABLE_BYPASS) begin : bypass_gen
assign rdata =
(we1 && (raddr==waddr1)) ? wdata1 :
(we2 && (raddr==waddr2)) ? wdata2 :
(we3 && (raddr==waddr3)) ? wdata3 :
(we4 && (raddr==waddr4)) ? wdata4 :
dout;
end else begin
assign rdata = dout;
end
endgenerate
// Maintain the selection map
always @(posedge clk) begin
if (we1)
sel_map[waddr1] <= 'd0;
if (we2)
sel_map[waddr2] <= 'd1;
if (we3)
sel_map[waddr3] <= 'd2;
if (we4)
sel_map[waddr4] <= 'd3;
end
endmodule
值得说明的是:上述实现仍然需要考虑四个写端口与一个读端口的数据旁通路径。通过例化参数ENABLE_BYPASS可以指定是否使用数据旁通逻辑。
将两个Section写端口并联,并分别引出其读端口,即构成了一个4w 2r寄存器堆。
总结
本文讨论的数据的分布存储方法和基于面积换时序的逻辑复制方法,在集中存储式寄存器堆的优化中取得了较好的效果。但该结构缺点也十分明显:首先,对集中寄存器堆的复制无疑增加了面积和功耗,其次,随着写端口数的增加,仲裁逻辑的规模也随之增长,这将导致数据路径延迟增加,进而降低寄存器堆时钟工作频率。
相比于ASIC设计,本结构更适合于FPGA验证。理由如下:在FPGA中,寄存器是非常有限的资源。若直接实现一定规模的RAM结构,则需要大量占用寄存器资源。为此,FPGA在硬件上集成了RAM Block资源。这些RAM Blocks多可配置为双端口模式,但对于更复杂的端口配置(如本例的4w2r),则只能间接实现。
本设计完全采用RAM Blocks实现多端口寄存器堆。因为FPGA综合工具在分析verilog源码时,将自动识别出我们所采用的DPRAM,转而使用RAM Block资源,避免占用寄存器资源,为设计的其它部分留出更多可用的寄存器资源。同时,这将避免使用LUT实现复杂的RAM单元寻址和控制逻辑,从而优化时序。
2018 10.20
===================================================
本博文仅供参考,多有疏漏之处,欢迎提出宝贵意见。
【CPU微架构设计】分布式多端口(4写2读)寄存器堆设计的更多相关文章
- 【CPU微架构设计】利用Verilog设计基于饱和计数器和BTB的分支预测器
在基于流水线(pipeline)的微处理器中,分支预测单元(Branch Predictor Unit)是一个重要的功能部件,它负责收集和分析分支/跳转指令的执行结果,当处理后续分支/跳转指令时,BP ...
- ARM架构--CPU的微架构
网上确实有说ARM架构的,但是此架构泛指用ARM指令系统的CPU,而不是CPU的微架构.,硬件电路上,要用ARM指令集系统,必然硬件设计电路上要要遵循,ARM指令的特点和寻址方式,所以说高通和苹果的C ...
- InfoQ一波文章:菜鸟核心技术/Intel发布CPU新架构3D堆栈法/BDL/PaddlePaddle/百度第三代Spider/Tera
菜鸟智慧新物流核心技术全解析 孟靖 阅读数:63192018 年 12 月 14 日 16:00 2018 年天猫双 11 全球狂欢节已正式落下帷幕,最终成交额定格在 2135 亿元,物流订单 ...
- 微服务架构下分布式Session管理
转载本文需注明出处:EAII企业架构创新研究院(微信号:eaworld),违者必究.如需加入微信群参与微课堂.架构设计与讨论直播请直接回复此公众号:“加群 姓名 公司 职位 微信号”. 一.应用架构变 ...
- 手机服务器微架构设计与实现 之 http server
手机服务器微架构设计与实现 之 http server ·应用 ·传输协议和应用层协议概念 TCP UDP TCP和UDP选择 三次握手(客户端与服务器端建立连接)/四次挥手(断开连接)过程图 · ...
- CPU和微架构的概念
CPU是什么: 中央处理器(CPU,Central Processing Unit)是一块超大规模的集成电路,是一台计算机的运算核心(Core)和控制核心( Control Unit). 它的功能主要 ...
- Java生鲜电商平台-SpringCloud微服务架构中分布式事务解决方案
Java生鲜电商平台-SpringCloud微服务架构中分布式事务解决方案 说明:Java生鲜电商平台中由于采用了微服务架构进行业务的处理,买家,卖家,配送,销售,供应商等进行服务化,但是不可避免存在 ...
- 处理器核、Core、处理器、CPU区别&&指令集架构与微架构的区别&&32位与64位指令集架构说明
1.处理器核.Core.处理器.CPU的区别 严格来说"处理器核"和" Core "是指处理器内部最核心的部分,是真正的处理器内核:而"处理器&quo ...
- 阿里微服务架构下分布式事务解决方案-GTS
虽然微服务现在如火如荼,但对其实践其实仍处于初级阶段.即使互联网巨头的实践也大多是试验层面,鲜有核心业务系统微服务化的案例.GTS是目前业界第一款,也是唯一的一款通用的解决微服务分布式事务问题的中间件 ...
随机推荐
- Web高级 网站安全
1. SQL注入 虽然现在SQL注入发生的情况总的来说越来越少,还是提二句.关于什么是SQL注入大家都知道就不多说了. 1.1 原理 我们在做前端页面的时候,少不了会又各种输入框,然后通过GET或者P ...
- (引用)!Unicode,GBK以及UTF8的联系和区别
在实现单片机显示汉字的操作时,了解到有关汉字编码的相关概念. Unicode是一种字符集,该字符集可以涵盖世界上所有的语言.最常见的字符集是ASC II-0~127(0x00~0x7f).Unicod ...
- xpath知多少
XPath 语法 XPath 使用路径表达式来选取 XML 文档中的节点或节点集.节点是通过沿着路径 (path) 或者步 (steps) 来选取的. XML 实例文档 我们将在下面的例子中使用这个 ...
- com.android.build.api.transformException报错的解决方法
最近遇到一个问题:工程需要依赖模块1和模块2,但是模块1和模块2都使用了opencv,但opencv的版本不同,如果同时依赖两个模块,就会报错重复定义...如果模块2依赖模块1,工程再依赖模块2,也会 ...
- WordPress版微信小程序3.2版发布
WordPress版微信小程序(下称开源版)距离上次更新已经过去大半年了,在此期间,我开发新的专业版本-微慕小程序(下称微慕版),同时开源版的用户越来越多,截止到2018年11月26日,在github ...
- Flex 布局的教程
前言:以前也经常用flex布局,但是最近看到别人使用的时候,发觉以前自己还是不够理解这个,重新看了一遍http://www.ruanyifeng.com/blog/2015/07/flex-gramm ...
- 通过nginx日志,统计最近两天的交易笔数
#!/bin/bash yesterday=`date -d last-day +%Y-%m-%d` dayago=`date -d '2 days ago' +%Y-%m-%d` #echo $ye ...
- 使用NPM安装Vue项目
使用NPM安装Vue项目步骤如下: 一.先安装node.js,下载node.js安装包,node.js安装成功之后,左击电脑左下角>运行>输入cmd,如下图所示: 二.点击确定进入,分别在 ...
- 6.3 基于二分搜索树、链表的实现的集合Set复杂度分析
两种集合类的复杂度分析 在[6.1]节与[6.2]节中分别以二分搜索树和链表作为底层实现了集合Set,在本节就两种集合类的复杂度分析进行分析:测试内容:6.1节与6.2节中使用的书籍.测试方法:测试两 ...
- Anatomy of a Database System学习笔记 - 查询
查询解析 解析会生成一个查询的内部展示.格式检查包含在解析过程中. 每次解析一个SELECT,步骤如下:1. 从FROM里找到表名,转换成schema.tablename.这一步需要调用目录管理器ca ...